Par : Noé FAURE
Formation Supérieure aux Métiers du Son Directeur de mémoire : Charles VERRON, Septembre 2018
Abstract
Directivity of sound sources is a common phenomena of our everyday life. Someone’s voice talking, some musical instrument or high-speaker playing : they all radiate sound according to the direction in space in a way that is interpreted by the brain, consciously or unconsciously.
Some fields showed an early interest about the feature of directivity. In architectural acoustics and acoustic simulation, the interaction between source directivity and reverberation have been subject to many investigations. In musical acoustics, the capture and the analysis of source directivity is signi- ficant to fully characterize music instruments. Finally, the question of directivity appears in the field of video games. This was made possible by the improvement of game engines and with the increase of CPU. However, music and sound production are currently left behind : the acoustic phenomena of directivity is naturally present during sound recording, but the information is lost right away for the rest of the production chain.
The present work intends to explore a new kind of production workflow for sound engineers, inte- grating the manipulation of sound sources with directivity.
The HOOF (High Order O-Format ) presented here, appears as an interesting answer. It consists in using the spherical harmonics decomposition to store directional sound sources, for the purpose of post-production. In this work, we will first go into detail through the recording and encoding process. Then, we will talk about the post-production and the decoding part, back to the physical world.
Throughout the Appendix, we will review the pre-existing solutions to work with source directivity.
Résumé
La directivité des sources sonores est un phénomène que nous côtoyons au quotidien. Qu’il s’agisse de la voix d’un interlocuteur, d’un instrument de musique ou d’un haut-parleur, ces variations perceptives sont intégrées naturellement par le cerveau de manière consciente ou inconsciente.
Plusieurs domaines se sont déjà intéressés au rayonnement des sources sonores, notamment celui de l’acoustique architecturale et de la simulation acoustique où l’influence de la directivité sur la perception de la réverbération a été largement étudiée. Pour l’étude des instruments de musique, la captation et l’analyse du rayonnement ont également une place importante. Finalement, c’est dans le domaine des jeux vidéo que l’on retrouve la question de la directivité, permise par le perfectionnement progressif des moteurs de jeu et l’augmentation de la puissance de calcul. Mais le domaine de la production sonore et musicale est en reste : ce paramètre, présent naturellement au moment de la prise de son, disparaît ensuite de la chaîne de production.
Ce travail se propose donc d’explorer un nouveau type de production pour les ingénieurs du son, intégrant la manipulation de sources directives.
Le format HOOF (High Order O-Format), présenté ici, apparaît comme une réponse intéressante. Il s’agit d’utiliser le formalisme des harmoniques sphériques pour stocker des sources directives, à des fins de post-production. Nous évoquerons les problématiques de captation et d’encodage en harmoniques sphériques ainsi que les différentes possibilités de restitution, virtuelles ou physiques.
En annexe, on trouvera un état des lieux des différentes solutions logicielles pré-existantes pour appréhender les sources directives.
Mots clés : Sources directives, rayonnement, HOOF, harmoniques sphériques, réalité virtuelle.
Introduction
Nous assistons depuis quelques années à un regain d’intérêt et à une démocratisation des médias « immersifs ». Des casques stéréoscopiques et des caméras 360° sont désormais disponibles sur le marché du grand public, les productions vidéos 360° de qualité sont de plus en plus nombreuses (LeMoigne, 2016 [3]), et disponibles sur les réseaux sociaux : on peut désormais être son propre « réalisateur », immergé au sein d’un film, avec la possibilité de regarder tout autour de soi.
L’audio a donc un rôle important à jouer : il s’agit de plonger l’auditeur dans un espace sonore (« réaliste » ou « imaginaire »), soit grâce à un système de haut-parleurs ou par des traitements binauraux au casque. Cet intérêt pour « l’audio spatialisé » a amené les concepteurs de DAWs1 à augmenter le nombre de canaux disponibles, les développeurs à concevoir des outils de spatialisation, et les ingénieurs du son à s’intéresser aux formats audios spatialisés.
Mais une prochaine étape importante, déjà en cours d’expérimentation, est sans doute la captation vidéo volumétrique (ou 6 DoFs2), offrant la possibilité au spectateur de se déplacer dans la scène, et éventuellement d’interagir avec elle. On risque donc d’assister prochainement à un nouveau type de média, à la frontière entre le jeu vidéo et le cinéma, interrogeant la place du spectateur dans l’œuvre cinématographique.
Certaines expériences avec des caméras « lightfield »3 ont déjà montré quelques résultats intéressants
pour ce type de captation. Et l’audio va devoir trouver des solutions pour capter ou simuler les effets « acoustiques » de distance, d’occlusion et de directivité des sources. Les sources sonores manipulées, jusqu’alors omnidirectionnelles, se verront attribuer un volume et une directivité propre.
Nous verrons dans une première partie que de nombreux travaux de recherche ont déjà été effectués autour de la captation et la caractérisation du rayonnement des sources sonores, dans des conditions plus ou moins restrictives, à des fins de simulations acoustiques. Un éclairage particulier sera apporté sur les instruments de musique, objets sonores complexes s’il en est.
Mais la spécificité de l’ingénieur du son est qu’il appréhende le son au service d’un projet artistique ou esthétique. Que ce soit dans un contexte musical, audiovisuel, radiophonique ou autre, les outils qu’il manipule, de la prise de son à la post-production, n’ont pas vocation à restituer fidèlement la réalité de manière scientifique et objective, mais de répondre à des codes, des goûts et des expérimentations artistiques variées.
Il s’agit donc d’imaginer un format pratique et pertinent pour manipuler les directivités de sources sonores dans le cadre de productions artistiques, pour les étapes de la captation et de la post-production : c’est l’objectif du format HOOF (High Order O-Format), extrapolation aux ordres supérieurs du O-Format ambisonique. Le travail sur les sources HOOF est indépendant du format de sortie, et la restitution peut-être faîte en stéréo, binaural, ou sur un système multicanal.
Nous détaillerons dans la seconde partie de ce mémoire les différents aspects de la solution HOOF (captation, post-production, restitution), en les illustrant par quelques cas d’usages. Les scripts Py- thon rédigés dans le cadre de ce travail seront disponibles en Annexe, ainsi qu’un état des différentes solutions pré-existantes.
Première partie : La directivité : méthodes de mesures et représentations
1. Définitions
En acoustique, on parle de rayonnement pour désigner l’émission d’énergie par une source sonore, sous forme d’ondes acoustiques. La directivité d’une source sonore est la répartition spatiale du rayonnement autour de la source. Elle est la plupart du temps exprimée sous forme d’une fonction en coordonnées sphériques, et permet de caractériser une source sonore.
Si une source sonore peut être parfaitement décrite d’un point de vue temporel et fréquentiel à partir d’un simple enregistrement monophonique, les informations de directivité nécessitent une des- cription spatiale.
Une source sonore est dite « omnidirectionnelle » ou « omnidirective » lorsque l’énergie est rayonnée de la même manière dans toutes les directions. C’est le cas le plus simple de description de la directivité, que l’on peut noter :
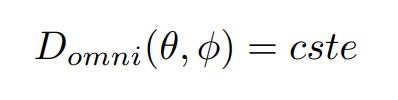
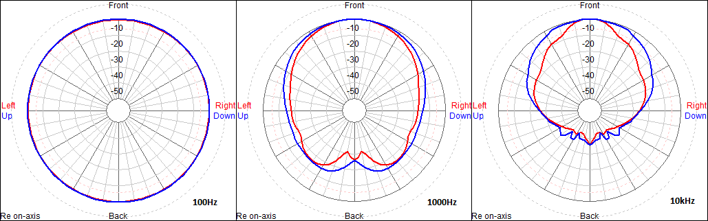
Il s’agit du cas théorique d’une source ponctuelle « monopole », aussi appelée « sphère pulsante »[6]. En effet, une source réelle ne peut pas être omnidirective à toutes les fréquences, comme le montre la figure 1 ci-dessous 4. La prise en compte de la fréquence est donc indispensable pour décrire des sources réelles.
Comme le rappelle Martin Pollow dans [34], plusieurs définitions de la directivité fréquentielle sont possibles, suivant l’application envisagée. Il distingue en effet la « directivité en magnitude« , où seule la partie réelle du spectre complexe est prise en compte de la « directivité complexe » tenant compte des informations de phase.
L’aspect dynamique de la directivité peut également être pris en compte. En effet, pour certaines sources et à certaines fréquences, le rayonnement évolue au cours du temps, ce qui pourrait donner la description ultime de la « directivité dynamique« .
On pourrait donc décliner la fonction de directivité
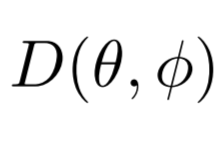
de plusieurs manières :
- Directivité en « gain » :
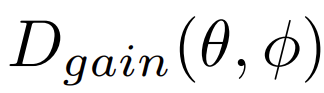
variation du niveau sonore autour de la source, en considé- rant toutes les fréquences (« pleine bande »).
- Directivité en « magnitude » :
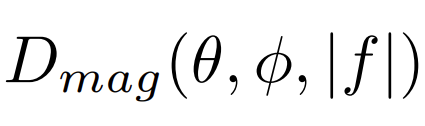
obtenue à partir de la partie réelle du spectre, souvent exprimée en utilisant des moyennages par bande d’octave (ou 1/3 d’octave).
- Directivité « complexe » :
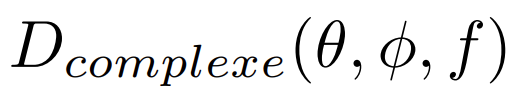
obtenue à partir du spectre complexe, prise en compte des informations de phase.
- Directivité « dynamique« ,
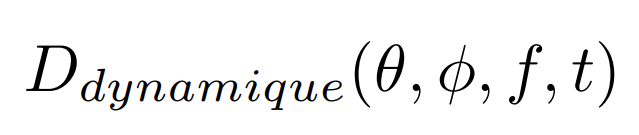
évolution de la directivité au cours du temps. Ainsi, la finesse de la description doit être adaptée à l’application recherchée.
Dans le cadre de virtualisation de sources sonores, s’il s’agit simplement de faire entendre les variations de volume sonore en fonction de l’orientation de la source, une simple directivité « en gain » peut suffire. Si l’on souhaite ajouter du réalisme à la simulation et ajouter la dépendance fréquentielle, on peut utiliser une directivité en « magnitude ».
Enfin, si la phase absolue (l’inversion de phase) n’est pas directement perçue par l’oreille humaine, les dégradations spectrales dues à la phase le sont. La «directivité complexe» est donc une formulation utile dans les cas faisant intervenir plusieurs sources sonores corrélées, ou pour simuler des sources sonores en volume comme nous le verrons dans la troisième partie.
Mentionnons également que la directivité est souvent liée à la longueur d’onde rayonnée, plus précisément au rapport entre la fréquence rayonnée et les dimensions de la source sonore. Les fréquences possédant une longueur d’onde supérieure aux dimensions de la source sont généralement omnidirectives. On peut considérer, et on le voit sur la figure 1, que les sources sonores sont de plus en plus directives lorsque l’on monte en fréquence, et qu’elles sont moins directives lorsque leurs dimensions réduisent.
Notons finalement que la directivité peut également permettre de caractériser un récepteur, comme un microphone par exemple, ou encore l’oreille humaine. On désigne d’ailleurs fréquemment un mi- crophone par sa directivité : un microphone «omni», «cardio», ou «bidi», s’adapte différemment au contexte de prise de son. Les HRTFs5 constituent une mesure des fonctions de directivité des oreilles.
Un processus de transmission acoustique peut donc être caractérisé à la fois par la directivité de la source et du récepteur. Par exemple, le signal perçu par les oreilles est une combinaison de la directivité d’une source sonore et de celle des oreilles, de même qu’un signal capté par un microphone est le résultat de la combinaison de la directivité de la source avec celle du microphone.
2. Méthodes de mesures
On peut déterminer la directivité d’une source sonore en partant de modèles physiques théoriques. Cela consiste à approcher le comportement vibratoire d’une source réelle par une description mathématique de la structure vibratoire. Ces modèles sont pratiques, puisqu’ils sont paramétriques, et permettent de déterminer l’influence de tel ou tel paramètre sur le résultat sonore final. Mais ils ne constituent toujours qu’une approximation de la réalité.
Une seconde approche consiste à passer par la mesure, à l’aide d’un ou plusieurs microphones, pour caractériser le rayonnement d’une source sonore. Cela soulève différentes problématiques.
2.1 Sources sonores
Il est compliqué, par la mesure, de caractériser de manière continue la surface enveloppant la source sonore, la mesure consiste en un échantillonnage spatial de cette surface, souvent sphérique (ou circulaire en 2D). Afin de reconstituer une fonction continue à partir de la mesure, il sera nécessaire d’utiliser une loi d’interpolation6.
La norme ISO 3745 [16] fournit diverses recommandations concernant les mesures de directivité de sources sonores. Il y est précisé que la mesure de directivité « s’adapte à tous types d’excitations, impulsionnelles ou continues, constantes ou fluctuantes ». La mesure peut être « simultanée », si tous les microphones captent le signal au même moment ou « séquentielle », si l’excitation est parfaitement reproductible dans le temps.
Lorsque l’excitation est parfaitement reproductible (un haut-parleur par exemple), on peut utiliser un bras mécanique afin de déplacer les microphones, ou placer la source sur un plateau tournant afin de la faire pivoter tout au long de la mesure. Cela permet en général d’augmenter la résolution du maillage.
Pour la mesure, les microphones sont dirigés vers la source et placés à équidistance de son « centre acoustique ». Le champ de pression rayonné par la source est alors capté dans les différentes directions de l’espace.
2.2 Lieux de mesure
Afin de s’abstraire des caractéristiques acoustiques du lieu (réflexions, réverbération…), les mesures sont souvent faites en chambre anéchoïque (ou semi-anéchoïque). Les conditions anéchoïques sont censées simuler des conditions de champ libre autour de la source, c’est-à-dire des conditions dans lesquelles les réflexions acoustiques sont négligeables pour la zone de fréquence étudiée (de 100Hz à 10000Hz d’après l’ISO 3745 [16]).
Les chambres « semi-anéchoïques », quant à elles vérifient les conditions de champ libre sur une demi-sphère, le sol étant recouvert par une surface rigide semi-réfléchissante. Ces dernières conditions peuvent être intéressantes dans le cas où le rayonnement de la source sonore étudiée est fortement couplé avec le sol.
Comme l’ont proposés certains chercheurs, on peut également envisager de capter le rayonnement d’une source sonore dans un contexte acoustique «réaliste» (voir Fig.2(a)), et non en conditions de laboratoire [36]. C’est d’ailleurs l’option que j’ai prise lors de l’expérience de captation menée au CNSMDP en novembre 2017 (voir I.5).
2.3 Dimensions
Lorsqu’on parle de la directivité d’une source sonore, cela sous-entend en général le champ lointain, c’est-à-dire la zone à partir de laquelle le rayonnement de la source peut être considéré comme des ondes planes. Dans l’idéal, les dimensions du système de mesure devraient donc être adaptées à celles de la source sonore.
![(a) Enregistrement en conditions acous- (b) Enregistrement en conditions anéchoïques, tiré de [28] tiques, tiré de [36]
Figure 2 – Captation de sources directives en conditions acoustiques et anéchoïques](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-220.png)
Figure 2 – Captation de sources directives en conditions acoustiques et anéchoïques
Pour cela, la norme ISO3745 définit une «dimension caractéristique de la source» (d0), exprimée en mètres. Comme on le voit sur la figure 3, il s’agit de la distance entre le centre géométrique de la source et le coin le plus éloigné de l’hypothétique «parallélépipède rectangle» qui contiendrait la source mesurée. Avec une différence entre les conditions de mesures anéchoïques et semi-anéchoïques.
À partir de cette valeur, plusieurs éléments sont à considérer pour la taille de la surface de mesure :
- le rayon (r) de la sphère de microphones doit être au moins supérieur au double de la dimension caractéristique de la source (r > 2.d0)
- le rayon de la sphère doit être au moins supérieur au quart de la longueur d’onde la plus grave émise par la source (r > 1/4 λmax)
- le rayon de la sphère doit être au moins supérieur à 1 mètre.
![Figure 3 – Dimension caractéristique de source (d0) en conditions anéchoïques (gauche) et semi-anéchoïque (droite), extrait de [16].](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-221.png)
Par exemple, pour un violon de dimensions : 21 x 9 x 60 cm, la dimension caractéristique de la source en conditions anéchoïques est : d0 = 32.1cm .
On doit donc avoir :
- r > 64.2cm
- r > 43.4cm
- r > 1m
⇾ On choisira donc une sphère de rayon > 1m.
2.4 Géométrie du système de mesure
Pour les mesures simultanées d’une source sonore par un réseau de microphones, diverses configu- rations de microphones sont envisageables afin d’échantillonner la sphère. Certaines sont régulières, d’autres non, le nombre de points de mesures peut varier également. En pratique, les principales possibilités citées par la norme ISO sont de discrétiser la sphère en utilisant des trajectoires circulaires coaxiales, méridionales, ou bien des trajectoires en spirales.
Il s’agit là de spécifications/recommandations afin de mesurer des niveaux sonores, par bandes d’octaves ou par tiers d’octaves, aux abords d’une source sonore quelconque. D’autre part, l’espacement équiangulaire avec un espacement régulier entre les microphones est le type de configuration pris en charge par la plupart des formats actuels (voir Annexe 3, « Formats de données »).
La question de la position et la répartition des microphones a également été étudiée dans une approche plus théorique par Franz Zotter dans sa thèse « Analysis and Synthesis of Sound-Radiation with Spherical Arrays » [40], dans le but de représenter la source en utilisant la base des harmoniques sphériques (voir partie 4.3 )
Il y fait état de différentes solutions pour passer de l’échantillonnage discret de la sphère à la représentation en harmoniques sphériques, avec des répartitions variées de microphones. Chacune d’elles présente des avantages et inconvénients en termes de nombre de microphones, de coût de calcul, mais surtout d’erreur générée lors du passage en harmoniques sphériques. Nous n’entrerons pas ici dans les détails mathématiques de ces solutions, la figure 4(e) montre la configuration à 64 microphones retenue par Zotter.
Enfin, chacun est libre d’adapter le système en fonction des sources sonores étudiées, de l’objectif des enregistrements, et évidemment du nombre de microphones, préamplificateurs et convertisseurs disponibles.
Si certaines sources présentent des symétries, il est possible d’effectuer la mesure sur une partie du champ, puis d’extrapoler. Des configurations à deux couronnes (Fig. 4(b)) peuvent être utilisées pour avoir une meilleure résolution sur les plans vertical et horizontal. Les étudiants « Tonmeister » de la Kunst Universität Berlin quant à eux, dans le cadre d’un projet de comparaison de position de micro- phones, ont placé des couples stéréophoniques7 autour d’une source afin de permettre à l’auditeur8 d’écouter les différentes paires de microphones en acoustique naturelle (Fig. 4(f)).
On le voit sur la figure ci-dessous, la résolution microphonique a tendance à augmenter au fil des années.

3. Spécificités des instruments de musique
Nous allons nous intéresser au cas plus spécifique de la caractérisation du rayonnement des instruments de musique. Si les premiers travaux d’envergure datent des années 1970 avec Jürgen Meyer (publiés dans [26]), des travaux ont été menés ces dernières années notamment au Danemark par Otondo et Rindel [31], en Finlande par Pätynen et al [32], en Allemagne entre Berlin et Aachen par
Pollow [35] et Vorländer, principalement à des fins de simulations acoustiques. Des recherches ont également été menées à l’IRCAM et à l’IEM de Graz [28]. Différentes bases de données sont donc disponibles, que nous pourrons exploiter par la suite.
Nous allons voir que lorsqu’il s’agit d’enregistrer et de mesurer des rayonnements d’instruments de musique, des contraintes supplémentaires adviennent et différentes options pourront être prises en fonction de l’objectif de la mesure (acoustique instrumentale, simulation acoustique, sources virtuelles…).
3.1 Reproductibilité
Nous l’avons évoqué précédemment, la question de la reproductibilité du signal sonore est importante dans le choix du système de captation. S’agissant de l’instrument de musique, des systèmes de doigts robotisés[23] ou de bouches artificielles[28] ont été développés afin de s’abstraire du jeu du musicien et de pallier à la non-reproductibilité. Ainsi, il serait possible d’utiliser une mesure de type séquentiel, et d’utiliser un nombre restreint de microphones en répétant l’excitation autant de fois que nécessaire pour quadriller tous les points de mesure.
Cependant, la plupart des études récentes ont considéré qu’il était difficile de s’abstraire du musi- cien et de son jeu, ainsi que de son corps, qui joue un rôle prépondérant dans le rayonnement lui-même (masquage de certaines zones de l’espace). La mesure «simultanée» de la directivité a donc été adoptée, avec un musicien jouant au centre d’une sphère de microphones.
Pour notre part, dans le contexte de simulation ou de production de contenus et non de l’analyse objective à des fins scientifiques, nous envisageons également le système musicien-instrument comme indissociable dans la production et le rayonnement du son.
3.2 Contenu spectral
Un autre enjeu de l’instrument de musique est qu’il n’excite pas toutes les fréquences du spectre. En effet, chaque note jouée est constituée d’une fréquence fondamentale et de ses harmoniques ou partiels. Ce contenu spectral est propre à l’instrument, auquel s’ajoute le «bruit» lié à l’action de l’instrumentiste pour produire le son (souffle, son de clefs, déplacement des doigts sur les frettes,…).
Contrairement à un signal « sweep » envoyé dans un haut-parleur, permettant d’analyser finement une réponse impulsionnelle en balayant avec la même énergie toutes les fréquences du spectre, chaque note jouée sur un instrument excite un nombre fini de fréquences.
Plusieurs approches sont envisageables à la mesure, afin d’extraire l’information sur l’ensemble du spectre. Il est possible d’exciter artificiellement l’instrument à l’aide d’un signal synthétique plat en fréquence (un bruit blanc comme l’a fait LeCarou dans [23] ou un sweep), ou en utilisant un marteau pour produire une impulsion (de type Dirac comme dans NBody Project [7]) : ces deux méthodes permettent de s’abstraire des conditions de production du son par l’instrumentiste et sont souvent utilisées pour déduire/formuler des modèles mathématiques à partir des mesures.
D’autres approches consistent à extraire l’information utile par des traitements et moyennages à partir d’enregistrements musicaux, ou effectuer une description « note à note » à partir d’enregistrements de notes isolées jouées sur l’instrument. C’est le parti pris par les chercheurs de Aachen dans
[38] Pour la construction d’une base de données de directivité de 41 instruments de musique (modernes et anciens), ils ont ensuite effectué une extraction de pics à partir du spectre afin de ne garder que l’information pertinente. Une autre approche serait d’interpoler entre les différents pics et d’extraire « l’enveloppe spectrale » de l’instrument (que l’on peut deviner sur la figure 5).
![Figure 5 – Analyses spectrales des différentes notes d’une trompette, enregistrement tiré de la base de données de Pollow et al [34]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-225.png)
Une méthode astucieuse a également été proposée par Perez Carrillo et al dans [33] pour exciter « de manière homogène toutes les fréquences sur une large zone de fréquences » en utilisant un glissendo (ce qui n’est possible que sur certains instruments).
Il s’agit là de conditions plus ou moins «écologiques» (par rapport au contexte habituel de jeu) pour étudier le rayonnement de l’instrument ou du système «musicien-instrument». Dans le cadre de l’expérimentation menée au Conservatoire (voir partie I.5), les méthodes de moyennage ont été utilisées, à partir d’enregistrements musicaux.
3.3 Mouvements du musicien
Une autre contrainte importante lors de la mesure est celle du mouvement de l’instrument. Comme nous l’avons mentionné plus haut, la source sonore doit être centrée lors de la mesure. Tout écart à cette position entraînera des variations de phase entre les signaux captés par les microphones et pourra engendrer du filtrage en peigne et des erreurs de mesure, d’autant plus grandes que l’on monte en fréquence.
Le centre acoustique de la source est défini comme « la position à partir de laquelle les ondes planes observées en champ lointain semblent diverger « , et la « position à partir de laquelle la pression diminue de manière inversement proportionnelle à la distance« [20]. Ces deux définitions étant liées à l’hypo- thèse que toute source peut être approximée par une « source ponctuelle équivalente », c’est-à-dire une source directive ramenée en un point de l’espace.
Une fois de plus, la connaissance de l’objectif de la captation doit aider à mesurer l’importance de cette erreur de mesure. S’il s’agit de mesurer la directivité en « magnitude », de petites variations de position auront peu d’influence. Mais si l’on souhaite étudier le rayonnement «complexe» de la source, les mouvements de la source peuvent être problématiques pour des questions de variation de phase.
Il est alors possible de contraindre le musicien en fixant l’instrument, ou de suivre ses mouvements à l’aide d’un dispositif de tracking et de les compenser en post-traitement sur le signal capté (type de dispositif utilisé lors des mesures de HRTFs). Différentes approches algorithmiques ont été proposées pour le recentrage acoustique de sources en rotation et translation, notamment par Deboy[10] et Ben Hagai et al[4].
La figure suivante montre une source omnidirectionnelle avant et après recentrage :
![Figure 6 – Diagramme de rayonnement d’un monopole à 1000Hz décalé de 30cm, avant et après recentrage acoustique, tiré de [10]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-226.png)
Pour les instruments plus volumineux, souvent moins mobiles, le problème du mouvement se posera moins, mais la difficulté sera de déterminer précisément le centre acoustique de la source, et de disposer d’une chambre assez grande pour accueillir les mesures.
Quoi qu’il en soit, les musiciens (humains) ont tendance à bouger, plus ou moins selon les instruments et le répertoire. Qu’il s’agisse d’interagir avec l’acoustique du lieu ou de créer du mouvement dans le son, ces mouvements font partie intégrante de l’interprétation et doivent être pris en compte s’il s’agit d’une application artistique.
Nous verrons dans la partie II.7 deux scénarios de prise de son possibles dans lesquels la directivité des sources est prise en compte, le caractère « dynamique » de la directivité pouvant être simulé à la restitution.
4. Analyses et représentations
4.1 Les grandeurs objectives de la directivité
Les scientifiques s’appliquent à mettre en place des critères et formulations afin de décrire les différents paramètres du son. Pour parler du niveau sonore, on peut utiliser la sonie (ou « loudness« ), les dB pondérés A, B, C, LU, VU, pour s’adapter aux finesses de la perception. Pour la description du timbre, on peut parler du spectre, moyenné par octave ou 1/3 d’octave, de l’enveloppe temporelle, de l’enveloppe spectrale, des formants. . . La directivité présente également quelques critères d’apprécia- tion et descripteurs pertinents. Nous en citerons quelques uns :
- Le facteur de directivité[13] : Souvent calculé dans l’axe principal de la source, il permet de juger de la répartition spatiale de l’énergie, ou du degré de proéminence d’une direction de l’espace. Il s’agit donc du rapport entre l’intensité rayonnée dans une direction donnée (Iref ) et l’intensité moyenne9 rayonnée sur l’ensemble de la sphère (Imoy) :
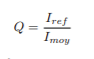
Sa valeur sera égale à 1 pour une source parfaitement omnidirective.
- L’indice de directivité quant à lui, défini dans la norme ISO-3745 est le facteur de directivité exprimé en dB :
ID = Laxe — Lmoy = 10.log(Q)
Avec Laxe le niveau sonore moyen dans l’axe, et Lmoy le niveau sonore moyen sur l’ensemble de la sphère.
- L’indice de «non-uniformité du niveau sonore sur la surface » : défini dans l’ISO-3745 [16], cet indicateur permet d’évaluer la variabilité en niveau du champ sonore sur la surface de mesure. On peut le calculer par la formule suivante :
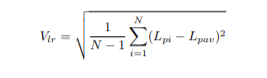
- Lpi la pression moyenne au niveau du ième microphone (en dB).
- Lpav la moyenne des pressions évaluée sur toute la surface de mesure (en dB).
- N le nombre de microphones sur la surface.
Pour une source omnidirective, sa valeur sera donc nulle.
- L’angle d’ouverture à n dB :
Cette valeur est parfois indiquée par les fabricants d’enceintes, à -3dB ou -6dB (« directivité nomi- nale »). Il s’agit de l’angle, par rapport à l’axe principal de directivité, à partir duquel le niveau sonore est à n dB en dessous du niveau dans l’axe.
Il permet de juger de la directivité d’une enceinte, ou au contraire de sa large ouverture. Cette valeur est parfois donnée par bande de fréquence ou pour une fréquence donnée. En effet, l’angle d’ouverture sera en général d’autant plus faible que l’on monte en fréquence.
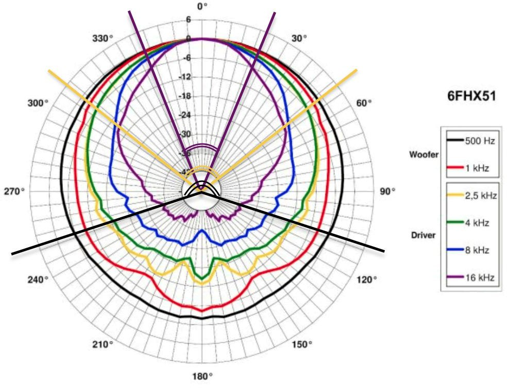
Sur la figure ci-dessus, représentant le diagramme de directivité du haut-parleur coaxial 6FHX51 du fabricant B&C10, on peut observer les angles d’ouverture à -6dB à différentes fréquences.
- Le «front to back factor» et le «front to side factor» :
Ces critères, utilisés dans la description des antennes (réseau de capteurs répartis suivant une géo- métrie particulière) sont évoqués par J.Meyer (dans « Acoustics and the Performance in Music« ) pour exprimer la répartition spatiale de l’énergie selon les directions « avant-arrière » (F/B) ou « avant-côtés » (F/S). Cela implique de définir une orientation de référence pour la source, à partir de laquelle seront calculés les rapports d’énergie entre la direction avant, arrière, gauche et droite.
Typiquement, le « front to back factor » permettra de différencier un cor (pavillon orienté vers l’arrière) d’un trombone (pavillon orienté vers l’avant) : (F/B)cor < 0 < (F/B)trombone
On les note :
F/B = 10.log(Iavant) — 10.log(Iarriere)
F/S = 10.log(Iavant) — 10.log(Icotes)
4.2 Les représentations visuelles
Une fois la mesure effectuée, vient la question de la représentation visuelle.
Comme nous l’avons souligné en première partie, la directivité est une fonction présentant plusieurs dimensions : spatiales (2D ou 3D), spectrales (résolution fréquentielle, octaves ou 1/3 d’octaves) et éventuellement la phase.
Jürgen Meyer est l’un des premiers à avoir mesuré, décrit, et représenté le rayonnement des instru- ments de l’orchestre, et a donc été confronté au problème de la représentation multidimensionnelle de la directivité en 2D, afin d’illustrer son ouvrage « Acoustics and the Performance of Music » [26].
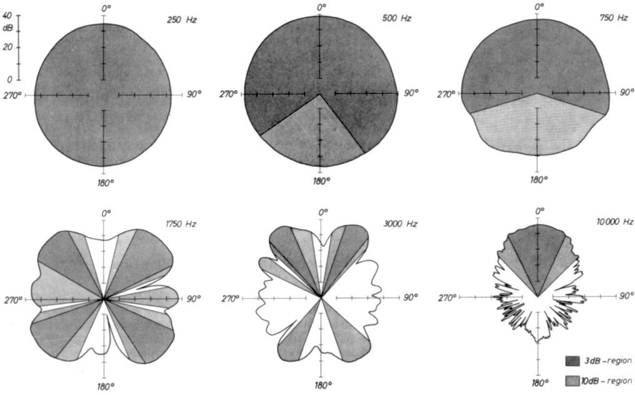

Figure 8 – Deux types de représentations « polaires », en 2D et en 3D
Le diagramme polaire est utilisé par Meyer pour représenter, à une fréquence donnée et pour une certaine plage dynamique, la répartition spatiale de l’énergie dans le plan horizontal (fig. 8(a)). C’est une représentation très répandue aujourd’hui, notamment pour visualiser les caractéristiques des microphones.
Selon le même principe, Meyer propose également une représentation tri-dimensionnelle en effectuant des coupes dans certaines directions de l’espace (fig. 8(b)) : un plan horizontal, le plan vertical «avant-arrière», le plan vertical «gauche-droite», et le plan vertical dans l’axe de l’instrument.
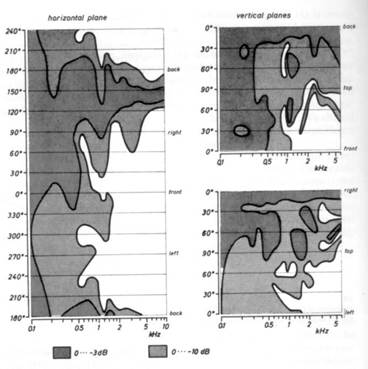
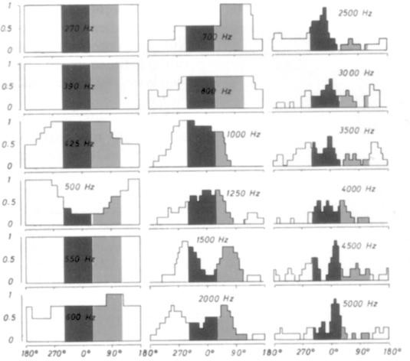
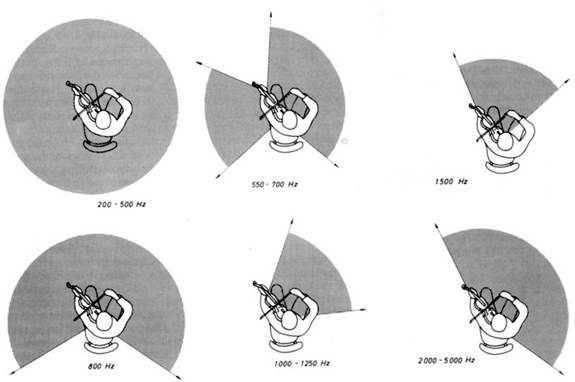
Figure 9 – Trois types de représentations utilisées par Meyer
Une autre option est de présenter le diagramme de directivité projeté sur un plan, dans les diffé- rentes directions. Comme on peut le voir sur la figure 9(a), le niveau sonore est moyenné par plages de 0 à -3dB, de -3 à -10dB, puis en deçà. Si cette représentation a l’avantage de présenter simultanément les 3 variables (espace, fréquence, niveau), elle paraît moins directe à la lecture que la diagramme polaire, auquel nous sommes plus habitués.
Des histogrammes sont également utilisés par Meyer, où il moyenne par angle (Fig. 9(b)).
La visualisation proposée par Meyer qui a été la plus reprise dans différents ouvrages est sans doute celle présentée en figure 9(c). On y voit, pour certaines fréquences spécifiques, la zone où le niveau est maximum, sur une plage de 3dB. C’est sans doute la visualisation la plus simple du rayonnement, mais peu précise, car elle ne présente qu’un niveau moyen (0 à -3dB) pour une fréquence donnée, et dans un plan particulier.
Comme on le voit dans la démarche menée par Meyer, la question de la représentation n’est pas simple au vu du nombre important de variables en jeu. On peut aujourd’hui facilement tracer par des méthodes numériques différents types de représentations, en 2D et 3D, mais la question du choix des paramètres reste importante : il s’agit souvent d’un compromis entre précision, complexité et lisibilité.
4.3 Les harmoniques sphériques
L’ensemble des configurations de captation que nous avons présentées jusqu’ici possède des symétries sphériques. Un domaine parfaitement adapté au stockage et à la description des signaux captés est donc celui des harmoniques sphériques, que nous allons présenter ici.
Un signal temporel possède un spectre propre et peut se décomposer en une série de sinusoïdes. Dans le cadre du calcul informatique, on utilise la transformée de Fourier discrète (TFD) pour passer du domaine temporel (s(n)) au domaine fréquentiel (S(k)) :
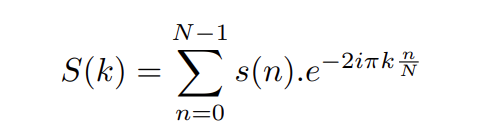
avec n l’indice temporel, k l’indice fréquentiel, N le nombre de points considérés. La transformée de Fourier inverse (IFT), permet quant à elle, permet de repasser du domaine des fréquences au domaine temporel.
Le même raisonnement peut s’appliquer à des fonctions dépendant de variables spatiales. Une fonction continue exprimée en coordonnées sphériques possède un spectre sphérique (« Spherical Wave Spectrum« ) et peut se décomposer en une série d’harmoniques sphériques, en utilisant la transformée en harmoniques sphériques (« Discrete Spherical Harmonic Transform« , DSHT) :
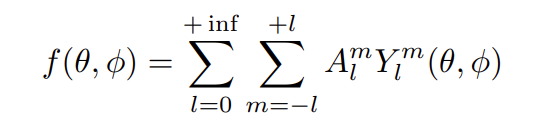
Où Am est un coefficient de pondération, Y m est l’harmonique sphérique d’ordre l et de degré m, définie à l’aide du polynôme de Legendre Pm, donnée11 par :
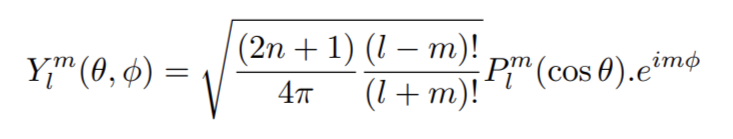
La transformée en harmoniques sphériques inverse permet l’opération de retour dans la base angulaire.
On peut visualiser les 16 premières harmoniques sphériques sur la figure (Fig.10) ci-dessous :
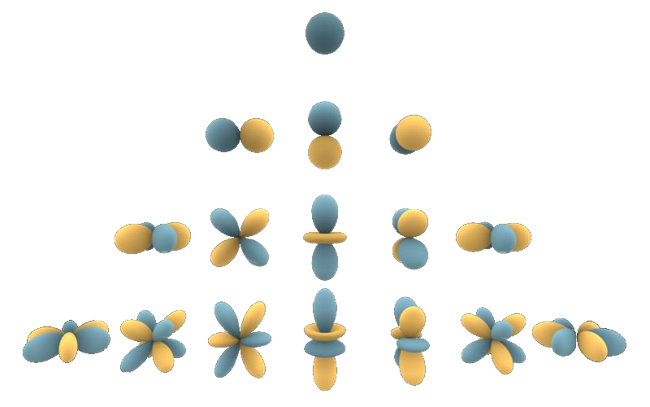
La décomposition en harmoniques sphériques est un outil mathématique utilisé dans différents domaines, pour l’analyse et la manipulation de données spatiales en coordonnées sphériques, notamment pour la topographie ou encore la cosmologie.
L’exemple suivant illustre l’utilisation des harmoniques sphériques pour l’analyse de données to- pographiques terrestres. Sur la figure 11, la carte topographique terrestre est d’abord analysée, puis tronquée à différents ordres. On peut y observer la contribution des différentes harmoniques sphériques sur le résultat final.
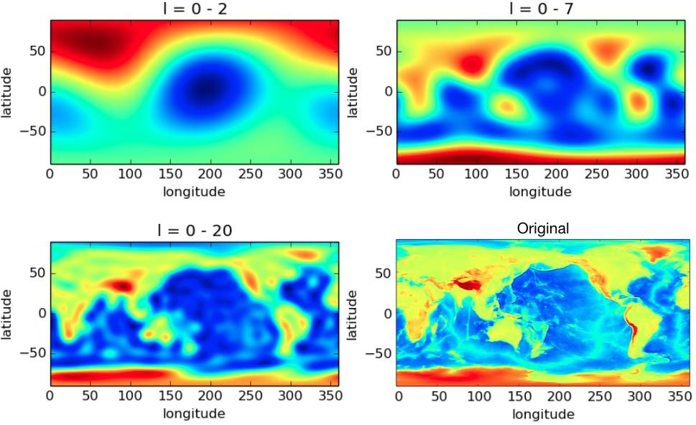
En acoustique physique, les harmoniques sphériques sont couramment utilisées dans la résolution de l’équation d’onde en coordonnées sphériques, lorsqu’il s’agit de décrire le champ sonore entrant ou sortant sur une surface donnée [9]. Mais également pour l’analyse du rayonnement de sources sonores, comme l’a fait Weinreich dès 1980 [39].
L’approche ambisonique
Michael Gerzon a été le premier, dans les années 70, à proposer d’utiliser une version tronquée du formalisme des harmoniques sphériques pour la captation, le stockage, la manipulation, et la restitution du champ sonore en un point de l’espace [12] [14]. En son temps, Gerzon s’est restreint aux quatre pre- mières harmoniques sphériques, dont les figures de directivité correspondent à celles de microphones réels courants (omnidirectionnel et bidirectionnel). Le format de stockage correspondant est appelé « B-Format « , ou encore « Ambisonique d’ordre 1 ».
Le format Ambisonique présente l’avantage d’être indépendant du système de prise de son et de restitution. On peut en effet encoder un microphone ou spatialiser des sources sonores, considérées alors comme des ondes planes convergentes. Le décodage peut être fait aussi bien sur un système de haut-parleurs qu’au casque, au travers de traitements binauraux.
Dans les années 2000, Jérôme Daniel (dans [8]) a contribué à étendre l’approche ambisonique aux ordres supérieurs, avec le format HOA (« High Order Ambisonics« ). Il s’agit d’utiliser un nombre plus important d’harmoniques sphériques, donc d’augmenter la résolution de description du champ sonore décrit, et d’élargir le « sweet spot » lors de la restitution sur haut-parleurs.
En pratique, plus l’ordre augmente, plus le nombre de microphones à la captation et de haut-parleurs à la restitution doit être élevé. Pour la captation de scènes sonores à ce format, on peut utiliser des microphones dits « Ambisoniques » ou « HOA », composés d’un nombre de capteurs du même ordre de grandeur que le nombre de composantes de l’ordre HOA cible.
Le formalisme des harmoniques sphériques peut également servir à décrire des rayonnements de sources sonores. C’est l’approche que nous développerons dans la deuxième partie à travers le HOOF (High Order O-Format).
La figure suivante (Fig.12) présente plusieurs systèmes microphoniques ambisoniques, depuis les années 1970 avec Gerzon jusqu’à aujourd’hui.

5. Enregistrement au CNSMDP
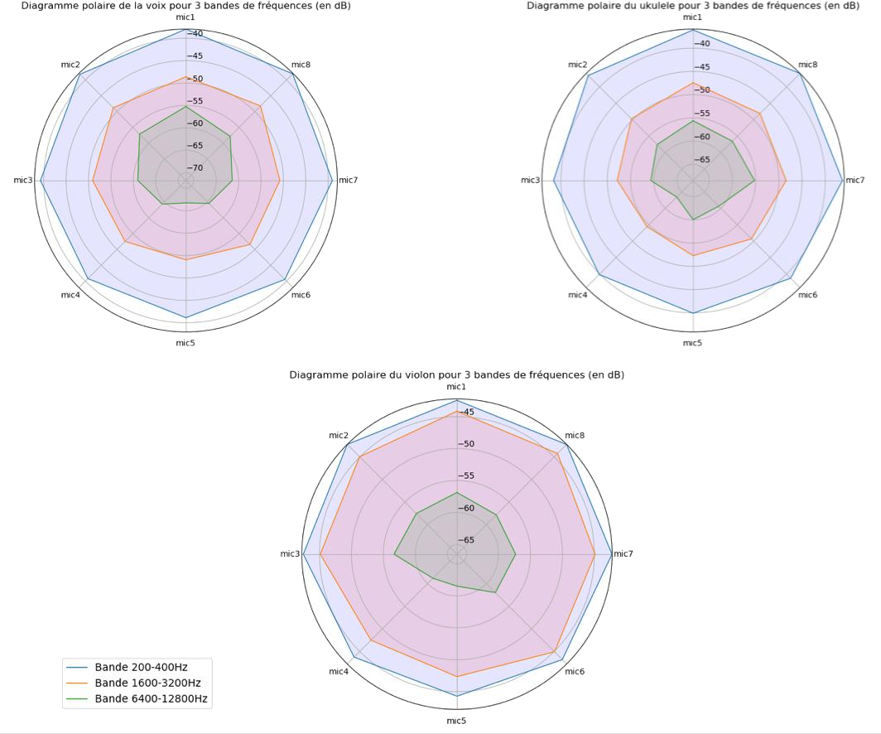
Dans le cadre de ce mémoire, un enregistrement a été réalisé en novembre 2017 au CNSMDP, afin de capter différentes directivités de sources sonores et de créer de la matière de travail. Cette expérimentation en conditions d’acoustique « réelle » a eu lieu dans la salle du Grand Plateau d’orchestre, où 8 microphones Schoeps MK4 (cardioïdes, afin de limiter l’effet de salle) ont été régulièrement disposés sur un plan horizontal circulaire, pointant vers le centre du cercle (voir Fig.13). Cette version 2D a servi de première approche, simple à mettre en place, avant l’expérimentation finale en 3D.
Plusieurs types de sources ont été enregistrées (une voix, un ukulele, un violon et une enceinte Yamaha HS7) à trois distances différentes de la source (70cm, 1m et 2m).
La source vocale était de type parlée, à un niveau « conversationnel » (lecture d’un texte d’environ 30 secondes). Le ukulele était joué en strumming, sur une grille harmonique de quatre accords durant 45 secondes. Le violon était joué par Shuichi Okada, violoniste au CNSMDP, interprétant la Chaconne de J.S. Bach (un extrait de 45 secondes a été sélectionné pour les analyses). Le haut-parleur, placé sur un pied à hauteur des microphones, a été excité avec un sweep afin de pouvoir en tirer une réponse impulsionnelle de source directive (ou « masque de directivité » comme nous le verrons en Partie II. 7.2).

Cette séance a été réalisée de manière assez empirique, mais a permis de prendre conscience de certaines difficultés pratiques dues à la prise multi-microphonique de sources directives. Notamment, la précision dans le placement des microphones et le centrage précis de la source.
Les limites d’une telle prise de son « millimétrée » sont apparues. Le placement des microphones a été effectué suivant des critères « géométriques » et non pas en fonction de la source12. Le timbre résultant dans les différents microphones était d’assez piètre qualité. Il serait d’ailleurs intéressant de réfléchir à une approche plus « qualitative » de la captation multi-microphonique de rayonnement, basée sur l’écoute et adaptée à la source. Reste à savoir si les modèles géométriques sont compatibles avec le plus traditionnel placement « à l’oreille ».
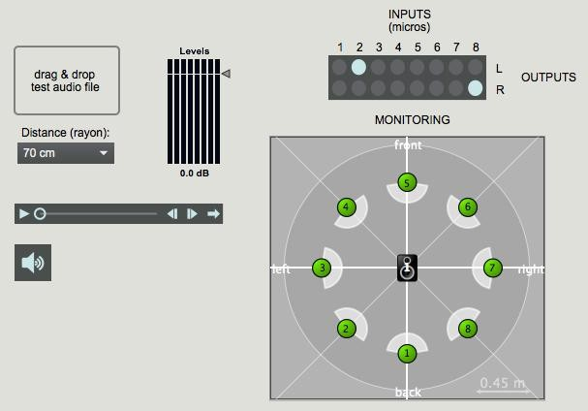
Toutefois, il est intéressant de pouvoir écouter les microphones aux différentes positions autour de l’instrument. La réponse directionnelle du haut-parleur a également donné des résultats très crédibles par simple convolution avec différents signaux monophoniques. Un patch Max/MSP de monitoring a été créé à cet effet (voir Fig.14).
Il était par ailleurs encourageant de constater que des analyses sommaires (effectuées à partir des en- registrements), même en conditions non-anéchoïques avec 8 microphones sur un plan, montrent déjà des résultats intéressants.
La figure 15 montre que l’ensemble des sources voient leur directivité s’affiner dans les hautes fré- quences, et on peut observer la direction des sources lors de la prise de son (voix en face, ukulele et violon vers le micro 8). L’analyse spectrale a été effectuée en moyennant par bandes d’octaves, sur toute la durée des extraits musicaux sus-cités. Les analyses de la figure 15 ont été tracées grâce au script Python « Plotpolar_Averagespectrum.py », disponible en Annexe.
Ces enregistrements nous serviront également à tester, dans la seconde partie, les différentes mé- thodes développées pour le processus d’encodage/décodage HOOF.
Deuxième partie : le HOOF (High Order O-Format) : un format pour le rayonnement
6. Introduction du format HOOF
Le format ambisonique (introduit dans la partie 4.3) connaît aujourd’hui un fort intérêt, notamment pour la diffusion de vidéos 360° sur internet, et pour la réalité virtuelle. La mise sur le marché de nouveaux microphones ambisoniques, et le développement de solutions logicielles dédiées à la post-production ambisonique ont permis une certaine démocratisation de ce formalisme et son usage à des fins créatives.
Ce contexte de foisonnement autour des nouveaux formats audios « spatialisés » semble être une opportunité pour introduire une dimension supplémentaire rattachée aux sources sonores : celle de leur directivité. On parle en effet de « son 3D », ou « d’audio 360 », mais les sources avec lesquelles travaillent les ingénieurs du son jusqu’ici sont la plupart du temps omnidirectionelles.
À cela, j’ai eu l’idée d’ajouter la dimension de rayonnement des sources sonores sous forme d’harmoniques sphériques est venue d’une part, de l’utilisation croissante du format ambisonique, et d’autre part, des représentations visuelles des lobes de directivité d’instruments de musique en harmoniques sphériques fréquemment utilisées dans la littérature. Après quelques recherches bibliographiques, j’ai pu constater que cette approche avait déjà quelques antécédents qui méritaient d’être développés, notamment à l’ordre 1 avec le O-Format, d’où le HOOF (High Order O-Format) a tiré son nom13.
Les méthodes (et scripts Python associés) présentées dans cette partie ont été mises en place dans le cadre de ce mémoire. Elles constituent des premiers cas d’usages fonctionnels et proposent des pistes à explorer, mais ne sont en aucun cas une vérité absolue et définitive sur l’utilisation du format HOOF.
6.1 Le O-Format
Le O-Format peut être vu comme le « B-Format de la directivité ». Il a été introduit par Dylan Men- zies en 1999 dans sa thèse « New Electronic Performance Instruments For Electroacoustic Music » [24]. Il s’agit d’une méthode alternative aux « SoundCones« 14 pour manipuler des directivités de sources virtuelles de manière compacte. Dans un article datant de 2002 [25], Menzies détaille quelques aspects du O-Format, en décrivant des outils à mettre en œuvre pour ce format qui n’a jusqu’ici pas suscité un grand intérêt.
L’encodage vers le O-Format peut être fait à partir d’un enregistrement, ou par synthèse à partir de filtres. Menzies évoque déjà la possibilité créative de travailler avec des réponses impulsionnelles d’objets sonores stockées directement sous forme d’harmoniques sphériques : c’est ce qu’il appelle les « modèles de résonance ». Il évoque même la possibilité d’utiliser un enregistrement en B-Format de manière détournée, pour décrire des sources sonores directives.
Le rendu (l’écoute) d’une source encodée en O-Format se fait en sommant les contributions des différentes harmoniques sphériques (W,X,Y,Z) dans la direction « source-récepteur ». Une astuce est également proposée par Menzies pour ajouter une largeur à la source à l’aide du paramètre de « domi- nance » utilisé en ambisonique.
Menzies est conscient des limites du O-Format pour décrire des sources très directives (par rapport aux « SoundCones » par exemple), et note même la possibilité de monter en ordre afin d’augmenter la résolution de la description, mais « les coûts [de calcul] seraient trop élevés en comparaison aux gains apportés, de même que pour l’ambisonique d’ordre supérieur » (HOA).
Puisque le O-Format est le « B-Format de la directivité« , le HOOF peut être considéré comme le « HOA de la directivité« .
6.2 Avantages de l’approche en harmoniques sphériques
Si le O-Format n’a pas connu de grand succès en son temps, différentes raisons portent à croire que le contexte actuel puisse y être plus favorable.
La limite du coût de calcul évoquée par Dylan Menzies n’est plus d’actualité. De plus, l’architecture des stations de travail a évolué avec l’intégration de bus « ambisoniques » pour la majorité d’entre elles (qui étaient limitées jusqu’ici aux systèmes multicanaux traditionnels : stéréo, 4.0, 5.1 et 7.1) et d’outils permettant la manipulation d’une scène sonore au format ambisonique. Des effets associés à la représentation sphérique sont également disponibles (effets de focus, compression/EQ par beam,…), et ouvrent la voie à de nouvelles expérimentations créatives.
Les différentes motivations quant à l’utilisation d’un format en harmoniques sphériques pour dé- crire des directivités de sources se résument en quelques points :
- Rétrocompatibilité à l’ordre 0 (source omnidirectionnelle).
- Format compact et homogène (≥ 4 canaux pour décrire l’ensemble du champ sonore sphérique)
- Adaptabilité/scalabilité de la résolution (l’ordre ambisonique) aux besoins et aux capacités.
- Agnostisme du format au système de captation et de restitution.
- Démocratisation du formalisme ambisonique chez les ingénieurs du son qui n’existait pas lors des prémices du O-Format, et stations de travail compatibles (bus ambisoniques).
- Maléabilité du format pour l’application d’effets, multitude d’outils préexistants pour le HOA réutilisables (plugins ambisoniques, voir partie 8.1).
- Possibilités éventuelles de compression en utilisant des algorithmes développés pour le HOA15.
- Antécédents scientifiques à la représentation harmonique sphérique des figures de directivité.
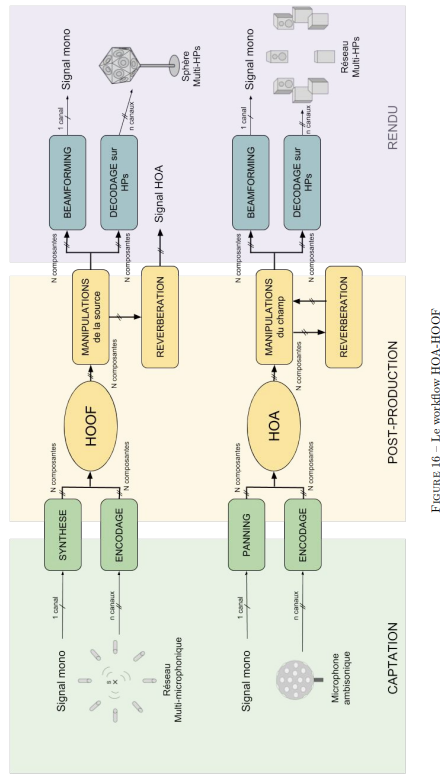
Dans cette partie, nous allons détailler les trois grandes étapes de l’utilisation du HOOF dans une production audio « spatialisée ».
La captation, est l’étape par laquelle la matière sonore va être captée par des microphones sous forme de signal audio, la post-production est celle au cours de laquelle la matière captée va être transformée, puis mixée, et enfin l’étape de rendu consiste en la restitution du résultat sonore sur un système de haut-parleurs ou au casque.
La figure suivante illustre ces trois grandes étapes, en proposant un parallèle entre le HOOF et le HOA, pour repérer les similitudes et les différences entre ces deux formats.
7. Captation HOOF
Comme on peut le voir sur le schéma précédent (Fig. 16), le format HOOF peut être obtenu de deux manières différentes : par la captation multi-microphonique d’une source directive ou par synthèse à partir d’une source monophonique.
Les deux approches présentent chacune leurs avantages et inconvénients : la captation multi-micro phonique permet d’accéder à la directivité « réelle » de la source, de manière dynamique, mais nécessite un nombre plus important de microphones, alors que la synthèse consiste à appliquer une directivité ar- bitraire déterminée par l’ingénieur du son, mais ne requiert qu’un seul microphone lors de la captation.
En pratique, si l’on souhaite créer une scène sonore à 6 degrés de liberté faisant intervenir des sources directives, deux scénarios de prise de son sont possibles :
- Chacune des sources est enregistrée par un système multi-microphonique, en re-recording16, éventuellement en conditions anéchoïques, puis mixée au sein d’une scène sonore.
- Les sources sont enregistrées simultanément par des microphones d’appoint placés en proximité, et un masque de directivité est appliqué à chacune d’elle. Des capteurs de mouvements peuvent alors être utilisés pour restituer le mouvement des instruments dans la scène finale.
7.1 Enregistrement multi-microphoniques
Dans le cas du scénario 1, il faudra encoder en HOOF les différentes sources sonores, chacune enregistrée avec un système multi-microphonique. Pour cela, il sera nécessaire de trouver une matrice d’encodage permettant de passer du domaine discret des microphones au domaine HOOF.
Nous l’avons vu dans la partie I.2.4, différentes configurations de microphones sont envisageables pour la captation du rayonnement d’une source sonore. Un parallèle peut être fait entre le décodage HOA sur un ensemble de haut-parleurs, et l’encodage HOOF d’une configuration de microphones, pour laquelle il faudra calculer une matrice d’encodage spécifique. La résolution de la description dépend du nombre de microphones utilisés pour l’échantillonnage de la sphère (ou du cercle en 2D).
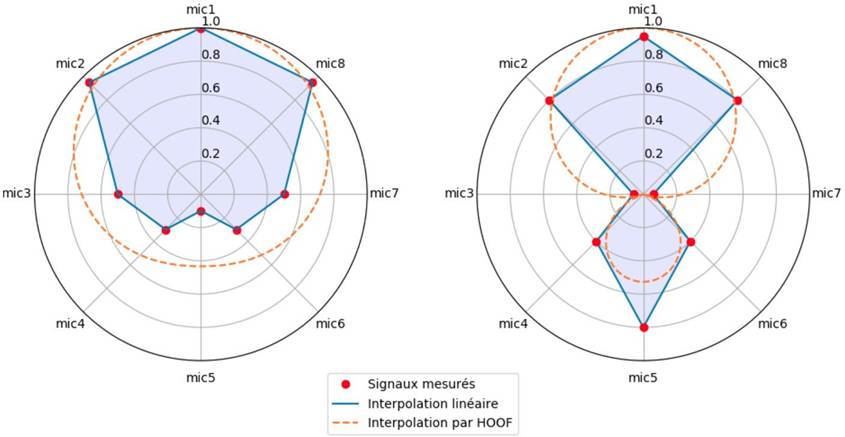
Le format HOA, via un processus de « panning-ambisonique »/décodage, peut être considéré comme une loi de panning entre les haut-parleurs. Le passage par le format HOOF à partir d’un enregistrement multi-microphonique fournit quant à lui une loi d’interpolation17 entre les microphones afin de passer d’une description discrète à une description continue du rayonnement de la source18.
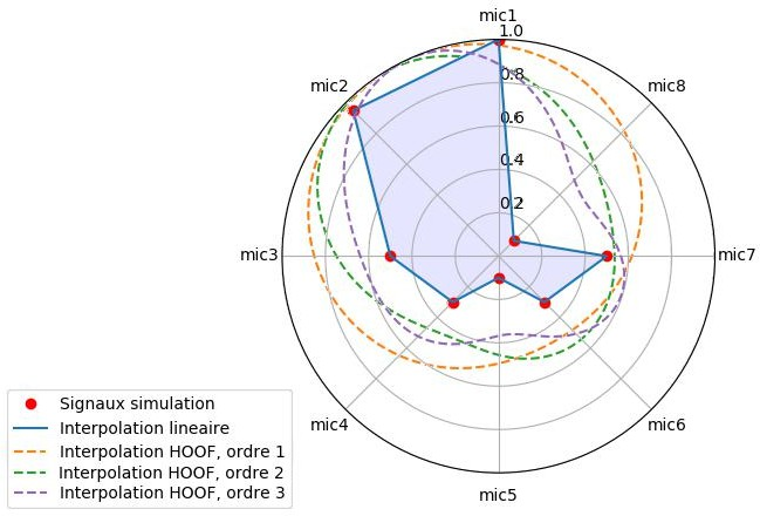
La figure suivante illustre la « loi d’interpolation » du format HOOF, après encodage d’une configuration régulière de 8 microphones. Le script Python « Interpolation_HOOF_o123.py » utilisé pour générer ces figures est disponible en Annexe.
Nous allons maintenant aborder le calcul des matrices d’encodages, permettant de passer d’un format de microphones discrets au format HOOF.
Encodage d’une configuration 2D, à l’ordre 1
On souhaite décrire une source rayonnante comme une combinaison linéaire d’harmoniques sphériques. Connaissant les signaux captés par les microphones (SMic) entourant la source, on cherche les signaux correspondant aux composantes (SW , SX, SY ), tels que :
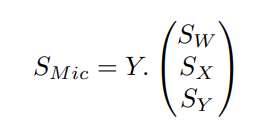
Y étant la matrice décrivant les contributions des harmoniques sphériques dans les directions des microphones, données par l’équation (1) en première partie. Pour une configuration de n microphones placés sur un plan aux angles
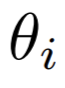
on aura donc :
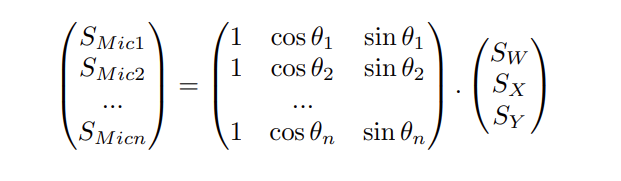
Afin de limiter la perte d’information lors de la captation de la figure de directivité de la source, il faut que le nombre de microphones (n) soit au moins égal au nombre de composantes harmoniques sphériques. C’est-à-dire, à l’ordre N, il faut que n ≥ (2N + 1) en 2D.
Il faudra donc : n ≥3 microphones à l’ordre 1, n ≥5 microphones à l’ordre 2, n ≥7 microphones à l’ordre 3, n ≥9 microphones à l’ordre 4, etc… Afin de passer des signaux microphoniques à la base des harmoniques sphériques, on cherche une matrice Y —1 telle que :
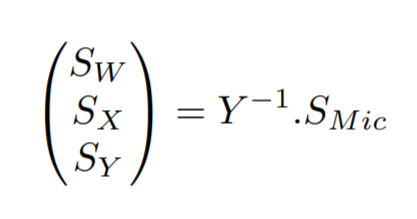
La base des harmoniques sphériques, décrite par Y, présente une propriété d’orthogonalité, les colonnes des Y sont donc linéairement indépendantes. On peut utiliser la méthode de la « pseudo-inverse » afin d’approcher Y —1 par une pseudo-inverse à gauche de Y :
Pinv(Y ) = (Y T .Y )—1.Y T
La matrice obtenue, spécifique à la configuration des microphones, permet de passer des signaux des microphones au domaine des harmoniques sphériques. Concrètement, on peut l’utiliser pour convertir un enregistrement multi-microphonique en source HOOF 2D.
Généralisation de l’encodage en 3D, à l’ordre N
On souhaite généraliser au cas d’une source rayonnante au centre d’une sphère de n microphones (SMic) entourant la source. À l’ordre N, on cherche les signaux correspondant aux (N+1)2 composantes harmoniques sphériques, tels que :
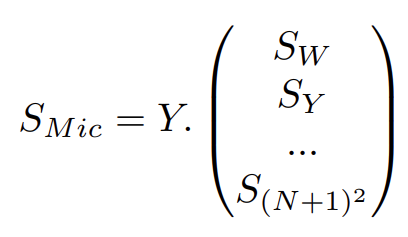
Y étant la matrice décrivant les contributions des harmoniques sphériques dans une direction
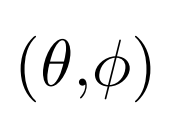
donnée. Pour une configuration de n microphones placés aux angle
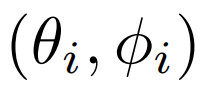
on aura donc :
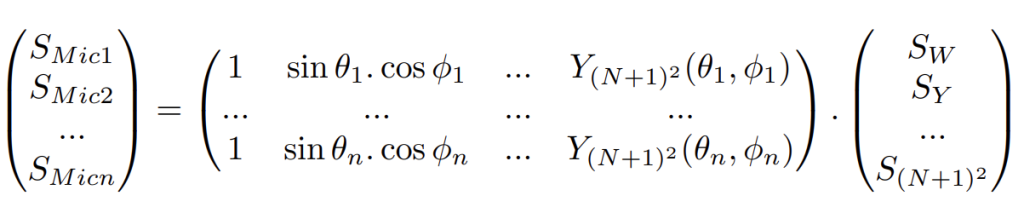
En 3D, le nombre de microphones doit vérifier : n ≥ (N + 1)2. Il faudra donc : n ≥4 microphones à l’ordre 1, n ≥9 microphones à l’ordre 2, n ≥16 microphones à l’ordre 3, n ≥25 microphones à l’ordre 4, etc…
On cherche à calculer la matrice permettant de passer des signaux microphoniques à la base des harmoniques sphériques, on cherche une matrice Y —1 :
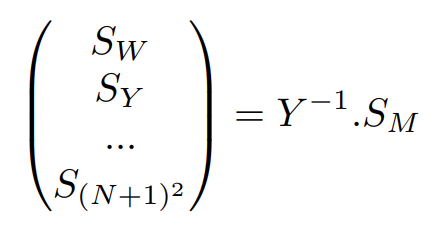
On peut également utiliser la méthode de la pseudo-inverse, de même qu’en 2D, qui nous permettra d’encoder une certaine configuration de microphones dans le domaine des harmoniques sphériques.
Grâce à ces matrices d’encodage, il est donc possible de produire des sources HOOF à partir de sources directives enregistrées.
Le script « EncodageHOOF_o123_3D.py » présenté en Annexe permet de générer une matrice d’encodage à l’ordre 1, 2 ou 3, à partir d’une configuration de microphones, et d’encoder les signaux dans le format HOOF 3D.
La figure suivante (Fig. 18) montre l’influence de l’ordre HOOF pour l’encodage d’une figure de directivité captée par 8 microphones sur un plan 2D. On remarque que plus l’ordre est élevé, plus la figure d’interpolation HOOF s’ajuste à la figure de directivité « captée ».
Considérations pratiques
Comme nous l’avons évoqué, un nombre minimum de microphones est requis afin d’encoder une source à un ordre HOOF donné (comme dans le cas des capsules nécessaires à la conception d’un microphone HOA). Trois cas sont envisageables :
- Si ce nombre n’est pas atteint, le champ environnant la source sera « sous-échantillonné », et le problème « sous-déterminé », ce qui conduira à des coefficients HOOF incohérents.
- Lorsque le nombre de microphones est égal au nombre de composantes HOOF, l’échantillonnage est dit « critique » : la solution au problème sera exacte pour cette position de microphones mais ne sera pas robuste à la rotation par exemple, comme on peut l’observer sur la figure 19.
- Lorsque le nombre de microphones est supérieur au nombre de composantes HOOF, la source est « sur-échantillonnée », le problème est alors « sur-déterminé », c’est-à-dire qu’il n’y a pas de solution exacte, mais l’approximation du champ est potentiellement meilleure en augmentant le nombre de microphones.
Il est donc nécessaire d’adapter le système à la source à capter. C’est là que l’écoute et la connaissance du rayonnement des instruments de musique peut se révéler utiles. En effet, pour capter certains instruments comme les petites percussions (shakers, triangle, claves…) au rayonnement omnidirectionnel, il est démesuré d’utiliser un système de 64 microphones. Mais pour des instruments à cordes par exemple, dont la table d’harmonie génère un rayonnement plus complexe, il peut être utile d’augmenter au maximum le nombre de capteurs, afin d’approcher au mieux la réalité.
Les limitations pratiques du nombre de microphones disponibles, de voies de pré-amplificateurs, convertisseurs, d’espace disponible, temps de montage du système, etc… rentrent également dans l’équation. Suivant l’application et le débit disponible, il sera donc parfois plus intéressant de se restreindre à la version 2D du HOOF, moins gourmande et parfaitement valide sur le plan horizontal.
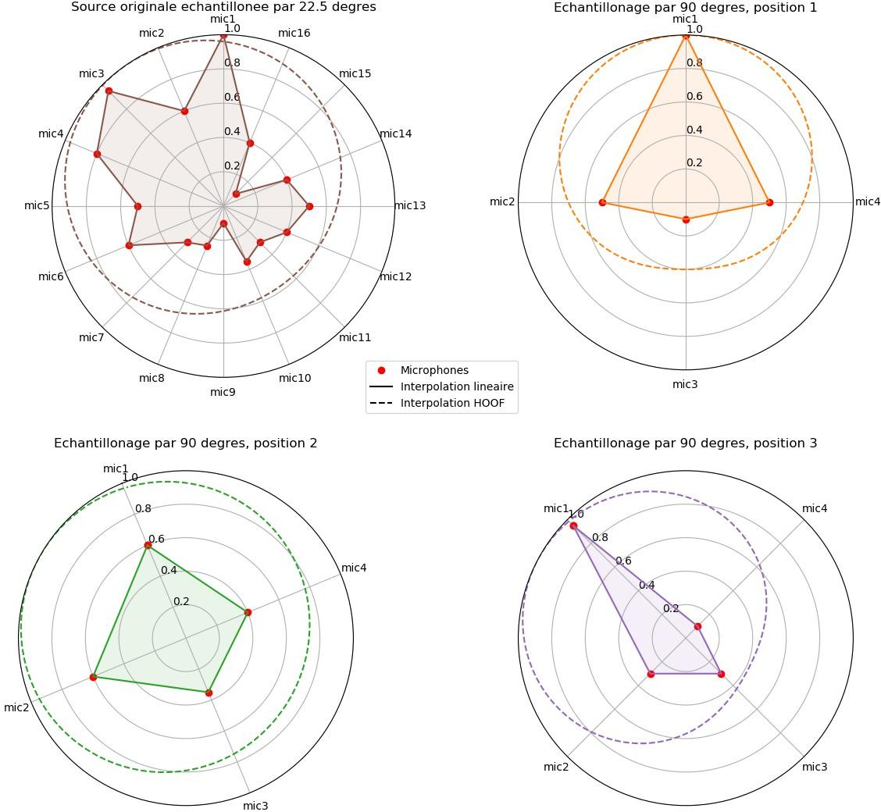
Comme on le voit sur la figure ci-dessus (fig.19), la sous-estimation du nombre de microphones nécessaires à la captation peut conduire à des résultats incohérents. Pour cette source dont la fonction de directivité présente des variations à une fréquence spatiale élevée (fréquence angulaire de 22,5°), un échantillonnage tous les 90° ne sera pas suffisant, ou du moins pas robuste à une rotation du système.
Les options possibles sont donc d’augmenter le nombre de microphones, ou de répartir les microphones à des points « stratégiques » du rayonnement de la source. C’est-à-dire aux endroits présentant les variations les plus extrêmes : les creux et les pics de la figure de directivité.
7.2 Synthèse par masque de directivité
Dans le cas du scénario 2, le son de chacune des sources est capté par un microphone en proximité. Afin de créer une directivité propre à chaque source, deux méthodes sont envisageables : il s’agit soit d’appliquer un « masque de directivité » issu de mesures à la source, soit de « sculpter » sa directivité à l’aide de filtres manuels, c’est ce qu’on pourrait appeler une « égalisation spatiale« .
Synthèse par masque
Le concept de « masque de directivité » est assez direct : il s’agit d’appliquer un masque à un signal monophonique, afin de lui attribuer la directivité d’une source réelle.
Concrètement, il s’agit d’appliquer à la source un ensemble de filtres19, pondérant chaque composante harmonique sphérique pour coller à la directivité de la source initiale. Ce type de modèle SIMO (« Single Input Multiple Output) a été décrit par Franz Zotter dans sa thèse[40], et pourrait être résumé dans le domaine temporel par la formule suivante :
e(t)* Mask = s(t)
Avec e(t) le signal d’entrée monophonique, Mask le masque de directivité (vecteur de filtres : linéaire et invariant dans le temps), et s(t) les n composantes HOOF en sortie.
Nous utiliserons ici des filtres de type FIRs20, mais il est également possible d’envisager une implémentation à l’aide de filtres paramétriques.
Comme on le voit sur la figure ci-dessous, pour générer un masque de directivité à partir d’une source réelle captée au sein d’un ensemble de microphones, deux cas peuvent se présenter :
a) On a accès à l’enregistrement acoustique d’un signal quelconque émis par une source sonore (voix par exemple), capté dans une direction d0 donnée. Le masque à appliquer sera relatif à cette direction.
b) On a accès à un signal sweep, émis par une source placée au centre du système multi-microphoniques.
Cas n° 1 : Signal quelconque et calcul du masque masque relatif
Dans ce premier cas, nous avons accès à un signal quelconque en sortie de la source sonore, dans une direction de référence (Sref ) et dans les directions des différents microphones. Il s’agit alors de déterminer un masque que l’on pourrait qualifier de « relatif » car il est lié à une direction de captation particulière21.
Comme on peut le voir sur le schéma ci-dessous (Fig. 20), la génération du masque à partir d’un signal quelconque multi-microphonique peut être réalisée en 3 étapes :
- Analyses spectrales et extraction de l’enveloppe spectrale : le signal capté par les différents microphones est analysé par transformée de Fourier.
Nous l’avons évoqué en partie I.3.2 : chaque source sonore possède son timbre propre et n’excite pas toutes les fréquences. Il est donc nécessaire d’extraire l’enveloppe spectrale de la source, afin de constituer un masque à partir des informations pertinentes.
Diverses méthodes sont envisageables pour cela, comme l’extraction de pics utilisée par Martin Pollow dans [34]. Nous effectuerons quant à nous cette opération de lissage du spectre par simple moyennage grâce à une fenêtre glissante.
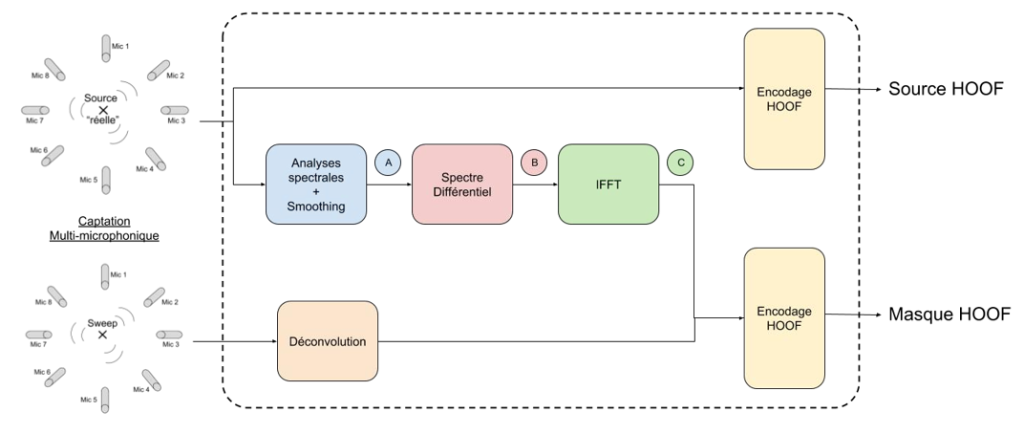
B. Détermination du spectre différentiel : les différences spectrales entre les différents microphones et la référence renseignent sur la directivité de l’instrument dans ces directions de l’espace. Le masque de directivité que l’on souhaite obtenir est la compensation à appliquer aux différentes fréquences afin d’obtenir les différentes directions à partir d’un microphone de référence. On divise les enveloppes spectrales pour obtenir le masque de passage Sref vers Sn (signal microphone n). Le lissage (ou extraction de l’enveloppe spectrale) effectué précédemment permet notamment d’éli- miner les risques de divergence liés à cette opération.
C. Transformée de Fourier inverse : les opérations précédentes ayant été effectuées dans le do- maine fréquentiel, il est nécessaire de repasser dans le domaine temporel à l’aide de la transformée de Fourier inverse.
Ce passage nécessite néanmoins quelques opérations préalables, comme la symétrisation et la du- plication du spectre en miroir, afin d’obtenir un filtre réel à phase linéaire.
Le script « FilterDesign_o123_2D.py », disponible en Annexe permet d’effectuer cette génération de masque à partir d’un signal multi-microphonique quelconque en renseignant la position des différents microphones sur le plan horizontal. Les masques générés à partir des signaux de voix, violon et ukulele sont également visualisables en Annexe.
Cas n° 2 : Détermination du masque à partir d’un signal sweep
Dans le cas où un sweep a pu être enregistré au moment de la captation, la génération du masque de directivité nécessite moins d’étapes.
Comme on peut le voir sur la figure 20, le signal sweep est capté par le système, puis déconvolué et encodé en HOOF, afin d’obtenir les réponses impulsionnelles à appliquer aux différentes harmoniques sphériques. Ce masque contient la fonction de transfert de la source elle-même et de sa directivité.
Il est possible d’accéder au « masque absolu » de certains instruments comme la trompette ou le trombone en envoyant un sweep par l’embouchure, ou en excitant le chevalet d’un instrument à cordes, mais cela peut s’avérer plus compliqué pour d’autres types de sources comme la voix, ou des instru- ments à percussion par exemple.
Une autre manière de créer une source HOOF serait donc d’appliquer « manuellement » certains gains ou filtres à une source monophonique, suivant les directions de l’espace, afin de la modeler selon la directivité souhaitée. Cela permet d’éviter l’écueil d’une source ne pouvant pas être mesurée, et pourrait également servir à créer des sources qui n’existent pas dans la réalité (directives dans les graves et omnidirectionnelles dans les aigus par exemple).
Synthèse par égalisation spatiale
J’aimerais proposer l’expression « égalisation spatiale » pour désigner le fait d’appliquer un filtrage fréquentiel dépendant des directions de l’espace. Il est possible de créer une source directive en utilisant ce type de filtrage.
Mon état des lieux m’a permis de dégager 2 principaux types d’égalisation spatiale au format HOOF : l’approche par « beamforming » et l’approche « discrète ».
- Beamforming : Le plugin « DirectivityShaper » de l’IEM-suite (voir Fig.22), propose déjà une ap- proche d’égalisation spatiale par « beamforming « 22. L’utilisateur se voit proposer quatre beams, dont il peut régler la directivité (en faisant varier l’ordre de 0 à 7), la direction, et la pondération utilisée23 (« Basic », « MaxRe » ou « InPhase »). Pour chacun des beams créés, un filtre paramétrique est appliqué (passe-bas, passe-bande ou passe-haut) : il en résulte une source directive au format HOOF pouvant monter à l’ordre 7.
- Approche discrète : Un autre type d’interface pourrait être imaginée avec une approche plu- tôt « discrète » de l’égalisation spatiale. Il s’agirait de laisser à l’utilisateur un certain nombre de points à manipuler, échantillonnés sur la sphère (nombre plus ou moins important de points sui- vant l’ordre HOOF en sortie), pour créer des figures de directivité personnalisables pour chaque bande de fréquence24, après interpolation entre les points. La question du nombre de bandes et celle du type de filtrage restent ouvertes.
Considérations pratiques
La question de l’ergonomie de ce type d’outil mériterait un travail plus approfondi, quant à la visualisation et la manipulation de la source 2D/3D, le type de filtres à utiliser, etc… afin de le rendre réellement exploitable en situation de production.
On peut d’ores et déjà remarquer un parallèle entre la synthèse HOOF et les modules de réverbérations numériques, qui peuvent être soit « à convolution » (issus de mesures acoustiques) soit « algo- rithmiques » (et paramétrables). Ces deux approches ne s’opposent pas et peuvent même parfois être combinées (cf les réverbérations hybrides). Le choix est laissé à l’ingénieur du son d’utiliser l’une ou l’autre selon ses goûts, ses envies, et le projet sur lequel il travaille.
En situation de production HOOF, l’ingénieur du son aurait donc le choix entre la captation multi-microphonique ou l’utilisation d’un plugin (à 1 entrée et N sorties) pour synthétiser chacune de ses sources directives.
On pourrait décrire l’outil de synthèse par masque comme une « Altiverb de la directivité »25. On peut imaginer y trouver l’ensemble des instruments de l’orchestre, mais également différents masques de voix, de transducteurs de la vie quotidienne (radios, téléphones…), et pourquoi pas des animaux. Tout ce qui serait utile dans le cadre de la post-production de contenus 6 DoFs devrait s’y trouver. Il serait également souhaitable de pouvoir importer des masques issus d’autres formats (voir Annexe), pour lesquels des données ont déjà été captées et traitées, après conversion en HOOF.
Pour l’outil de synthèse par égalisation spatiale, une banque de « presets » basée sur des mesures pourrait également être fournie. Cela permettrait à l’ingénieur du son d’aller plus rapidement en choisissant un modèle de base, et en l’affinant à l’aide des différents contrôles, puis en le sauvegardant éventuellement pour un usage ultérieur.
7.3 Illustration : le violon Stroh
Pour clore cette section sur la création de sources HOOF, j’aimerais évoquer un exemple atypique d’instrument de musique, qui pose question et pourrait faire l’objet d’un rendu intéressant au format HOOF.
Parmi les instruments à cordes, le violon Stroh26 (du nom de son inventeur) fait figure d’original. Parfois appelé «violon à pavillon» ou «violon trompette», cet instrument se distingue des autres ins- truments à cordes par son mode de rayonnement, qui se fait au travers d’un pavillon. Dans le cadre de la synthèse de directivité, la question du masque à appliquer à cet instrument pose donc question : celui d’un violon ou celui d’un instrument à pavillon ?

L’origine controversée du violon Stroh ne sera pas discutée ici, mais il est à noter que son invention a été déposée en 1899, époque des débuts de l’enregistrement, et s’inscrit dans la lignée du phonographe. Les premiers systèmes de prise de son, dits « acoustiques », possédaient un pavillon, vers lequel la source sonore devait être dirigée et projeter un maximum de son énergie afin d’augmenter le rapport signal/bruit.
Le violon Stroh, dont la directivité et la puissance se rapprochent plus de celles d’une trompette que d’un violon traditionnel, était donc un candidat particulièrement adapté à ces contraintes de prise de son.
Dans l’idéal, il serait intéressant de pouvoir mesurer la directivité du violon Stroh afin de lui appliquer son propre masque. Mais faute de moyens ou face à un instrument nouveau, l’ingénieur du son doit trouver des solutions. La synthèse de sources directives en est une. L’écoute doit évidemment guider son choix, mais les expérimentations créatives sont également permises par les masques de directivité. On pourrait tout à fait appliquer un masque de trompette à un violon, un masque de flûte à une guitare ou encore un masque de haut-parleur à une voix.
8. Post-production HOOF
8.1 Manipulations et visualisation de la source HOOF
Comme nous l’avons signalé en introduction de cette partie, les outils développés pour l’ambisonique peuvent tout à fait être utilisés dans le cadre du HOOF. Ces outils permettent d’effectuer des manipulations du champ sonore dans le domaine des harmoniques sphériques, c’est-à-dire indépendamment du système de captation et de restitution. Mais ils présentent également l’intérêt (souvent par l’intermédiaire d’un beamforming) de pouvoir travailler sur une partie isolée du champ, et ainsi de pouvoir véritablement « façonner » l’espace sonore (HOA) ou le rayonnement de la source (HOOF). La précision de cette zone de l’espace sera d’autant plus grande que l’ordre sera élevé.
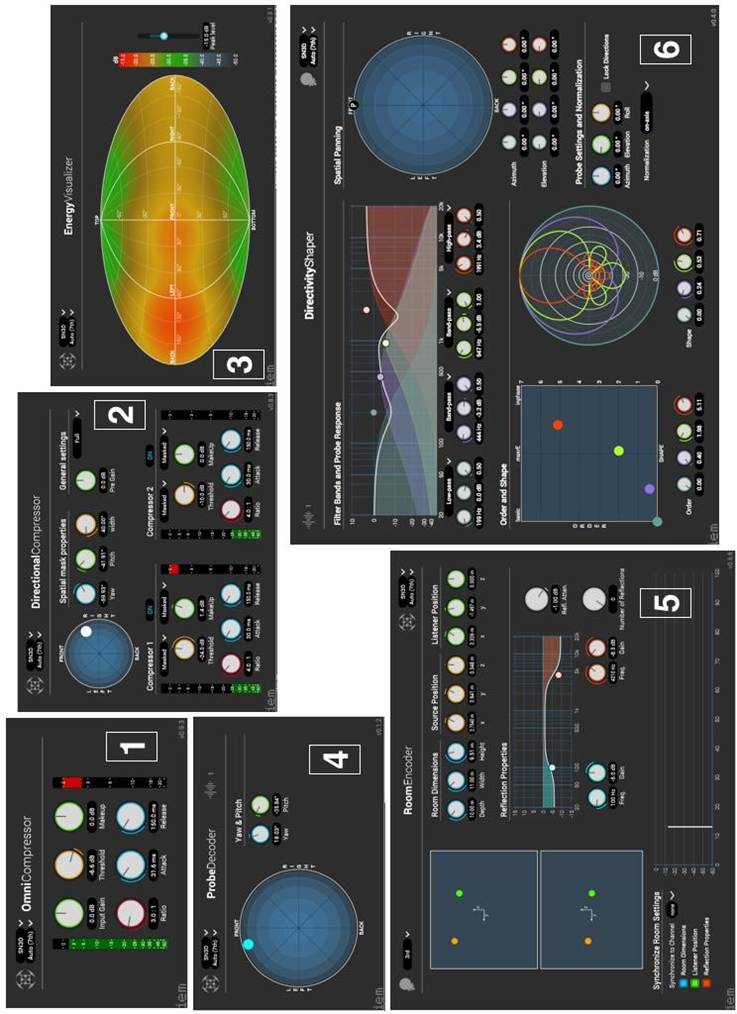
Certaines manipulations sont assez spécifiques aux harmoniques sphériques comme la rotation et l’effet de focus, d’autres sont des outils « traditionnels » de l’ingénieur du son comme la compression dynamique ou le filtrage/EQ qui ont été adaptés au paradigme ambisonique. Les outils ambisoniques de visualisation du champ sonore peuvent être appliqués au champ rayonné par une source HOOF. La suite de plugins de l’IEM27 présentée en figure 22 offre un panel de quelques effets ambisoniques disponibles actuellement, et utiles dans le cadre du HOOF. Ces plugins fonctionnent jusqu’à l’ordre 7 :
a) « OmniCompressor » : compression contrôlée par le signal du canal W (omni), et appliquée à l’ensemble des canaux.
b) « DirectionalCompressor » : compression contrôlée par une partie du champ sonore (à travers un beamforming), et appliqué à une partie du champ définie par l’utilisateur.
c) « EnergyVisualiser » : visualisation de la répartition de l’énergie sur la sphère, projetée en 2D. »ProbeDecoder » : projection en ondes planes dans une direction de l’espace (Voir partie 9.1). »RoomEncoder » : réverbération algorithmique MIMO (Voir partie 8.2).
d) « DirectivityShaper » : filtrage spatial d’une source monophonique (par beamforming) sur 4 bandes de fréquence afin de créer une source directive (Voir partie 7.2).
En termes d’implémentation et de coût de calcul, le format ambisonique est très économique. En effet, de simples combinaisons linéaires entre les différentes composantes permettent déjà d’effectuer des transformations intéressantes.
8.2 La réverbération
La réverbération artificielle est l’un des outils principaux du mixeur pour la création d’un espace acoustique. Les deux types de réverbérations artificielles existants sont la réverbération « à convolution« , utilisant des réponses impulsionnelles issues de mesures acoustiques, et la réverbération « algorithmique« , utilisant des modèles physiques ou des réseaux de retards pour simuler artificiellement des réflexions acoustiques.
Jusqu’à présent, l’envoi des sources sonores dans la réverbération ne prend pas en compte les caractéristiques de rayonnement des sources dans l’espace acoustique. L’utilisation du format HOOF et de réverbérations dédiées pourrait permettre cet ajout, et ainsi d’approcher un peu plus les conditions acoustiques « réelles ». Les deux approches « traditionnelles » de réverbération sont également envisa- geables pour la directivité.
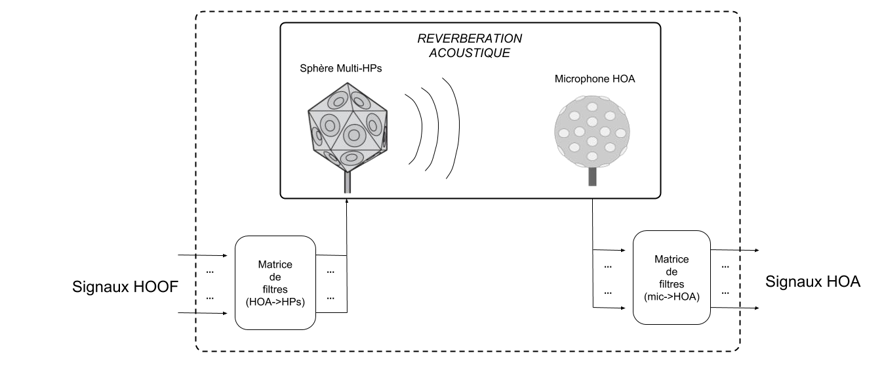
Dans le cas de la réverbération HOOF, il faut noter une différence de nature entre les signaux d’entrée et de sortie, comme on peut le voir sur la figure de synthèse HOA-HOOF (Fig. 16). En effet, contrairement aux réverbérations HOA qui sont appliquées directement sur les composantes ambisoniques, la réverbération HOOF prendra en entrée des sources directives (HOOF) et restituera un effet de salle tel qu’il serait perçu par un auditeur, encodé en un point de l’espace (HOA).
La réverbération à convolution
Ce type de réverbération basée sur des réponses impulsionnelles de salles (RIRs pour « Room Im- pulse Response« ) est déjà utilisée dans le domaine de l’acoustique architecturale depuis de nombreuses années. Elle a évolué récemment afin de prendre en compte les informations de directivité de la source et du récepteur[11], sous la forme de systèmes MIMO (« Multiple Inputs Multiple Outputs« )[27]. Il s’agit d’effectuer des réponses impulsionnelles à l’aide de sphères compactes de haut-parleurs (source) et de microphones HOA (récepteur), comme le montre la figure 23 ci-dessous.
Ainsi, il serait possible de convoluer n’importe quel signal encodé en harmoniques sphériques par cet ensemble de filtres contenant les caractéristiques spatiales et temporelles de la réverbération.
La réverbération MIMO sous forme de plugin n’est finalement qu’une extension (en termes d’implémentation) des réverbérations à convolution mono et stéréo pré-existantes. Il serait donc possible de la mettre en œuvre rapidement dans un cadre de post-production.
Cependant, la limite de ce type d’approche est que la réponse impulsionnelle spatiale comprend le son direct, une source convoluée se verra donc attribuer une position dans l’espace (celle de la source au moment de la mesure). La configuration de mixage couramment utilisée de type « bus de réverbération », dans lequel toutes les sources sont envoyées et mélangées, n’est donc pas possible en l’état. Il faut avoir une réverbération propre à chaque source. Une autre limite à prendre en compte est celle du coût de calcul, proportionnel pour chaque source à la longueur de la réponse impulsionnelle et au nombre de canaux convolués.
Il est également envisageable, pour tenter d’approcher encore plus la réalité, de mesurer des réponses impulsionnelles MIMO aux positions des différentes sources dans la salle. Cela permet d’accéder au comportement acoustique « réel » de la salle dans ces configurations source-récepteur précises. Dans ce cas, on souhaitera conserver le son direct, le système MIMO jouera alors à la fois le rôle de réverbéra- tion et d’encodeur HOA (tout comme le plugin « Room Encoder » de l’IEM).
La réverbération algorithmique
On appelle « algorithmique » toute technique de réverbération basée sur des réseaux de retard (FDN28) ou des lancers de rayons acoustiques.
Le « lancer de rayon » (« ray-tracing « ) est une solution permettant d’appliquer une réverbération en prenant en compte la directivité de la source. Il s’agit d’une technique couramment utilisée dans les logiciels de simulations acoustiques, pour simuler les caractéristiques acoustiques d’une salle avant même sa construction. Cela consiste à projeter un certain nombre de « rayons acoustiques » partant de la source jusqu’au récepteur, avec un certain nombre de réflexions sur les murs. La directivité de la source peut donc y être prise en compte, moyennant simplement un filtrage des rayons selon la direction de projection.
Un outil utilisant cette technique a déjà été implémenté dans un plugin de la suite IEM : le « Room Encoder » (voir Fig.22 (5)). Celui-ci permet de placer une source directive et un récepteur (jusqu’à l’ordre 7) dans un espace de type « boîte à chaussure », et de faire varier les paramètres de la réverbération. Cependant, le modèle utilisé et la limite du nombre de réflexions ne permet pas d’avoir un résultat sonore très convaincant.
Le framework EVERTims (Voir Annexe 3.3), permettant l’importation de modèles de directivités en harmoniques sphériques, utilise également cette technique de « lancer de rayons » pour simuler une réverbération à partir de géométries particulières de salles.
Il faut également noter que le coût de calcul peut être important par cette technique, surtout en temps réel, suivant le nombre de rayons et de réflexions considérées.
Concernant les réverbérations à « réseau de retard », il en existe pour des formats plus « traditionnels » (stéréo, 5.1 et plus récemment HOA), mais une implémentation prenant en compte les aspects de directivité du HOOF nécessiterait une étude plus approfondie.
Considérations pratique
Une dernière solution, plus raisonnable en termes de coût de calcul, serait d’ajouter la réverbération après décodage des sources HOOF. Par exemple une réverbération ambisonique dans le cas d’une resti- tution via un format HOA, ou une réverbération 5.0 ou quad si les sources HOOF sont ensuite mixées au format 5.1. Le son direct serait alors fonction de la directivité de la source, et la réverbération serait appliquée directement à celui-ci. Dans ce cas de figure, il est possible d’utiliser les réverbérations à « réseau de retard » (type Lexicon, Bricasti, TC Electronics) pré-existantes, suivant le format de sortie.
Il est de plus en plus question dans le cadre des nouveaux formats « objets » ou « hybrides »29 de laisser le décodeur prendre en charge la gestion de la réverbération. Celui-ci se placerait donc en bout de chaîne, contrôlé par des métadonnées indiquées par l’ingénieur du son lors du mixage, et s’adaptera en fonction du dispositif de restitution (décodage sur haut-parleurs ou binaural).
8.3 Illustration : l’effet Leslie en HOOF
La cabine Leslie, inventée dans les années 1930 par Donald Leslie, est un système d’amplification et de diffusion sonore. Elle est dotée de deux diffuseurs rotatifs : un pour les aigus (la trompette) et un pour les graves (le tambour). Ce dispositif met à profit la directivité des diffuseurs pour créer de manière acoustique un effet unique, proche du vibrato30. La figure 24(a) propose un schéma de fonc- tionnement de la cabine Leslie. Dans le cadre d’une prise de son stéréo (deux micros à 90° en général pour les aigus), la Leslie apporte également un effet de spatialisation et d’enveloppement naturel.
La cabine Leslie fut créée à l’origine pour s’associer avec les orgues électroniques, et plus particulièrement l’orgue Hammond, et offrir au son un effet acoustique plus convaincant que les vibratos utilisés à l’époque. Elle fut ensuite associé à d’autres instruments, au cours d’expérimentations créatives en studio, comme à la guitare de Georges Harrisson (dans « Lucy in the Sky with Diammonds« 31), ou à la voix de John Lennon (dans « Tomorow Never Knows« 32), mais aussi à la basse ou même à l’accordéon, comme le montre cette publicité des années 70 (figure 24(b)).
La vitesse de rotation des diffuseurs possède deux modes, un lent et un rapide, chacun créant un effet différent. Dans les aigus, le mode rapide laisse même entendre une variation fréquentielle, due à l’effet Doppler. Les phases d’accélération et de décélération sont également utilisées pour l’effet de désynchronisation qu’elles procurent entre les graves et les aigus.
Des émulations logicielles de l’effet Leslie existent, simulant cet effet basé en premier lieu sur des phénomènes acoustiques liés au comportement directionnel des diffuseurs. Cet outil peut désormais faire partie de la boîte à outils du mixeur.
Nous allons voir que le format HOOF peut être utilisé pour simuler cet effet. De la manière la plus simple, il s’agirait d’appliquer à un son le masque HOOF d’un haut-parleur, puis de lui appliquer une rotation à une certaine vitesse et d’écouter le résultat.
La figure 24(c) propose une implémentation permettant de contrôler de manière indépendante les vitesses de rotation de la trompette et du tambour, par un filtrage de type « cross-over » des hautes et basses fréquences.
Une possibilité serait de mesurer la directivité d’une véritable cabine Leslie, afin d’appliquer directement les masques « trompette » et « tambour » au modèle.
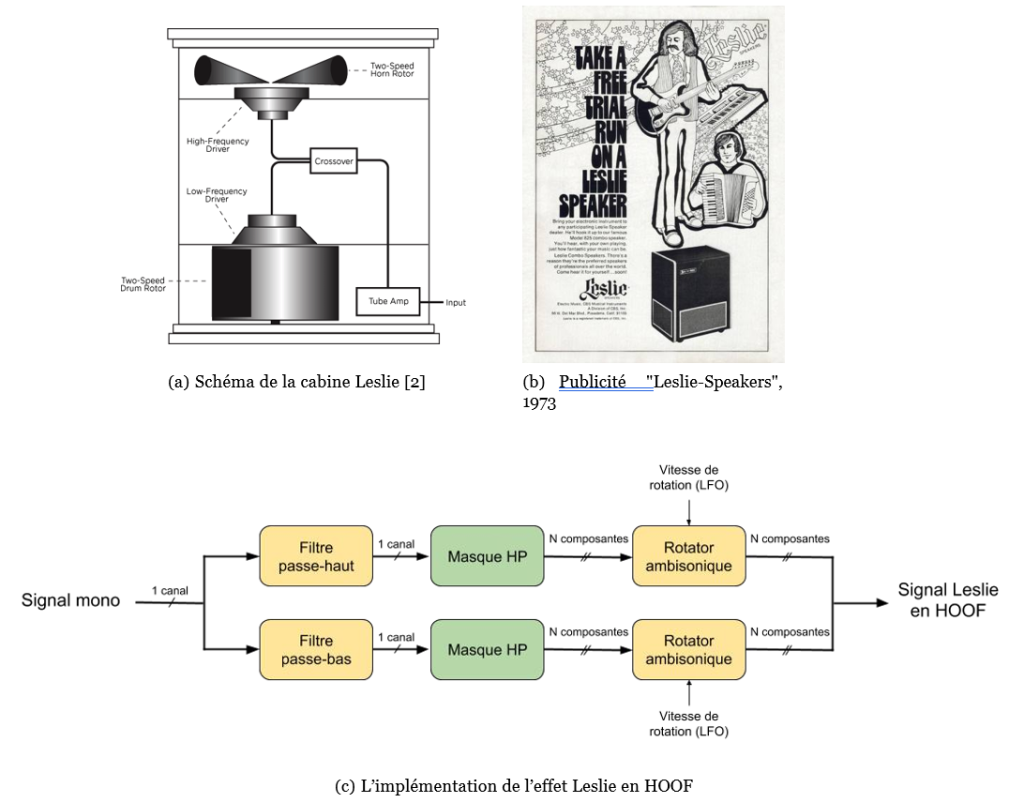
9. Rendu HOOF
Comme on peut le voir sur la figure 16, il existe deux manières de restituer une source HOOF : la diffusion sur une sphère compacte de haut-parleurs ou l’intégration de la source à une scène sonore virtuelle.
Le cas du décodage sur haut-parleurs nécessiterait un développement approfondi, et ne sera donc pas abordé ici. De nombreux articles se trouvent dans la littérature, auxquels le lecteur curieux pourra se référer afin d’approfondir le sujet.
Nous détaillerons ici la seconde option, mettant en œuvre une projection en ondes planes source HOOF, dans une direction de l’espace.
9.1 Décodage « basique » en ondes planes
Afin d’écouter un signal qui a été encodé dans le domaine des harmoniques sphériques, il s’agit de projeter celui-ci dans une direction de l’espace correspondant à celle de l’auditeur. C’est-à-dire sommer les contributions des différentes harmoniques sphériques dans cette direction : c’est ce qu’on peut qualifier de décodage « basique ». Le son direct ainsi obtenu pourra ensuite être spatialisé dans un système de restitution.
Soit

l’angle relatif entre l’axe de la source et l’auditeur et (SW , SX, SY ) les composantes de la source encodées en harmoniques sphériques. On obtient le signal décodé Sp par :
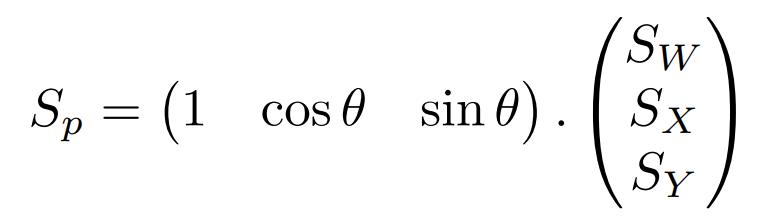
Le plugin « ProbeDecoder » de la suite de plugin IEM (Fig. 22 (4)) est parfaitement adapté à cette application, puisqu’il permet d’écouter une direction de projection en ondes planes du champ ambiso- nique.
Le signal monophonique issu de la projection pourra ensuite être spatialisé en binaural ou sur un système de haut-parleurs, selon l’application. Il pourra également servir de signal d’entrée pour un mixage HOA « classique ».
9.2 Décodage par « beamforming » (optimisations)
Nous l’avons déjà évoqué dans la partie 7.2, le « beamforming » consiste à appliquer une pondération particulière aux harmoniques sphériques. Dans le cas du décodage, ce principe est mis à profit afin de minimiser les contributions des lobes secondaires, ou pour affiner le lobe principal. L’un va au détriment de l’autre : c’est ce qu’on peut constater sur la figure ci-dessous (Fig. 25, tirée de la thèse de Jérôme Daniel.
Les différentes pondérations utilisées pour l’ambisonique (MaxRE, InPhase, . . . ) peuvent être ap- pliquées dans le cas du HOOF, proposant un résultat sonore différent du décodage « basique » en ondes planes.
Un patch Max/MSP (Fig.26) a été créé afin de comparer l’effet des différents types d’optimisations sur la directivité d’une source HOOF lors d’une restitution en binaural. Il permet d’effectuer des rotations et déplacements de la source, et d’écouter le résultat selon l’optimisation utilisée.
Une série d’écoutes, effectuée à différents ordres HOOF, a permis de déterminer que l’optimisation
«InPhase» semble la plus pertinente à appliquer, autant en terme de timbre perçu que d’efficacité de l’effet de directivité.
Ce patch constitue donc une sorte de synthèse de cette seconde partie, dans laquelle nous avons abordé les notions d’encodage, manipulations et décodage HOOF. Il intègre des objets du Spat33 et de la librairie ambisonique « HOA library« 34.
![Figure 25 – Lobes de directivité associés aux différents décodages ambisoniques, ordres 1 à 4. Figures tirées de [8].](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-252.png)
La restitution d’un « effet de champ proche », qui consisterait à élargir la source sonore lorsque l’auditeur s’en approche, reste à explorer. Il s’agirait d’augmenter le volume apparent de la source sonore, en utilisant par exemple plusieurs projections en ondes planes qui seraient réparties devant l’auditeur.
Finalement, l’une des applications que nous ne développerons pas ici est le rendu d’une source HOOF sur sphère multi-haut-parleurs. Cet aspect soulève en effet de nombreuses problématiques an- nexes (de l’ordre de la conception acoustique du système d’enceintes) et constituerait un sujet de recherche à part entière.
Cependant, ce type de dispositif électro-acoustique, associé au format en harmoniques sphériques, est d’ores et déjà utilisé à l’IEM de Graz à des fins acoustiques, mais également artistiques. Il a été adopté notamment par le compositeur Gerriet K. Sharma qui utilise les réflexions liées à la géométrie du lieu afin de créer des sources secondaires, et composer des œuvres immersives « in-situ ».
Même s’il reste pour l’instant très onéreux, ce nouveau système de diffusion « multicanal en un point » offre de nouveaux champs d’exploration extrêmement prometteurs.
10. Conclusion
Le travail de synthèse qui a été fait dans ce mémoire a permis une réelle mise à jour des travaux de Dylan Menzies sur le O-Format, en la généralisant aux ordres supérieurs. La formalisation d’une chaîne de production à l’usage des ingénieurs du son a été mise en œuvre, et différents éléments de vocabulaire associés à la production dans le format HOOF ont été proposés.
Comme on a pu le constater à la lumière de cette seconde partie, les outils de production HOOF sont quasiment tous déjà fonctionnels : sous forme de briques successives, à l’exemple de la suite IEM, ou adaptables depuis l’ambisonique notamment pour les effets (EQ, compresseurs, rotateurs …).
Cependant, plusieurs aspects théoriques évoqués dans ce travail de recherche mériteraient d’être approfondis : la question de la répartition et l’encodage des microphones, la réverbération HOOF, ou encore l’effet de champ proche. Aussi, la mise en place de tests perceptifs formels pourrait permettre de valider les méthodes utilisées, et d’évaluer l’influence des différents paramètres en jeu (nombre de microphones nécessaires à la captation, ordre HOOF optimal,…).
Même si certains points peuvent encore être approfondis, le format HOOF est déjà exploitable dans la pratique, mais la question de son adoption par les ingénieurs du son reste épineuse. Lors des débuts du format ambisonique, peu de personnes auraient prédit son essor. Pourtant, l’apparition des vidéos 360° a permis le développement des nombreux outils de production dont nous disposons aujourd’hui. La création d’une suite de plugins HOOF dédiés, plus ergonomique, pourrait sans doute encourager les ingénieurs du son à travailler avec des sources directives. Mais c’est sûrement dans les applications qu’il faut chercher, et dégager des motivations artistiques à l’utilisation du format HOOF.
En termes d’applications, le cas de la navigation dans des scènes virtuelles pourrait constituer à terme un nouveau type de média, pour lequel la notion de source directive prendrait tout son sens. C’est le cas de la partie pratique que j’ai menée afin d’illustrer cet écrit : « Runai on the moon ». L’objectif de ce projet, mené en collaboration avec le groupe Runai35, a été de créer une expérience musicale mettant en œuvre le format HOOF dans une scène à 6 degrés de libertés.
Il s’agit d’une sorte de clip immersif, permettant à l’auditeur de naviguer autour des musiciens dans un univers virtuel. Ce nouveau type de média questionne sur la place de l’auditeur vis-à-vis de l’œuvre avec laquelle il peut interagir, les aspects de narration, mais également sur le travail de l’ingénieur du son quant à la qualité du rendu final et du mixage, dont il n’aura finalement entendu qu’un nombre limité de versions.
La capacité à s’adapter et à remettre en permanence en question ses pratiques me paraît indis- pensable, en tant qu’ingénieur du son. La recherche et les évolutions technologiques offrent sans cesse de nouveaux outils, permettant de nombreuses expérimentations créatives, il ne tient qu’à nous de les saisir afin de créer du neuf, de l’inédit.
Troisième partie
ANNEXE : Scripts Python et solutions logicielles existantes
1. Scripts Python pour le format HOOF















2. Solutions préexistantes, 1re partie : les in- terfaces
La question de la directivité a déjà été abordée par certains domaines, qui ont conçu des solutions adaptées à leur application. Il s’agit d’une part, des logiciels de simulation acoustique, utilisés notamment par les ingénieurs en acoustique architecturale, et d’autre part, des jeux vidéos dans lesquels le joueur se déplace au sein d’un univers sonore virtuel interactif.
Chacun de ces domaines possède ses motivations propres pour la description modélisée de scènes sonores. On peut les résumer par la formule : « Plausibility VS Accuracy » utilisée par J.M Jot dans [22]. En effet, l’objectif de l’acoustique architecturale est en effet d’approcher au mieux la réalité physique dans le cadre de simulations, avec le plus d’exactitude possible.
Les designers sonores de jeux vidéos quant à eux travaillent à créer des scènes sonores crédibles : qu’elles soient « réalistes » ou « imaginaires ». Ces derniers sont motivés par des raisons créatives et perceptives. Ils sont également contraints par des questions de coût de calcul et les limites du moteur de rendu.
2.1 Les logiciels de simulation acoustique
Basés sur des modèles physiques, les logiciels de simulation acoustique permettent de simuler la réponse d’une salle avant même sa conception, ou encore de simuler la disposition d’un système d’enceintes de sonorisation. Des sources virtuelles sont donc utilisées, et leur directivité généralement prise en compte car elle influe sur le résultat sonore perçu. Nous en citerons quelques-uns :
Odeon
Ce logiciel dédié aux simulations acoustiques architecturales [30] propose d’utiliser des sources « points » omnidirectionnelles (de synthèse ou enregistrées) mais également des modèles directifs. Les modèles préexistants peuvent être importés dans le logiciel via les formats CLF36 ou .So8 (format propriétaire natif d’Odeon).
Un module d’édition est également proposé (Le « Source Directivity Editor « , Fig. 27(a)) pour créer ses propres directivités, avec la possibilité de les exporter au format.So8. Ce module propose une résolution fréquentielle par bande d’octave (de 63Hz à 8kHz) et angulaire sur une sphère échantillon- née de 10° en 10°. Lorsque des données ne sont pas renseignées, le logiciel effectue une interpolation « elliptique » des valeurs pour chaque bande de fréquence, afin de lisser les valeurs.
Il est également possible de partir d’un fichier CLF au format texte importé, dans lequel est indiqué en premier lieu le type de directivité (« POLAR », « FULL » ou « SYMETRIC »), puis les valeurs correspondantes pour chaque angle et bande d’octave. Le type « POLAR » indique que les données de directivité ont été mesurées sur deux plans (horizontal et vertical), le type « FULL » indique que les données ont été mesurées sur toute la sphère échantillonnée de 10° en 10°, et le type « SYMETRIC » indique que la source possède un axe de symétrie (pas d’option de symétrie plane) et les données sont donc renseignées seulement sur un arc de 180°.
Ease
Ease (pour « Enhanced Acoustic Simulator for Engineers« ) est également un logiciel de simulation acoustique. Il propose un module appelé « Speaker Lab » (voir Fig.27(b)), permettant de créer, manipuler et exporter des sources directives au format GLL (« Generic Loudspeaker Library« ). Ces sources pourront ensuite être exploitées dans les modules de simulation acoustique de EASE.
Ce format, particulièrement adapté aux haut-parleurs permet de travailler avec des résolutions angulaires allant jusqu’au degré, par bande d’octave.
Il prend en compte les informations de phase, issues de mesures ou de simulation de haut-parleurs, sous forme de réponse impulsionnelle. Cela présente l’avantage de pouvoir travailler avec des sources multi-points (les fameux « line arrays« ) et d’ajuster un système à l’aide de délais ou de filtres FIRs.
De nombreux constructeurs fournissent désormais les fichiers GLL de leurs modèles d’enceintes, permettant l’importation dans EASE et la manipulation dans le module « Speaker Lab ».
CATT
Le logiciel CATT-Acoustic, largement répandu dans les bureaux d’étude en acoustique, permet également de gérer les sources directives par le biais de son module « directivity ».
Cet outil, que l’on peut visualiser sur la figure 27(c), permet de créer et manipuler des fichiers aux formats SD0, SD1 suivant la précision recherchée. En effet, le SD0 permet un échantillonnage des plans vertical et horizontal tous les 15○alors que le SD1 permet d’échantillonner la sphère complète tous les 10°.
Une évolution plus récente est le SD2, qui est géré quant à lui par la « DLL Directivity Interface », et permet de décrire une source acoustique sous une forme dynamique (DLL). La résolution fréquentielle est désormais inférieure à la bande d’octave, la résolution angulaire peut être de l’ordre du degré (et peut être irrégulière, plus dense à certains endroits), mais surtout : il est possible de créer une dépendance des données de directivité à la distance et gérer ainsi les effets de « champ proche » et « champ lointain ».
La dernière version en date est le SD3, qui prend également en compte les données de phase, avec une résolution angulaire de 5°.
Il est également possible d’importer des fichiers .CLF (format que nous évoquerons dans la partie suivante, annexe 3) dans le logiciel CATT-Acoustic.
2.2 Les bibliothèques audio 3D
Dans les années 90, les puissances de calcul des ordinateurs ont permis d’envisager le rendu d’univers audio-visuels 3D interactifs. Un format de fichier a alors été normalisé pour la description hiérarchique de scènes 3D interactives : c’est le VRML (« Virtual Reality Markup Language« ) [18]. Ce type de des- cription a pour but de spécifier au moteur de rendu la position des différentes sources sonores mais également les effets à appliquer quant à la réponse de l’environnement acoustique.
Le X3D (Extended 3D) [19] succède au VRML en 2004, en y ajoutant quelques améliorations, notamment la description du rayonnement des sources sonores.
Les « SoundNodes » permettent de caractériser le comportement spatial des objets sonores. Le modèle de directivité choisi est une directivité « en gain ». Il consiste en une double ellipse définissant un champ proche de la source où le niveau est maximum, et un champ éloigné où le son n’est plus perçu. La zone de décroissance se situe donc entre les deux ellipses (voir Fig.28(a).
En 2005, la partie 11 de la norme MPEG-437 spécifie le format BIFS (« Binary Format for Scene« ). Également basé sur une description hiérarchique des scènes sonores (comme VRML), sa spécificité est l’ajout de la dimension temporelle basée sur des « timestamps« 38, mais aussi d’une possible caractéri- sation fréquentielle de la directivité. Le « DirectiveSound node » permet de spécifier ces informations de directivité de source sous deux approches : « physique » ou « perceptive ».
L’approche physique consiste à définir le diagramme de directivité 2D de la source, en spécifiant les angles et les gains associés à chaque fréquence, par le biais d’un vecteur. Ces valeurs sont spécifiées sur un demi-cercle, le modèle considéré étant à symétrie axiale. On le voit, cette approche « à la mano » est laborieuse et inadéquate à toute notion de créativité.
L’approche « perceptive », quant à elle développée conjointement par les chercheurs de l’IRCAM et de France Télécom (cocorico !) propose des paramètres « simples and intuitifs » au créateur de contenu tels que : la « source presence« , « source warmth« , « source brilliance« , ainsi que la caractérisation d’une « OmniDirectivity » pour chaque objet de la scène sonore. Celle-ci permet de spécifier l’égalisation (fré- quentielle) à appliquer à la source pour l’envoi dans la réverbération.
Dans les mêmes années, Microsoft fournit aux développeurs une API39 afin de programmer des logiciels (jeux vidéo par exemple) dont les rendus seront gérés par les différents périphériques hard- wares compatibles : c’est le DirectX.
DirectSound3D est une bibliothèque audio de l’API DirectX, qui permet de gérer les scènes so- nores en 3D. Celle-ci propose un modèle de rayonnement basé sur des cônes de directivité : un cône intérieur pour simuler l’axe de directivité d’une source, où le gain est maximal, et un cône extérieur où le gain est moindre. La figure 28(b) illustre ce modèle.
La libraire OpenAL40, ayant l’avantage d’être multi-plateformes, fournit dans son API des outils du même type, pour manipuler des sources directives.
2.3 Les DAWs, renderers audio spatialisés
De même que pour le domaine de « l’acoustique virtuelle interactive » dont nous venons de parler, l’espace sonore rendu dans un mixage musical ou de cinéma n’a pas pour vocation de reproduire la réalité acoustique avec exactitude, mais d’en fournir une version crédible d’un point de vue esthétique et artistique.
Cependant, parallèlement aux langages de descriptions utilisés pour les jeux vidéo, rares sont les outils de spatialisations sonores disponibles pour les ingénieurs du son permettant de contrôler di- rectement les effets de directivité des sources sonores. En effet, les mixeurs (musique et cinéma) ont toujours trouvé des astuces pour régler ces questions en utilisant les effets à leur disposition (filtres, EQ, réverbération, etc…).
Un simple filtre passe-bas est souvent placé en amont de l’envoi dans la réverbération pour limiter le rayonnement des aigus, conformément à la réalité perceptive de la réverbération. Également, le rapport « son direct/son réverbéré » et les effets de distance sont gérés en ajustant directement le niveau des faders.
Toutefois, et du fait du rapprochement que nous avons évoqué entre le travail des designers sonores et celui des ingénieurs du son, certains outils sont apparus permettant un contrôle plus direct (et visuel) des effets de directivité des sources.
Voici les trois solutions dédiées actuellement disponibles :
Le Spatialisateur (Spat)
Créé à l’IRCAM en 1995, le « Spat » est un logiciel destiné à la simulation acoustique [29], com- prenant des modules de réverbération et de spatialisation sonore. Celui-ci peut être utilisé dans des contextes très différents comme les concerts live, le mixage audio spatialisé, la réalité virtuelle, les ins- tallations sonores interactives… À l’origine développé sous forme modulaire avec des objets Max/MSP, dont le nombre a augmenté avec les années [5], le Spat a ensuite été porté en plugins audios par la société Flux : : (« Ircam-tools » et plus récemment « Spat Revolution »).
La particularité du Spat est qu’il se trouve à l’intersection entre l’acoustique physique et les outils de productions sonores plus traditionnels à destination artistique. En effet, il est basé en grande partie sur des modèles physiques pour la réverbération et certaines méthodes de rendu (WFS et ambiso- niques notamment), mais ses applications sont majoritairement musicales et artistiques.
Un point fort du Spat est que son développement a donné lieu à un grand nombre d’études sur les as- pects perceptifs de la réverbération et des espaces acoustiques, qui ont ensuite été implémentés dans le logiciel. L’utilisateur a donc le choix dans l’interface, avec la possibilité d’utiliser des contrôles « percep- tifs » (« présence« , « chaleur « , « brillance« , « enveloppement« …)41 ou des contrôles issus de l’acoustique (« EDT « , « densité modale« , « cluster distribution« …).
Les aspects de directivité des sources sonores y ont été pris en compte, particulièrement dans leur rapport à la réverbération. La source sonore est en effet divisée en deux parties : axis faisant office de son direct, et omni, signal qui alimentera la réverbération. Comme on peut le voir sur la figure 29(a), chacune des parties comporte une égalisation propre, paramétrable en 3 bandes de fréquences. Chaque source se voit définir une « aperture« , angle d’ouverture pour le son direct, qui rappelle forte- ment « l’angle d’ouverture à n dB » (défini partie 4.1).
Facebook Spatial Workstation (FB360)
La plateforme Facebook s’intéresse depuis quelques années aux contenus « immersifs ». En 2016, elle rachète Two Big Ears, une société ayant développé des outils de mixage dans un format fortement inspiré de l’ambisonique. Ces outils sont depuis distribués gratuitement sous forme de plugins, pour permettre aux créateurs de contenus d’accompagner la vidéo d’un son 360○.
Ce n’est que récemment42, dans la version 3.2, qu’un module de directivité (« Directionality« ) a été
ajouté au plugin (voir Fig. 29). Celui-ci consiste en l’application d’un filtre de type « high shelf », dont la fréquence centrale est fixé à 2kHz et la pente varie suivant la direction par rapport à l’axe (voir Fig. 30).
Le paramètre « opening angle » permet d’ajuster l’angle d’ouverture dans l’axe la source, et « effect level » est un coefficient de l’amplitude de l’effet appliqué. La réverbération incluse dans la suite FB360 (modèle de « shoebox » peu convaincant…) est alimentée par le signal de source directive.
Cet outil, reprenant l’idée du cône de directivité, est pour l’instant très basique. D’après la do- cumentation, les paramètres ont été optimisés pour la voix et laissent peu de marge de manœuvre à l’utilisateur (sur les paramètres de l’EQ par exemple). On peut imaginer que des versions prochaines verront l’ajout de réglages plus fins sur la directivité.
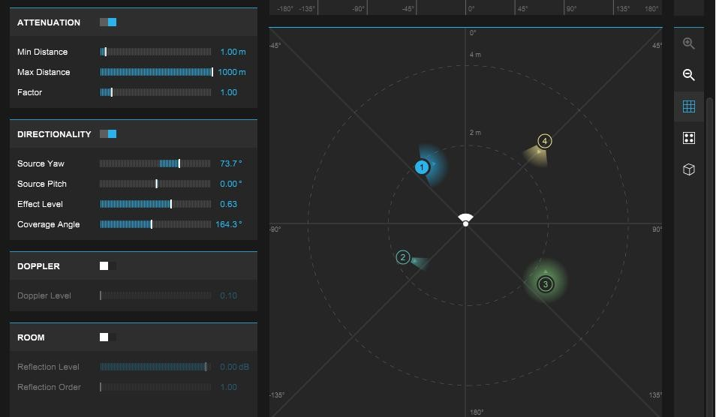
Figure 29 – La même scène sonore sur deux outils de spatialisation différents
Google Resonance SDK
La firme Google s’intéresse également à l’audio spatialisé pour les applications AR/VR. Récem- ment, la plateforme a mis à disposition un SDK43 multi-plateformes, pour permettre aux développeurs d’intégrer l’audio spatialisé à leurs applications.
Le SDK propose différents modules et un moteur de rendu basé sur l’ambisonique pour un certain nombre de plateformes de développement : IOS, Android, Web, Unity, Unreal, FMOD et Wwise. Et également un plugin de binauralisation HOA (ordre 3) en VST.
Les modules pour FMOD et Unity incluent un « AudioListener » (rendu binaural), un « AudioSound- field » (lecture de fichiers ambisoniques), et un « AudioSource » permettant le contrôle de la directivité des sources sonores. Il s’agit simplement d’une loi de gain qui n’est pas sans rappeler l’ambisonique puisqu’elle utilise une combinaison de figures bidirectionnelle et omnidirectionnelle, contrôlée par le paramètre « Directivity« . Un second paramètre, « Sharpness« , permet de resserrer la directivité. La loi de gain implémente les deux paramètres Dir et Sharp comme suit :
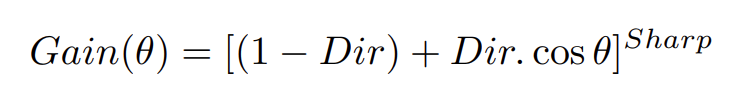
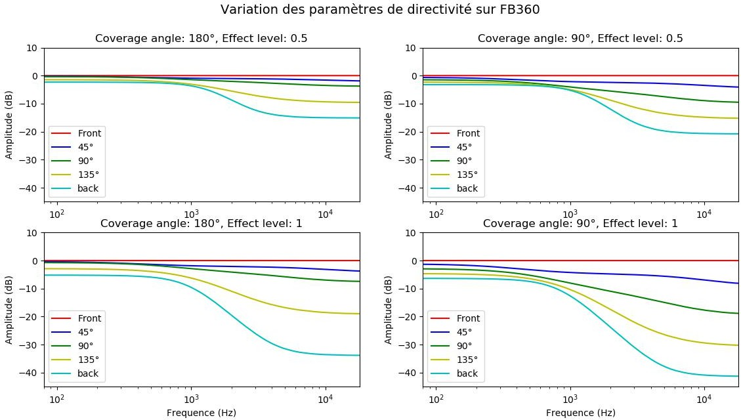
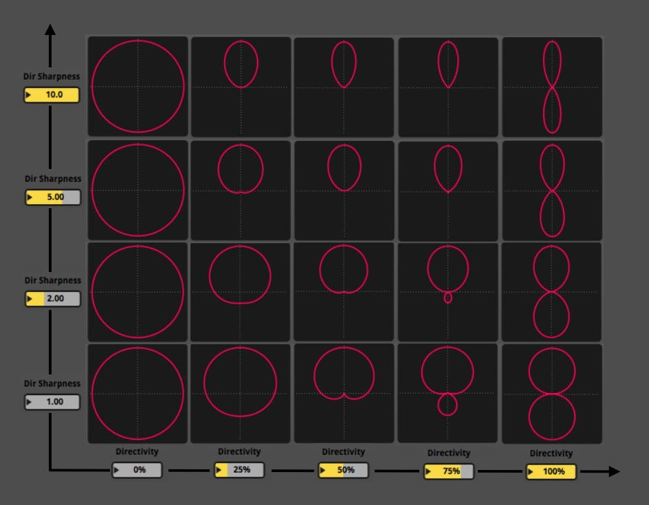
3. Solutions préexistantes, 2ᵉ partie : les formats de données
Nous venons d’étayer divers types d’interfaces et de moteurs de rendu déjà existants pour manipu- ler et jouer des scènes sonores mettant en œuvre des sources directives.
Mais comme le rappelle Jean-Marc Jot dans [21], pour qu’une solution logicielle soit viable, il est indispensable qu’elle réponde au défi de la standardisation : « Standardization is essential for enabling platform-independent playback and re-usability of scene elements by application authors and sound de- signers« 44.
En effet, la définition d’un format commun pour les sources directives permettrait d’unifier les dif- férentes pratiques, et de faciliter la vie des ingénieurs du son sur le travail de création de scènes sonores.
Quelques tentatives sont apparues au cours des dernières années. Les avantages et inconvénients de chacune d’elles seront détaillées, puis synthétisées dans un tableau récapitulatif.
3.1 OpenDAFF
« We want to ease the exchange of directional audio data between people and institutions« 45
Tel est le credo formulé par les chercheurs d’Aix-la-Chapelle (RWTH) à l’initiative d’OpenDAFF (« Open Directional Audio File Format « ), comme une réponse à l’appel de J.M Jot.
Leurs travaux autour de la simulation acoustique en réalité virtuelle ont donné lieu à la création de ce format d’échange de mesures acoustiques directionnelles. Ce format OpenDAFF peut être utilisé pour stocker des mesures de sources sonores (mesures de haut-parleurs, d’instruments de musique) ou de récepteurs (microphones, HRTFs). Il permet d’associer à chaque point d’une sphère échantillonnée une réponse impulsionnelle, une fonction de transfert du système, et les valeurs mesurées associées.
Une interface graphique (« DAFFViewer », voir Fig.3.1(a)) a été développée pour visualiser les don- nées, ainsi qu’un utilitaire en ligne de commande (« DAFFTool ») pour créer et manipuler des fichiers OpenDAFF. Une librairie C++ ainsi qu’une série de scripts Matlab sont également disponibles.
Le projet de l’OpenDAFF a été conçu spécifiquement pour la directivité. Des bases de données issues de travaux de recherche sont déjà constituées46, mais il n’existe malheureusement pas d’outil dynamique et pratique pour manipuler ces directivités, ce qui constitue un frein à son adoption directe par les ingénieurs du son.
3.2 CLF (Common Loudspeaker Format)
Le format CLF [15] est également un format ouvert, destiné à stocker et à distribuer des données de systèmes de haut-parleurs. Il a été créé par le CLF-group47, à destination des fabricants d’enceintes et des développeurs et usagers de logiciels de simulation acoustique, dans une volonté d’uniformisation face à la variété des formats propriétaires en usage, spécifiques à chaque logiciel.
Cela a été une réussite puisque la grande majorité des fabricants d’enceintes et des développeurs de logiciels dédiés l’ont adopté (Odeon, CATT,…). Des outils de visualisation (« CLFViewer ») et d’édition (« CLFEdit ») sont mis à disposition sur le site du CLF-group, ainsi qu’une base de données de fichiers CLF. Les fichiers sont créés au format binaire (extensions .CF1 ou .CF2) par les auteurs afin d’en assurer l’intégrité, ou au format texte afin qu’ils puissent être édités.
Comme son nom l’indique, ce format est fortement orienté à destination des logiciels de simulation acoustique évoqués en 2.1, et des applications de « design de système » en sonorisation. Il inclut non seulement des données concernant la directivité de la source, mais également des données mécaniques (poids, type d’enceintes), électro-acoustiques (sensibilité, puissance, impédance), et des critères comme l’indice de directivité ou l’angle d’ouverture à -6dB (voir 4.1), calculés par bandes de fréquences. Il peut donc servir à trouver des informations sur les différentes enceintes disponibles.
Les données de directivité sont issues de mesures avec un échantillonnage équi-angulaire de la sphère, le format a connu des évolutions depuis sa création :
- CF1 : Résolution angulaire de 10°, résolution fréquentielle par bandes d’octave.
- CF2 : Résolution angulaire de 5°, résolution fréquentielle par bandes de 1/3 d’octave.
- CF2 version2 : Extension de CF2, avec l’ajout des informations de phase du système, et de données sur les filtres.
3.3. SOFA (Spatially Oriented Format for Acoustics)
Le format SOFA [15] a été développé à l’origine pour proposer une solution commune de stockage des HRTFs (Head Related Transfert Function), afin de permettre notamment le développement d’outils de rendus binauraux personnalisés. Il est également prévu d’y stocker tout type de données de me- sures issues de « systèmes acoustiques » en renseignant précisément les positions source/récepteur, qu’il s’agisse de BRIR (Binaural Room Impulse Response), de DRIR (Directive Room Impulse Response), ou encore de données de directivité de sources. Ce dernier aspect, qui pourrait nous intéresser ici, est actuellement en cours de développement par différents chercheurs participant à l’élaboration de SOFA.
Le projet EVERTims48 propose un framework « open-source » pour les simulations acoustiques et la réalité virtuelle. Il met en œvre un réverbération en ray-tracing, et un module de gestion de source appelé « Source Unit » permettant de manipuler des sources directives : « The new auralization unit now supports the SOFA format to import either HRIR or source directivity patterns ».
Comme nous l’avons vu avec le projet EVERTims, il est en théorie possible d’implémenter l’impor- tation de données de directivité issues de mesures acoustiques via le format SOFA dans les simulateurs acoustiques. Malgré tout, cela n’a pas encore été mis en pratique, et pour la manipulation de sources, SOFA reste un format « figé » et peu malléable, au sens où il nécessite d’utiliser Matlab et ses librairies SOFA.
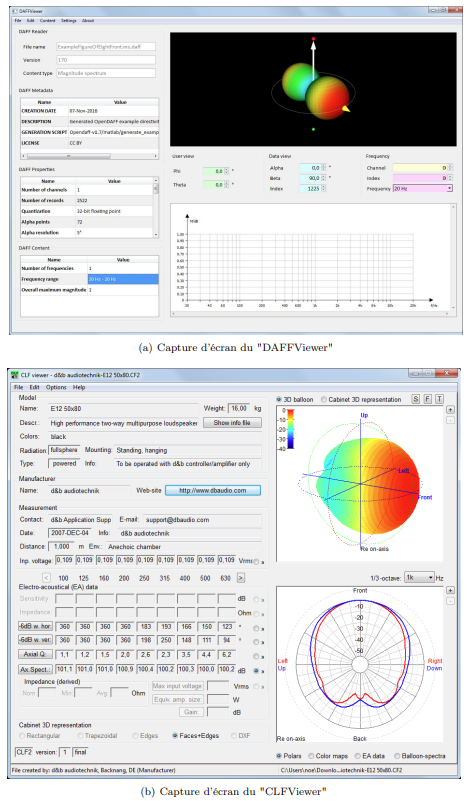
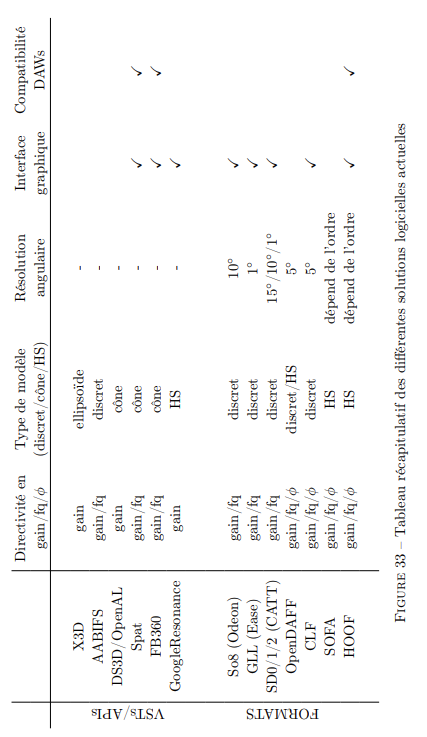
Table des figures

Bibliographie
- Site web :. https://fr.wikipedia.org/wiki/Harmonique_sphérique. Dernière visite : 2018- 05-30.
- Site web :. https://www.strymon.net/rotary-speaker-technology-white-paper. Dernière visite : 2018-05-30.
- LeMoigne Alice. Vers une nouvelle vidéo musicale immersive :Quel son pour la vidéo 360 ? Master’s thesis, CNSMDP, Formation Supérieure aux Métiers du Son, 2016.
- Ilan Ben Hagai, Martin Pollow, Michael Vorländer, and Boaz Rafaely. Acoustic centering of sources measured by surrounding spherical microphone arrays. The Journal of the Acoustical Society of America, 130(4) :2003–2015, 2011.
- Thibaut Carpentier, Markus Noisternig, and Olivier Warusfel. Twenty years of ircam spat : looking back, looking forward. In 41st International Computer Music Conference (ICMC), pages 270–277, 2015.
- Antoine Chaigne and Jean Kergomard. Acoustique des instruments de musique (2e édition revue et augmentée). Belin, 2013.
- Perry R Cook and Dan Trueman. Nbody : Interactive multidirectional musical instrument body radiation simulators, and a database of measured impulse responses. In ICMC, 1998.
- Jérôme Daniel. Representation de champs acoustiques, application a la transmission et a la res- titution de scenes sonores complexes dans un contexte multimedia. PhD thesis, Paris 6, 2000.
- Jérôme Daniel, Sebastien Moreau, and Rozenn Nicol. Further investigations of high-order am- bisonics and wavefield synthesis for holophonic sound imaging. In Audio Engineering Society Convention 114. Audio Engineering Society, 2003.
- Daniel Deboy. Acoustic centering and rotational tracking in surrounding spherical microphone arrays. Master’s thesis, Institute of Electronic Music and Acoustics, University of Music and Performing Arts, Graz, Austria, 2010.
- Angelo Farina, Paolo Martignon, Andrea Capra, and Simone Fontana. Measuring impulse res- ponses containing complete spatial information. In Audio Engineering Society Conference : UK 22nd Conference : Illusions in Sound. Audio Engineering Society, 2007.
- Peter Fellgett. Ambisonics. part one : General system description. Studio Sound, 17(8) :20–22, 1975.
- Antonio Fischetti. Initiation à l’acoustique. 2001.
- Michael A Gerzon. Ambisonics. part two : studio techniques. studio sound, 17(8) :24–26, 1975.
- CLF Group et al. A common loudspeaker file format. Syn-Aud-Con Newsletter v32, (4), 2004.
- Acoustics — Determination of sound power levels and sound energy levels of noise sources using sound pressure — Precision methods for anechoic rooms and hemi-anechoic rooms. Standard, International Organization for Standardization, Geneva, CH, March 2012.
- Information technology – Coding of audio-visual objects – Part 11 : Scene description and applica- tion engine, address = Geneva, CH, institution = International Organization for Standardization. Standard, October 2005.
- Information technology – Computer graphics and image processing – The Virtual Reality Mode- ling Language – Part 1 : Functional specification and UTF-8 encoding, address = Geneva, CH, institution = International Organization for Standardization. Standard, December 1997.
- Information technology – Computer graphics and image processing – Extensible 3D (X3D) – Part 1 : Architecture and base components. Standard, International Organization for Standardization, Geneva, CH, December 2004.
- Finn Jacobsen, Salvador Barrera Figueroa, and Knud Rasmussen. A note on the concept of acoustic center. The Journal of the Acoustical Society of America, 115(4) :1468–1473, 2004.
- Jean-Marc Jot. Efficient description and rendering of complex interactive acoustic scenes. In 10th Int. Conference on Digital Audio Eflects. DAFx, 2007.
- Jean-Marc Jot and Jean-Michel Trivi. Scene description model and rendering engine for interactive virtual acoustics. In Audio Engineering Society Convention 120. Audio Engineering Society, 2006.
- Jean-Loïc Le Carrou. Vibro-acoustique de la harpe de concert. PhD thesis, Université du Maine, 2006.
- Dylan Menzies. New performance instruments for electroacoustic music. PhD thesis, 1999.
- Dylan Menzies. W-panning and o-format, tools for object spatialization. In Audio Engineering So- ciety Conference : 22nd International Conference : Virtual, Synthetic, and Entertainment Audio. Audio Engineering Society, 2002.
- Jürgen Meyer. Acoustics and the Performance of Music. Verlag Das Musikinstrument Frankfurt am Main, 1978.
- Hai Morgenstern, Johannes Klein, Boaz Rafaely, and Markus Noisternig. Experimental investi- gation of multiple-input multiple-output systems for sound-field analysis. In 22nd International Congress on Acoustics (ICA), 2016.
- Markus Noisternig, Franz Zotter, and Brian FG Katz. Reconstructing sound source directivity in virtual acoustic environments. In Principles and Applications of Spatial Hearing, pages 357–372. World Scientific, 2011.
- IRCAM/Espace Nouveaux. Spatialisateur, user manual. IRCAM.
- ODEON Room Acoustics Software. Odeon User’s manual.
- Felipe Otondo and Jens Holger Rindel. A new method for the radiation representation of musical instruments in auralizations. Acta Acustica united with Acustica, 91(5) :902–906, 2005.
- Jukka Pätynen, Ville Pulkki, and Tapio Lokki. Anechoic recording system for symphony orchestra.
- Acta Acustica united with Acustica, 94(6) :856–865, 2008.
- Alfonso Pérez Carrillo, Jordi Bonada, Jukka Pätynen, and Vesa Välimäki. Method for measuring violin sound radiation based on bowed glissandi and its application to sound synthesis. The Journal of the Acoustical Society of America, 130(2) :1020–1029, 2011.
- Martin Pollow. Directivity patterns for room acoustical measurements and simulations, volume 22. Logos Verlag Berlin GmbH, 2015.
- Martin Pollow, Gottfried Behler, and Bruno Masiero. Measuring directivities of natural sound sources with a spherical microphone array. In Proceedings of the 1st Ambisonics Symposium Graz, pages 1–6, 2009.
- BN Postma, Leonardo Katz, BF Funes, and Esteban Lombera. Design of a measurement me- thodology to characterize acoustic parameters and sound directivity of string instruments in a real acoustic environment. In International Symposium on Musical and Room acoustic (ISMRA), 2016.
- Jens Holger Rindel, Felipe Otondo, and Claus Lynge Christensen. Sound source representation for auralization. In International Symposium on Room Acoustics : Design and Science. Hyogo, Japan, 2004.
- Noam R Shabtai, Gottfried Behler, Michael Vorländer, and Stefan Weinzierl. Generation and analysis of an acoustic radiation pattern database for forty-one musical instruments. The Journal of the Acoustical Society of America, 141(2) :1246–1256, 2017.
- Gabriel Weinreich and Eric B Arnold. Method for measuring acoustic radiation fields. The Journal of the Acoustical Society of America, 68(2) :404–411, 1980.
- Franz Zotter. Analysis and synthesis of sound-radiation with spherical arrays. Citeseer, 2009.
- Franz Zotter and Matthias Frank. Challenges of musical instrument reproduction including di- rectivity. The Journal of the Acoustical Society of America, 138(3) :1785–1785, 2015.
Remerciements
La réalisation de ce mémoire a été possible grâce au concours de plusieurs personnes que j’aimerais remercier tout particulièrement :
- Charles, mon directeur de mémoire, pour son temps, ses conseils avisés et ses commentaires impitoyables mais éclairés.
- Gregory et Jérôme pour les nombreuses élucubrations et discussions passionnantes, ainsi que Marc, Alex et toute l’équipe audio d’Orange Labs pour m’avoir permis de mener ces réflexions dans les meilleures conditions. Un grand merci à Laureline, Thomas et Stéphane.
- Merci à Louise pour sa patience et son aide à la relecture.
Je remercie également :
- La FSMS, étudiants et professeurs, Denis Vautrin son directeur, ainsi que Conservatoire de Paris, les musiciens que j’y ai rencontré et ses moyens techniques.
- Shuichi Okada, violoniste, pour avoir accepté d’interpréter la Chaconne de Bach dans une cage de micros. Guillaume(s), Natalyia, Bogdan, Tobias, Samuel du groupe Runai, pour leur inves- tissement dans le projet expérimental de clip à 6 DoFs : les astronautes.
- Et bien évidemment à la promo 2014, pour ces quatre ans intenses, ses rigolades et autres pi- treries.
Thanks to :
Martin Pollow, Franz Zotter and Jukka Pätynen, for providing me with some multi-microphone array audio samples. I wish this modest work to be a contribution to their research.
Notes
- « Digital Audio Workstation » = Stations de travail audionumériques. ↩︎
- « 6 Degrees of freedom » = correspondant aux 3 degrés de translation et rotation d’un auditeur au sein d’une scène. ↩︎
- Dispositif permettant de capter une scène en relief. ↩︎
- Enceinte E12 audiotechnik, de d&b. ↩︎
- « Head Related Transfer Functions » : filtres utilisés pour la synthèse binaurale. ↩︎
- Voir partie 7.1 ↩︎
- Configuration de type « A-B », espacé de 50cm. ↩︎
- Audios disponibles sur : http://soundmedia.jp/nuaudk. ↩︎
- Intensité que donnerait une source omnidirectionnelle « équivalente » (de même puissance). ↩︎
- http://www.bcspeakers.com/en/products/coaxial/6-5/8/6fhx51 ↩︎
- NB : Les coefficients peuvent varier suivant la convention de normalisation utilisée. ↩︎
- Ce qui est en principe contraire à l’éthique FSMS… ↩︎
- La proposition m’a été soufflée par Jérôme Daniel au cours de discussions. ↩︎
- Voir Annexe 2.2, DirectSound 3D. ↩︎
- Codeurs développés dans la norme MPEG-H par exemple. ↩︎
- Enregistrement des sources l’une après l’autre. ↩︎
- D’autres lois d’interpolation sont envisageables, comme le VBAP par exemple. ↩︎
- À l’écoute, l’interpolation a tendance à « lisser » la directivité de la source, par rapport à l’écoute des microphones originaux. ↩︎
- Le masque peut décrire une simple directivité en « gain », il s’agira alors d’un vecteur de gains scalaires. Il peut également décrire, par un vecteur de filtres, une directivité en « magnitude » ou une directivité « complexe ». ↩︎
- « Réponse Impulsionnelle Finie ». ↩︎
- On pourrait envisager de générer ce masque systématiquement par rapport à l’axe principal de directivité de la source, où l’énergie est la plus importante sur l’ensemble du spectre. ↩︎
- « Formation de voie » : pondération des harmoniques sphériques pour créer un lobe de directivité dans une direction. ↩︎
- Ayant pour résultat le resserrement du lobe principal, et la présence plus ou moins prononcée de lobes secondaires. ↩︎
- Dans le même esprit que l’interface du module « DLL Directivity Interface », voir figure 27 en annexe. ↩︎
- Réverbération à convolution proposée par AudioEase et largement utilisée par les ingénieurs du son. ↩︎
- <http://chroniques.bnf.fr/numero_courant/coulisse/violon_de_stroh.htm)> ↩︎
- Au format VST distribués gratuitement et en open-source sur https://plugins.iem.at. ↩︎
- Feedback Delay Network. ↩︎
- Le MPEG-H ou l’ADM notamment. ↩︎
- Variation périodique du volume au cours du temps à une fréquence donnée. ↩︎
- Album « Sgt. Pepper’s Lonely Hearts Club Band « , The Beatles, 1967. ↩︎
- Album « Revolver « , The Beatles, 1966. ↩︎
- Spatialisateur de l’IRCAM, voir Annexe 2.3. ↩︎
- http://hoalibrary.mshparisnord.fr ↩︎
- Groupe de musique traditionnelle Irlandaise. ↩︎
- Common Loudspeaker Format, voir Annexe 3 . ↩︎
- Concernant le codage « d’objets audio-visuels », la partie 11 est dédiée à la « description et au rendu de scènes » [17]. ↩︎
- « Timestamps » = Marqueurs temporels. ↩︎
- API = « Application Programming Interface ». ↩︎
- https://www.openal.org ↩︎
- Que l’on retrouve d’ailleurs dans MPEG-4, partie 11 (voir Annexe 2.2). ↩︎
- Version sortie en mai 2018. ↩︎
- SDK = « Software Development Kit « , suite de « briques logicielles » à l’usage des développeurs. ↩︎
- « La normalisation est essentielle pour permettre la compatibilité entre les diflérentes plateformes de restitution, et la réutilisation d’éléments communs dans plusieurs projets. » ↩︎
- « Nous voulons faciliter l’échange de fichiers audio directionnels entre les personnes et les institutions. » ↩︎
- http://www.opendaff.org ↩︎
- http://www.clfgroup.org ↩︎
- http://evertims.github.io ↩︎