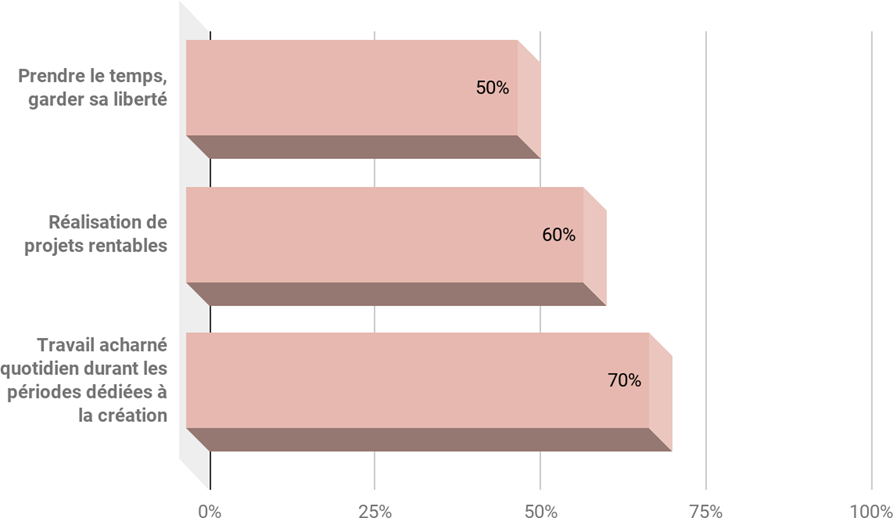
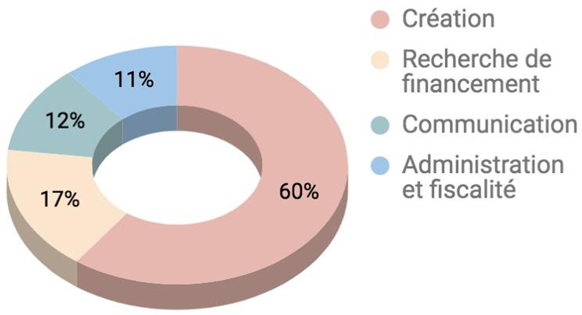
Comment servir et écouter aujourd’hui les trésors musicaux du passé ?
Par : Jean Viardot
Formation Supérieure aux Métiers du Son Directeur de mémoire : Valentin Bauer, Octobre 2023
Résumé
Les musiques afro-américaines des années 1950-60 ont influencé jusqu’à aujourd’hui plusieurs générations d’artistes. Pourtant, leurs enregistrements originaux ne sont plus aussi largement écoutés qu’autrefois. Le grand public ayant été formé à une écoute stéréophonique de haute définition, écouter des masters monophoniques au rendu bruité, déséquilibré et étriqué peut aussitôt sembler inhabituel, non spontané. C’est pourquoi, dans l’engouement suscité par l’audio immersif, notre étude cherche à savoir dans quelle mesure remixer en son immersif des masters monophoniques de blues, R&B et soul des années 1950-60 peut faire sens aujourd’hui sur le plan musical, culturel et historique.
Nous concevons une première expérience réunissant 24 ingénieurs du son, musiciens et experts du répertoire ciblé. Par un entretien semi-dirigé, une séance d’écoute avec questionnaire et une séance de remixage en son spatialisé de trois morceaux de blues, R&B, soul, elle vise à évaluer les comportements de réflexion, d’écoute et de remixage vis-à-vis de masters originaux des années 1950-60. Parmi les principaux résultats, les participants estiment pour deux morceaux que leur propre remixage favorise davantage la musique que le master original. Nous identifions le master original entravant le plus selon eux le message musical délivré, et nous en réalisons un remixage en son immersif, fidèlement à leurs commentaires et à leurs actions.
Dans une seconde expérience, un premier test d’écoute comparative du master original et de notre master remixé vise à connaître l’intérêt musical et culturel de présenter celui-ci au grand public. Huit professionnels de l’industrie phonographique jugent notre remixage respectueux de la musique, valorisant l’arrangement et susceptible de plaire. Le second test vise à connaître la préférence de 45 consommateurs de musique entre les deux versions. Une large majorité préfère écouter la chanson dans notre remixage, aurait envie de l’écouter plus souvent ainsi et de profiter en son immersif des autres chansons du label.
Abstract
African American music from the 1950s-60s has influenced various generations of artists. However, nowadays, consumers do not listen to these original recordings as widely as before. Being used to listening to high-fidelity stereo recordings, they may have difficulties listening to noised, disturbed, or tight mono recordings. Therefore, amid the current immersive audio craze, our study aims to understand how remixing in immersive audio 1950s-60s mono blues, R&B, soul recordings may be meaningful today, on the musical, cultural and historical levels.
Our first experiment gathers 24 sound engineers, musicians and experts of this musical repertoire. It aims to assess thinking, listening, and remixing behaviors towards the 1950s-60s original masters, through a semi-structured interview, a listening session with a questionnaire, and a spatialized audio remixing session of three blues, R&B, and soul recordings. Among the main results, regarding two songs, the participants think that their remix better fits the music than the original master. After identifying the worst original master with respect to the musical purpose according to them, we have remixed it in immersive audio, faithfully to their comments and actions.
In our second experiment, a comparative listening test between the original master and our new immersive audio master aims to understand the musical and cultural point to be able to introduce it to a wider audience. Eight experts from the phonographic industry assess that our remixed master respects the music, highlights the instrumental arrangement and would appeal to people. A second test aims to find out the preference between both versions of 45 music consumers. By an overwhelming majority, the participants prefer to listen to our immersive remix. Furthermore, they would like to listen to this song more often in the immersive format, and call for listening to other songs from the label in the same immersive audio conditions.
Introduction
La restauration par intelligence artificielle d’images captées au début du XXᵉ siècle1 détient le pouvoir de faire émerger en chacun de nous une nouvelle réflexion sur le temps passé. Empreint d’un réalisme inédit, ce nouvel objet nous livre en effet de cette époque une vue en tous points différente de celle que notre mémoire lui connaissait. La temporalité jusque-là évidente d’un film devient soudain sous-jacente. Au premier regard, la haute définition et le fluide enchaînement de ses images nous laissent logiquement croire à un film actuel. Mais l’instant suivant, des signes évidents d’un passé plus lointain (vêtements, accessoires, coiffures) contrarient notre première impression. Dès lors, un phénomène psychique survient en nous : la dualité époque passée (réalité) / époque simultanée (apparence). C’est cette dualité qui trouble l’œil et l’esprit, nous fait perdre la notion du temps et de l’espace, nous rend momentanément autre.
À la lumière de cette révolution technique, pouvons-nous croire à une expérience sensorielle analogue dans le domaine de l’audio ? Pouvons-nous, en remodelant le son d’un enregistrement monophonique, entendre nous situer soudain devant les musiciens de la séance, être instantanément projetés plusieurs décennies en arrière entre les murs du studio d’enregistrement ? En retravaillant l’aspect de l’objet qu’est l’enregistrement, on pourrait au moins espérer percevoir et apprécier autrement son contenu musical. Certes l’objectif est ambitieux ; mais certains procédés actuels, comme la séparation de sources et le mixage en son immersif, entretiennent aujourd’hui l’espoir de nous le faire vivre.
Toutefois, avant de songer à une quelconque expérience perceptive, il est nécessaire d’examiner le bien-fondé de cette démarche au travers d’une étude pratique et approfondie. Ce projet soulève en effet dans plusieurs domaines d’importantes questions, que nous aborderons.
Au vu de ce que nous avons évoqué, deux grandes problématiques se présentent à nous :
- Dans quelle mesure remixer en son immersif des masters monophoniques fait-il sens aujourd’hui sur le plan culturel, historique et artistique ?
- Cette démarche de travail répond-elle à une envie particulière des consommateurs actuels vis-à-vis des enregistrements anciens ?
Dans l’histoire de l’enregistrement musical, la période 1950-60 constitue une époque charnière. Pour la première fois en effet, le preneur de son ne dispose plus d’une seule empreinte sonore possible pour l’enregistrement d’une œuvre – celle imposée auparavant par la gravure directe sur le disque – mais d’un tout premier nuancier de couleurs sonores, grâce notamment à l’éclosion de l’enregistrement magnétique. L’une d’elles est ainsi choisie pour incarner finalement, en lien étroit avec l’œuvre et le style musical à enregistrer, l’esthétique sonore de l’enregistrement. Cette période est aussi extrêmement fertile musicalement. Dans le dur contexte de ségrégation raciale sévissant aux États-Unis, plusieurs artistes de blues, de rhythm and blues (R&B) et de soul s’installent très vite au sommet du paysage musical populaire. Grâce aux nouvelles techniques d’enregistrement, le caractère perpétuellement organique et créatif de leur musique transpire aussi désormais au travers d’esthétiques sonores bien caractéristiques.
Mais tout en pouvant considérer que la plupart des enregistrements de blues, R&B et soul des années 1950-60 ont été réalisés avec beaucoup de clairvoyance et une certaine maîtrise d’un matériel d’enregistrement certes en progrès mais encore limité, pensons-nous forcément pour autant que tous témoignent d’un rendu sonore « idéal » vis-à-vis de la musique annoncée ? Pensons-nous forcément que le rendu sonore de ces masters originaux est en tous points conforme à la manière dont l’œuvre a été pensée, composée, arrangée et interprétée ? Croyons-nous qu’il est vraiment celui qui place le potentiel de ressenti de l’œuvre à son plus haut niveau ? Cela concerne tant le respect et la mise en valeur de l’esthétique musicale, de la composition et de l’arrangement qui ont été pensés et organisés consciemment par les artistes, que le jeu d’interprétation et le son spécifique de chacun des musiciens de la séance.
Ces interrogations, orientées vers la problématique a, figurent au centre d’une première expérience que nous consacrons à trois masters originaux du répertoire cité. Celle-ci vise à étudier les comportements de réflexion, d’écoute et de remixage, lors d’une séance de remixage particulière. Nous obtenons les pistes séparées de ces enregistrements, inexistantes à partir des premiers magnétophones, grâce à une technologie récente de séparation de sources basée sur l’intelligence artificielle. Ce test, qui réunit ingénieurs du son, musiciens et experts musicaux du répertoire concerné, vise donc précisément à analyser leur évaluation du rendu sonore de ces masters originaux (Q.R.1) et de leurs masters remixés (Q.R.3) vis-à-vis de la musique, leur degré d’engagement dans la séance de remixage (Q.R.2) et la cohérence entre leurs réponses émises à l’entretien préliminaire et leurs choix de remixage (Q.R.4).
Cette première expérience donnera naissance à une seconde qui s’attachera à répondre à la problématique b. Nous tirerons en effet des remarques des participants de la première expérience l’enregistrement présentant le rendu sonore le moins en accord avec ce que suggère selon eux la musique. Nous en réaliserons un remixage en son immersif, fidèlement aux caractéristiques musicales relevées et aux choix de remixage privilégiés par l’ensemble des participants. Finalement, nous organiserons un test d’écoute comparative entre la version sonore originale de cette chanson et notre version remixée. Dans un premier test, nous solliciterons l’expertise de producteurs musicaux, de réalisateurs artistiques et d’ingénieurs du son pour savoir si notre version remixée présente aujourd’hui un intérêt culturel et musical à être entendue par le grand public, et si elle pourrait prétendre à être commercialisée aux côtés de la version originale (Q.R.5). Puis, dans un second test d’écoute comparative, nous demanderons à une partie du grand public (musiciens, non musiciens et experts du répertoire concerné) à travers laquelle des deux versions sonores ils préfèrent écouter cette chanson (Q.R.6).
Ainsi, nous serons en mesure de conclure notre étude sur le degré de pertinence musicale, culturelle et historique que présente aujourd’hui l’action de remixer en son immersif un master monophonique de blues, R&B ou soul produit dans les années 1950-60 (a). En plus de cela, nous pourrons savoir si cette nouvelle approche de travail répond en fait à une envie particulière des consommateurs actuels vis-à-vis des enregistrements anciens (b).
Notre étude s’organise donc en trois temps : une revue de littérature des principaux thèmes évoqués, l’expérience n°1 répondant à la problématique a, et l’expérience n°2 complétant la réponse à la problématique a et traitant la problématique b. Dans une discussion finale, nous confronterons les résultats de nos expériences avec les données issues de la littérature pour enrichir notre réponse aux problématiques a et b.
I. État de l’art
A. Enregistrer et écouter la musique blues/R&B/soul dans les années 1950-60 : allier organicité musicale et nouvelles techniques d’enregistrement
Nous proposons dans cette première partie une plongée dans les années 1950-60 au cœur de l’enregistrement musical aux États-Unis. Comme notre étude souhaite évaluer l’intérêt de remixer en son immersif la musique blues/R&B/soul de cette période, nous chercherons ici à comprendre ce qui fait son essence et comment les ingénieurs du son exploitent les nouvelles techniques sonores pour l’enregistrer tout en calibrant leur produit aux modes d’écoute du grand public.
1. Exprimer son identité noire dans la musique afro-américaine
Malgré l’abolition de l’esclavage, les États du Sud ne reconnaissent pas les amendements de la Constitution des États-Unis qui établit depuis 1870 l’égalité des droits civiques entre tous les citoyens américains. À travers les lois Jim Crow, ils instaurent jusqu’au milieu des années 1960 une politique de ségrégation raciale entre les Blancs et les Noirs dans tous les lieux publics (Poole, 2014). Celle-ci s’opère jusque dans les magasins de disques, dont les premiers ouvrent dans les années 1920. On y trouve alors des « pop records », des enregistrements de musique interprétée « par et pour les Blancs », et des « race records », similairement pour les Noirs (Pirenne, 1994). Notons pourtant que de nombreux Blancs américains se procurent assez tôt certains de ces « race records ». Les musiciens noirs y affirment leur identité dans trois genres dominants, le blues, le rhythm and blues et la soul, qui impliquent alors des moyens d’expression différents.
1) Le blues
Le blues naît bien avant l’industrie discographique. Il puise dans son essence dans les work songs2 récités par les esclaves et travailleurs noirs durant la deuxième moitié du XIXᵉ siècle, en particulier la période esclavagiste (Woods, 2017). Bien que son style s’en éloigne dès les années 1920, notamment par l’emploi de la guitare acoustique, il en conserve l’idée de posséder peu pour exprimer beaucoup.
Traditionnellement, le Delta blues du Mississippi ne fait appel qu’à un chanteur-guitariste comme Robert Johnson qui, avec un lyrisme très organique, exprime toute la douleur, la plainte et l’amertume du peuple noir (Ausseil et al., 1995). Le tempo souvent lent mais appuyé traduit l’envie de voyager mais la difficulté pour y parvenir. Il s’accélère parfois sous la forme d’un boogie pour alléger le propos. De plus en plus, des instruments tels que la contrebasse, le piano, les vents (clarinette, saxophone, trompette, trombone), et des chœurs viennent s’ajouter à la voix (Bessie Smith, Georgia White) et à la guitare (parfois remplacée par le banjo) pour donner plus de poids aux sentiments véhiculés (Jolibert, 2002). Le blues migre ensuite à Chicago à l’aube des années 1950 (Muddy Waters, Howlin’ Wolf), où l’instrumentarium s’électrifie aussitôt, à l’image de la guitare, soliste désignée avec l’harmonica (Bas-Rabérin, 1973). Pour compenser cette nouvelle puissance de l’orchestre, la batterie apparaît. Par la douleur qu’il continue d’exprimer en fond, le blues s’exporte ensuite au-delà des frontières américaines.

(Source : https://digital.nepr.net)
2) Le rhythm and blues
Révélé aux États-Unis au début des années 1940, le rhythm and blues est une définition musicale d’après-guerre de la population noire américaine. Bien que le terme, abrégé R&B, puisse être traduit par l’expression « rythme et mélancolie », les musiciens de ce courant entendent donner beaucoup plus de poids au rythme qu’au blues souffreteux (Hofstein, 1991). Avec cette énergie portée sur un texte plus léger et plus drôle, ils veulent faire oublier le quotidien discriminatoire que subit la population noire depuis plusieurs décennies (Hofstein, 1991). Pour lancer ce courant effervescent, ces musiciens réunissent les marqueurs de trois genres inhérents à la musique noire : le rythme du jazz, le lyrisme du blues, et bien sûr le chant gospel, qui réunit à lui seul ces deux attributs (Ripani, 2006). C’est en 1949 que Jerry Wexler, bientôt producteur d’artistes R&B chez Atlantic Records, baptise le « rhythm and blues » dans le magazine Billboard, bannissant le terme discriminatoire de « race music » (Pirenne, 1994).

La batterie, la contrebasse (bientôt basse électrique), le piano et parfois la guitare électrique forment le socle rythmique. Et inspirée des big bands swing, la section de cuivres (au moins un saxophone et une trompette) égaient le répertoire en dialoguant avec la voix principale. Des artistes remuants tels que Fats Domino, Big Joe Turner et Ray Charles viennent ainsi au tournant des années 1950 donner un souffle nouveau à toute la musique américaine. C’est ce courant en particulier qui entraîne dans son sillage l’émergence du rock’n’roll (Garofalo, 2002).
3) La soul
La soul se construit dès le milieu des années 1950 (Guralnick, 2003). Mais comme le rhythm and blues mêle simultanément plusieurs courants, ce n’est qu’en 1969 que le magazine Billboard lui donne un nom (Pirenne, 1994). Soul signifie « l’âme » : celle d’une chanson, d’une voix ou des musiciens. Bien que l’empreinte rythmique du R&B reste bien marquée, c’est la voix qui par son éloquence, sa grandeur, son expressivité, puisée dans la tradition du chant gospel pour incarner l’âme des Noirs américains. Guralnick (2006) raconte que c’est Ray Charles qui, au milieu des années 1950, lance ce courant en étant l’un des premiers artistes à arranger des chants de gospel dans un cadre profane3, ce qui lui vaut de nombreuses réprimandes de la population afro-américaine. Mais c’est aussi lui qui introduit le terme en 1958 dans son album Soul Brothers. La soul reprend les effectifs denses du R&B en y incluant souvent l’orgue, en référence à l’église, le tout dans une cadence rythmique tantôt très douce, tantôt frénétique. Durant toutes les années 1960, au paroxysme de tension liée à la lutte des Noirs américains pour la reconnaissance des droits civiques, les voix poignantes d’Aretha Franklin et d’Otis Redding expriment l’émotion sincère de la population afro-américaine. Toutefois à cette même période, certains labels de soul/R&B comme Motown Records abandonnent l’idée d’une culture unique en destinant ouvertement leur musique aux deux publics, Noirs et Blancs (Guralnick, 2003). Non seulement cette orientation, secondée par la fin de la ségrégation raciale, marque peu à peu la fin de la musique noire exclusive aux États-Unis, mais le blues, le rhythm and blues et la soul continuent jusqu’à aujourd’hui d’exercer leur influence.

2. L’adoption de nouveaux moyens d’enregistrement
1) L’avènement de l’enregistrement magnétique
L’arrivée de l’enregistrement magnétique dans les studios d’enregistrement à la fin des années 1940 pose les bases d’une nouvelle ère sonore, dont profitent ensuite pleinement les productions des années 1950-60.
Dans les années 1920-30, les laboratoires cherchent à remplacer l’enregistrement musical électrique par un medium plus facile à lire et à la restitution sonore moins bruitée. Ils fondent leurs recherches sur l’enregistrement magnétique, dont le principe est défini dès la fin du XIXᵉ siècle par Oberlin Smith et Valdemar Poulsen : un courant circulant dans une bobine génère un champ magnétique qui provoque l’aimantation de fines particules disposées sur un support (Mercier et al., 2010). Fritz Pfleumer invente alors en 1928 comme support d’enregistrement la bande magnétique, une bande papier kraft avec de la poudre de fer. Bien que sa grande souplesse empêche encore une magnétisation durable, elle attire l’attention de la compagnie allemande AEG qui rachète le brevet et commence à développer le Magnetophon K1 (Kimizuka, 2012). Via une bande d’acétate puis de plastique, ce dernier devient le premier enregistreur magnétique utilisé pour la diffusion radio et, dès 1936, l’enregistrement de concerts4. Mais l’Allemagne nazie tient en secret cette prouesse dont elle profite grandement pendant le conflit mondial (Rémond, 2015).
En juillet 1945, l’ingénieur électricien Jack Mullin est envoyé en Allemagne pour examiner les outils de communication utilisés par l’ennemi durant la guerre. Dans l’un des bunkers, il découvre plusieurs Magnetophon AEG. Il en rapatrie deux aux États-Unis, les remet en état et les présente au chanteur Bing Crosby, qui cherche justement un moyen pour enregistrer ses shows à la radio avec une qualité sonore semblable à celle d’une émission en direct (Cogan & Clark, 2003). Devinant tout le potentiel de cet outil, celui-ci soutient Mullin dans ses travaux en le faisant nommer ingénieur-chef au sein de la jeune entreprise Ampex. En 1948, Mullin ouvre les portes de l’enregistrement magnétique à la radio et très bientôt aux studios d’enregistrement, en commercialisant l’Ampex Model 200A (Kimizuka, 2012).

Très vite, le magnétophone monophonique5 investit les studios américains. Les ingénieurs du son aperçoivent aussitôt les grands atouts de production qu’offre la bande magnétique. Parmi ceux-ci, la nouvelle bande passante est sans doute la plus évidente et la plus bénéfique (Cogan & Clark, 2003). La fidélité de reproduction est alors hautement améliorée, ce qui sert particulièrement à la définition des timbres des instruments. De plus, le souffle d’enregistrement causé par le support est avec la bande magnétique bien plus faible que celui qu’occasionne le disque gravé, tel qu’on enregistrait la musique jusque-là. Mais surtout, en coupant les bandes issues de différentes prises et en les assemblant convenablement, les ingénieurs du son peuvent faire du montage entre les différentes prises. Cette nouvelle méthode de production constitue une ressource importante pour les musiciens et les producteurs qui souhaitent corriger quelques passages d’interprétation. Il devient aussi plus aisé de naviguer temporellement dans l’enregistrement grâce au rembobinage de la bande et à la réactivité de la tête de lecture. Enfin, une bande peut être effacée et donc réutilisée pour d’autres enregistrements, là où quelques années avant, il était évidemment inimaginable de pouvoir gommer le sillon gravé sur un disque.
Le magnétophone mono d’abord utilisé est dit pleine piste, car son unique piste d’enregistrement occupe toute la hauteur de la bande (Rumsey & McCormick, 2002). Pendant quasiment toute la décennie 1950, il est le maillon final de la chaîne sonore de tous les enregistrements aux États-Unis, dont ceux des artistes de blues, de R&B et de soul. Comme il est réduit à une seule piste, les instruments continuent d’enregistrer tous à la fois, en live, comme au temps de l’enregistrement acoustique puis électrique. Les ingénieurs du son lui envoient une somme de signaux provenant de plusieurs micros, qu’ils mixent en direct pendant la séance sur des mixettes de 4 ou 8 voies (Gordon, 2013) (figure 5). Ces mixettes rudimentaires limitent bien souvent le nombre de micros utilisés, et ainsi la qualité de restitution de tous les instruments. La musique comme le mixage, tout se fait en direct. Si les producteurs souhaitent une meilleure prise, il faut donc en refaire une en entier et avec tous les musiciens.

Ainsi, l’enregistrement magnétique modifie d’abord légèrement le déroulé d’une séance d’enregistrement, il améliore surtout la qualité de restitution par rapport au disque. Le montage des bandes mixées constitue finalement une bande « master », envoyée aux stations de radio pour sa diffusion et aux compagnies de pressage de disques pour sa commercialisation (Rumsey & McCormick, 2002).
2) L’enregistrement multipiste, la question de l’overdubbing
Dès 1953, plusieurs studios commencent à se procurer des magnétophones bipistes6, 3 pistes, et bientôt 4 pistes. En octroyant par exemple une piste entière à la voix principale, les ingénieurs du son peuvent ajuster sa présence dans un mixage postérieur (Rumsey & McCormick, 2002).
Mais c’est à la fin des années 1950 que l’enregistrement magnétique vient possiblement modifier leurs habitudes de travail. Ampex inclut dans ses magnétophones la fonction simul-sync, qui rend la tête d’enregistrement capable de lire la bande avec une qualité de restitution acceptable.
Lecture et enregistrement peuvent donc être synchrones, lançant la mode de l’overdubbing7. Initiée dès 1950 par Les Paul avec deux enregistreurs mono, cette technique consiste à enregistrer une partie musicale par-dessus une autre enregistrée précédemment sur une autre piste (Bode, 1984). Pour un confort acoustique ou d’interprétation, les ingénieurs du son peuvent désormais enregistrer séparément chaque section instrumentale. En particulier, un musicien peut effectuer plusieurs prises de son passage soliste sans demander au reste de l’orchestre de jouer avec lui. Et un autre peut chanter ou jouer plusieurs voix sur un même passage.
Mais malgré l’atout apparent que représente cette pratique, les producteurs de blues, de R&B et de soul s’en tiennent d’abord à ce que suggère la musique8. Comme exposé en section I.A.1., la musique afro-américaine exprime avant tout un certain sentiment, une certaine énergie que les musiciens se sentent appelés à partager et interpréter collectivement, simultanément. La majorité de ces musiques reste donc principalement enregistrée dans la même pièce et en live (Gordon, 2013). Grâce au format de la prise de trois minutes, le grand public profite alors d’interprétations profondes et uniques de chanteurs de blues comme Howlin’ Wolf9 et de soul comme Otis Redding10, et parfois déchaînées avec Big Mama Thornton11 et Ray Charles12 en R&B.
Mais au cours des années 1960, le label de R&B Motown Records commence à se détacher de cette philosophie. Bien qu’il conserve d’abord l’enregistrement live, son fondateur Berry Gordy se procure en 1965 une nouvelle machine 8 pistes13. Il veut valoriser les riches arrangements des productions de la maison en les enregistrant dans des conditions acoustiques favorables (multi- cabines) et surtout séparément (overdubbing). Pour la chanson Ain’t No Mountain High Enough14 (1967), il enregistre d’abord en live la section rythmique, puis par overdubs successifs, la section de cuivres, de cordes, de percussions, et finit avec le duo vocal Marvin Gaye / Tammi Terrell. Tandis que Chess, Atlantic et Stax privilégient l’énergie musicale commune et instantanée digne des musiques afro-américaines, « Hitsville15 » veut concevoir un produit dédié à tous les publics, en exploitant tous les atouts de l’enregistrement multipiste (Bowman, 1997).
3) La chambre d’écho, signature d’un label
Les studios de musique afro-américaine veulent aussi offrir un espace sonore à leurs enregistrements ; ils construisent dans leurs locaux une ou plusieurs chambres d’écho. Dans ce volume très réverbérant, l’ingénieur du son diffuse la bande d’une piste ou d’un master. Par un micro, il y récupère la source réverbérée qu’il mixe ensuite avec les autres instruments enregistrés. Comme chaque chambre d’écho est unique acoustiquement, elle contribue à définir la signature du label, que le support magnétique est capable de retranscrire (Cogan & Clark, 2003).
Capitol Records, qui produit certains artistes de jazz convertis au R&B comme Louis Prima, en possède quatre dans les années 1950 (figure 6). À dix mètres de profondeur sous les studios de prise, leurs murs épais sont contenus dans un autre volume plus grand et séparé par un système de ressorts pour s’affranchir des vibrations extérieures (principe de la boîte dans la boîte) (Cogan & Clark, 2003). Les ingénieurs du son choisissent aussi la chambre en fonction du format mono ou stéréo du master (Cogan & Clark, 2003). Ces réverbérations naturelles marquent aussitôt le cachet du « son Capitol », comme nous l’entendrons en section II.A.1.1.

4) Le progrès du microsillon
Une fois le produit finalisé, l’enregistrement du magnétophone est gravé sur un disque acétate qui sert de modèle à des matrices utilisées pour le pressage de disques de polychlorure de vinyle (PVC), destinés au commerce (Rumsey & McCormick, 2002). Ce matériau plastique, bien moins lourd, moins fragile et moins coûteux que la gomme-laque (shellac), s’impose très rapidement et durablement sur le marché américain de l’enregistrement. En 1947, le label Columbia brevète le microsillon, un disque vinyle au sillon extrêmement fin qui accroît soudain la qualité audio des enregistrements des années 1950 et crée deux nouveaux formats commerciaux, l’album 33 tours et le single 45 tours (Kimizuka, 2012). En 1952, l’inventeur et ingénieur du son Emory Cook profite de cette finesse de gravure pour appliquer le concept de la gravure stéréophonique de Blumlein (Rumsey & McCormick, 2002) : le microsillon stéréo voit le jour (Barry, 2010). Dès 1958, plusieurs centaines d’enregistrements stéréophoniques sont commercialisés aux États-Unis. Toutefois, ce nouveau mode de gravure présente aussi d’importantes contraintes techniques, très vite compensées par les studios. Par nature, les basses fréquences ont une grande amplitude et une lente modulation (Rumsey & McCormick, 2002). La pointe peine donc à les graver à l’enregistrement et à les reproduire à la lecture du disque. Pour ôter cette contrainte, la Recording Industry Association of America instaure au début des années 1950 l’égalisation RIAA, qui indique à l’ingénieur du son d’atténuer les basses fréquences et d’amplifier les hautes fréquences avant la gravure (Rumsey & McCormick, 2002). Sans respect de cette courbe, la mauvaise gravure des basses fréquences pourrait distordre l’enregistrement et réduire le temps d’enregistrement disponible sur une face de disque. En réglant l’égalisation inverse à la lecture, l’auditeur retrouve le signal original. Cette méthode d’égalisation, approuvée dès 1954 par la majorité des studios américains, contribue grandement au succès populaire du disque vinyle (Stotzer, 2003).
3. La nécessité de privilégier le master monophonique
1) La diffusion radiophonique
Aussi précieux soient leurs nouveaux atouts d’enregistrement et de mixage, les ingénieurs du son sont priés par les producteurs de faire correspondre les masters aux moyens usuels d’écoute du grand public. Car invariablement, l’objectif reste de vendre.
Avant le succès de la télévision dans les années 1960, le moyen dominant pour la diffusion de l’information et de la musique reste la radio. En plus du poste sédentaire du salon, divers appareils à lampe plus petits, plus mobiles et parfois plus fantaisistes viennent satisfaire le quotidien de millions de personnes. Dès 1954, les consommateurs emportent partout avec eux leur petit poste à transistors. Et pour encourager cet usage, la radio FM vient grandement améliorer la qualité du signal émis (Lemesle, 2015). Les labels de distribution envoient donc les disques récemment pressés aux stations radiophoniques locales pour qu’elles diffusent le plus rapidement et le plus souvent possible. Avec cette forme consommatrice de l’écoute musicale, le but est de faire aimer au grand public le nouveau tube de l’artiste et lui donner envie de se procurer le disque 45 tours en magasin (Bowman, 1997). Or tous les postes de radio fixes et mobiles des années 1950-60 sont mono (Lemesle, 2015). Ainsi, malgré l’explosion du format stéréo, plusieurs labels importants de musique blues/R&B/soul exigent encore pendant plusieurs années à l’ingénieur du son de prioriser le rendu sonore du master mono. De cette manière, ils se garantissent une certaine corrélation entre ce qu’ils produisent et ce que les gens entendent.

2) Les disques à commercialiser
Mais la nécessité pour les maisons de disques de favoriser le master mono ne s’arrête pas à la première écoute du grand public ; elle persiste quand ce dernier a acheté leur disque.
Avec l’apparition du microsillon, plusieurs modèles de postes de radio intègrent une platine de disque vinyle. Mais la pointe d’un tourne-disque mono, qui ne se déplace que latéralement, peut user un disque stéréo. Le grand public qui possède majoritairement cet appareil moins coûteux que la platine stéréo, est donc prévenu : une platine mono (figure 8) ne peut lire que des disques mono (Gilotaux, 1967). Non seulement les ingénieurs du son doivent alors systématiquement livrer chaque nouvel album dans les deux formats, mais ils sont priés par le label de privilégier le mixage mono pour favoriser les ventes. Nous verrons alors en section II.B.1.1. et III.B.4. dans quelle mesure ce format dicté il y a 60 ans profite aujourd’hui à la musique.

Finalement, les entreprises phonographiques évitent cette double production en adoptant au cours des années 1960 la gravure universelle, qui modère l’amplitude verticale du sillon, ce qui met les deux canaux plus en phase et densifie donc le centre de l’image stéréo. Ces nouveaux disques stéréo compatibles peuvent être lus par toutes les platines, mais accélèrent la transition vers les platines stéréo (figure 9) pour profiter du nouvel espace sonore (Gilotaux, 1967).

Westinghouse Model 52 MPS 2 (1960)(Source : https://www.pinterest.fr)
B. Dolby Atmos, l’écoute musicale immersive
1. Mixer en Dolby Atmos
1) Présentation de la technologie
Le Dolby Atmos est une technologie de son immersif mise au point par les laboratoires Dolby en 2012. D’abord introduite dans les salles de cinéma, les disques Blu-ray et divers services de streaming vidéo payants, elle commence depuis plusieurs années à investir l’industrie musicale.
En immergeant l’auditeur au sein d’un système de haut-parleurs pouvant atteindre 64 unités, Dolby (2020) lui promet une expérience inouïe. Standardisé 7.1.4 (figure 10), ou parfois 9.1.6, 11.1.8, le Dolby Atmos est en effet l’un des seuls formats audio à proposer une dimension verticale à sa restitution. Dans les salles de cinéma équipées, et plus tard dans les salles de concert, ceci se traduit par l’alignement de deux rangées longitudinales de haut-parleurs suspendus au plafond. Un ou deux caissons de basses à l’arrière de la salle viennent aussi s’y ajouter (Cabanillas, 2020). À la demande des labels musicaux, de plus en plus de studios de mixage, comme le studio Guillaume Tell près de Paris, commencent dès 2016 à s’équiper d’une douzaine de nouveaux haut-parleurs (7 autour de soi, 4 au-dessus et 1 subwoofer pour le standard 7.1.4) et d’un moteur de rendu Dolby Atmos pour mixer ou remixer diverses productions en son immersif. Les ingénieurs du son apprennent donc à mixer en 3 dimensions (largeur, profondeur, hauteur), et à sculpter un nouvel « environnement sonore » pour la musique traitée. Par exemple, s’il le souhaite, cette technologie permet à l’ingénieur du son d’élargir la scène sonore d’un enregistrement symphonique, passant de 60° (stéréo) à 100° ou même 180°. En dissociant les sources, il est aussi en mesure de les démasquer et de former autour d’elles un nouvel espace propre (Simon, 2018).
2) Le mixage orienté objet
En mixage stéréo, l’ingénieur du son place chaque source en fonction des canaux (plutôt vers l’enceinte de gauche, plutôt vers celle de droite, etc.) (Rumsey & McCormick, 2002). En mixage immersif, il n’a plus cette contrainte frontale et peut disposer chaque source, qu’il nomme alors « objet », où il le souhaite dans l’espace sonore formé par le dôme d’enceintes. Très simplement, il peut définir la taille et l’orientation de cet objet dans l’espace, et même lui assigner des trajectoires manuelles ou automatiques, sans jamais se préoccuper de son système de diffusion (Erard, 2020). Il ne se soucie donc plus d’insérer son mixage dans une « image sonore » stéréophonique, mais de construire avec ses objets un « environnement sonore ». Le Dolby Atmos Renderer (figure 11), moteur de rendu du Dolby Atmos communicant avec la station audionumérique, peut accueillir jusqu’à 128 objets en entrée et les diffuser ou exporter vers 64 sorties physiques indépendantes (Dolby, 2021). Dedans, le mixeur peut visuellement y mixer ses sources dans un bed (7.1, 9.1, 11.1…), qui est dépendant du système de diffusion de la régie de mixage, ou bien à la manière d’un mixage orienté objet qui, comme défini précédemment, ne l’est pas. Finalement, le bed, les objets, et les métadonnées de ces objets qui contiennent toutes leurs données spatiales (position dans l’espace 3D, taille, orientation…), constituent le format Dolby Atmos (Dolby, 2020). Au terme du mixage immersif, l’ingénieur du son en réalise un export en 12 canaux, destiné aux plateformes de streaming dont nous étudierons l’offre en section I.B.3.2. Cet export est également encodé en 2 canaux, métadonnées comprises, pour une écoute binaurale au casque. D’autres logiciels de mixage orienté objet existent avec des performances similaires, comme SPAT Revolution16 développé par Flux et l’Ircam, que nous utiliserons dans le cadre de ce mémoire (voir section II.A.2.1.).

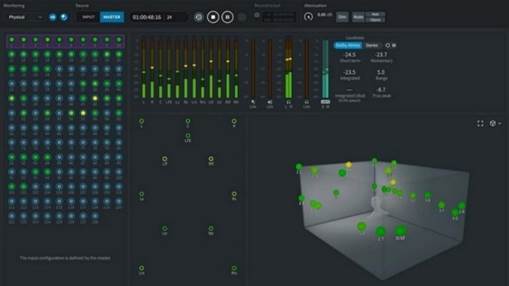
3) Comment mixer en Dolby Atmos ?
Les nouvelles fonctionnalités du mixage en son immersif ouvrent de nouveaux horizons aux méthodes de travail des ingénieurs du son. Néanmoins, ceux-ci doivent garder à l’esprit certains réflexes qu’ils avaient en mixage stéréo. Lors d’une table ronde consacrée au remixage et au remastering en Dolby Atmos d’enregistrements stéréo, certains d’entre eux livrent leur expérience et les habitudes de travail qu’ils ont acquises en la matière (Thornton, 2020). Tout d’abord, tous rappellent qu’il est question avant tout de musique, que comme en stéréo, « le plus important […] est de réaliser un mixage dans lequel l’artiste puisse se reconnaître ». Les ingénieurs du son restent également toujours aussi attentifs à l’écoute du grand public : « Si l’on est distrait par quelque chose qui soit étranger à la musique, alors il y a erreur dans le mixage », annonce l’un d’eux. Cependant, ils reconnaissent que « l’implication de la musique vers la spatialisation n’est pas immédiate, [que] c’est un exercice très difficile ». Par exemple, en devant remixer en son immersif un titre des Rolling Stones à partir des bandes multipistes, l’un des mixeurs déclare qu’il est « très difficile de conserver quelque chose de compact dans un mixage spatialisé ». En travaillant majoritairement en mixage orienté objet, les ingénieurs du son apprécient enfin « ne pas avoir besoin de tasser le mixage dans un petit espace », ce qui les incite souvent à mixer en Dolby Atmos « avec beaucoup plus de dynamique » qu’ils ne le feraient en stéréo, tout en se conformant aux outils de mesures. De cette expérience du mixage stéréo, ils conservent en revanche la vérification nécessaire de la compatibilité aux autres formats. Bien qu’ils reposent leur travail sur la version originale stéréo, ils vérifient davantage la compatibilité de leur mixage avec les autres formats multicanaux (5.1, 7.1…). En particulier, vérifier la compatibilité en binaural demeure essentiel selon eux, car c’est dans ce format que les auditeurs au casque entendront leur produit, après l’encodage du master sur 2 canaux. Enfin, les ingénieurs du son exploitent la nouvelle dimension verticale pour « obtenir quelque chose de plus grand », former avec les enceintes du bas un véritable dôme sonore, pour parvenir à l’immersion recherchée. Finalement, avec l’apport déterminant du mixage orienté objet, ils voient le Dolby Atmos « en passe de devenir le principal medium d’écoute musicale multicanale ». À l’inverse du précédent format 5.1, le Dolby Atmos offre selon eux un « environnement sonore retranscrit intelligemment à partir des canaux latéraux et arrière, mais aussi des informations spatiales des objets sonores ». Dans notre étude, nous observerons en sections III.B.4. et III.C.4. les apports du remixage en son immersif pour une œuvre enregistrée en mono.
2. Le remixage en Dolby Atmos de masters monophoniques : l’exemple de Pet Sounds
1) Origine du projet
Le 2 juin 2023 est sorti une version remixée en Dolby Atmos de l’album Pet Sounds des Beach Boys, enregistré en mono en 1966. Ce projet unique est intervenu à la demande du groupe lui-même, qui a confié les bandes originales multipistes à Giles Martin, fils de George Martin le célèbre producteur des Beatles (Tamarkin, 2023). Pet Sounds marque un tournant dans l’approche d’enregistrement du groupe et a ainsi grandement influencé les Beatles dans leurs productions ultérieures (Lambert, 2008). Précédemment, Giles Martin avait déjà remixé en son immersif plusieurs albums des Beatles comme Sgt. Pepper’s Lonely Hearts Club Band (1967), Abbey Road (1969) puis Revolver (1966) (Tamarkin, 2023).
2) Intérêts et objectifs de remixage
Livrant son expérience, Giles Martin nous donne de précieuses clefs pour le remixage en son immersif de masters monophoniques des années 1960. Honoré de cette demande du groupe, il raconte comment son travail de remixage repose avant tout sur son amour inconditionnel de la version mono originale : « Sur mon bureau, la version mono tourne en boucle. Par essence, je pense que l’idée est de ne pas changer l’ADN de quelque chose mais plutôt d’améliorer l’expérience d’écoute, d’être vraiment à l’écoute de votre ressenti de fan et d’essayer de s’assurer d’honorer l’esprit de l’enregistrement » (Tamarkin, 2023). Ainsi, Martin a voulu penser comme un musicien du groupe, ressentir à travers la version originale leurs intentions. « Vous écoutez le mix mono original et vous essayez de débloquer ce qu’ils essayaient de faire. Vous ne pouvez pas être eux, mais vous essayez de comprendre. Il ne s’agit pas de technologie, il s’agit d’une chanson, et si une chanson vous fait ressentir quelque chose » (Cruse, 2023). Le producteur suit ainsi fortement la priorité musicale confiée par les ingénieurs du son en section I.B.1.3. Mais selon lui, respecter cette musique, c’est aussi voir toutes les « couleurs, les textures et l’imagination » qui composent les morceaux de cet album et qui méritent d’être mieux perçues dans un nouvel espace (The Beach Boys, 2023). « Placer ces sons dans un espace immersif signifie […] que vous pouvez entendre des instruments que vous n’avez jamais entendus auparavant », déclare Martin (The Beach Boys, 2023). Par ailleurs, il est conscient des habitudes d’écoute d’une génération actuelle « qui n’écoute pas de mono » (Cruse, 2023). Ainsi, pour respecter à la fois la musique et les préférences d’écoute d’aujourd’hui, il voit à travers le Dolby Atmos une solution : « La grande chose à propos de l’audio immersif est que vous pouvez avoir des racines au milieu et faire venir des voix autour de vous » (Cruse, 2023). Guidé également par la version stéréo mixée par Mark Linett en 1997, Giles Martin dévoile la démarche qu’il a entreprise et ses principaux objectifs de remixage pour Pet Sounds : « Ce que j’ai essayé de faire, c’est […] de trouver un sens à ce que c’est d’être dans le studio avec le groupe. Je pense que l’intimité est la clé » (Tamarkin, 2023). Par ces termes, Martin annonce l’un des grands enjeux que peut présenter l’évolution immersive d’un master mono original, le réalisme sonore. Il veut ainsi signifier que se sentir devant les musiciens en écoutant un remixage immersif peut pleinement contribuer à capter toute « l’imagination » musicale contenue dans cet album. Finalement, dans cette idée, Martin se sentirait « honoré et privilégié » si ce remixage permettait de ramener l’auditeur « au temps où il a entendu l’album pour la première fois » (Tamarkin, 2023). Démocratiser l’écoute de Pet Sounds, tel est donc avec ce projet immersif le souhait ultime des Beach Boys et de Giles Martin.
3. L’offre du Dolby Atmos au grand public : les plateformes de streaming audio
Examinons à présent à travers l’offre des plateformes de streaming audio, dans quelle mesure les consommateurs de musique ont aujourd’hui accès à des enregistrements mixés ou remixés en Dolby Atmos.
1) Le streaming audio, le medium plébiscité pour l’écoute musicale
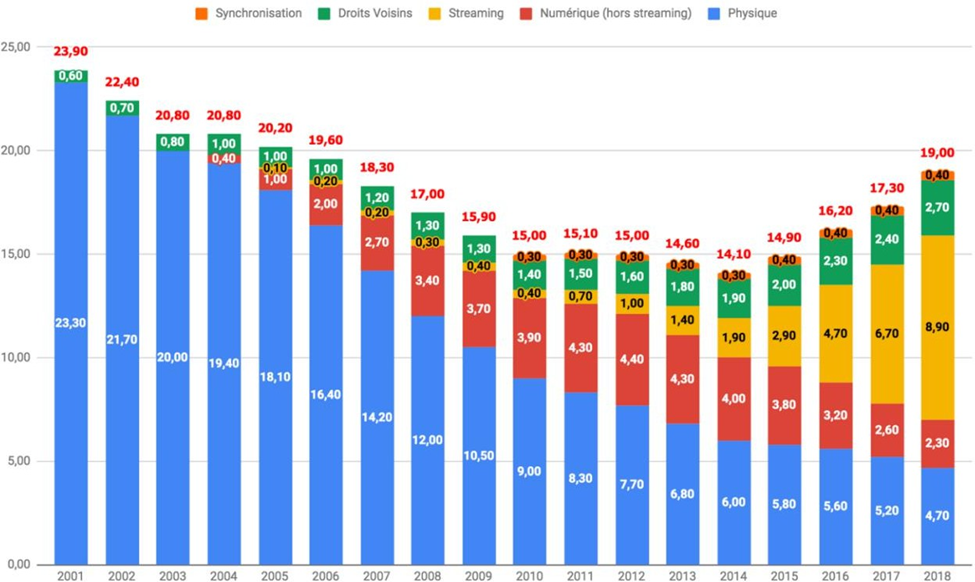
L’écoute musicale constitue une activité du quotidien de plus en plus présente. D’après une étude menée par la Fédération internationale de l’industrie phonographique17 auprès de 44000 personnes du monde entier âgées de 16 à 64 ans (2022), l’écoute hebdomadaire musicale atteint en moyenne dans le monde 20,1 heures en 2022, contre 18,4 heures en 2021. En France, ce volume horaire est passé de 16,6 à 16,9 heures. Nous apprenons qu’en plus du bien-être que la musique provoque selon les personnes sondées, l’une des principales causes de cette croissance d’activité réside dans l’offre soumise. En particulier, les plateformes de streaming audio proposent un choix de musiques extrêmement vaste et varié, le tout à la demande, et sans publicité pour les abonnés. La part des usagers des plateformes de streaming audio (abonnés et non-abonnés) représente aujourd’hui 74% des personnes interrogées dans cette étude exercée dans 22 pays qui représentent 89% des revenus du marché mondial de la musique enregistrée (IFPI, 2022). Mais nous apprenons surtout, en termes de temps d’écoute, que l’écoute musicale par abonnement aux plateformes de streaming audio est le premier moyen d’écoute musicale en France (22%, à égalité avec la radio) et dans le monde (24%). Ces services sont donc à la fois le présent et l’avenir de la consommation de la musique enregistrée dans le monde.
2) L’introduction d’un catalogue musical en son immersif
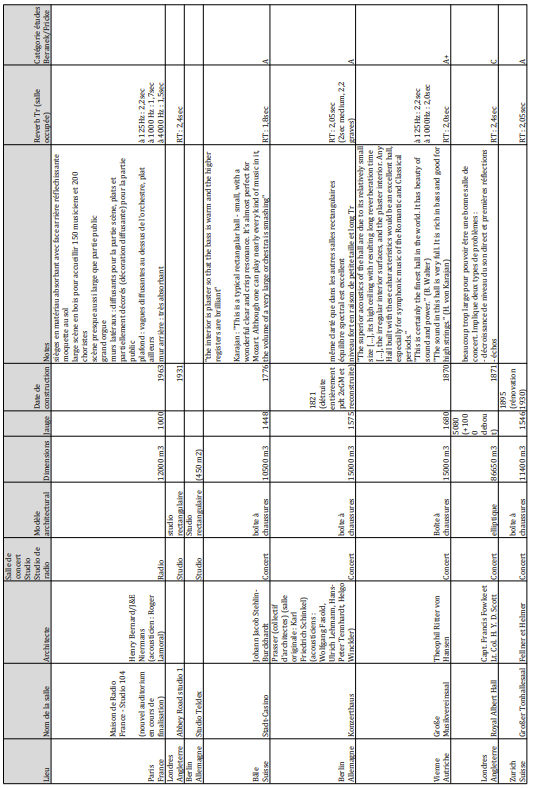
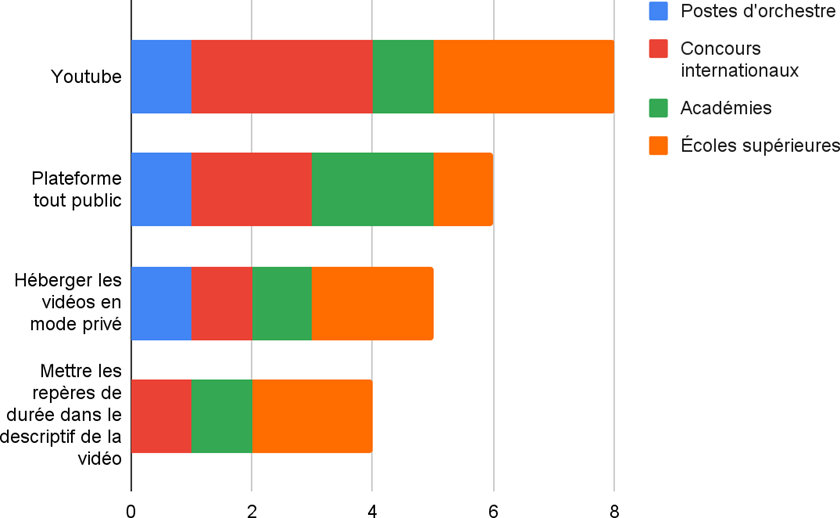
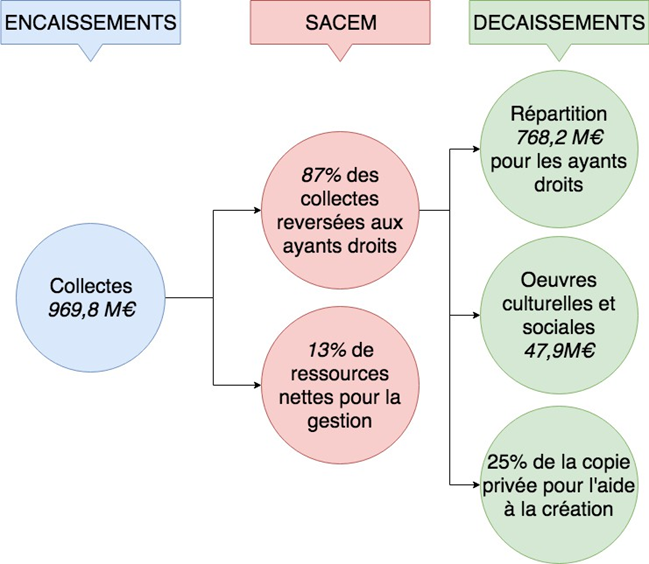
D’après les statistiques données précédemment, il appartient tout logiquement aux différents services de streaming audio de proposer un catalogue d’enregistrements mixés en son immersif. Nous résumons dans le tableau 1 leur offre actuelle en la matière.
| Plateforme de streaming audio | Dolby Atmos | Sony 360 Reality Audio | Stéréo |
| Tidal | X | X | X |
| Amazon Music | X | X | X |
| Apple Music | X | X | |
| Spotify | X | ||
| Tencent Music | X | ||
| Deezer | X | ||
| Qobuz | X | ||
| YouTube Music | X |
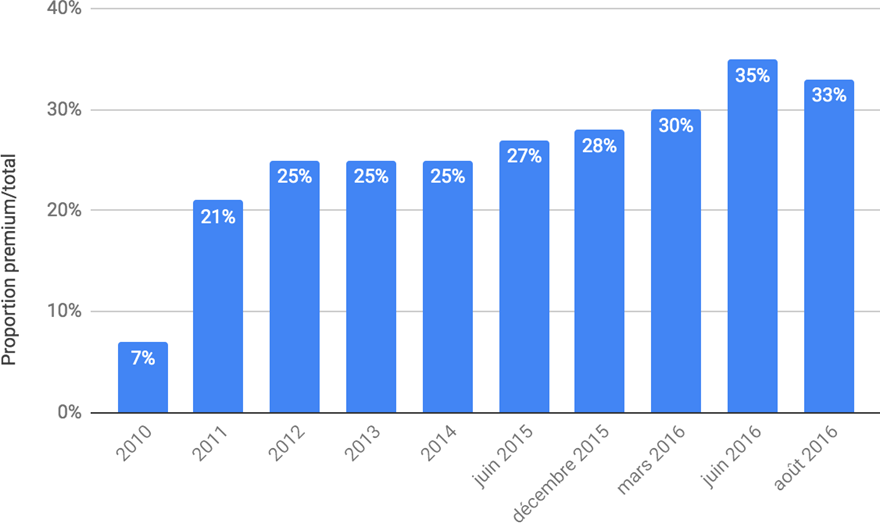
Sur les 8 plateformes de streaming audio qui comptent le plus d’abonnés, 3 proposent des catalogues musicaux en Dolby Atmos (Tidal depuis 2020, Amazon Music et Apple Music depuis 2021). Tidal et Amazon Music s’ouvrent également à l’autre format immersif existant, le Sony 360 Reality Audio (Kagan, 2022). Concentrons-nous sur Apple Music, le deuxième service de streaming le plus utilisé dans le monde en examinant son catalogue Audio Spatial qui réunit plusieurs milliers de mixages et remixages en Dolby Atmos (Apple, 2023). Entre son introduction en juin 2021 et février 2022, le volume du catalogue a été multiplié par 7, dans plus de 20 genres différents (Singleton, 2022). Rien ne garantit toutefois que tous ces enregistrements aient fait comme Pet Sounds (section I.B.2.) l’objet d’un travail de remixage immersif approfondi.
En particulier maintenant, observons à travers l’offre du catalogue Audio Spatial d’Apple Music l’activité actuelle autour du remixage en son immersif de masters monophoniques de blues/R&B/soul des années 1950-60. Nous remarquons que la très grande majorité du catalogue ne concerne que des enregistrements postérieurs à 1980, donc stéréo (Apple, 2023). Et très souvent, ces enregistrements sont contemporains, auquel cas le master immersif sort en même temps que le master stéréo. Parmi les plus anciens artistes dont plusieurs morceaux ont été remixés en Dolby Atmos, citons Neil Young, The Police, Queen, Madonna, Earth, Wind and Fire, ou encore Michael Jackson. Seul le catalogue Audio Spatial Jazz contient un grand nombre d’enregistrements des années 1950-60 (Miles Davis, Wayne Shorter, Oscar Peterson, Art Blakey…), mais tous sont stéréo d’origine, et non mono. Rares sont donc encore les enregistrements monophoniques à avoir connu une transformation immersive. À notre connaissance, les seuls albums enregistrés en mono à avoir été remixés en Dolby Atmos sont ceux des Beatles et des Beach Boys que nous avons cités en section I.B.2.1. En outre, Apple Music (2023) propose un catalogue R&B immersif, mais il s’agit là du R&B contemporain qui, même s’il prend ses racines dans le R&B et la soul que nous avons présentés en section I.A.1.2. et I.A.1.3., a esthétiquement beaucoup évolué depuis l’explosion du hip-hop dans les années 1980-90. À partir de toutes ces données, nous constatons donc qu’il n’y a pas encore d’alignement entre à la fois les enregistrements les plus populaires de blues/R&B/soul et même les enregistrements monophoniques de tout genre musical, et leur présence dans le catalogue d’enregistrements remixés en Dolby Atmos de la plateforme Apple Music.
3) Une réussite commerciale mais encore masquée
Revenons dans notre cadre général et observons si l’introduction du catalogue Audio Spatial en 2021 a produit un effet déclencheur sur la part de marché d’Apple Music dans le domaine du streaming musical. Les éléments statistiques nous obligent à répondre négativement à cette proposition. Bien qu’Apple Music soit le deuxième service de streaming audio le plus plébiscité par le grand public à l’échelle mondiale, sa part de marché (13,7%) ne représente encore que la moitié de celle du leader Spotify (30,5%) (Mulligan, 2022). Or ce dernier, qui ne propose toujours pas de qualité audio lossless18 (Spotify, 2023), semble encore bien loin de vouloir s’ouvrir à l’audio immersif. Après l’introduction de l’Audio Spatial, Apple Music n’a pas vu sa part de marché augmenter entre 2021 et 2022, passant de 15% à 13,7% (Mulligan & Mulligan, 2022). Pourtant, Oliver Schusser, vice-président d’Apple pour Apple Music, affirme : « Nous avons maintenant plus de la moitié de notre base mondiale d’abonnés Apple Music qui écoute en Audio Spatial, et ce nombre augmente en fait très, très vite » (Singleton, 2022).
Pour encourager l’adoption du Dolby Atmos, plusieurs constructeurs comme Sony, Yamaha ou Apple lui-même incluent dans leurs casques audio l’option de head tracking19 et garantissent aux utilisateurs une sensation de réalisme immersif décuplée. Les Apple AirPods sont alors de loin en France les écouteurs sans fil les plus vendus en 2022, avec 53% de part de marché (Licata Caruso, 2022). Mais la même année, 8 des 10 smartphones les plus vendus dans le monde sont des Apple iPhone (Rastogi, 2023). Avec ces informations, il semblerait donc que l’atout pratique de l’audio sans fil et surtout la compatibilité avec les autres appareils Apple soient toujours aux yeux des consommateurs les deux principaux arguments à l’acquisition des écouteurs et casques Apple, loin du souci de l’écoute avec head tracking sur Apple Music.
C. La séparation de sources
1. Définition et applications
La séparation de sources est une technologie de traitement du signal capable de séparer les différentes sources (les instruments en musique) d’un master mono ou stéréo. Elle comporte diverses applications. Disposer des voix instrumentales séparées peut faciliter la transcription de partitions, pour arranger ou illustrer le travail d’un compositeur. En pédagogie également, la séparation de sources peut permettre à un interprète de retirer une partie jouée par un musicien de l’enregistrement, pour se substituer à lui et ainsi s’entraîner virtuellement à jouer une œuvre du répertoire classique/jazz20 avec les autres instruments de l’ensemble, comme proposée par l’application NomadPlay (Chalot & Guittet, 2017). Pour l’indexation musicale, la détection de certains instruments favorise l’identification automatique du style musical (Richard et al., 2013). Enfin, traiter individuellement le son de chaque source dans un travail de remixage du morceau est l’application qui nous intéresse dans notre étude, en particulier pour des enregistrements dont les multipistes n’ont jamais existé, comme expliqué en section I.A.2.1. (Clavel, 2003).
2. Les deux modes de séparation de sources
1) Factorisation en matrices non négatives (NMF)
La factorisation en matrices non-négatives21 est un mode de séparation pour les sources émettant des sons harmoniques. Elle se charge de scinder le signal harmonique et le signal inharmonique du signal original, sous le nom de « séparation harmonique/percussive », pour réaliser ensuite une analyse harmonique (Müller, 2021).
a. La séparation harmonique/percussive préalable
Comme rappelé par Müller (2021) et illustré en figure 12, un signal harmonique est visible dans le sens horizontal d’un spectrogramme (représentation temps/fréquence) : sa fréquence fondamentale et ses harmoniques, multiples de la fondamentale, se superposent, et sa durée peut être étendue selon l’entretien du son par l’instrument. Un signal percussif se détecte lui dans le sens vertical : il se compose de toutes les fréquences à des niveaux distincts et sa durée est limitée.
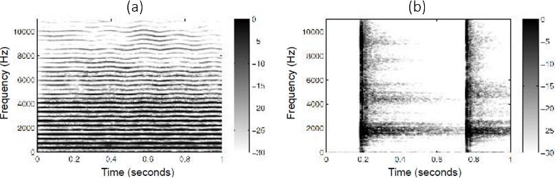
Considérons un bref signal comportant un son harmonique et deux sons percussifs, dont nous obtenons le spectrogramme par Transformée de Fourier à Court Terme (STFT). L’objectif de la séparation harmonique/percussive est alors de décomposer ce dernier en deux spectrogrammes semblables à la figure 12 (Müller, 2021).
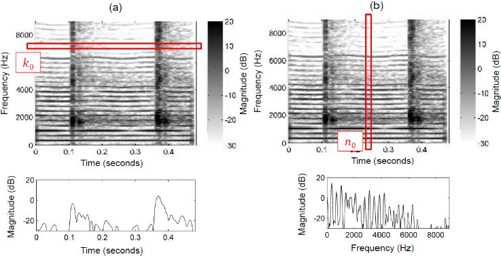
Pour cela, deux fonctions de filtrage doivent être créées : une fonction H avec la fréquence k variable et le temps n fixe, pour prévenir d’un événement percussif. Et une fonction P avec la fréquence k fixe et le temps n variable, pour prévenir d’un événement harmonique. En faisant défiler chaque fonction sur son axe respectif (figure 13), on obtient par détection des maximas et après filtrage le spectrogramme des événements harmoniques et celui des événements percussifs.
Or l’intensité et la précision de chaque filtrage dépend du nombre de valeurs respectives. Ces spectrogrammes pseudo-harmonique YH et pseudo-percussif YP ne peuvent donc être retenus comme denrée fiable de séparation (Müller, 2021). De ceux-ci, on préfère générer deux masques binaires définis ainsi :
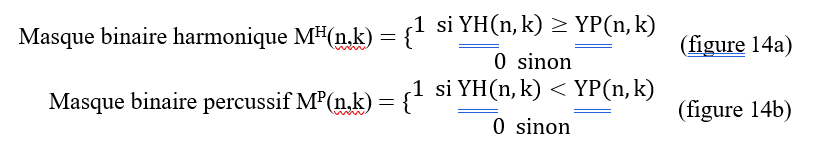
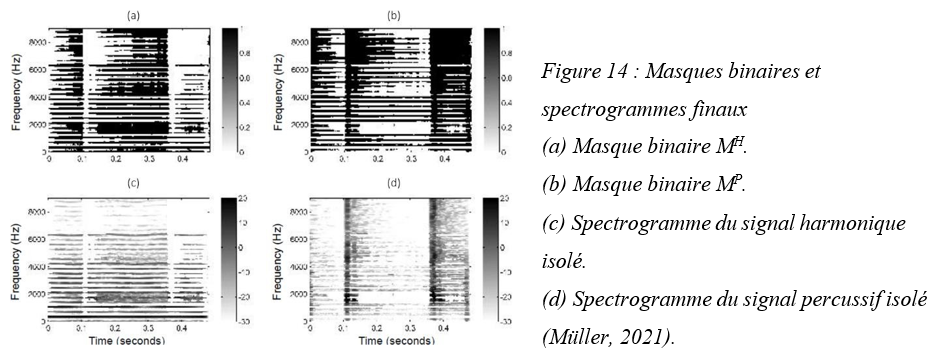
On applique les masques MH et MP directement au spectrogramme original pour obtenir le spectrogramme harmonique (figure 14c) et percussif (figure 14d). Par transformée STFT inverse, on obtient enfin séparément le signal harmonique et le signal percussif (Müller, 2021).
b. La décomposition matricielle du signal harmonique
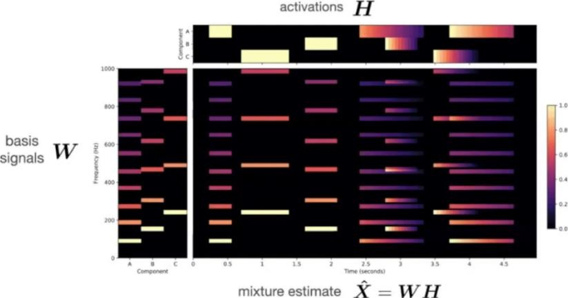
Tous les harmoniques d’une note jouée par instrument surgissent puis disparaissent sensiblement en même temps. Selon les termes de Gaël Richard, spécialiste du traitement du signal audio, ils « s’activent » puis « se désactivent » simultanément entre eux (I’MTech, 2020). Avant de séparer les sources en jeu dans un enregistrement, la factorisation en matrices non- négatives permet d’abord de séparer toutes les notes jouées, toutes sources confondues. Elle décompose la matrice du signal harmonique en deux matrices : la matrice « dictionnaire », qui renseigne l’ensemble des notes et leurs harmoniques jouées, et la matrice « activations », qui dit à quel moment chacun d’eux intervient dans la séquence (figure 15) (Ewert & Müller, 2012). Comme le nombre et l’intensité des harmoniques joués définit le timbre d’une source, le modèle NMF regroupe les notes ayant un même profil harmonique et leur attribue une source. Ainsi, elle reconstitue individuellement chacune d’elles en remultipliant les deux matrices décomposées et en prenant soin de fixer à 0 toutes les activations des notes au profil harmonique différent, et donc jouées par d’autres sources (Ewert & Müller, 2012).
La NMF n’est pas seulement capable de séparer des sources. Ewert et Müller (2012) ont réussi à séparer la main droite et la main gauche d’un enregistrement monophonique de piano, en renseignant au modèle NMF la partition musicale exécutée dans l’extrait sonore. Mais cette séparation de sources informée ne donnant pas encore satisfaction, ils ont vu l’intérêt de demander au modèle NMF de représenter simultanément la matrice « dictionnaire » et la matrice « activations ». Pour l’aider à cela, ils lui ont transmis au préalable les informations temporelles MIDI du signal original, ce qui lui a permis d’effectuer à part l’analyse des fréquences.
c. Avantages et limites
La NMF présente plusieurs avantages. D’abord, elle ne demande pas de grandes capacités de calcul, tout s’opérant par analyse spectrale (Ewert & Müller, 2012). De plus, elle exploite sa capacité d’analyse harmonique pour isoler plus d’instruments de ce type que la méthode par apprentissage profond, que nous expliquerons en section I.C.2.2.
En revanche, son modèle de décomposition matricielle ne se limite qu’aux sons harmoniques, ce qui l’oblige au préalable à les séparer des sons inharmoniques ou percussifs, dont elle n’est pas en mesure de détecter ni d’isoler les sources en cause. Le modèle harmonique contient aussi une limite importante, puisque lorsqu’une même note est jouée par plusieurs instruments, il lui est difficile de distinguer quels harmoniques appartiennent à quel instrument. Par conséquent, il n’est pas rare que la séparation de sources par NMF laisse apparaître quelques interférences entre certaines sources soi-disant isolées (Liutkus et al., 2013).
2) Apprentissage profond
a. Notions et définitions
L’intelligence artificielle (IA) est un domaine de l’informatique visant à mimer l’intelligence humaine. En s’extrayant du domaine de la programmation dans lequel la machine esclave doit exécuter des tâches assignées, la machine d’intelligence artificielle apprend, à travers différents essais et erreurs, comme le ferait un cerveau humain. (Le Cun, 2019). Dans la plupart des applications, elle agit souvent dans une recherche de gain de temps pour l’être humain, se substituant souvent à lui, comme pour effectuer un diagnostic médical ou immobilier.
L’apprentissage automatique22 est l’un des principaux champs d’étude de l’IA. À partir d’une grande quantité de données qu’on lui fournit, un algorithme d’apprentissage automatique va constituer seul des modèles qui lui permettront de prédire un résultat (Le Cun, 2019). Dans le domaine audio, ses applications sont nombreuses : reconnaissance et classification de sons (voiture, chien, marteau), conversion de texte en discours et inversement, reconnaissance d’enregistrements commercialisés (ex : application Shazam) (Facciotto et al., 2017). L’opérateur évalue alors la différence entre ce qu’il sait ou souhaite faire, et ce que livre l’algorithme.
Sous-branche de l’apprentissage automatique, la machine d’apprentissage profond23 est plus autonome et plus perfectionniste : elle réussit à identifier les erreurs qu’elle commet, les prend en compte pour recommencer son calcul et optimiser le résultat qu’elle offre (Le Cun, 2019). S’inspirant du modèle du cerveau humain, elle comprend un vaste réseau de neurones artificiels qui se réorganise sans cesse pour améliorer son rendement. Ce réseau, réparti en plusieurs couches communicantes, s’agrandit perpétuellement au cours de l’apprentissage pour définir son niveau d’expérience et ainsi son niveau de performance. Ainsi, par analogie à la plasticité synaptique du système neuronal humain, plus la machine reçoit de données et plus elle rencontre d’expériences différentes, plus elle sera performante. Quand l’algorithme d’apprentissage automatique traite plusieurs milliers de données, les réseaux de neurones en gèrent plusieurs millions, ce qui leur demande beaucoup de ressources GPU24 et donc un temps de travail plus important (LeCun, 2016). Pour toutes ces raisons, l’apprentissage profond s’étend avec une efficacité exemplaire à de nombreux domaines d’application : reconnaissance vocale et faciale, traduction automatique des langues25, reconnaissance d’objets ou de personnes sur une image26, création d’une œuvre « à la manière de », véhicule autonome et donc, séparation de sources sonores (LeCun, 2016).
b. Séparation par apprentissage supervisé
Dans l’apprentissage automatique supervisé, la machine est guidée. En recevant de notre part le problème original et les résultats qu’elle doit en obtenir, elle cherche en continu au cours de son apprentissage à restreindre l’écart entre ceux-ci et ceux qu’elle obtient (Le Cun, 2019). Appliqué à la séparation de sources, nous définissons un cadre à la machine : nous lui fournissons un catalogue d’enregistrements contenant notamment chacun une batterie (ou des percussions), une basse (ou une contrebasse), et une ou plusieurs voix, et en guise de modèle d’apprentissage, chaque prise de son originale de ces sources en proximité (Schulze-Forster, 2021). En confrontant ces deux types d’information, la machine détecte des similitudes entre la plupart des masters : elle identifie une même source souvent prépondérante (la voix), une autre occupant essentiellement le bas du spectre (la basse), une autre percussive, sans harmonicité (la batterie), et le reste des sources sans réelle similarité. Cette phase d’identification est typique du réseau de neurones convolutif (CNN), qui apprend à extraire les caractéristiques de chaque objet pour en établir une classification qui lui permettra de le reconnaître à nouveau (Schulze-Forster, 2021). Pour affiner son analyse du signal entrant, la machine le lit à l’endroit et à l’envers. Puis elle apprend sur tous les masters reçus à isoler ces trois sources, suivant le modèle des fichiers multipistes.
Parmi les bases de données libres de droits pour encourager la recherche, citons la RWC Music Database qui regroupe les sons multipistes et informations MIDI de 315 œuvres de musique classique, jazz, instrumentale et populaire de divers pays du monde (Goto, 2002). Le critère du libre accès s’avère en effet essentiel car, pour l’apprentissage profond, plus le réseau de neurones se confronte à des esthétiques différentes, plus il se montrera performant lors d’une prochaine séparation. Initiée en 2013, la séparation de sources par apprentissage supervisé demeure aujourd’hui la méthode la plus employée pour séparer les sources d’un enregistrement, si toutefois celui-ci répond aux conditions que nous donnons ci-dessous (Schulze-Forster, 2021).
c. Avantages et limites
Tous les outils de séparation de sources actuellement disponibles sur le marché, dont trois seront présentés en section I.C.3., emploient une méthode de séparation par apprentissage supervisé. En effet, la découverte d’architectures de réseaux très performantes, l’accroissement de la puissance de calcul des processeurs graphiques et l’amélioration de la disponibilité des données d’entrée font sans cesse évoluer le modèle, donnant des résultats en progrès constant. C’est pourquoi, à l’inverse de la méthode par NMF, une séparation de sources effectuée par apprentissage profond offre pour n’importe quelle source une meilleure qualité de séparation que celle qu’on aurait opéré il y a quelques années. Le meilleur de l’IA en matière de séparation de sources est donc à venir (Miron et al., 2016).
En revanche, le modèle d’apprentissage supervisé englobe certaines limites, des prérequis que l’enregistrement doit détenir pour une séparation de sources réussie. Tout d’abord, les réseaux de neurones sont aujourd’hui entraînés pour ne séparer un enregistrement qu’en quatre stems : voix / basse / batterie / autres, le stem « autres » regroupant tous les signaux que l’outil n’a pas su isoler (Hennequin et al., 2020). Bien qu’elle soit une première avancée en matière d’apprentissage profond, cette limite empêche ainsi pour le moment les enregistrements de grandes formations27 et certains styles musicaux aux instruments différents (jazz, musiques du monde) de bénéficier de ce procédé. De plus, même lorsque l’effectif instrumental répond aux exigences, le réseau de neurones a besoin d’une grande base de données audio pour apprendre à isoler. Or il n’est pas toujours aisé d’avoir accès aux multipistes d’enregistrements ayant des caractéristiques instrumentales et sonores proches de celui que nous voulons traiter (Schulze-Forster, 2021). Par exemple, pour séparer les sources d’un enregistrement de big band des années 1930-40, il faut trouver des enregistrements multipistes de big band avec une empreinte sonore similaire à celle des enregistrements de cette période (timbres et dynamique restreints, souffle, etc.). Or comme annoncé en section I.A.2.2., l’enregistrement multipiste ne naît que 20 ans après. Comme il implique la création d’une nouvelle base de données, ce cas constitue aujourd’hui l’un des principaux intérêts de la recherche en séparation de sources. Plus généralement, même pour les modèles actuels de séparation par apprentissage supervisé, il n’est pas rare que la machine éprouve des difficultés à isoler les sources d’un enregistrement dont l’équilibre ou les timbres sont différents de ceux sur lesquels elle a appris. En particulier, si un instrument est déjà mal reproduit ou trop discret dans le mixage original à cause d’une prise de son limitée, l’outil ne peut pas l’isoler et le rendre soudain plus défini. En outre, quand beaucoup de fréquences provenant de différentes sources se chevauchent, la séparation des sources peut grandement se compliquer (Schulze-Forster, 2021). Comme la machine apprend en essayant, elle laisse d’abord apparaître dans quelques stems quelques artefacts audibles en hautes fréquences, qui s’atténuent au fur et à mesure que le réseau de neurones se développe. Et comme elle agit individuellement sur chaque canal, séparer les sources d’un master stéréo est plus facile pour elle, profitant d’un premier démasquage spatial. Enfin, l’un des principaux enjeux du procédé concerne actuellement la réverbération. Non seulement celle-ci floute la source à laquelle elle appartient, mais elle masque également les autres sources. Pour certains modèles en apprentissage profond, elle peut complexifier la séparation, en particulier en queue de réverbération dont le niveau plus faible brouille son appartenance à telle ou telle source (Miron et al., 2016).
Cela dit, malgré les éventuels artefacts et manques révélés dans chaque source isolée, la séparation de sources par apprentissage profond n’occasionne aucune perte de signal, pas même le souffle d’un enregistrement. Ainsi, si l’on additionne toutes les sources séparées, on aboutit véritablement au master original qu’on a fourni à la machine. En d’autres termes, le masquage des sources, qui contribue en fait à ce que l’on perçoit d’elles dans le mixage original, se reforme. Dans une séance spécifique que nous organiserons, nous découvrions donc en section II.B.2.2. quelles sont les limites de la séparation de sources par apprentissage profond pour un remixage en son spatialisé, qui implique d’assembler les sources isolées.
3. Les logiciels de séparation de sources disponibles
1) Le moteur primaire de séparation : Spleeter (Deezer)
En 2019, le groupe de recherches de la plateforme de streaming musical Deezer lance Spleeter, un outil de séparation de sources reposant sur le fonctionnement de réseaux de neurones conçus et pré-entraînés avec l’outil d’apprentissage automatique TensorFlow (Hennequin et al., 2020). Prenant comme modèle la base de données musdb18 qui compte 150 morceaux de genres variés et leurs fichiers multipistes (au moins une batterie, une basse et des voix), il propose trois options de séparation : une séparation en 2 stems voix/accompagnement, une autre en 4 stems voix / basse / batterie / autres, et une en 5 stems en isolant en plus le piano. Avec Open-Unmix, Demucs et Nussl, Spleeter est l’un des premiers outils de séparation de sources en libre accès à publier les codes Python qui l’ont généré, afin de permettre à chacun de peaufiner l’apprentissage des modèles pré-entraînés avec TensorFlow, aussi en libre accès (Hennequin et al., 2021). Opérant une séparation en 4 stems jusqu’à 100 fois plus vite que le temps réel en utilisant un seul GPU (entraîné pendant une semaine), il est l’un des séparateurs les plus performants sur musdb18. Toute amélioration de résultat s’effectue par un nouveau codage (Hennequin et al., 2020).
2) L’édition spectrale manuelle : SpectraLayers (Steinberg)
À son origine en 2012 et pendant plusieurs années, le logiciel SpectraLayers est un outil d’édition et de restauration spectrale audionumérique qui permet de retirer ou de corriger directement sur spectrogramme certains défauts présents dans un enregistrement, comme des bruits acoustiques, des clics numériques, du souffle, des sons sibilants, une réverbération trop présente, etc. (Dobrev, 2020). En 2020, son éditeur Steinberg décide d’inclure dans la version 7 la fonctionnalité de séparation de sources, en reprenant les modèles pré-entraînés de Spleeter (Hennequin et al., 2021). Comme celui-ci, le logiciel est donc capable de diviser un master en 2, 4 ou 5 stems selon notre choix. Mais de manière très ergonomique, il offre à l’utilisateur la possibilité de prolonger et d’améliorer manuellement la séparation effectuée automatiquement. Lorsque l’on entend et l’on voit sur le spectrogramme d’un stem issu de la séparation, par exemple celui de la « Batterie », que certaines fréquences doivent normalement appartenir au stem « Voix », nous pouvons les encadrer précisément et les déplacer dans un nouveau stem que l’on crée et que l’on superposera au stem « Voix ». Ainsi, la voix retrouve un spectre plus complet et témoigne d’une amélioration de la qualité de séparation des sources. Ici, un stem est aussi appelé layer (calque), d’où le nom SpectraLayers et son idée de corriger puis superposer des calques spectraux. Par conséquent, cet éditeur spectral peut nous permettre d’obtenir une division de master en plus de 5 stems. En effet, la retouche manuelle des spectrogrammes peut aussi bien sûr s’appliquer au stem « Autres » qui contient souvent plusieurs instruments. Si ceux-ci présentent des profils spectraux suffisamment distincts, il nous est possible de les identifier, de les sélectionner et de les placer convenablement dans un nouveau calque réservé à chaque nouvelle source isolée. Nous expliquerons et illustrerons en section II.A.1.2. notre utilisation de cet outil.
3) La détection automatique des harmoniques : RipX (Hit’n’Mix)
À l’instar de SpectraLayers, RipX n’est initialement pas un outil de séparation de sources, bien que ses premières fonctionnalités s’en approchent et finissent même par servir le processus. À l’origine, Martin Dawe, son créateur, souhaite concevoir un outil capable de générer une partition musicale à partir d’un enregistrement polyphonique (Hit’n’Mix, 2023). Son premier souci est alors d’en séparer toutes les notes jouées. Après s’être heurté aux limites d’un modèle d’analyse spectrale similaire à la NMF (section I.C.2.1.), il commence à écrire un algorithme pour la détection automatique des hauteurs de notes, qu’il voit comme la clé de la réussite. Cet outil, capable de distinguer les hauteurs de différentes fréquences (fondamentales et harmoniques), en récolte également d’autres détails (amplitude, phase, variations de hauteur) qui lui permettent de relier chaque fréquence fondamentale à ses harmoniques. Ces informations deviennent si détaillées que Dawe essaie un jour à partir d’elles de resynthétiser chaque note. Malgré les premiers essais balbutiants, Dawe a un nouveau projet : pouvoir manipuler individuellement chaque note d’un enregistrement (modifier sa hauteur, sa longueur, ajouter un vibrato…). Il publie un premier logiciel, Hit’n’mix Play, qui permet non seulement ces manipulations mais aussi d’entendre chaque instrument de l’enregistrement. Mais il est conscient que la qualité de restitution des sons est largement en-deçà de l’exigence professionnelle. Ainsi pendant près de 10 ans, il se consacre à densifier son programme pour aboutir à une qualité audio digne d’un usage professionnel. En 2019, il fait paraître Hit’n’Mix Infinity, un outil hautement salué mais dont la qualité de séparation se heurte encore parfois au problème de chevauchement de fréquences de sources à l’unisson. Or, eu égard à l’actualité, Dawe constate que les tout récents modèles de séparation de sources conçus par apprentissage supervisé, dont Spleeter, se montrent plus robustes face à ce problème, pour isoler la voix, le piano, la basse et la batterie. Il décide donc de compléter son propre programme par une phase d’apprentissage automatique, le menant à la création d’un logiciel hybride, RipX (figure 16). Comme il a été formé à détecter les harmoniques des notes, l’algorithme de Dawe peut théoriquement isoler plus de sources (guitare, cordes) que les modèles actuels d’apprentissage profond, mais ceux-ci apprennent à réaliser des tâches délicates comme la distinction des harmoniques proches. Ces deux méthodes de séparation de sources viennent donc ici se compléter. Nous examinerons avec précision les fruits de ce mariage en section III.A.1.
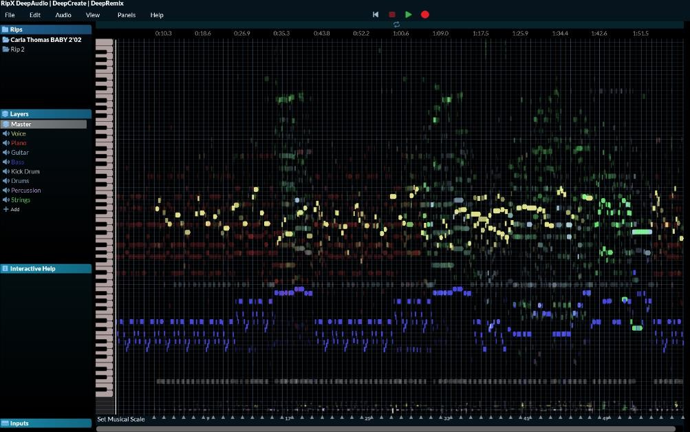
II. Expérience n° 1 : remixage en son spatialisé de trois masters monophoniques des années 1950-60
Pour traiter en profondeur les deux grandes problématiques a et b introduites, l’expérience n°1 s’avère fondatrice. Elle vise à étudier et à comprendre les comportements de réflexion, d’écoute et de remixage d’ingénieurs du son, de musiciens et d’experts musicaux de la période 1950-6028, face à des masters originaux d’enregistrements blues, R&B et soul de ces années. Reposant sur un entretien préliminaire, une écoute de masters originaux mono, puis une séance de remixage en son spatialisé, elle s’applique à répondre aux questions suivantes :
QR1 : Dans quelle mesure les participants jugent que le rendu sonore général de la version originale est en accord avec les caractéristiques musicales de la chanson abordée, qu’ils ont eux- mêmes listées préalablement ?
QR2 : Dans quelle mesure ingénieurs du son, musiciens et experts du répertoire musical ciblé modifient-ils le rendu sonore de masters de blues, R&B, soul produits dans les années 1950-60 dans le cadre d’une séance de remixage en son spatialisé ?
QR3 : Dans quelle mesure les participants jugent que le rendu sonore général de leur version partiellement remixée est en meilleur accord avec les caractéristiques musicales de la chanson traitée, qu’ils ont eux-mêmes listées préalablement ?
QR4 : Dans quelle mesure les choix de remixage des participants sont-ils cohérents avec leur conception de la relation entre une œuvre musicale et son esthétique sonore d’enregistrement dans le contexte des musiques écrites et enregistrées dans les années 1950-60 ?
Après avoir expliqué le travail de préparation et justifié le protocole de l’expérience, nous en présenterons puis en discuterons les résultats, avant de conclure.
A. Méthode expérimentale
1. Travail préliminaire : séparation des sources de 4 masters monophoniques des années 1950-60
Pour la séance de remixage, nous devons d’abord minutieusement isoler les signaux de quatre enregistrements monophoniques de la période ciblée, avant de les présenter aux participants.
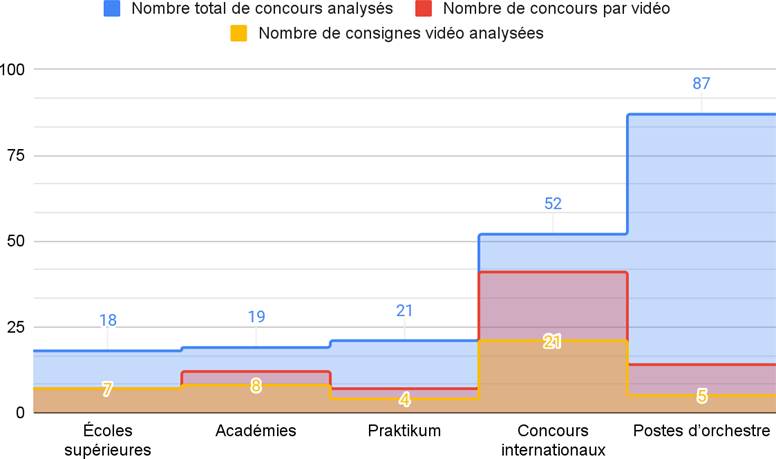
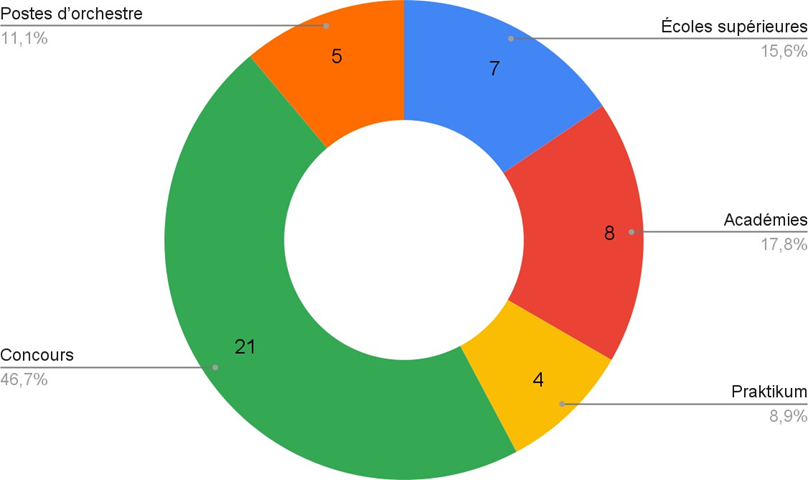
1) Choix des 4 masters monophoniques
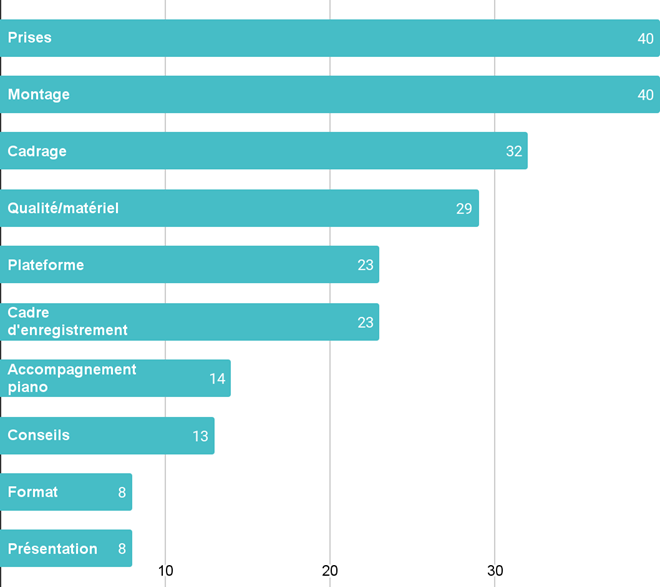
De cette période 1950-60, nous cherchons trois enregistrements de genres précis – blues, R&B et soul – et un quatrième de genre différent, qui servira d’enregistrement-test aux participants (section II.A.3.2.c.). Comme exposé en section I.C.2.2.c., chaque enregistrement doit valider, pour une séparation optimale des sources avec un outil d’apprentissage profond, les prérequis suivants :
- Un effectif instrumental mesuré : voix, piano, claviers, cuivres, guitare (optimisation éventuellement possible pour les trois derniers), basse et batterie, au maximum. Pas d’autres instruments à cordes ou à percussion ;
- Eviter les morceaux avec unissons et interventions simultanées, notamment entre voix et cuivres, voix et chœurs, piano et guitare ;
- Une définition et une transparence correctes d’enregistrement, pour identifier aisément chaque instrument actif.
Après une revue d’écoute attentive et motivée par ces critères, nous avons choisi pour l’expérience n°1 de séparer les sources des quatre enregistrements monophoniques suivants :
- m1. Wonder What is Wrong with Me – Lightnin’ Hopkins (1956) · Blues. Effectif : voix lead, guitare électrique, contrebasse, batterie

- m2. Oh, Marie – Louis Prima (1959) · Jazz/R&B. Effectif : voix lead, chœurs, cuivres, piano, guitare, contrebasse, batterie

- m3. B-A-B-Y – Carla Thomas (1966) · Soul. Effectif : voix lead, chœurs, cuivres, orgue, piano, guitare, basse, batterie

- m4. Just Call Me Lonesome – Jim Reeves (1959) · Country [enregistrement-test] Effectif : voix lead, guitare solo, guitare rythmique, piano, contrebasse, batterie

Les trois premières chansons, aux atmosphères contrastantes, partagent des instruments semblables aux fonctions variées selon le genre. On peut donc supposer qu’elles suscitent des réflexions distinctes chez les participants, influencées par la relation singulière entre chaque esthétique sonore et chaque style musical enregistré. L’exception à noter est que les deux guitares dans la chanson country ne peuvent pas être dissociées, ce qui n’altère toutefois pas l’objectif d’essai de cet enregistrement. Nous donnons en annexe B1 toutes les informations relatives à ces quatre enregistrements.
2) Choix du logiciel de séparation de sources : SpectraLayers
Nous allons maintenant nous pencher sur la séparation de sources des trois enregistrements – sujets de l’expérience n°1 (m1, m2, m3), bien que l’enregistrement m4 ait subi strictement les mêmes opérations. Nous avons choisi pour cela l’outil SpectraLayers, présenté dans la section
I.C.3.2. En effet, la retouche manuelle de séparation que nous avons réalisée sur les différents calques de spectrogrammes s’avère être un atout de choix, particulièrement concernant les signaux d’instruments non séparés automatiquement, comme :
- La voix et les chœurs dans le stem « Voix » d’Oh, Marie de Louis Prima et de B-A-B-Y de Carla Thomas ;
- Le saxophone ténor solo, les cuivres et la guitare dans le stem « Autres » d’Oh, Marie ;
- Les cuivres, la guitare et l’orgue dans le stem « Autres » de B-A-B-Y.
Plus généralement, notre retouche manuelle permet de prolonger et d’affiner la séparation résultante de l’apprentissage profond. En sélectionnant certaines fréquences ou groupes de fréquences de la source A, placées par erreur dans le stem de la source B lors de la séparation initiale, nous les avons réintégrées dans le stem de la source A, nouvellement créé ou préexistant. Le bénéfice est double : libérer tous les signaux utiles de certains masques et reconstituer les sources dispersées dans différents stems par le logiciel. De toute évidence, ce dernier aurait théoriquement dû effectuer ce travail, dont on déduit déjà une première limite du modèle de séparation de sources par apprentissage profond sans détection des harmoniques des notes.
Les figures 17 et 18 montrent respectivement de façon générale et fine l’efficacité de notre édition spectrale lorsque certaines empreintes fréquentielles se trouvent par erreur dans le stem d’une autre source. Les figures 19 et 20 témoignent, elles, d’une précision certaine de l’outil quand nous sélectionnons des fréquences appartenant à une même source pour en créer un nouveau stem, non généré par l’apprentissage profond. Dans la figure 20, nous avons récupéré une quantité importante d’harmoniques dans le stem « Autres » pour la « Voix » de Prima (dont le spectre s’est aussitôt reformé). Nous l’avons ensuite scindé en un stem « Voix » définitif et un nouveau stem « Sax dialogue ». À l’instar des sources, les possibilités de remixage semblent déjà se multiplier.
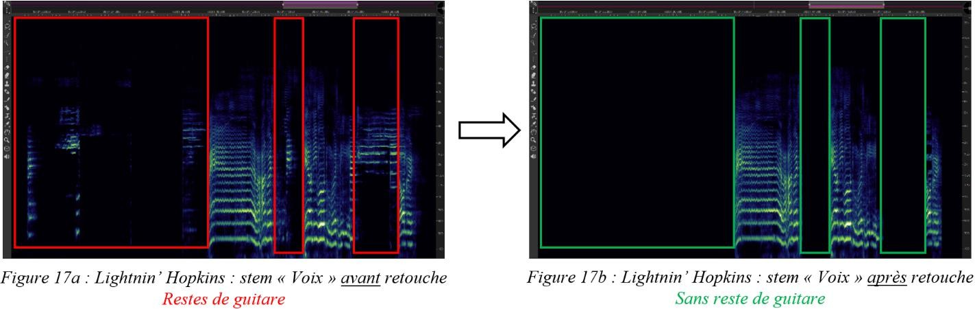
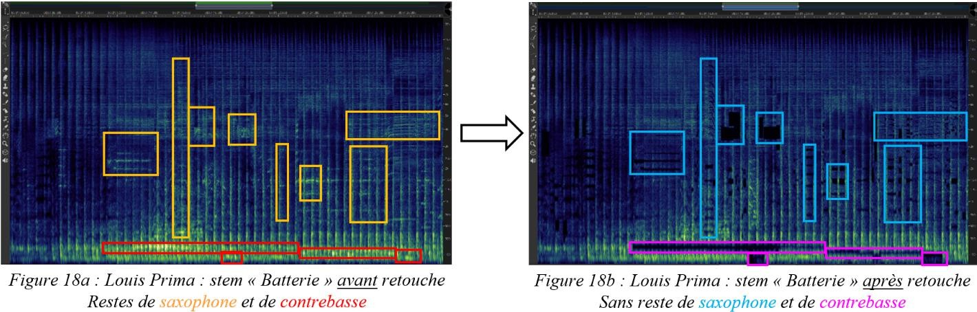

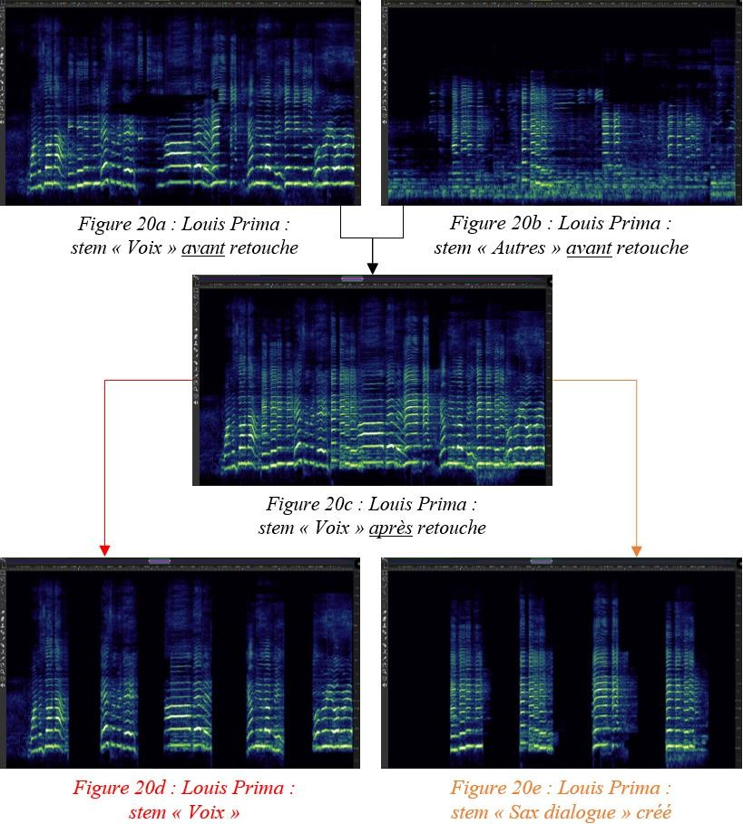

Toutefois, malgré sa capacité théorique à isoler le piano, la réalité diffère. La figure 21 révèle ce défaut, le stem « Piano » original de B-A-B-Y apparaissant très peu fourni car le signal de l’instrument se trouve en fait principalement dans le stem « Autres ». Certes notre retouche manuelle corrige facilement cet écart, mais elle montre encore les limites d’un système ne détectant pas les harmoniques des notes. Mais après l’une de nos tentatives, l’isolation du piano dans un morceau où l’instrument est plus présent donne des résultats plus probants. Il semblerait donc que l’équilibre des niveaux entre les sources du master influence la qualité de leur séparation.
À l’issue de ce long travail – une vingtaine d’heures passées par morceau –, nous avons obtenu pour chaque enregistrement-sujet le signal des sources suivantes :
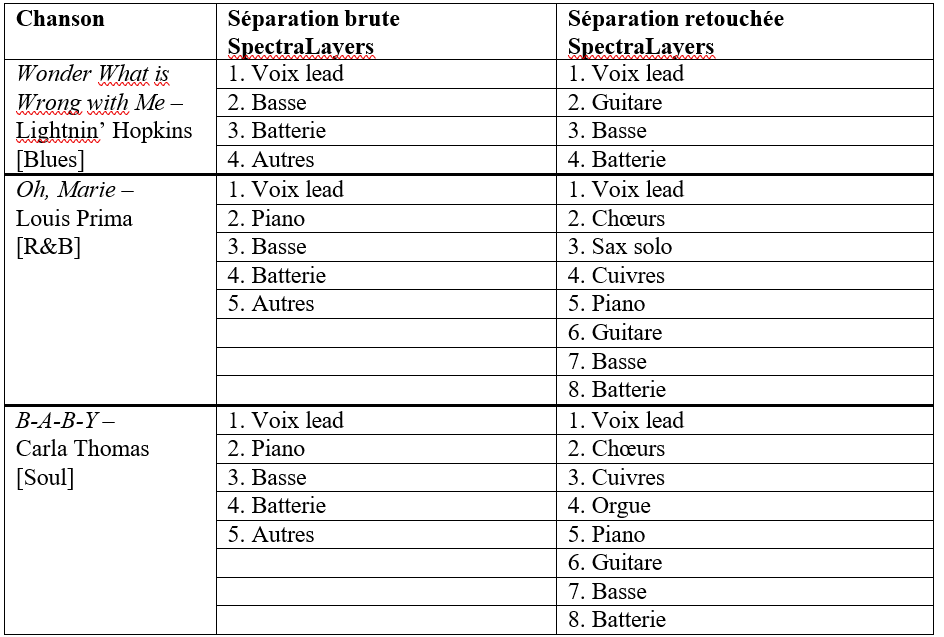
Reste à savoir dans quelle mesure cette qualité de séparation permettra aux participants de l’expérience de réaliser leurs envies de remixage. Nous l’expliciterons dans la section II.B.2.2.
2. Préparation de l’expérience
1) Conception d’une interface simplifiée de remixage à l’usage des participants
Comme abordé dans la section II.A.3.1, notre expérience s’adresse à une majorité de participants non-ingénieurs du son, non-initiés au mixage. Il est donc primordial que l’interface de remixage que nous mettrons à leur disposition soit simplifiée et intuitive pour leur permettre de penser d’abord par la musique, notre principale motivation.
Pour cette séance de remixage, nous utiliserons SPAT Revolution, un logiciel professionnel de mixage 3D orienté objet, adapté à notre expérience. En effet, chaque Room (salle virtuelle) accueillera les sources de chaque morceau. Les quatre Room (3 morceaux-sujets + 1 morceau- test) resteront actives toute la séance, évitant ainsi toute manipulation complexe, en particulier lorsque nous passerons au remixage de la chanson suivante. La session SPAT unique à chaque participant agira en fond pour collecter et quantifier les manipulations sonores lui parvenant d’un contrôleur OSC, l’interface manipulée par le participant.
Nous avons ainsi contacté Nicolas Erard, employé à l’entreprise Flux Audio conceptrice de SPAT Revolution, pour concevoir ensemble une interface de contrôle spécialement adaptée au logiciel et à nos besoins. Après discussions, Nicolas a adapté les bases d’interaction entre SPAT Revolution et son interface de contrôle existante29 avec l’application OSC30 Open Stage Control31, pour nous guider dans la personnalisation de l’interface en fonction de nos besoins pour l’expérience. De nombreux éléments ont alors rapidement convergé entre nos exigences (facilité, lisibilité, efficacité) et les fonctionnalités offertes par SPAT via Open Stage Control. Nous avons ainsi défini ensemble trois caractéristiques concrètes de notre interface de remixage :
- Une limitation à 4 paramètres de mixage fondamentaux : niveau, égalisation (3 égaliseurs bas/medium/aigu à facteur Q large et fixe), localisation 360°, niveau de réverbération
- Une facilité de manipulation : tout paramètre est aisément modulable par la souris
- Une clarté de la présentation : présentation en tranches, cadres, légendes, couleurs
Après plusieurs modifications d’optimisation opérées à l’issue de deux pré-tests (section II.A.4.), l’interface de remixage sur Open Stage Control se présente comme ci-dessous :
2) Conception d’une interface de récupération des données de remixage des participants
Afin d’apporter une réponse valide aux questions Q.R.2 et Q.R.4, et comme développé en section II.A.3.2.c., nous avons souhaité connaître le nombre et l’ordre des manipulations de remixage effectuées par le participant sur chaque morceau remixé. Avec l’aide de mon directeur de mémoire, nous avons donc créé une interface chargée de retranscrire ces informations dans un fichier texte. En voici l’architecture sous Max/MSP et un exemple de script livré en sortie :
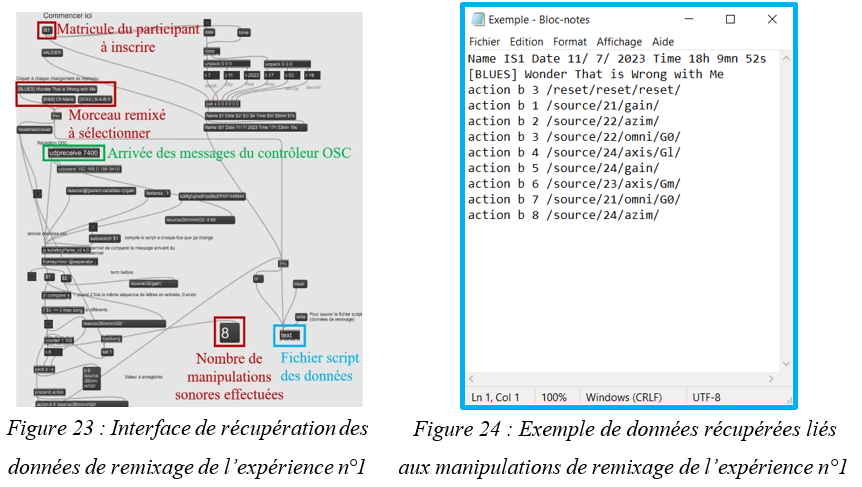
À titre d’exemple, nous décodons ci-dessous les informations récupérées en figure 24 :
« Le 11/07/2023 à 18h09, l’ingénieur du son n°1 a manipulé dans cet ordre les paramètres de remixage suivants sur l’enregistrement de la chanson Wonder That is Wrong with Me : 1. Niveau de la voix lead / 2. Localisation de la guitare / 3. Niveau de réverbération de la guitare / 4. EQ bas de la batterie / 5. Niveau de la batterie / 6. Niveau de la batterie / 7. Niveau de réverbération de la voix / 8. Localisation de la batterie. »
Nous effectuerons à l’issue de chaque remixage une capture d’écran de l’interface de remixage qui complètera ce fichier pour nous assurer une certaine finesse d’analyse des résultats.
3) Lieu d’accueil et synoptique
C’est le plateau 1 du conservatoire – une salle équipée d’un dôme de 44 enceintes commandées par le logiciel de traitement et de diffusion multicanale AFC Image (Yamaha), et donc destinée au mixage en son immersif – qui nous accueillera avec les participants.
Nous avons donc abouti pour l’expérience n°1 au synoptique suivant :
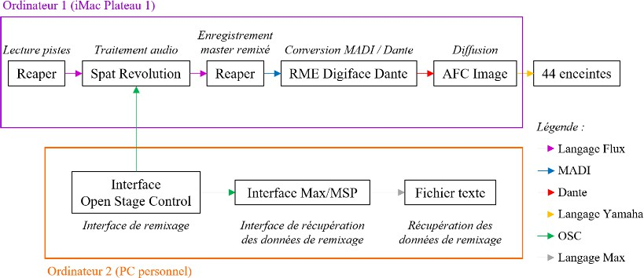
En plus de sa grande stabilité, la station audio Reaper nous permet d’enregistrer dans une piste audio multicanale le remixage en son spatialisé de chaque participant, comme détaillé ici :
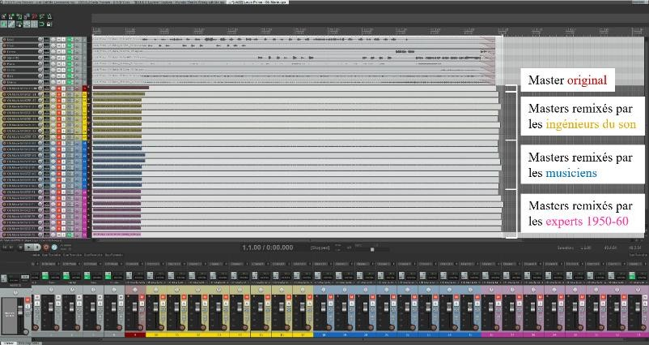
3. Protocole expérimental
Le protocole présenté ci-dessous est le résultat de quelques corrections apportées à l’issue de deux pré-tests, que nous renseignerons dans la section II.A.4.
1) Profils de participants
Cette expérience ne vise pas à juger les qualités de mixeur de chacun des participants, mais entend étudier leur attitude vis-à-vis d’enregistrements anciens. Afin de discerner d’éventuelles disparités de comportement, nous avons choisi de convier plusieurs profils de participants. Tous auront toutefois en commun une oreille musicale avisée, certains termes et questions pouvant être inaccessibles pour des personnes non musiciennes.
Les ingénieurs du son, avertis des contextes technologiques d’enregistrement de cette époque méritent toute notre attention pour discuter, écouter et remixer de tels enregistrements. Sur le plan musical, les mélomanes des années 1950-60 sont essentiels pour évoquer des chansons, des artistes et des enregistrements qui leur tiennent à cœur. Enfin les musiciens, créateurs musicaux, apportent une oreille et une sensibilité uniques et alignées sur l’essence musicale de notre étude.
Pour cette expérience n°1, nous avons donc invité par e-mail 8 ingénieurs du son, 8 musiciens et 8 experts du répertoire blues/R&B/soul des années 1950-6032. Tous répondent aux variables d’âge, de sexe, de niveau d’expérience en mixage et de connaissance du répertoire musical ciblé.
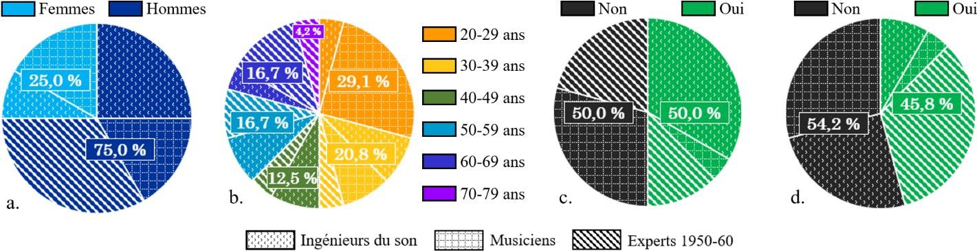
2) Déroulé de l’expérience
a) Entretien préliminaire semi-dirigé : le rapport conceptuel à l’œuvre musicale, à l’esthétique sonore d’enregistrement et à leur relation
Cette première phase d’échanges, visible en annexe B2, désire sonder le participant sur la pratique du remixage d’enregistrements passés. Après en avoir établi les fondations autour de la notion d’esthétique sonore (QA1) et de sa relation avec l’œuvre qu’elle a un jour enlacée (QA2), nous poursuivrons la discussion avec des questions plus ciblées (QA3, QA4) qui éclaireront notre sondage. Si le participant montre un intérêt au remixage d’enregistrements des années 1950-60, nous lui demanderons s’il pense à un aspect sonore particulier qu’il corrigerait sur la plupart des enregistrements de cette période (QA5). Nous retiendrons cette donnée pour la comparer ultérieurement avec la réponse donnée en QB6 ainsi qu’avec les choix de remixage effectués (voir section II.B.2.1.) pour chaque morceau de l’expérience. Lorsque cela se révélait pertinent ou nécessaire pour nos objectifs de recherche, nous avons parfois choisi de suivre le participant dans des explications plus détaillées, plus illustrées, afin de mettre en lumière des conceptions plus générales (principe de l’entretien semi-dirigé).
b) Questionnaire d’écoute du master original : les désirs sonores
La deuxième partie de l’expérience devient davantage active pour le participant. Nous lui faisons écouter au même niveau sonore le master original mono des chansons de Lightnin’ Hopkins, Louis Prima et Carla Thomas, sélectionnées en section II.A.1.1.).
Le questionnaire d’écoute que nous soumettons vise à comprendre dans quelle mesure la musique appelle le participant à lui souhaiter une quelconque modification sonore du master original. Il a aussi pour objectif, en vue de la partie III, de déterminer lequel des trois enregistrements originaux présente aux yeux des participants le rendu sonore global le moins en accord avec ce que représente selon eux l’essence du morceau en question.
Comme le montre l’intitulé des questions posées en annexe B3, nous avons précisément construit ce questionnaire autour de la motivation centrale de notre étude, l’œuvre, la musique.
La question QB1 est essentielle car plus le participant alimente sa réponse, plus il lui sera facile de répondre aux questions suivantes qui concernent certes l’aspect sonore mais toujours en étroite relation avec la chanson abordée. C’est pourquoi elle fait volontairement appel à des ressentis et des évocations très personnelles liées à la musique entendue.
Les questions QB2 à QB5, consacrées au rendu sonore, constituent le cœur de notre étude des comportements d’écoute face à des masters originaux des années 1950-60. Les participants y ont alors l’occasion en pratique de donner leur avis sur la relation entre une œuvre et l’esthétique sonore de son enregistrement. Pour tirer des résultats ciblés de ce questionnaire, nous faciliterons aussi l’analyse d’écoute des participants en la portant sur trois critères sonores essentiels en écoute critique d’enregistrement : le rendu de l’équilibre entre les sources (QB3), celui de leurs timbres (QB4) et celui de l’espace dont elles disposent dans l’image sonore (QB5). La question QB5 regroupe l’aspect mono de l’enregistrement, son relief, sa profondeur et la réverbération. Guidés par la composante musicale, les participants devront ajuster ces critères selon elle en évaluant dans quelle mesure le rendu sonore du master original convient à leur propre définition –stylistique, esthétique, historique – de la chanson (QB1). Enfin, nous identifierons les éventuels désirs sonores des participants en faveur de la chanson par la question QB6 qui, sans la nommer, constitue en fait un préambule à la proposition suivante de remixage.
Lors des écoutes, pour s’affranchir d’un potentiel effet d’ordre, nous avons choisi de contrebalancer l’ordre des trois masters écoutés d’un participant à un autre. Comme six ordres sont mathématiquement possibles, nous effectuerons chacun d’eux quatre fois pour l’expérience (6×4 = 24 participants).
c) Séance de remixage : les choix sonores
La phase pleinement pratique de l’expérience a enfin lieu. Nous invitons les participants à concrétiser leurs éventuelles envies de modifications sonores formulées pour chaque enregistrement en QB6, à travers une séance de remixage en son spatialisé spécialement configurée. Pour s’assurer d’un maximum de neutralité dans nos explications, nous leur demanderons de lire l’énoncé en annexe B4 avant de se lancer pleinement dans l’exercice.
À ce moment, nous introduisons aux participants l’interface de remixage présentée en section II.A.2.1. Avant qu’ils ne commencent à s’entraîner avec elle, nous prenons le temps de leur montrer comment chaque paramètre de remixage peut être aisément ajusté avec la souris. Après cela, tous les participants seront libres de leurs choix et de leurs actions.
Devant l’intérêt que peut susciter cette séance de remixage, il est important de rappeler l’objectif de recherche de la présente expérience : examiner les comportements d’écoute et, ici, de remixage des différents profils de participants sur trois enregistrements monophoniques des années 1950-60. Le but ultime n’est donc ni pour eux ni pour nous d’obtenir pour chaque chanson une qualité de remixage irréprochable, un rendu sonore « idéal » vis-à-vis de la musique, mais de savoir quelles sont les premières manipulations sonores qu’ils entreprennent pour y parvenir. C’est en ce sens que nous avons limité le nombre de manipulations de remixage possibles. Dans cette expérience n°1, les comportements et les choix musicaux priment sur la performance.

d) Questionnaire d’autocritique du nouveau master avec entretien d’auto-confrontation individuelle : les conclusions
Après chaque remixage effectué suivant l’ordre des chansons de la phase d’écoute, nous demanderons au participant d’adopter un regard critique sur son propre master en le comparant au master original, toujours vis-à-vis de sa conception de l’œuvre. Notre objectif est de savoir dans quelle mesure les premières manipulations qu’il a pu effectuer le rapprochent déjà de son rendu sonore idéal pour la chanson (Q.R.3), telle qu’il l’a présentée en QB1. Plus précisément, des questions d’auto-confrontation individuelle s’intéressent ici pour chaque morceau, en observant l’état final de l’interface de remixage, à discuter de l’esprit de cohérence du participant entre ses désirs sonores formulés en QB6 et ses choix opérés dans la phase c). Nous les mêlons finalement à la phase d’autocritique du nouveau master pour former un questionnaire oral, disponible en annexe B5, que nous présentons volontairement comme le revers littéral de celui de l’écoute du master original, toujours centré sur l’œuvre.
La question QD6 du questionnaire d’autocritique s’avère essentielle sur le plan technologique et méthodologique. Elle nous permettra de savoir dans quelle mesure la retouche manuelle d’une séparation de sources opérée aujourd’hui par apprentissage profond et sans détection des harmoniques permet aux participants de réaliser leurs envies sonores. Ainsi, nous saurons dans quelle mesure ces perturbations éventuelles jouent un rôle dans leur évaluation du rendu sonore du nouveau master vis-à-vis de la substance musicale.
Suite à l’enchaînement remixage/questionnaire d’autocritique de chacun des trois enregistrements, l’expérience prend fin.
3) Collecte et analyse des données
Nous analyserons les réponses issues de l’entretien préliminaire et les réponses verbales au questionnaire d’écoute par théorie ancrée (Glaser & Strauss, 1967). En classant les termes et expressions prononcés par les participants en concepts généraux et sous-concepts, nous définirons les idées générales qui émergent de chacune de leur réponse.
Concernant les évaluations attribuées aux rendus sonores des masters originaux et remixés, nous les synthétiserons pour chaque morceau et chaque critère sonore en créant des boîtes à moustaches pour illustrer les variations des évaluations avant et après le remixage.
Nous reprendrons les informations fournies par l’interface Max/MSP présentée en section II.A.2.2. pour élaborer pour chaque morceau remixé le digramme en barres des manipulations et des paramètres de remixage les plus privilégiés par l’ensemble des participants.
Nous calculerons et renseignerons l’ensemble de ces résultats par chanson et par profil, ce qui nous permettra d’établir des comparaisons selon ces deux axes.
4. Pré-tests : corrections apportées au protocole initial
Pour évaluer la fiabilité et la fluidité du protocole avant les premiers tests, nous avons organisé deux pré-tests avec deux étudiants en fin de cursus FSMS.
Le premier d’entre eux visait à contrôler la fiabilité du protocole : l’intitulé, l’objectivité et l’enchaînement logique de toutes les questions, le réglage du niveau d’écoute identique à tous les morceaux, les conditions de remixage (interface, nombre précis de manipulations autorisé) et le fonctionnement de l’interface de récupération des données de remixage. Comme ce protocole est dense, nous avons demandé au premier étudiant de formuler ses remarques sur le contenu de l’expérience dès qu’elles lui apparaissaient. Ainsi, sans contrainte de temps, nous avons pu noter les ajustements protocolaires que nous avons réalisés pour la première séance :
- Nous inviterons les participants à orienter chaque écoute d’un master original vers les éléments du questionnaire d’écoute : évocations et caractéristiques musicales de la chanson, rendu sonore global, rendu de l’équilibre, des timbres, de l’espace des différentes sources sonores vis-à-vis de la musique. Cette préparation s’avère précieuse, car ces questions sont peu souvent explorées pour des enregistrements passés ;
- Nous effectuerons oralement les questionnaires d’écoute du master original et d’autocritique du nouveau master, pour permettre aux participants de partager immédiatement des impressions, que nous retranscrirons fidèlement en direct ;
- Nous étendrons à 12 le nombre de manipulations de remixage autorisé, pour offrir aux participants une plus grande latitude d’exécution de leurs idées musicales et augmenter le nombre de choix liés à celles-ci ;
- Afin de ne pas entraver les idées musicales des participants, ajuster successivement les potentiomètres d’égalisation (bas, medium, aigu) d’une même source sera compté comme une seule manipulation dans l’interface Max/MSP ;
- Toujours pour satisfaire les envies sonores des participants, nous leur permettrons d’éventuellement modifier dans SPAT Revolution la longueur et la queue de réverbération pendant chaque remixage, sans que cela ne compte comme une manipulation. Bien que ces paramètres aient été initialement réglés par nos soins en fonction du morceau traité ;
- Nous concevrons une session OSC et une session SPAT unique à chaque participant, afin d’en sauvegarder et d’en analyser les positions et valeurs finales des paramètres touchés.
Le second pré-test, qui a entériné les précédents ajustements, entendait quant à lui vérifier la fluidité du protocole, avec l’objectif de tenir cette riche expérience en un temps limité d’1h30. À l’issue de ce pré-test au rythme plutôt modéré, nous sommes finalement parvenus à une durée d’1h45. Nous nous sommes donc finalement fixés comme objectifs de test de passer maximum 15 min sur l’entretien préliminaire (phase a) et 15 min sur chaque chanson écoutée/critiquée (phase b) et remixée/critiquée (phase d).
B. Résultats expérimentaux : analyse par morceau et par profil
1. Analyse quantitative
Préambule : mesure du degré de participation à la séance de remixage
La très grande majorité des participants a adoré cette expérience car les questions et les manipulations mises en jeu leur ont ouvert de nouvelles perspectives d’approche dans leur propre domaine d’activité33. Nous n’avions honnêtement pas prévu cet engouement. En particulier, aucun n’a été gêné par la longueur de l’expérience (1h45-2h), et certains l’ont même fait durer davantage pour enrichir la discussion dans les différents questionnaires et/ou profiter du temps de remixage. De prime abord, il est important de savoir dans quelle mesure les différents profils de participants se sont engagés dans cette session de remixage pour chacun des trois morceaux. Nous pouvons évaluer cet aspect en calculant la moyenne et l’écart-type du nombre de manipulations de remixage par morceau et par profil :

Premièrement, avec une moyenne totale élevée et très resserrée du nombre de manipulations (10,42 / 10,5 / 10,33 pour chaque profil respectif, sur 12 autorisées), nous pouvons voir que tous les profils de participants ont joué le jeu du remixage, et de façon assez égale. Les ingénieurs du son sont bien pleinement engagés dans la démarche de remixage. De plus, de manière positive, les experts du répertoire ne sont pas si fermés à l’idée de se prêter au jeu des modifications sonores d’enregistrements qu’ils ont coutume depuis longtemps d’écouter.
En revanche, on aperçoit différents comportements de remixage lorsque l’on confronte les trois enregistrements. Assez nettement, c’est la chanson B-A-B-Y qui a connu en moyenne à travers la session le plus grand nombre de manipulations sonores (11,33) avec la plus faible dispersion (1,04). En détail, la moyenne très élevée et l’écart-type très bas du nombre d’opérations montrent pour tous les profils un premier intérêt pour modifier en faveur de cette chanson certains aspects sonores originaux. C’est aussi sur celle-ci que les ingénieurs du son et les experts du répertoire ont opéré le plus de manipulations. Nous verrons quelles sont-elles en section II.B.1.2.
1) Évolution des notes de rendu sonore vis-à-vis de la musique entre le master original et le master remixé de chaque participant
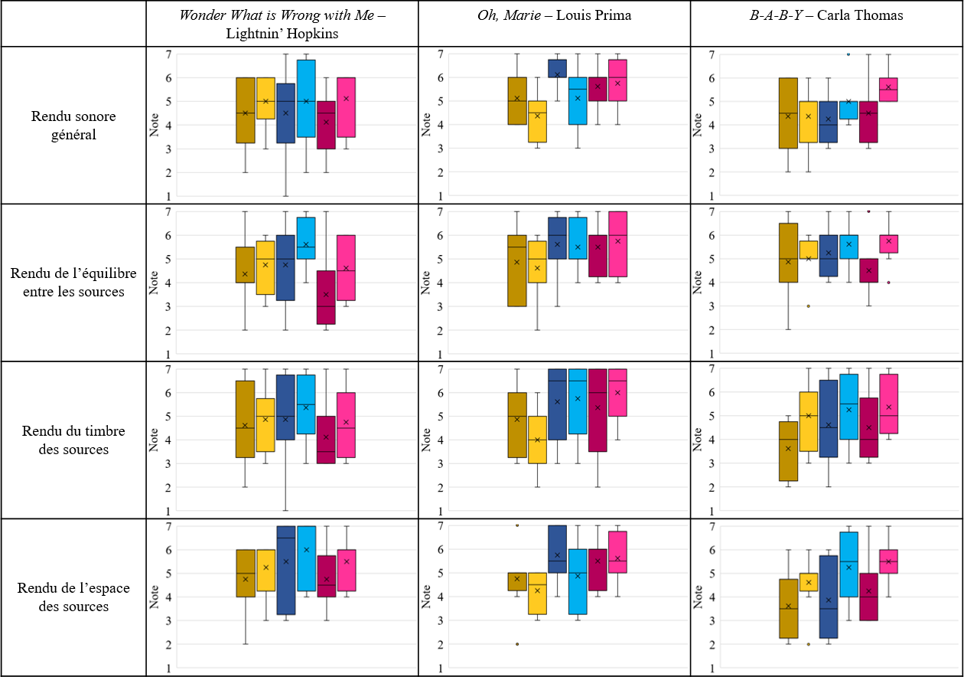

Légende : 1 colonne = 1 chanson // 1 ligne = 1 critère d’évaluation sonore
La figure 2934 nous apportent six résultats majeurs sur les préférences de rendu sonore des participants entre le master original et le master qu’ils ont remixé :
R1 : L’enregistrement de la chanson de Louis Prima présente aux yeux des participants le rendu sonore original le plus en accord avec les caractéristiques musicales de la chanson. Nous discuterons en section II.C. de l’enregistrement au rendu sonore original entravant le plus le propos musical.
R2 : La version des chansons de Lightnin’ Hopkins et de Carla Thomas, remixée par chaque participant a selon tous les profils en moyenne un meilleur rendu sonore vis-à-vis de la musique que la version originale, tous critères sonores confondus.
R3 : En particulier, en plus d’être plus élevées en moyenne, les notes attribuées au rendu de l’espace des sources sonores des chansons de Lightnin’ Hopkins et de Carla Thomas sont plus homogènes dans les versions remixées que dans la version originale.
R4 : Chaque profil de participant s’accorde moins sur le rendu sonore général de la chanson Lightnin’ Hopkins que de celle Carla Thomas, pour la version originale et leur version remixée.
R5 : Les experts 1950-60 sont, en moyenne sur chacun des trois morceaux et vis-à-vis des caractéristiques musicales, plus satisfaits du rendu sonore de leur version remixée que de celui de la version originale, tous critères sonores confondus.
R6 : Les ingénieurs du son sont en moyenne les moins satisfaits du rendu sonore de leur version remixée de la chanson de Louis Prima, tous critères sonores confondus.
2) Paramètres et manipulations de remixage privilégiés
Nous considérons qu’une manipulation de remixage est « privilégiée » par les participants pour le remixage d’un morceau si elle est souvent pratiquée (nombre d’occurrences élevé) et si elle est prioritaire (faible ordre d’apparition). Pour chaque chanson remixée, nous avons donc représenté ces deux informations35 au sein de la figure 30.
La figure 30b confirme le résultat R1 puisque le master original d’Oh, Marie n’est pas sujet à des manipulations correctives de remixage prédominantes. Les choix sont en effet davantage personnels, ce qui occasionne ce profil de graphe équilibré.
En revanche, conformément au résultat R2, les figures 30a et 30c révèlent clairement des manipulations de remixage privilégiées. Les participants les effectuent pour ajuster des aspects sonores du master original ne leur paraissant pas en totale symbiose avec la musique : le timbre et le niveau de la guitare et de la contrebasse pour le morceau de blues, le timbre de la basse et la position spatiale de l’orgue, du piano et des cuivres pour le titre de soul.
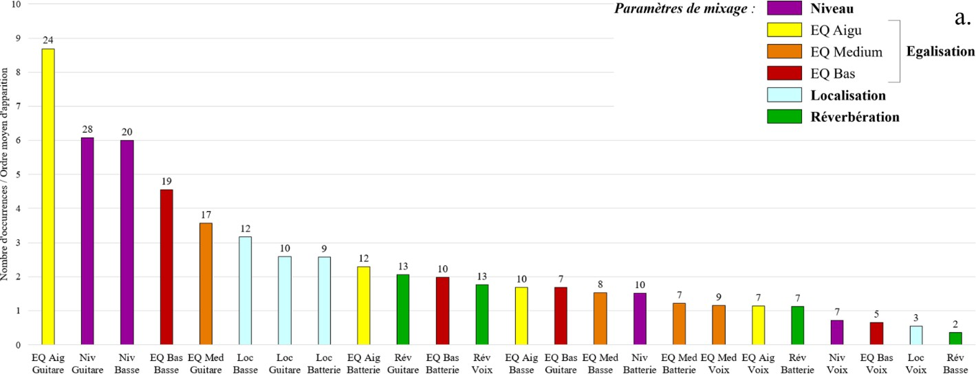
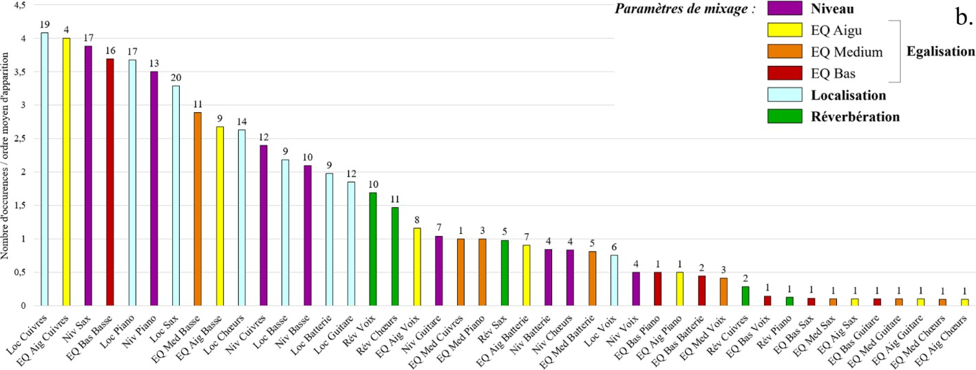
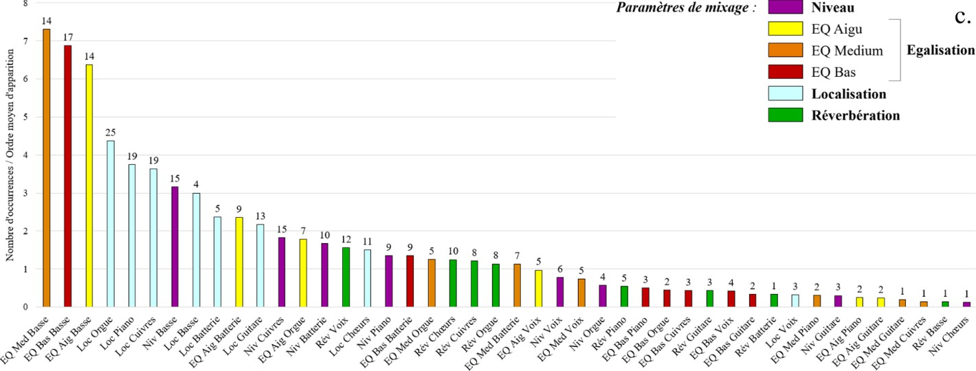
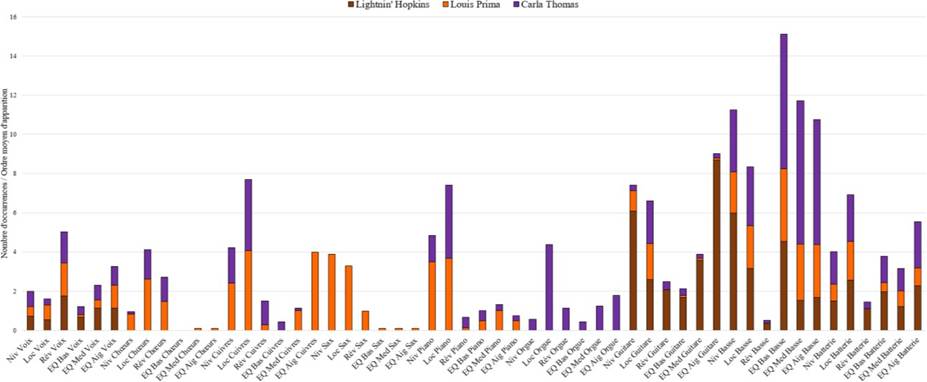
La figure 31 nous offre une vue d’ensemble des manipulations sonores privilégiées par les participants pour remixer des masters monophoniques de blues/R&B/soul des années 1950-6036. Contrairement à la figure 30, nous n’y renseignons pas le nombre d’occurrences au-dessus de chaque barre de manipulation, par souci de lisibilité. En particulier, nous pouvons identifier la basse comme étant pour eux l’instrument-clé pour améliorer drastiquement le rendu sonore général en faveur du message musical.

Plus généralement et directement lié à nos deux problématiques qui concernent le remixage en son immersif, nous pouvons remarquer à travers le tableau 4 que la localisation à 360° constitue le paramètre de remixage le plus privilégié en moyenne sur les trois chansons par l’ensemble des participants pour s’approcher d’un rendu sonore idéal.
2. Analyse qualitative
1) Niveau de correspondance entre les réponses à l’entretien préliminaire et les choix de remixage
Pour traiter la question Q.R.4, intéressons-nous à présent aux conceptions des participants évoquées dans l’entretien préliminaire.
Tout d’abord, pour pouvoir parler ensuite du terme, nous avons cumulé toutes les réponses données aux questions QA1, QA2 et QA3 pour établir une définition médiane des participants de l’esthétique sonore d’un enregistrement musical : empreinte ou couleur sonore particulière perceptible sur l’enregistrement d’une œuvre musicale. Liée aux techniques d’enregistrement et aux modes sonores caractéristiques d’une époque, elle constitue le plus souvent un choix, opéré en lien étroit avec l’esthétique musicale de l’œuvre et partagé par l’ingénieur du son, le producteur de séance et les artistes, qui peuvent même parfois en être à l’initiative et créer la musique autour d’elle. Ce choix, parfois réfléchi en amont de l’enregistrement, intervient le jour de la séance (acoustique de studio, positionnement des musiciens, type et positionnement de micros) et lors du mixage (quel type de timbres, de plans sonores, de réverbération) dans le but prioritaire de servir le discours musical. Pouvant avoir un impact énorme sur notre perception postérieure de l’œuvre – variant selon le style musical – et se définir comme l’identité sonore du label ou de l’artiste, elle peut prétendre à devenir une référence pour d’autres enregistrements.
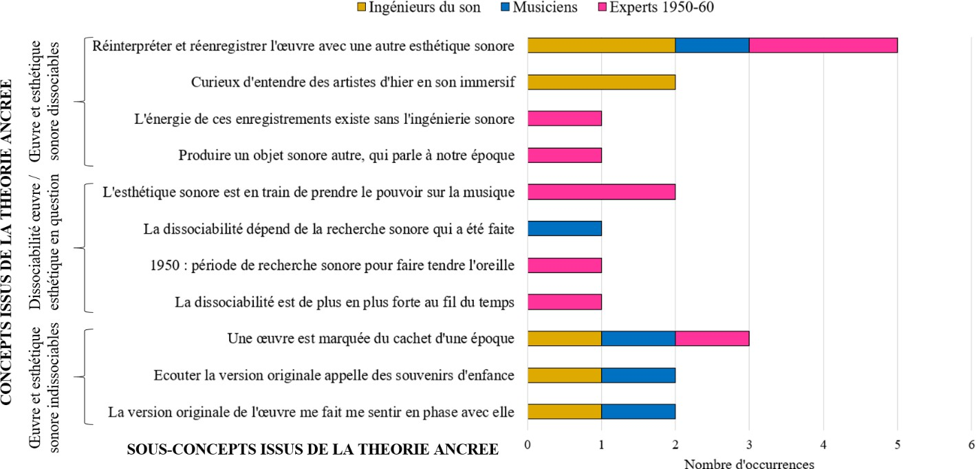
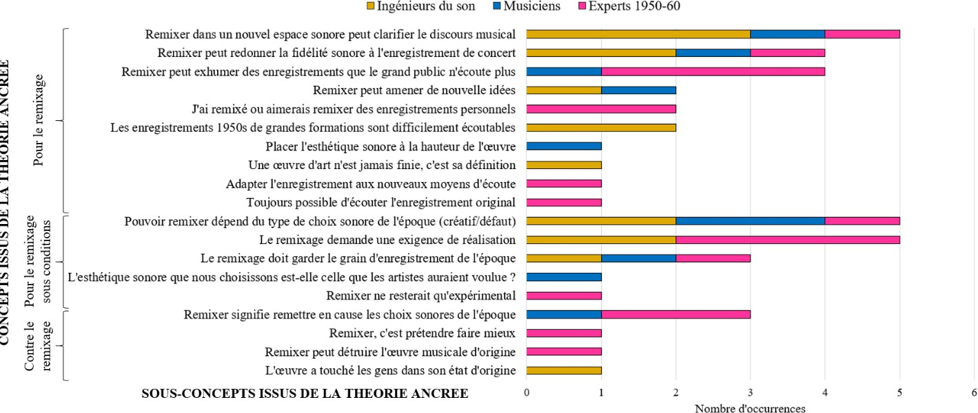
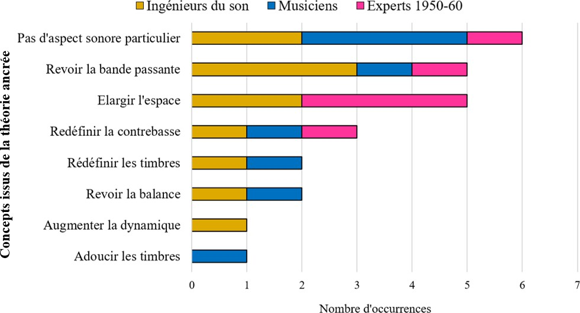
En accord avec cette définition de l’esthétique sonore, une large majorité de participants (75%) considère qu’elle peut être dissociée de l’œuvre musicale pour les productions des années 1950-60. La figure 32 illustre leurs perspectives sur cette question analysée par théorie ancrée.
Notons le désir exprimé par deux ingénieurs du son d’entendre en audio immersif certains enregistrements mono de cette période : un concert de Charlie Parker pour l’un, un album des Beach Boys pour l’autre. Cette dissociabilité entre l’œuvre et son esthétique sonore originale revêt un caractère essentiel pour valider notre approche centrée sur la musique : modifier la seconde sans altérer la première.
Mais justement, qu’en est-il du remixage aux yeux des participants ? 83% d’entre eux (20/24) sont favorables à la modification d’aspects sonores d’enregistrements des années 1950-60 qu’ils connaissent, pour lesquels l’esthétique sonore ou au moins son rendu joue en défaveur de l’œuvre, contrairement à la définition donnée précédemment. La figure 33 montre alors les aspects positifs, limitants et négatifs que relèvent les participants pour la pratique du remixage dans ce contexte.
Les principaux avantages incluent l’éclaircissement du discours musical par un nouvel espace sonore et le moyen de revitaliser certains enregistrements au profit du grand public. Cependant, une grande prudence nous est recommandée par les participants, qui implique de se renseigner sur la nature et l’origine des aspects sonores soi-disant gênants de ces enregistrements, et ensuite d’adopter une exigence de réalisation. En confrontant ces idées aux résultats de la figure 29, nous discuterons de cette question dans la section II.C.
Enfin, la figure 34 révèle les aspects sonores que les participants favorables au remixage souhaiteraient prioritairement modifier dans les enregistrements des années 1950-60, à travers divers exemples de leur choix. En particulier, élargir l’espace de ces enregistrements mono constitue l’un des deux désirs sonores les plus fréquemment exprimés.
Pour affiner notre étude des comportements, nous avons comparé les désirs sonores exprimés par ces participants lors de l’entretien préliminaire pour divers enregistrements de la période 1950- 60, dont cinq d’entre eux pour l’espace, avec leurs choix ultérieurs lors de la séance de remixage des trois chansons. La figure 35 nous donne donc pour chaque morceau remixé et chaque participant concerné deux informations sur les aspects sonores qu’il a annoncés à l’entretien préliminaire vouloir en priorité corriger sur divers enregistrements des années 1950-60 (QA5) : combien d’entre eux figurent en effet parmi les modifications sonores prioritaires souhaitées avant le remixage de chaque morceau (QB6), et combien d’entre eux font l’objet d’une manipulation de remixage et le cas échéant, à quel niveau de priorité. Par exemple, pour la chanson de Lightnin’ Hopkins, nous voyons que le musicien n°1 a suivi son envie préliminaire de revoir la balance des enregistrements de 1950-60 (QA5), puisqu’il a émis ce souhait de modification en écoutant le master original (cercle coloré) et qu’il l’a concrétisé au remixage en l’effectuant en première position (barre du graphe). Ou encore, pour cette même chanson, l’ingénieur du son n°7, comme dit à l’entretien préliminaire, a souhaité élargir l’espace sonore en écoutant le master original, pourtant il n’a fait aucune manipulation dans ce sens lors du remixage.
De cette figure, quatre éléments nous apparaissent importants. D’abord, les participants sont globalement cohérents entre l’entretien préliminaire et le remixage puisqu’au moins la moitié des envies sonores formulées sur divers enregistrements des années 1950-60 s’est vérifiée pour chacun des trois masters originaux écoutés avant la séance de remixage. Puis, avec 12 aspects sonores communs sur 18, c’est la chanson B-A-B-Y de Carla Thomas qui présente le plus haut niveau de corrélation entre les modifications sonores que les participants souhaitent pour elle et celles qu’ils désirent en général pour des enregistrements 1950-60. Tous les aspects sonores particuliers souhaités pour certains enregistrements de 1950-60 ont été manipulés lors du remixage de la chanson B-A-B-Y, contrairement aux autres chansons. Enfin, le paramètre de localisation spatiale est celui qui affiche le plus haut degré de corrélation entre les envies sonores générales pour des enregistrements 1950-60 et les envies sonores particulières pour chacun des trois morceaux écoutés.
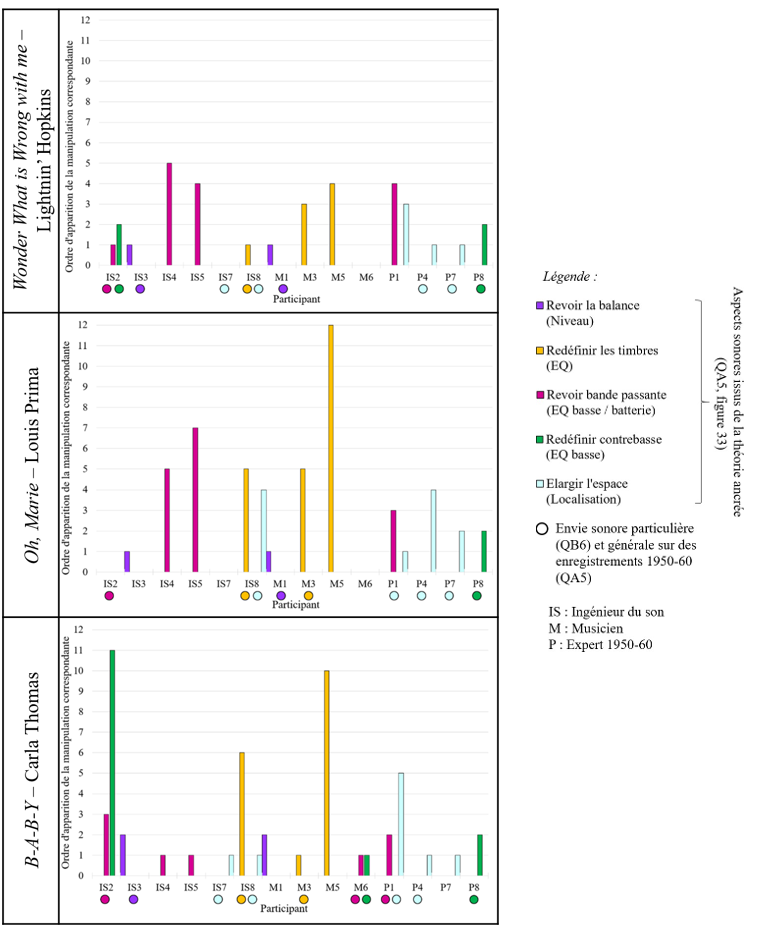
2) Limitations des signaux isolés sans détection des harmoniques pour le remixage en son spatialisé
Nous avons élaboré la figure 36 à partir des réponses des participants aux questions QD5 et QD6 du questionnaire d’autocritique du nouveau master. Elle nous offre une première évaluation pratique de la retouche manuelle de la séparation de sources par apprentissage profond sans détection des harmoniques, présentée en I.C.3.2. et opérée en II.A.1.2, pour un remixage en son spatialisé, expliquant certains résultats quantitatifs donnés en figure 29.
Les limitations ressenties dues à la qualité des signaux lors du remixage concernent des matières spectrales dépouillées, des interférences entre sources, des éléments non séparés, et varient selon le morceau. 54% des participants ont été limités par le signal de la basse de Lightnin’ Hopkins, car son absence d’harmoniques entravait leur envie de la redéfinir. Cela dit, tous ont reconnu que la prise de son instrumentale de 1954 était responsable de cette issue. Avec une même explication, 46% des participants ont déploré la présence aléatoire du signal du piano chez Louis Prima, qui défavorisait leur souhait d’augmenter son niveau. En revanche, seuls 13% des participants ont été limités pour remixer la chanson de Carla Thomas, ce qui leur a plus aisément permis d’entendre un master remixé plus fidèle à la musique (figure 29). Notons que 29%, 8% et 8% des participants souhaiteraient disposer des éléments séparés de batterie pour l’élargir dans chacune des trois chansons blues, R&B et soul. Finalement, 38%, 38% et 63% d’entre eux n’ont ressenti aucune limitation liée aux sources séparées et retouchées en amont, pour les remixages en son spatialisé des chansons de Lightnin’ Hopkins, Louis Prima et Carla Thomas. Cette donnée s’annonce cruciale en vue de la partie III.
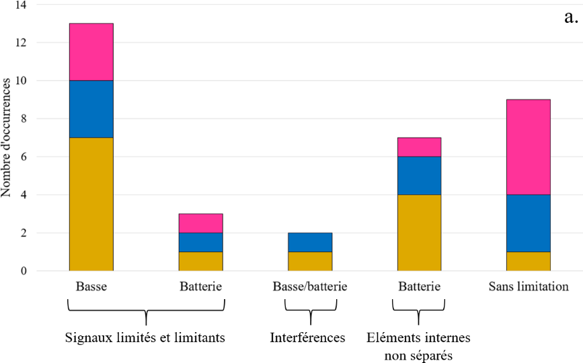
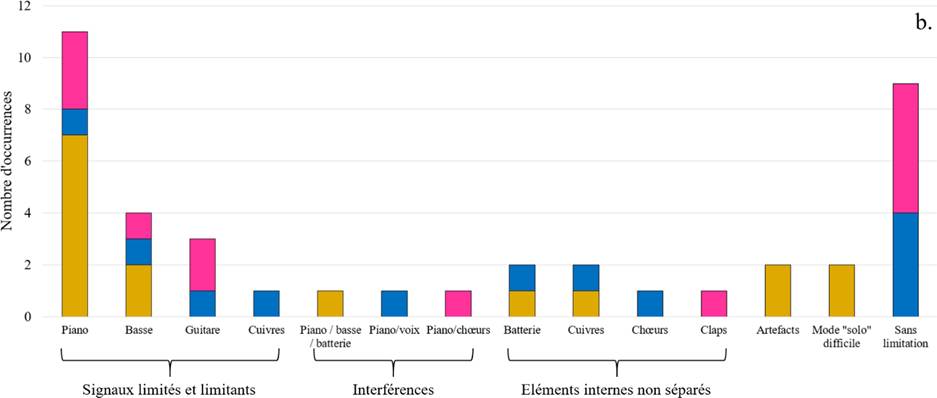
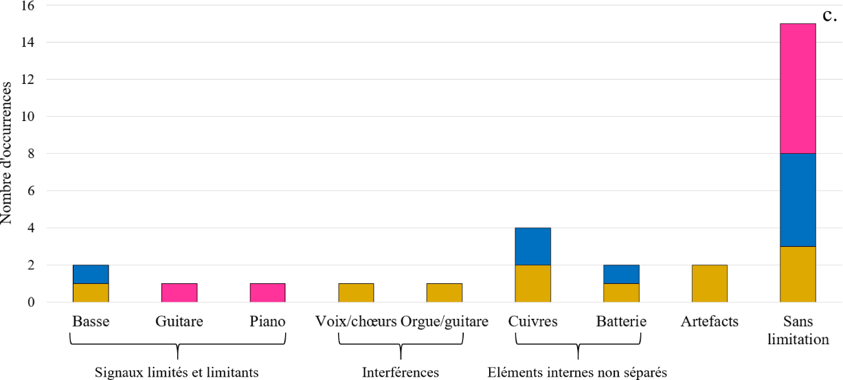
C. Discussion de l’expérience n°1 et conclusions
Cette expérience s’avère riche d’enseignements sur les comportements de réflexion, d’écoute et de remixage d’ingénieurs du son, de musiciens et d’experts musicaux du répertoire vis-à-vis des masters originaux d’enregistrements blues/R&B/soul des années 1950-60. Nous y avons donc analysé leur évaluation du rendu sonore des masters originaux (Q.R.1) et de leurs masters remixés (Q.R.3) vis-à-vis de la musique, leur engagement dans la séance de remixage (Q.R.2) et leur cohérence entre leurs réponses à l’entretien préliminaire et leurs choix de remixage (Q.R.4).
Dans leur réflexion, tous les profils de participants voient de nombreux intérêts à remixer aujourd’hui certains enregistrements de cette période, bien qu’ils n’en oublient pas de rappeler certains impératifs. La majorité, qui voit en cette pratique un atout majeur pour la musique, affirme d’abord que l’œuvre musicale peut évoluer librement sans l’esthétique sonore37 issue des années 1950-60 sans que son essence ne soit menacée. Au contraire, le bénéfice du remixage serait selon eux essentiellement musical : clarification du discours, fidélité sonore, découverte de catalogues enregistrés, nouvelles perspectives de composition. Cela conforte ainsi notre idée de guider notre étude par la musique, l’œuvre pensée, composée et interprétée. Une minorité pense en revanche que le remixage n’aurait qu’une utilité technique. Toutefois, plusieurs participants signalent que ce processus, exigeant et nécessairement garant de la temporalité originale, doit être documenté. Cela implique de savoir si les aspects sonores que le remixeur souhaite modifier – même dans une démarche musicale – ont constitué le jour de l’enregistrement un choix esthétique réfléchi ou un défaut technique connu. Or les ingénieurs du son de l’expérience nous rappellent que les aspects sonores perceptibles dans un enregistrement d’époque résultent le plus souvent de contingences matérielles. Il semblerait donc que l’hypothèse du défaut technique soit d’après les participants intéressés la plus fréquente pour les enregistrements de ces années. Ainsi, nous pouvons réaliser l’envie de la majorité des participants de retravailler prioritairement la bande passante et l’espace sonore – paramètre qui nous intéresse – de certains masters originaux des années 1950-60.
Ensuite, comme l’atout du remixage semble principalement musical pour les participants, écouter et évaluer de ce point de vue le rendu sonore de trois masters originaux de blues/R&B/soul de la période concernée leur a paru certes inhabituel, mais réalisable, pertinent et parfois confortable. En effet, tous ont éveillé leur sensibilité musicale et parfois leur affection marquée et fortuite pour certaines de ces chansons, pour définir ce qui les caractérise et éventuellement ce en quoi elles les touchent. Guidés par cela, en réponse à notre question initiale Q.R.1, l’ensemble des profils – y compris les experts 1950-60 – n’ont pas hésité à juger qu’un de ces masters originaux présentaient un rendu sonore desservant la musique. Le rendu sonore de l’enregistrement de la chanson B-A-B-Y a été le plus vivement critiqué par rapport à ce que l’œuvre dégage aux yeux des participants. En particulier, c’est dans ce master original que le rendu des timbres et le rendu de l’espace des sources sonores divergent selon eux le plus de la musique. Nous apercevons là une première cohérence de résultats entre les comportements de réflexion des participants (souhait de corriger en priorité la bande passante et l’espace sonore de divers enregistrements des années 1950-60) et leur comportement d’écoute (souhait de bonifier les timbres et l’espace du master original de B-A-B-Y) en faveur de la composante musicale.
Enfin, les comportements de remixage des participants sont aussi riches d’observations. En réponse à la question Q.R.2, les trois profils se sont prêtés au jeu des manipulations sonores pour chacune des trois chansons traitées. Surtout, pour répondre à la question Q.R.3, ceux-ci ont par cette séance pratique réussi à se rapprocher de leur propre rendu sonore idéal de deux chansons sur trois (What is Wrong with Me et B-A-B-Y), ce qui constitue l’un des principaux gains de cette expérience. En particulier, le rendu de l’espace des sources sonores dans ces deux versions que les participants ont remixées profite selon eux enfin à la musique. Ainsi, nous pouvons commencer à répondre à notre grande problématique a : au contraire de la chanson Oh, Marie de Louis Prima, remixer en son immersif les masters originaux monophoniques des chansons Wonder What is Wrong with Me de Lightnin’ Hopkins et B-A-B-Y de Carla Thomas fait sens sur le plan artistique, dans la mesure où l’œuvre elle-même s’en trouve régénérée au regard des participants de tout profil. Pourtant, cette conclusion intervient même alors que la séparation de sources sans détection des harmoniques, à l’origine de cette expérience, détient encore une grande marge de progression pour satisfaire toutes les envies de remixage de chacun. Nous noterons en particulier la mauvaise tendance de l’outil à regrouper des signaux dissemblables au sein d’un même stem, ce qui, malgré notre retouche manuelle approfondie, laisse apparaître quelques artefacts ou manques fréquentiels pour certaines sources essentielles comme la basse. Par ailleurs, l’incapacité de ce modèle, que nous avons présenté en section I.C.3.2., à diviser les éléments internes de la batterie et des cuivres entrave certains désirs sonores importants liés à la construction d’un nouvel espace sonore pour l’œuvre. À ce propos, la volonté portée par les participants pour ce dernier paramètre est pleinement affirmée pour le remixage de masters monophoniques des années 1950-60 : c’est l’aspect spatial qui est privilégié pour répondre à leurs attentes sonores des trois chansons, avec en prime une correspondance maximale avec les souhaits préliminaires des participants concernés. Nous comprenons donc vis-à-vis de la problématique a que la notion immersive dans le contexte de ces enregistrements passés tient artistiquement toute sa place aux yeux des participants, en théorie comme en pratique. Nous retiendrons la grande cohérence dont ont fait preuve ces derniers depuis leurs conceptions évoquées jusqu’à leurs manipulations effectuées, ce qui répond à notre question Q.R.4.
Encouragés par les résultats positifs de cette expérience, nous souhaitons maintenant les exploiter pour proposer au grand public la possibilité d’écouter un master immersif représentatif de ceux réalisés par les participants pour l’une des trois chansons. En abordant dans la partie III les choix de remixage privilégiés en faveur de celle-ci, nous complèterons ainsi notre réponse à la problématique a et parviendrons à la problématique b.
III. Expérience n°2 : Ecoute comparative du master original et d’un master remixé en son immersif de la chanson B-A-B-Y (1966)
Pour compléter notre réponse à la problématique a et traiter la problématique b, nous avons conçu une deuxième expérience qui vise à évaluer la demande du grand public pour un master en son immersif d’une des trois chansons de l’expérience n°1. Elle tend à mesurer plus directement le degré de pertinence musicale, culturelle et historique de la pratique du remixage en son immersif des répertoires afro-américains des années 1950-60. Pour ce faire, en reprenant le plus fidèlement les envies et choix de remixage des participants de l’expérience n°1, nous avons remixé en son immersif la chanson qui, au vu de leur évaluation du rendu sonore original, récolterait a priori les plus grands avantages musicaux d’une telle restructuration sonore : il s’agit de B-A-B-Y de Carla Thomas. Plusieurs résultats de l’expérience n°1 rappelés ci-dessous sont alors venus motiver notre choix de chanson :
- C’est elle qui présente selon les participants le rendu sonore original le moins en accord avec ses caractéristiques musicales (figure 29) ;
- Tous les profils ont pensé en moyenne de cette chanson que leur version remixée affichait un meilleur rendu sonore vis-à-vis de la musique que la version originale (figure 29) ;
- C’est la chanson pour laquelle les participants ont été les moins limités par la qualité des signaux isolés lors de la séance de remixage (figure 36) ;
- Le paramètre spatial38 est à la fois celui qui, aux yeux des participants, défavorise le plus fortement le master original de la chanson (figure 29) et celui qui affiche le plus haut degré de corrélation entre les envies sonores générales pour des enregistrements 1950-60 et les envies sonores particulières pour chacun des trois morceaux abordés (figure 35) ;
- Tous les aspects sonores particuliers souhaités pour certains enregistrements de 1950-60 ont été manipulés lors du remixage de cette chanson, contrairement aux autres (figure 35).
Après avoir employé une autre méthode de séparation de sources et opéré ce remixage immersif de la chanson B-A-B-Y, nous avons organisé deux tests d’écoute comparative aux protocoles et aux objectifs complémentaires.
Le premier, réservé aux « producteurs » de musique (des ingénieurs du son, réalisateurs artistiques et producteurs musicaux), vise à répondre à la question suivante :
QR5 : Aux yeux experts d’ingénieurs du son, de réalisateurs artistiques et de producteurs musicaux, le présent master remixé en son immersif de la chanson B-A-B-Y de Carla Thomas, enregistrée en mono en 1966, présente-t-il aujourd’hui un intérêt culturel et musical d’être entendu par le grand public ? En outre, pourrait-il prétendre aujourd’hui à cohabiter avec le master original au sein du catalogue discographique de l’artiste et du label ?
Le second, ouvert aux « consommateurs » de musique (des musiciens, des non-musiciens et des experts musicaux du répertoire soul des années 1950-60), est dirigé vers ces questions :
QR6 : A travers laquelle des deux versions sonores – version originale ou version remixée – les participants éprouvent-ils le plus de plaisir à écouter la chanson B-A-B-Y de Carla Thomas ?
QR7 : Les consommateurs de musique seraient-ils enclins à écouter la version remixée en son immersif de la chanson B-A-B-Y plus souvent que la version sonore originale, si elle était publiée à ses côtés sur leur plateforme de streaming musical favorite ?
Ainsi, la question Q.R.5 nous permettra de parfaire notre réponse à la problématique a, quand les questions Q.R.6 et Q.R.7 alimenteront notre problématique b.
Nous consacrerons la première partie au remixage en son immersif de B-A-B-Y, la deuxième au test d’écoute pour « producteurs » et la troisième au test d’écoute pour « consommateurs ».
A. Remixage en son immersif de B-A-B-Y de Carla Thomas
1. Choix du logiciel de séparation de sources : RipX
Contrairement à l’expérience n°1 où l’étude des comportements prévalait, nous sommes à présent pour notre remixage dans une recherche de performance sonore, en vue de le présenter aux participants de l’expérience n°2 et d’apporter la réponse la plus aboutie à nos questions. C’est pourquoi, après comparaison des outils, nous avons choisi de séparer les sources de la chanson B- A-B-Y avec le logiciel d’apprentissage profond RipX, basé sur la détection des harmoniques des notes et présenté en section I.C.3.3. Pour affiner ce résultat, nous avons à nouveau conclu cette séparation en retouchant les spectrogrammes des sources sur SpectraLayers.
1) La détection des notes et des harmoniques, le facteur qualité décisif
Comme nous l’avons constaté en II.A.1.2., la séparation de sources que réalise SpectraLayers affiche plusieurs limites importantes. Au contraire, RipX écarte presque toutes ces limites grâce à l’apport déterminant de la détection des notes puis de leurs harmoniques.
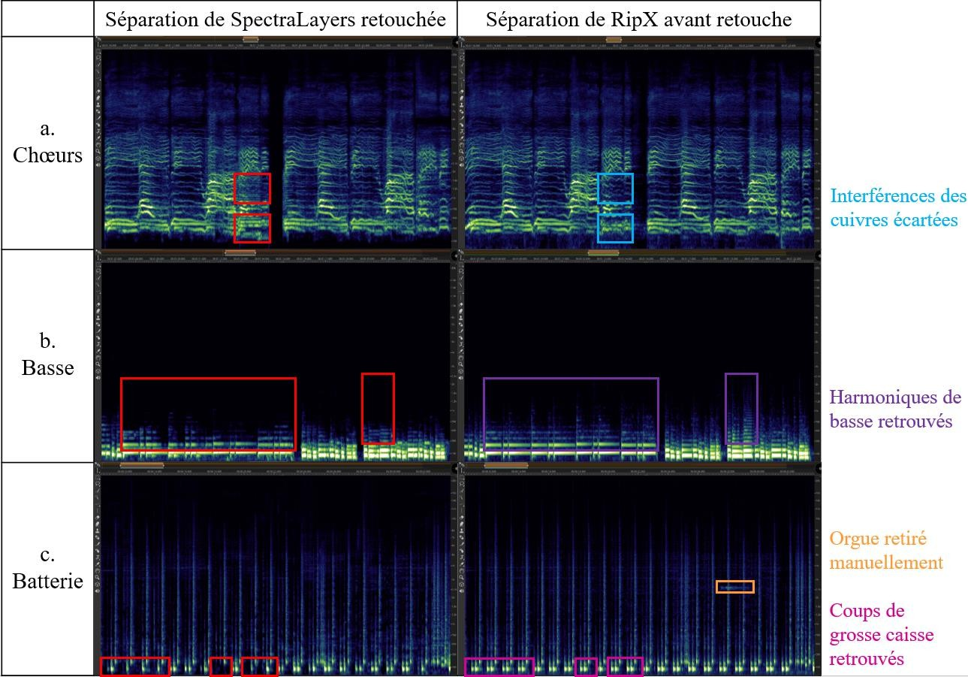
D’abord, comme RipX relie chaque note à la source qui la joue, aucune interférence n’existe par exemple dans le stem « Voix » avec les autres sources (figure 37a), contrairement à celui délivré par SpectraLayers.
Ensuite, la détection des harmoniques de RipX offre une meilleure qualité subjective de séparation et de définition pour certaines sources sonores. La figure 37b illustre ce phénomène sur la basse, dont le rendu sonore original était le plus gênant au regard de la musique selon les participants de l’expérience n°1. Sans cette détection préliminaire, SpectraLayers nous avait obligé à retirer manuellement du stem « Basse » les interférences d’autres sources, et avec elles, le peu de son contenu harmonique disponible, limitant ainsi la bande passante supérieure de l’instrument à 1 kHz environ. RipX, en détectant ses harmoniques, a su isoler proprement la basse et surtout reformer son enveloppe sonore, redéfinissant toutes ses transitoires d’attaques avec une bande passante supérieure atteignant 3 kHz.
Le passage de la séparation de sources de SpectraLayers retouchée à la séparation brute de RipX permet les bénéfices suivants : une récupération des informations harmoniques et dynamiques de l’ensemble des sources, une stabilité harmonique et ainsi présentielle de tous les signaux au cours du temps, une forte réduction du nombre et de l’intensité des interférences entre les sources et ainsi une raréfaction des artefacts numériques.
Cependant, la détection des notes et des harmoniques a aussi révélé certains évènements indésirables. Comme le souffle de l’enregistrement n’est ni un signal harmonique, ni un signal inharmonique, RipX ne le détecte pas et n’en tient donc pas compte pour la séparation. En parallèle, lorsque les harmoniques aigus ont une intensité inférieure à celle du souffle, le logiciel n’est plus capable de les repérer et est donc forcé de les ignorer également. Toutefois, cette limitation dans le haut du spectre des signaux de batterie (cymbales), de piano et de chœurs ne nous a pas paru limitante en écoutant la séparation effectuée. La séparation qui en résulte paraît finalement fidèle à notre perception de la musique multi-instrumentale, dirigée vers le sens musical non bruité et concentrée sur les aspects harmoniques et dynamiques des instruments.
2) Disparition des limitations de remixage relevées à l’expérience n°1
Sur les 12 limitations relevées par les participants de l’expérience n°1 pour le remixage de B-A-B-Y basé sur la séparation effectuée et retouchée sur SpectraLayers, nous avons constaté que 9 avaient disparu dans la séparation de RipX, avant même notre retouche manuelle. Nous donnons en annexe C1 un tableau récapitulatif de l’amélioration progressive de la qualité des signaux isolés de la chanson, depuis la séparation brute de SpectraLayers jusqu’à la séparation de RipX retouchée sur SpectraLayers. La séparation avec RipX a permis trois avantages principaux.
Premièrement, les signaux issus de RipX se révèlent intrinsèquement mieux définis et plus constants. En les écoutant isolément, nous ressentons personnellement un contact beaucoup plus fort avec chaque interprète, grâce à la nouvelle définition des enveloppes dynamiques, expliquée précédemment. Par exemple, ce logiciel révèle le jeu et le groove du bassiste, tandis que certains participants déploraient le manque d’informations livrées par SpectraLayers. De même, le piano incomplet et inconstant donné par ce dernier laisse place grâce à RipX à un instrument ayant récupéré toute la partie de la main gauche, avec toutes ses attaques, et ce tout au long du morceau.
Deuxièmement, RipX a exaucé partiellement l’un des souhaits de remixage des participants de l’expérience n°1 en rendant la grosse caisse indépendante du reste de la batterie (figure 37c), avec une présence plus constante que dans la séparation de SpectraLayers. Nous avons dû cependant retoucher le stem « Kick » pour déplacer certaines interférences de caisse claire vers le stem « Batterie ». Avec ce stem supplémentaire, RipX fait passer de 8 à 9 le nombre de sources que nous aurons à disposition pour le remixage immersif de B-A-B-Y.
Finalement, RipX estompe tous les artefacts de SpectraLayers qui limitaient des participants pour élargir l’image sonore et égaliser certains instruments comme la basse, la guitare et le piano.
2. Ligne de conduite du remixage
Fort des résultats de l’expérience n°1, nous avons souhaité respecter au maximum les remarques et les actions des participants pour remixer à notre tour, cette fois-ci sans la moindre limitation, la chanson B-A-B-Y de Carla Thomas. De plus, nous avons retenu le discours de certains participants pendant l’entretien préliminaire, qui recommandaient une documentation avisée de l’enregistrement de la chanson avant de réaliser un tel travail.
1) Objectifs musicaux de remixage issus de l’expérience n°1
Fidèlement à la visée artistique de notre recherche, nos objectifs de remixage immersif de B-A-B-Y sont avant tout musicaux. Nous les désignons donc par les cinq caractéristiques musicales de la chanson les plus souvent mentionnées par les participants à la question QB1 de l’expérience n°1, que nous chercherons à favoriser au maximum : le groove39, l’originalité de l’arrangement, la voix centrale, le genre soul et le label Stax.
Ces deux derniers traits caractéristiques ont une très forte signification sur le plan musical, culturel et historique, qui mérite de notre part de plus amples informations contextuelles. Dans l’Amérique ségrégationniste que nous avons exposée en section I.A.1., la ville de Memphis (Tennessee) concentre l’activité musicale la plus intense pour conter par les mots, les cris et le rythme, tous les drames sociétaux qui touchent la région. Au 926 East McLemore Avenue, Stax Records symbolise mieux que tous les autres labels soul cette affirmation d’identité noire. Il oriente volontairement sa musique vers toute cette population pour l’extraire des maux quotidiens. Le « son Stax », aussi appelé « Memphis Sound », se reconnaît parmi toutes les esthétiques sonores de labels par un aspect brut, tranchant et parfois rêche. En particulier, le son acoustique sec et brutal de la caisse claire d’Al Jackson, le batteur maison, impulse cette couleur sonore à tous les autres musiciens du studio (Bowman, 1997). L’un des experts 1950-60 nous a confiés que le master original de la chanson de Carla Thomas40 sonnait étonnamment […] un peu plus pop que les autres enregistrements Stax. Lors de notre remixage immersif, nous tenterons dans un rappel culturel et historique de retrouver le cachet sonore Stax et nous analyserons à travers les questions posées aux participants de l’expérience n°2 dans quelle mesure cette démarche profite à l’œuvre.
2) Choix de remixage issus de l’expérience n°1
Ensuite, nous avons relevé puis analysé par théorie ancrée l’ensemble des remarques formulées aux questions QB3 à QB5 pour lister les manipulations de remixage à opérer prioritairement, concernant respectivement l’équilibre entre les instruments, leurs timbres et leur espace propre et environnant.
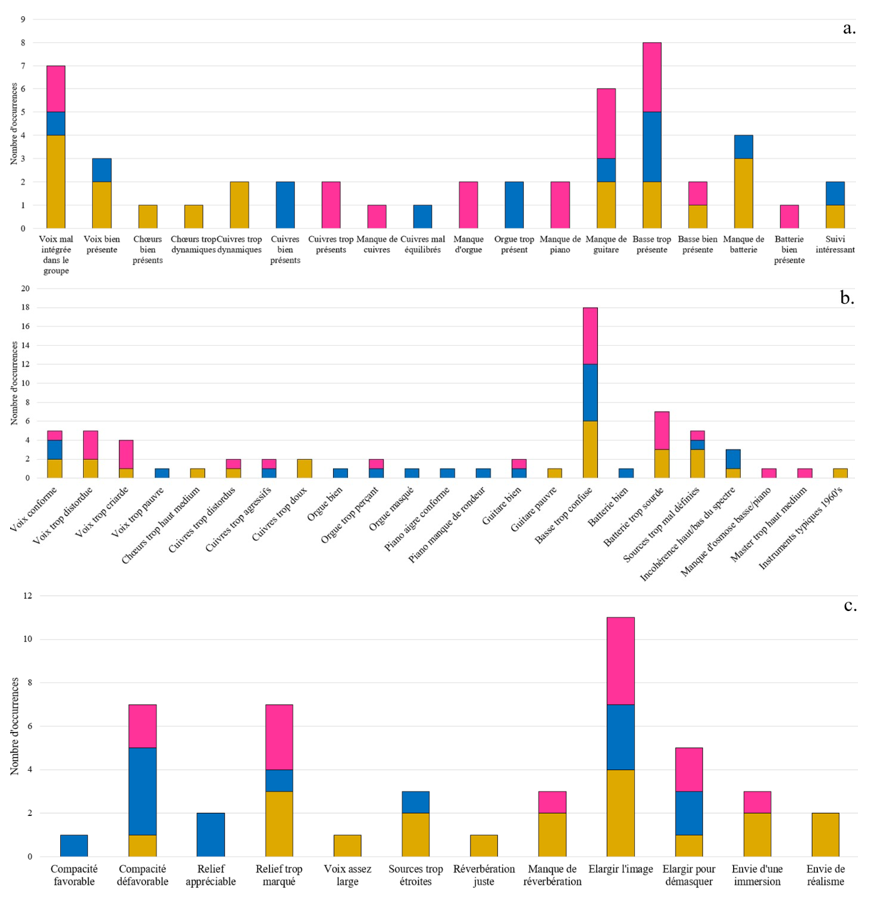
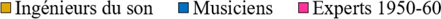
D’après la figure 38a, nous devrons intégrer davantage la voix et la basse dans le reste du groupe et augmenter particulièrement la guitare et la batterie41. La figure 38b indique quant à elle que nous devrons en priorité clarifier la basse42 et la batterie43, qui empêchent selon les participants de ressentir tout le groove que contient l’œuvre. Comme désiré, nous redéfinirons également dans ce but l’ensemble des sources. Spatialement, selon la figure 38c, nous élargirons l’image de l’enregistrement et nous réduirons l’espace entre les différents plans sonores, en augmentant notamment la taille de chaque source dans un nouvel espace 3D. Nous moulerons alors ce dernier en cherchant à nous sentir immergés dans le studio A du label Stax, renvoyé par exemple au jour de la séance d’enregistrement.
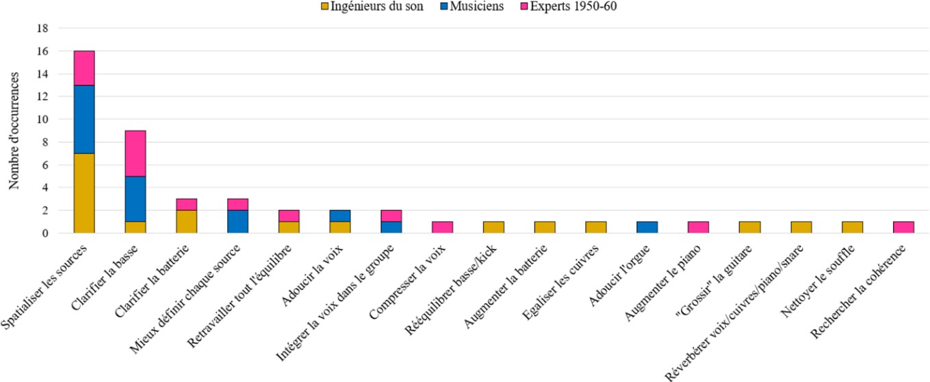
L’abandon de l’espace mono original de la chanson mérite de notre part une réelle considération historique, de laquelle nous tirerons notre justification. Comme nous l’avons expliqué en section I.A.3.1., les enregistrements des années 1950-60 étaient produits de telle manière à aligner le master publié sur le support d’écoute dominant à l’époque, le poste radio mono. Ainsi, conformément à notre responsabilité de nous renseigner sur sa nature créative ou subie, nous sommes en mesure d’affirmer que l’aspect mono du master original de B-A- B-Y n’a pas été décidé en 1966 par les acteurs de l’enregistrement (le producteur du label Jim Stewart, l’ingénieur du son Tom Dowd et les musiciens de la séance) dans un but artistique, mais par une contrainte technique à laquelle la musique a dû au contraire se plier44. Toutefois, en observant la popularité de cette chanson dès le moment où elle a été publiée45, nous pouvons constater que cette contrainte a été exploitée avec succès. Mais parce que notre étude donne la priorité à l’essence musicale des chansons, que 62,5% des participants de l’expérience n°1 mentionnent que l’aspect mono du master original est en fait limitant pour la chanson B-A-B-Y et qu’en spatialiser les sources constitue pour elle leur plus grand désir de remixage (figure 39), nous avons décidé pour notre propre remixage de nous affranchir de cette contrainte mono et de libérer les instruments de ce morceau dans un nouvel espace sonore immersif. Christophe Pirenne (1994) nous fait savoir que « l’essence de la musique soul repose sur l’expression et la transmission d’émotions et de sentiments très forts ». Tel est donc ce que nous espérerons que les participants de l’expérience n°2 ressentiront à l’écoute de notre master immersif de la chanson de Carla Thomas.
3) Compromis personnels
Comme ces différents désirs restent moyennés sur les 24 participants de l’expérience n°1, nous avons dû faire des choix sur la manière exacte d’effectuer ces opérations, en tenant comme ligne directrice les objectifs musicaux qu’ils nous donnent en section III.A.2.1.
Tout d’abord, pour produire le meilleur produit sonore possible, nous ne nous sommes fixés aucune limitation concernant le nombre de manipulations de remixage. Nous aurions pu nous ouvrir à de nouveaux paramètres de mixage, mais nous avons réalisé pendant notre travail que l’interface de remixage de l’expérience n°1 combinée à SPAT Revolution était en fait en mesure de répondre à tous nos besoins sonores.
Bien qu’en nous limitant à ces mêmes paramètres de mixage, nous avons ajusté précisément la fréquence de coupure de chaque égaliseur. Comme le facteur Q de l’égaliseur ne peut être modifié dans SPAT Revolution, ce travail s’avère essentiel pour redéfinir de manière appropriée chacune des sources sonores.
Mais avant cela, nous avons réfléchi à une disposition spatiale des sources la plus pertinente musicalement. Pour favoriser l’impression de réalisme46 du studio d’enregistrement, nous avons décidé, telle une performance live47, de placer tous les instruments devant nous (figure 40), tandis que tout l’espace latéral, arrière et supérieur allait être réservé à la réverbération immersive de SPAT Revolution. De plus, en gardant les instruments dans une même face de l’espace tridimensionnel, nous conservons l’esprit de groupe, cher aux studios Stax48 et donc à cette chanson. Pour éviter un aspect trop ponctuel des sources et conserver la fusion musicale qui existe entre chacune d’elles, nous avons opté pour un mixage orienté objet avec objets stéréo. Et pour sentir de façon réaliste l’espace qu’occuperait chaque source, nous avons joué sur la largeur de chaque objet. En commençant notre travail, pour honorer l’objectif musical premier qu’est le groove, nous avons réuni au centre de l’image sonore les trois instruments qui en sont selon nous les garants : la voix (et chœurs), la basse et la batterie. Nous avons légèrement écarté ces deux derniers de part et d’autre de la voix, permettant un premier démasquage. Et pour illustrer l’originalité de l’arrangement, nous avons réparti le reste des instruments de part et d’autre de ce socle rythmique. Pour sentir la cohésion de la section rythmique, nous les avons placés ensemble à gauche de l’image. Et pour permettre aux cuivres de donner toute leur puissance sans menacer d’autres instruments, nous leur avons réservé le côté droit de l’image. En ajustant la position de chaque source, nous avons finalement toujours cherché à la démasquer des autres pour mieux percevoir son rôle dans l’arrangement, sans pour autant perdre le lien musical qu’elle entretient avec les autres. En écoutant l’avancée de notre remixage, nous avons compris que c’est cet équilibre de distances entre les sources, bien que compensé en niveau et en égalisation, qui serait la clef pour valoriser simultanément le groove et l’arrangement de la chanson.

Enfin, pour servir notre objectif de réalisme sonore, nous nous sommes aidés de photos et d’extraits vidéo montrant le studio A de Memphis pour imaginer et paramétrer une réverbération plausible du lieu. Nous avons ensuite proportionné le niveau de réverbération de chaque source à celui que cette dernière engendrerait de manière acoustique. Avec grande parcimonie pour respecter le style musical du morceau, les sources que nous avons le plus réverbérées sont donc la voix lead, les cuivres et la batterie.
Nous verrons en sections III.B.4. et III.C.4. dans quelle mesure notre remixage immersif de B-A-B-Y remplit les objectifs musicaux énoncés en section III.A.2.1.
B. Test d’écoute pour « producteurs » : valider la réalisation et discuter la pertinence du master remixé
Comme indiqué en préambule, nous organisons deux tests d’écoute comparative du master original et de notre nouveau master immersif de la chanson B-A-B-Y. Le premier test, destiné aux « producteurs », vise à évaluer l’intérêt musical et culturel de partager au grand public notre master remixé (Q.R.5). Pour nous garantir une équité entre les deux expériences et mesurer notre étude au plus grand nombre, nous n’avons invité à l’expérience n°2 aucun participant de l’expérience n°1. L’exception concerne les trois experts 1950-60 du test pour « consommateurs », faute d’avoir pu en trouver d’autres.
1. Profils de « producteurs » de musique
Pour y recevoir une expertise technique et musicale approfondie de notre master remixé, nous avons invité à notre test par e-mail 8 professionnels de l’industrie discographique : 5 ingénieurs du son, 2 réalisateurs artistiques et 1 producteur musical, dont les renseignements personnels sont donnés dans le tableau 5. Certains de ces participants comptent parmi les plus grands spécialistes du label Stax et de son esthétique sonore particulière, ou de la pratique du mixage musical en son immersif.

2. Déroulé et conditions du test
D’environ 45 min, le test pour « producteurs » se déroule en trois phases condensées.
Avant tout, nous présentons au participant le contenu et les objectifs de l’expérience, et nous nous assurons de sa bonne compréhension. Pour commencer, nous l’invitons à s’asseoir sur la chaise haute que nous avons placée au centre du système de diffusion, pour écouter le master original mono de B-A-B-Y. Nous l’appelons ensuite à répondre à un questionnaire électronique, que nous donnons en annexe C2, qui reprend exactement l’intitulé des questions QB2 à QB5 de l’expérience n°1. En effet, nous visons ici à évaluer le rendu sonore de chacun des masters par rapport aux caractéristiques musicales de la chanson : nous saurons des oreilles expertes des participants lequel des deux masters répond le mieux aux exigences de la musique sur chaque critère sonore (rendu sonore général, rendu de l’équilibre, des timbres et de l’espace des différentes sources). Pour éviter de fatiguer le participant, nous ne lui avons laissé qu’une seule case de justification pour toutes ces questions (QF5).
Puis nous lui proposons la même démarche pour notre master immersif de la chanson49 : écoute / questionnaire. Le questionnaire est identique au premier, relatif à la musique. Nous permettons au participant de réécouter à volonté chacun des deux masters, de les confronter sur des extraits de leur choix, et de se déplacer librement dans la pièce pendant les écoutes.
Nous demandons ensuite au participant de comparer les deux masters sur trois aspects musicaux primordiaux. Deux d’entre eux, le groove (QH2) et l’arrangement (QH3), proviennent de l’expérience n°1. La question QH1, qui porte sur l’âme de la chanson, tient une place majeure pour notre égard déontologique de modifier un objet sonore existant. Elle nous aidera à alimenter notre question Q.R.5 et ainsi, notre problématique a. Grâce à ces trois questions, nous pourrons donc évaluer l’intérêt musical de l’existence du master immersif.
En conclusion, nous l’invitons à jouer le rôle d’un producteur musical dans les questions QI1 à QI5, qui nous offriront alors un éclairage avisé sur le potentiel culturel et commercial de notre remixage en son immersif de la chanson B-A-B-Y. Pour rappel, ce dernier exploite un dôme de 44 enceintes. Or il est quasiment certain qu’aucun participant ne dispose d’un tel système de diffusion. Nous avons donc ajouté dans les questions QI1 et QI2 la mention « toute considération matérielle exclue », qui supposerait de pouvoir entendre ce nouveau master via un support d’écoute bien plus usuel, le casque50.
Ainsi, nous serons en mesure de répondre entièrement à la question Q.R.5.
Dès la phase d’écoute du master original jusqu’à la fin du test, nous nous asseyons à l’arrière de la salle pour perturber le moins possible le participant. Cependant, nous restons à tout moment à sa disposition pour répondre à ses questions.

3. Collecte et analyse des données
Nous collecterons les notes attribuées par les participants aux questions QF1 à QF4 et QG1 à QG4 pour en tirer des boîtes à moustaches qui décriront l’évolution de chaque critère d’évaluation sonore vis-à-vis de la chanson, du master original au master immersif. Nous rassemblerons les justifications de ces notes, écrites par les participants en QF5 et QG5, pour les synthétiser dans un tableau évolutif, visible en annexe C3. Nous récupérerons l’ensemble des réponses fermées données à la question QH1 et suivantes, pour en dessiner un tableau statistique complet. Enfin, nous réunirons les réponses des participants aux questions QI3 et QI5, pour les figurer dans un tableau conclusif, visible en annexe C4.
4. Résultats
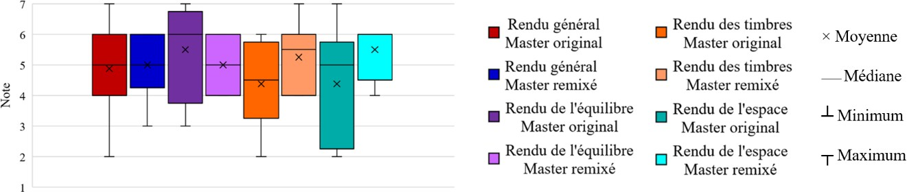
D’après la figure 42, les « producteurs » trouvent notre remixage en son immersif de
B-A-B-Y conforme à ce que suggère l’œuvre, et parfois davantage que le master original.
D’abord vis-à-vis de la chanson, ils donnent minimum en moyenne une note de 5/7 à chaque critère de rendu sonore de notre master remixé, qui témoigne donc d’un certain respect de l’écriture et de l’interprétation de l’œuvre. Par ailleurs, les participants jugent que notre master immersif offre pour 3 critères sur 4 un rendu sonore plus en lien avec la musique que le master original. Nous observons également une plus faible dispersion des notes en faveur de notre travail, sur tous les critères sonores. Bien que le rendu sonore général de B- A-B-Y ne progresse que très légèrement avec le master remixé, la plupart des experts sonores et musicaux se sont dits impressionnés par le changement dément provoqué par le master immersif, très beau, très chic, qui sonne, et surtout qui améliore et respecte le morceau, sans dénaturer le master original.
En vérité, ce sont les timbres et l’espace des sources qui profitent selon eux le plus de notre travail au regard de la musique. Leur rendu respectif passe ainsi de 4,375 à 5,25 et de 4,375 à 5,5 entre le master original et le master immersif. Le master remixé nettoie la vitre qui était entre le master original et l’auditeur, grâce à des instruments magnifiés, plus beaux comme le piano, plus clairs, plus agréables. La basse, dont le timbre confus entravait le plus la musique dans le master original lors de l’expérience n°1, est mieux définie, moins bourrue, plus constante tout au long du morceau, elle n’envahit plus et reste très présente sans écraser le son. Cependant, une minorité de participants nous ont révélé une batterie trop agressive, sans doute due au cachet Stax tranchant que nous avons tenté de lui redonner.
Quant à lui, le nouvel espace sonore, naturel, plus agréable et stable en se déplaçant selon les spécialistes du mixage en son immersif, a permis à la voix et aux autres sources de gagner de l’air, offrant à l’auditeur une meilleure impression de rendu de la dynamique du groupe et plus globalement une consommation plus directe, sans effort. Toutefois, certains participants ont été gênés par la batterie placée à droite de l’image, ou ont trouvé ce master immersif encore un peu trop frontal à cause d’une réverbération certes naturelle mais trop subtile. Ils ont donc été quelques-uns à souhaiter plus d’immersion.
En revanche, les participants ont été en moyenne moins convaincus musicalement par l’équilibre entre les sources dans notre master remixé que dans le master original. Les deux instruments relevés par une minorité de participants étant la voix trop en retrait, ce qui s’avère gênant par rapport à l’idée originale d’enregistrer pour la chanteuse , et la batterie avec une caisse claire qui claque trop parfois. Cela dit, le rendu global de l’équilibre des sources dans notre master immersif reste très correct avec une note de 5/7.
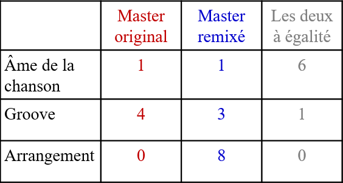
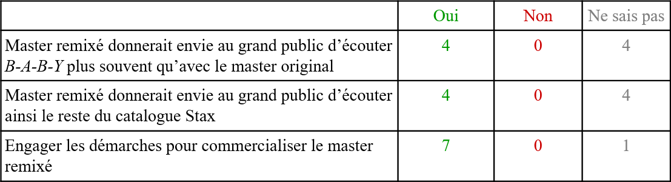
Comme indiqué en tableau 6, les participants ressentent plus le groove de la chanson dans le master original, tandis que tous entendent l’arrangement de la chanson mieux servi par notre master immersif. En effet, l’un d’eux pense que dissocier [spatialement] basse et batterie fait perdre du groove à notre master immersif, quand un autre trouve que ce dernier donne plus à entendre l’arrangement, dont on entend tous les détails . Mais 75% des participants s’accordent à dire que les deux masters parviennent, certes différemment, à retranscrire à égalité l’âme, l’essence de la chanson.
Comme mentionné sur le tableau 7, les participants sont très partagés sur une envie du grand public que déclencherait notre master immersif d’écouter la chanson B-A-B-Y plus souvent qu’auparavant avec le master original. Ils le sont tout autant sur celle du grand public d’entendre en son immersif l’ensemble du catalogue du label Stax. D’un côté, certains émettent des doutes quant à la capacité et à la sensibilité du grand public à dissocier le rendu original et ce remixage très respectueux, et même à entendre l’élargissement de l’image. À l’inverse, un autre participant loue les qualités d’écoute du grand public, qui pourrait être déstabilisé par le changement de « contrat d’écoute » entre le master original et le master remixé, de cette chanson enregistrée il y a presque 60 ans. De l’autre côté, d’autres participants se réjouissent de l’existence de ce nouvel éclairage qui faciliterait l’accès de cette musique au grand public, en attirant beaucoup de curieux pour un genre toujours très populaire aujourd’hui.
En revanche, presque tous les participants déclarent qu’en tant que producteurs de label, ils engageraient les démarches pour commercialiser notre master immersif de B-A-B-Y. Bien que certains ne verraient dans le label Spatial Audio qu’un argument marketing qui ne révolutionnerait pas cette musique, d’autres disent que le master original et notre master remixé, au nouvel éclairage intéressant, pourraient cohabiter pour favoriser l’accès à cette musique et laisser les gens s’amuser à comparer les deux versions.
5. Conclusions
À la lumière de ces résultats, les professionnels de l’industrie discographique que sont les ingénieurs du son, les réalisateurs artistiques et les producteurs musicaux, valident la réalisation technique de notre remixage en son immersif de la chanson B-A-B-Y de Carla Thomas. Selon eux, le rendu sonore y est en accord avec la musique, et nettement plus que le master original sur le plan des timbres et de l’espace des différentes sources. La dimension immersive et réaliste aurait pu toutefois être plus marquée d’après certains participants.
Par ailleurs, la grande majorité de ces spécialistes du label Stax et du mixage en son immersif ne voient aucune perte d’âme de la chanson à travers notre master remixé. Au contraire, ils plébiscitent à l’unanimité ce produit fidèle et respectueux de l’œuvre pour percevoir tous les détails de l’arrangement musical. C’est là aux yeux de tous les « producteurs » le grand intérêt musical de remixer aujourd’hui en son immersif la chanson B-A-B-Y de Carla Thomas (Q.R.5, problématique a). Ils notent néanmoins dans notre travail une légère perte de groove par rapport au master original, dont la cause possible est l’éclatement des sources dans l’espace, qui a justement profité à l’arrangement.
Bien que notre remixage leur paraisse réussi et convaincant musicalement, les participants sont partagés entre l’optimisme et le doute quant à la demande du grand public pour ce type de reconstruction immersive de la musique, pour cette œuvre et pour le catalogue du label en général51. Toutefois, avec une intention culturelle de partager un nouvel éclairage d’une œuvre et de favoriser ainsi son accès, ou uniquement commerciale dans le marketing actuel autour du son 3D, ils seraient quasiment tous enclins, en tant que producteurs d’un label comme Stax Records, à commercialiser notre master immersif de B-A-B-Y et à l’installer aux côtés du master original (Q.R.5, problématique a).
C. Test d’écoute pour « consommateurs » : évaluer la demande du grand public pour le master remixé
Après la validation de notre remixage en son immersif de la chanson B-A-B-Y par un cercle de professionnels de l’industrie discographique, ce dernier test d’écoute comparative qui concerne les consommateurs de musique s’avère crucial. En enrichissant notre réponse à la problématique a et en abordant seul la problématique b, c’est lui qui va clore et décider de l’issue de notre étude du remixage en son immersif de masters monophoniques des années 1950-60. Nous chercherons avec lui à savoir à travers quelle version sonore (originale ou remixage) les consommateurs préfèrent écouter B-A-B-Y (Q.R.6) et s’ils écouteraient notre version remixée plus souvent que la version originale si elle était publiée à ses côtés (Q.R.7).
Par souci de compréhension de la part des participants, nous n’emploierons pas dans toute cette partie le terme « master », mais nous préférerons parler de « version sonore ».
1. Profils de « consommateurs » de musique
Pour que le grand public soit le plus densément représenté à notre test, nous y avons convié par message le maximum de personnes. Forts du succès provoqué par l’accroche, nous avons reçu 45 participants issus pour la plupart de notre réseau de connaissances52 : 21 musiciens, 21 non musiciens, et 3 des 8 experts 1950-60 de l’expérience n°153. Bien que nous souhaitassions une égalité entre chaque profil pour une distribution conforme54, nous sommes parvenus à travers cette grande assemblée à remplir notre objectif premier de rassembler.
Quant aux non-musiciens, ce sont à la fois eux les plus grands consommateurs et les plus représentatifs du grand public. Leur présence nous est donc indispensable. Ensuite, nous avons conservé le profil des musiciens pour leur sensibilité auditive, dont le discours issu nous sera profitable. Enfin, le discours avisé des experts 1950-60 nous est tout aussi précieux que dans l’expérience n°1 vis-à-vis d’une chanson, B-A-B-Y (1966), qu’ils ont toujours entendue d’une manière et qu’ils vont entendre pour la première fois d’une autre. Nous réunissons en figure 43 les informations démographiques de ces participants.
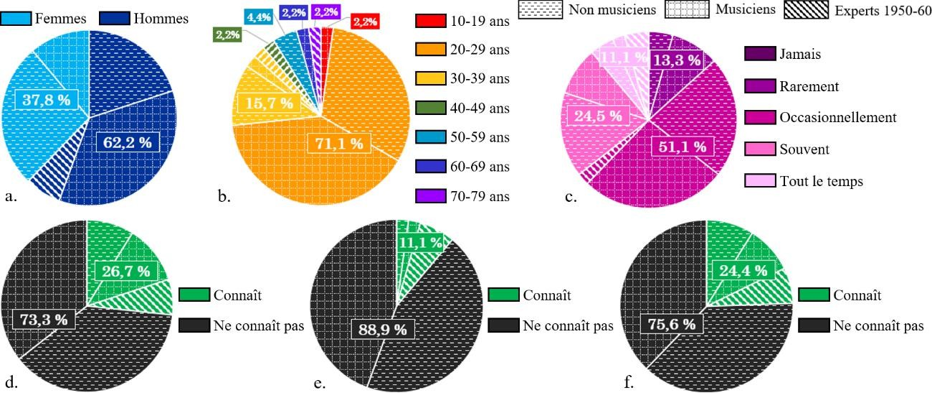
2. Déroulé et conditions du test
D’une durée de 30 min, le test pour « consommateurs » se déroule en trois temps. Premièrement, nous accueillons le participant au plateau 1 du conservatoire et lui demandons de répondre sur ordinateur à quelques questions démographiques (QJ1 à QJ5 visibles en annexe C5). Après cela, nous l’invitons à s’installer sur la chaise haute que nous avons placée au centre du système d’écoute de la salle (voir figure 41). Nous lui décrivons oralement l’expérience qui l’attend et lui indiquons ce qu’il va devoir déterminer : laquelle des deux versions sonores qu’il va entendre d’un même enregistrement lui procure le plus grand plaisir d’écoute. Se faisant, nous préparons le participant pour qu’il soit dans le meilleur confort pour un exercice certes plaisant mais inhabituel pour lui, en particulier pour un non musicien, qu’il puisse faire confiance à son oreille critique pendant les deux écoutes qui vont suivre. Nous commençons par lui faire écouter en intégralité la version originale et notre version remixée de B-A-B-Y, sans parler entre les deux55. Pour ne pas influencer le participant, nous ne lui évoquons pas avant la conclusion du test l’écoute d’une « version originale » et d’une « version remixée ». Nous craignons en effet qu’il perçoive négativement le terme « remixage », ou bien qu’il se montre complaisant envers notre version remixée s’il suppose que nous l’avons réalisée. Pour qu’il traite donc les deux versions à égalité et qu’il entende ce que chacune d’elles contient et renvoie de la musique, nous avons décidé dans notre discours et notre questionnaire de nommer « version A » la première version entendue et « version B » la seconde. En complément, pour nous affranchir d’un possible effet d’ordre, nous alternons secrètement entre chaque passage l’ordre d’écoute original/remixage. À l’issue des premières écoutes entières A et B et à tout moment du test, nous permettons au participant d’en effectuer d’autres à volonté sur des extraits précis qu’il pourra choisir, pour valider sa préférence.
Lorsqu’il la connaît, nous l’invitons à répondre sur ordinateur à notre questionnaire56. Ce dernier, disponible en annexe C5, propose toute une série de questions, souvent à choix multiples pour simplifier la réflexion du participant et garantir la fluidité du test. Nous les avons posées dans un ordre logique mais par facilité pour lui, nous lui permettons de les traiter dans l’ordre de son choix. D’abord, la question QK1 nous permet de retenir les émotions naissantes éventuelles du participant après les deux écoutes, susceptibles de s’évaporer au fil du test. Servant directement notre question Q.R.6, les questions QK3 à QK5 dominent quant à elles notre questionnaire.
Ensuite, pour confirmer notre priorité de la musique et maintenir ainsi le lien avec les deux tests précédents, nous avons inclus dans le test pour « consommateurs » les questions QK6 à QK8, identiques aux questions QH1 à QH3 du test pour « producteurs », concernant l’âme, le groove et l’arrangement de la chanson. Nos questions inverses QK9 et QK10, les plus détaillées, demandent au participant une certaine attention d’écoute. C’est là que nous rappelons oralement à ce dernier la possibilité de comparer le rendu de certains instruments en réécoutant certains extraits, qu’il peut choisir ou que nous pouvons proposer. Bien que le participant puisse cocher plusieurs critères perceptifs pour une même source, nous lui précisons bien de n’en cocher un que lorsqu’il a une préférence significative pour l’une des deux versions. Notre question QK11 rejoint les questions QK6 à QK8 des principales caractéristiques musicales de la chanson B-A-B-Y. Avant la phase de conclusion de notre test, nous suggérons aux participants une réflexion temporelle sur chacune des deux versions sonores (QK12 à QK14). Notre objectif à travers cette question est de voir certains participants se sentir dans la même époque via les deux versions sonores.
Enfin, après avoir informé le participant de l’identité des versions A et B57, nous concluons notre test par les questions QL1 et QL258 qui nous permettront de vérifier les hypothèses des « producteurs » émises en III.B.4., mais surtout de répondre directement à notre question Q.R.7 et à notre problématique b.
3. Collecte et analyse des données
Nous collectons les notes d’appréciation attribuées par les participants à la version originale et à notre version remixée de B-A-B-Y (QK3, QK4), pour en dessiner des boîtes à moustaches qui illustreront la moyenne et la dispersion d’appréciation de chaque version pour chaque profil. Nous rassemblons les réponses des participants aux questions QK5 à QK8 et QK1159 pour constituer des digrammes circulaires qui révèleront la version sonore préférentielle des participants pour chaque aspect musical mentionné. Nous sommons toutes les grilles de cases remplies par les participants aux questions QK9 et QK10 pour construire pour chaque critère sonore un digramme en barres multiples qui renseignera leur version préférée pour le rendu de chaque instrument. Nous nous aidons de leurs justifications pour interpréter ce diagramme. Nous recueillons les réponses des participants aux questions QK12 et QK13 pour composer un digramme circulaire qui dévoilera la version qui plonge les participants dans l’époque la plus éloignée d’aujourd’hui, la plus proche de l’époque d’enregistrement. Enfin, nous retenons les réponses des participants aux questions QL1 et QL2 pour former deux diagrammes circulaires qui répondront à notre problématique b.
4. Résultats
Avant tout, la grande majorité des participants ont ressenti beaucoup de plaisir à participer à ce test d’écoute comparative, un exercice qui leur a paru certes nouveau, mais stimulant pour leur écoute de la musique en général.
Les figures 44 et 45 nous révèlent un plébiscite généralisé pour notre remixage en son immersif de la chanson B-A-B-Y de Carla Thomas. En effet, les participants « consommateurs » sont 62,2% à préférer écouter cette musique à travers notre version remixée. De plus, il ne s’agit pas simplement d’une attirance pour un nouveau type de rendu sonore pour un enregistrement des années 1960, comme indiqué sur la figure 45 qui montre un réel plaisir des participants à écouter cette chanson dans la version immersive (appréciation moyenne de 7,5/10), davantage que dans la version originale (6,6/10 de moyenne). Nous notons également les 11,1% des participants qui, par choix argumenté, disent aimer autant l’une que l’autre version. Reste une minorité de participants (26,7%) qui privilégient l’écoute de la version originale, ce qui vient vérifier le constat sonore négatif de celle-ci, rendu par les participants de l’expérience n°1 en section II.B.1.1.
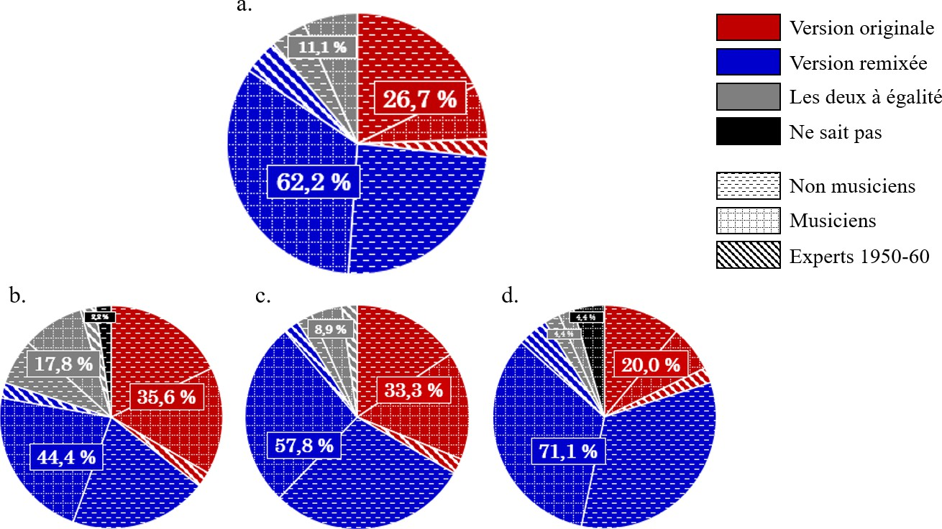
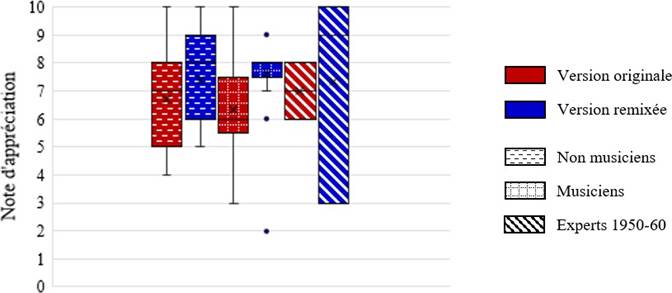
Sur le plan des principales caractéristiques musicales de la chanson énoncées par ceux – ci en section III.A.2.1., les « consommateurs » estiment à 57,8% ressentir plus de groove dans notre version remixée. Ils viennent ainsi contredire l’avis des « producteurs » en section III.B.4., qui désignaient la version originale. De plus, ils sont 71,1% à penser que notre version immersive met mieux en valeur l’arrangement de la chanson. Enfin, bien que les avis soient plus partagés, les participants sont toujours plus nombreux à juger que notre réalisation retranscrit le mieux l’âme de la chanson (44,4% contre 35,6% pour la version originale).
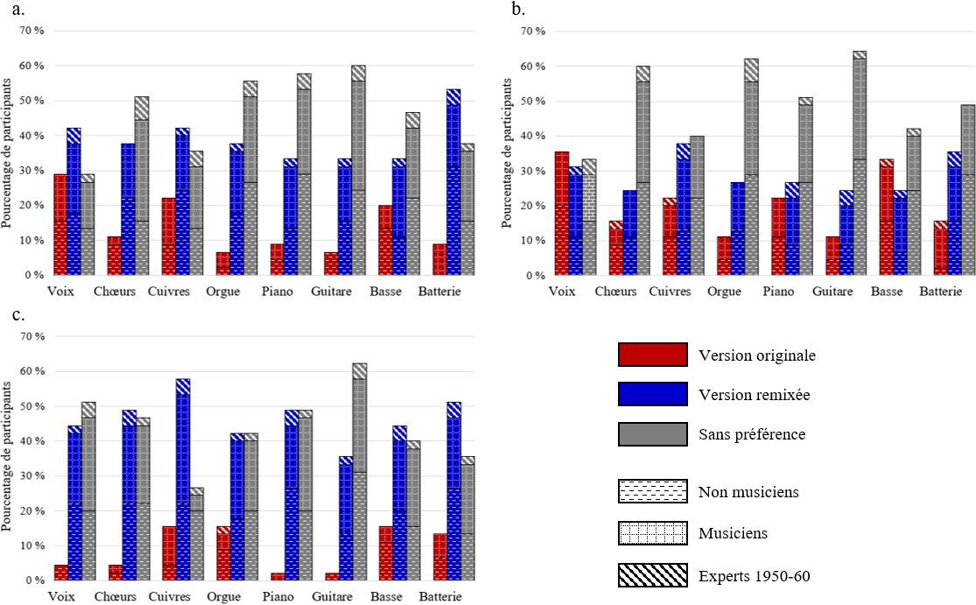
Dans le détail, la figure 46 nous apprend que les « consommateurs » n’ont la plupart du temps pas de préférence particulière pour le rendu sonore des différents instruments. Toutefois, certaines tendances se révèlent importantes.
D’abord, parmi les trois instruments qu’ils ont pensés oralement être les garants de l’âme et du groove de la chanson60, les participants sont les plus nombreux à préférer dans notre version remixée la présence de la voix61, et la présence et la place dans l’espace de la batterie. En revanche, ils sont très partagés concernant le timbre de la voix. La plupart d’entre eux (36%) le préfèrent dans la version originale, et d’autres (31%) dans notre version remixée. Cependant, en observant leurs justifications, nous remarquons qu’ils ne s’accordent pas sur ce qu’ils entendent : pour certains, la voix est plus présente ou bien plus agressive dans la version originale, et pour d’autres dans notre version remixée. En revanche, une tendance forte se dégage de la figure 46. Tous les participants ayant une préférence pour la présence et la place dans l’espace des instruments l’accordent très largement pour tous ceux-ci à notre version immersive. En particulier, la nouvelle présence des instruments62 a ravi de nombreux participants, grâce au nouvel espace propre qui apporte un vrai relief à l’ensemble. L’un des experts 1950-60 s’est réjoui de notre scène sonore pour pouvoir enfin chanter la partie de guitare et compter le nombre de cuivres : deux sax et une trompette. Plus globalement, 6 « consommateurs » ont aimé à travers notre version ressentir l’impression d’être dans le live, leur permettant de plus vivre la musique. Pour confirmer cette sensation de réalisme63, l’un des experts 1950-60 nous a avoué retrouver enfin [ce qu’il attendait] du son d’Al Jackson, le batteur maison : il est un des co-fondateurs du son Stax, nous dit-il, c’est donc logique qu’il apparaisse comme cela, [avec] la soudaine brutalité du coup de caisse claire . À ce propos, de façon tout à fait surprenante, 3 des 5 participants connaissant le son Stax nous déclarent qu’il est le mieux retranscrit dans notre version remixée. Un autre expert 1950 -60, spécialiste du genre et du label, nous avance même alors que si un mixage en stéréo [de B- A-B-Y] avait été conçu à l’époque64, cela aurait tout à fait pu être celui-là.

Nous arrivons à présent à la perception de la temporalité des versions sonores par les participants (figure 47). Pour rappel, bien qu’ils puissent s’en douter, ceux-ci ne savent pas qu’ils entendent la « version originale » et une « version remixée », et encore moins laquelle des deux versions A et B dissimule la version originale. De façon logique, c’est uniquement à travers cette version originale que la majorité des participants (53,3%) se trouvent baignés dans l’époque d’enregistrement de la chanson, qu’ils identifient souvent bien comme étant les années 1960. Les indices sonores ne leur manquent pas : un aspect plus brut, moins subtil, moins aéré de la version originale, au contraire de la modernité de notre version remixée, ressentie par la spatialisation des instruments. Mais par-dessus tout, nous sommes agréablement surpris par les 22,2% de participants qui ne se sentent plongés dans l’époque d’enregistrement que dans notre version immersive, pensant alors être la version originale. Nous n’avions pas prévu une telle perception de la part de ces participants, qui entendent dans notre version une sorte de grain musical qui correspond à leurs attentes imaginaires et les met ainsi en confiance. Ils ont été en fin de test très agréablement surpris de leur confusion65 et ne pensaient pas que ce genre de technique de mixage existait , capable de donner un grain à une musique, comme si elle datait de plusieurs décennies . Enfin, la même part de participants (22,2%) dit se sentir dans la même époque à travers les deux versions entendues, les années 1960. Selon eux, même avec l’éclatement des sources de notre version immersive, le son très caractérisé de la moitié du XXe siècle reste palpable. L’un des experts 1950-60 nous a même confié que le réalisme de notre version lui offrait un voyage temporel vers l’époque d’enregistrement.
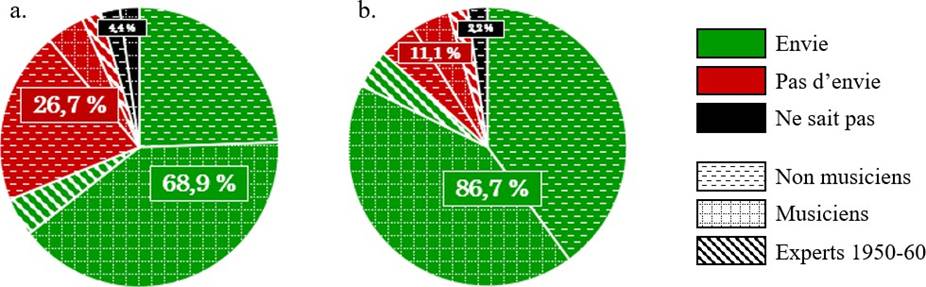
En conclusion d’après la figure 48, les « consommateurs » sont une très large majorité (68,9%) à avoir désormais envie d’écouter la chanson B-A-B-Y avec notre version remixée, plus souvent qu’avec la version originale. En particulier, 82% des participants qui connaissent la chanson et 75% des participants qui écoutent souvent ou tout le temps de la musique soul/R&B pour leur plaisir, ressentent cette même envie. L’une des non musiciennes nous confie66 être ébahie de découvrir que le positionnement des instruments joue à ce point sur les émotions procurées, quand l’un des experts 1950-60 nous indique qu’on aurait rêvé faire la chose pour ces artistes merveilleux de Memphis, Tennessee, et leur faire écouter . Par ailleurs, 86,7% des participants de notre test désireraient entendre le même type de transformation sonore sur l’ensemble du catalogue discographique du label Stax. En particulier, 87,5% des plus grands consommateurs de soul/R&B partagent ce désir.
5. Conclusions
En définitive, le remixage en son immersif de la chanson B-A-B-Y que nous avons opéré en section III.A. a conquis une large majorité de « consommateurs » de notre test, tant par rapport à la version originale que pour leur propre appréciation de la musique.
La plupart d’entre eux ressentent plus de plaisir à écouter cette chanson dans notre version immersive que dans la version originale, répondant ainsi à notre question Q.R.6. En attribuant à notre production une meilleure mise en valeur du groove et de l’arrangement musical, et même une meilleure retranscription de l’âme de la chanson, les « consommateurs » nous ont désigné leurs trois intérêts musicaux de remixer en son immersif la chanson de 1966 de Carla Thomas (problématique a). À leurs yeux, la musique s’épanouit dans son nouvel espace sonore qui revalorise la présence de tous les instruments et leur offre des timbres plus clairs et plus dignes du son du label Stax. En outre, bien que la majorité se sente davantage dans les années 1960 à travers la version originale, un groupe notable s’y retrouve tout autant en écoutant notre version immersive. Mieux, certains participants sont saisis par le réalisme sonore de celle-ci, qui les place soudain virtuellement devant les musiciens du groupe, en concert ou entre les murs du studio d’enregistrement.
Finalement, les « consommateurs » sont une très large majorité à éprouver l’envie d’écouter dans leur vie quotidienne la chanson B-A-B-Y plus souvent avec notre version remixée en son immersif qu’ils ne l’ont fait avec la version originale, répondant ainsi à notre question Q.R.7. Et ils sont encore plus nombreux à désirer entendre le reste du catalogue Stax, que beaucoup ne connaissent pas, dans des conditions de restructuration sonore similaires. Que le grand public exprime son envie de découvrir avec ce mode sonore un répertoire qu’il ne connaît pas suffisamment selon lui, incarne pleinement l’intérêt culturel du remixage en son immersif d’enregistrements monophoniques des années 1950 -60 (problématique a). Cela vient alors confirmer l’hypothèse des « producteurs » les plus optimistes sur la curiosité et l’engouement du grand public actuel pour ces reconstructions immersives d’enregistrements monophoniques. Néanmoins, pour répondre à notre problématique b, cet engouement ne vient pas combler une envie particulière des « consommateurs » actuels vis-à-vis des enregistrements anciens, car depuis longtemps, ils ont inévitablement appris à apprécier la musique au milieu des marqueurs temporels des versions originales. Simplement, d’après notre test, non seulement leur apprentissage ne les a pas enfermés dans une seule esthétique sonore possible pour la musique soul des années 1960, mais celle que nous avons adoptée dans notre version immersive a fait croître leur attachement à la musique, qu’ils ont pu pour la première fois apprécier dans son entièreté.
D. Discussion de l’expérience n°2 et conclusions
Cette seconde expérience nous apporte de forts enseignements sur le degré de pertinence musicale, culturelle et historique de la pratique du remixage en son immersif de masters monophoniques du répertoire soul des années 1950-60.
Initialement, les bienfaits d’une telle pratique sont musicaux. Comme nous l’avions pressenti en préambule, la chanson B-A-B-Y de Carla Thomas, dont le rendu sonore original a été le plus vivement critiqué par les participants de l’expérience n°1, a largement bénéficié de notre remixage en son immersif, d’après les participants de l’expérience n°2. Les premiers participants en sont à l’origine. En effet, nous avons retenu les principales caractéristiques musicales de l’œuvre qu’ils nous ont adressées, nous permettant de tracer notre direction de remixage. Nous avons noté leurs envies sonores dominantes vis-à-vis de la chanson, sur le plan du rendu de l’équilibre, des timbres et de l’espace des sources, et nous avons repris les manipulations de remixage qu’ils avaient amorcées pour les réaliser. À l’occasion d’une écoute comparative au cours de laquelle nous les avons invités à jouer le rôle d’un « producteur » de label, des professionnels de l’industrie discographique ont validé notre travail de remixage, respectueux de la chanson et lui offrant des timbres et un espace plus favorables à son expression. Lors d’une autre écoute comparative, les « consommateurs » de musique, que sont non musiciens, musiciens et experts musicaux 1950-60, comme les « producteurs », nous ont explicitement désigné le grand intérêt musical de remixer en son immersif des masters monophoniques des années 1950-60 : mettre en lumière l’arrangement d’une chanson (problématique a). En effet, certains éléments qui étaient dissimulés dans la version originale de B-A-B-Y sont soudain apparus aux oreilles de tous ces participants de manière claire et directe dans le nouvel espace de notre version immersive. Au contraire des « producteurs », les « consommateurs » y ont même mieux ressenti un autre aspect de la chanson : le groove. Cependant, l’observation des « producteurs » vérifie la nôtre pendant notre remixage. Comme le groove repose sur la fusion entre les instruments et que l’arrangement peut être éclairé par un éclatement spatial, il est difficile dans un remixage en son immersif d’améliorer réellement les deux aspects à la fois. C’est pourquoi nous avions choisi d’ouvrir l’espace conformément aux désirs des participants de l’expérience n° 1, et d’optimiser le groove en revoyant le niveau et le timbre de la basse et de la batterie, comme ils nous l’avaient également suggéré. Mais ce sont bien ces deux aspects musicaux réunis, qui constituaient alors notre direction de remixage tracée par les participants de l’expérience n°1, qui ont conduit la grande majorité des « consommateurs » à aimer écouter B-A-B-Y avec notre version immersive, plus qu’avec la version originale. Simultanément, cette majorité confirme l’expertise des « producteurs » sur le respect de l’œuvre dont fait preuve notre remixage. La recherche documentaire que nous avons effectuée sur l’identité du label Stax dans le contexte musical et politique des années 1960 nous a été très précieuse. Elle nous a aidés à éclairer l’œuvre sans la dénaturer, à changer drastiquement le rendu sonore du master original tout en respectant le style de la chanson et les intentions originelles des musiciens et des arrangeurs. Au vu des résultats des deux tests d’écoute comparative, nous y sommes parvenus.
Ainsi, par la musique, le remixage en son immersif de masters monophoniques des années 1950-60 trouve son intérêt culturel. Les « consommateurs », en montrant leur envie d’écouter de manière immersive B-A-B-Y comme le reste du catalogue Stax, répondent à l’adhésion des « producteurs » de commercialiser notre produit. La grande majorité de ces « consommateurs » exprimant cette envie nous ont avoué dans le même temps ne connaître que très vaguement le répertoire de ce label légendaire. La perspective pour eux serait ainsi alléchante : le découvrir en intégralité et avec le même plaisir d’écoute (problématique a).
Tandis que la question culturelle s’intéresse à la relation entre l’auditeur et les œuvres, la question historique pourrait concerner celle entre l’auditeur et les interprètes. Certains résultats de notre ultime test montrent cette tendance. Les « consommateurs » n’éprouvent pas d’envie particulière vis-à-vis des enregistrements anciens (problématique b), car ils se sont naturellement formés à l’idée que ceux-ci ne peuvent exister que dans leur apparence originale mono. Pourtant, en découvrant à travers notre test que cette démarche est en fait techniquement possible, ils sont surpris et fascinés. Plusieurs participants nous ont confié en écoutant notre version immersive avoir l’impression de se sentir virtuellement devant les musiciens, en concert ou sur le plateau du studio d’enregistrement. Bien que ces sensations de réalisme soient ici minoritaires, nous pensons juste et responsable de les prendre au sérieux dans le cadre du remixage en son immersif de masters monophoniques des années 1950 -60. En effet, les « producteurs » nous ont spontanément affirmé que la dimension immersive de notre nouveau master aurait pu être plus forte. Mais pensons au fait que, pour renforcer sa présence, nous pourrions continuer d’affiner les contours acoustiques de l’espace que nous souhaitons recréer en lien étroit avec le style musical. Alors ces participants immergés pourraient être en fait bien plus nombreux. Finalement, la large majorité des « consommateurs » conquis par la spatialisation des instruments d’une chanson enregistrée en 1966 s’accompagne de la sensibilité de certains participants au réalisme de notre master remixé pour nous indiquer le chemin à suivre des futurs travaux en matière de remixage immersif de masters monophoniques des années 1950-60 : préciser et renforcer vraiment l’immersion. Au regard de l’expérience n°2, nous sommes en mesure d’affirmer que le grand public semble prêt. De cette manière, si ces nouveaux produits réalistes et immersifs intègrent leurs habitudes d’écoute, ils créeront un espace commun entre deux époques distantes de plus de 60 ans, atout historique majeur pour les générations actuelles.
Discussion générale
Notre étude démontre l’intérêt musical, culturel et historique de remixer aujourd’hui en son immersif des masters monophoniques de blues/R&B/soul des années 1950-60. Pour cela, nous avons conçu deux expériences complémentaires : la première, qui évaluait les comportements de réflexion, d’écoute et de remixage de 24 participants face à des masters originaux de cette époque, nous a indiqué celui dont le rendu sonore défavorisait le plus le message musical, à savoir la chanson B-A-B-Y de Carla Thomas ; nous l’avons donc remixé en son immersif et l’avons soumis à 8 professionnels de l’industrie phonographique et 45 consommateurs de musique dans une seconde expérience d’écoute comparative avec le master original. D’abord, pour deux des trois morceaux du répertoire ciblé proposés à l’expérience n°1, les participants ont jugé en moyenne que le rendu sonore de leur version remixée servait davantage le propos musical que la version originale. Puis dans l’expérience n°2, les professionnels de l’industrie phonographique ont révélé le respect de l’œuvre originale dont faisait preuve notre version remixée en son immersif de B-A- B-Y, quand les consommateurs l’ont en grande majorité préférée à la version originale et seraient désormais prêts à écouter cette chanson plus souvent ainsi.
Plus précisément, les consommateurs éprouvent beaucoup de plaisir à entendre dans notre version remixée tout ce que la chanson B-A-B-Y comprend et véhicule d’un point de vue musical et émotionnel. Grâce au nouvel espace immersif introduit, comme les professionnels de l’industrie phonographique, ils ont aimé mieux percevoir les instruments qui constituent l’arrangement. Cet attrait confirme l’analyse de Giles Martin, qui a tout récemment remixé en son immersif l’album Pet Sounds des Beach Boys : « Placer ces sons dans un espace immersif signifie […] que vous pouvez entendre des instruments que vous n’avez jamais entendus auparavant. Ils sont dans l’enregistrement, mais ils sont maintenant dans un espace où vous pouvez les identifier » (The Beach Boys, 2023). En outre, selon les consommateurs, notre version remixée retranscrit mieux l’âme de la chanson, ce qui vient confirmer l’expertise des professionnels de l’industrie phonographique sur le respect de l’œuvre. « Les gens n’écoutent jamais de la technologie, ils écoutent de la musique », affirme Martin (Tamarkin, 2023). De même, nous n’avons pas souhaité faire un remixage technologique, mais musical de B-A-B-Y. Les résultats positifs de l’expérience n°2 viennent donc approuver l’intérêt pour la musique de penser réciproquement par elle lors du remixage, et bien avant déjà. Certes le rendu sonore du master original découle du magnétophone 2 pistes utilisé et du mixage de 8 voies effectué en direct. Mais la majorité des participants de l’expérience n°1 jugent que ces failles entravent le message musical des interprètes.
Par ailleurs, les moyens d’écoute du grand public ont bien évolué depuis les années 1960, et le casque, très usuel aujourd’hui, ne semble pas encourager les auditeurs à écouter de la musique en mono. Si l’on souhaite que ces trésors musicaux afro-américains traversent les époques, il serait opportun de l’adapter aux moyens d’écoute actuels. Nous suivons ainsi le discours de Martin : « Il y a une génération qui n’écoute pas de mono, alors comment respectez-vous cela ? » (Cruse, 2023). Comme les labels l’ont fait dans les années 1960 en privilégiant le master mono pour encourager le plus grand nombre d’écoutes à la radio, nous pourrions tout autant aujourd’hui satisfaire le grand public en lui proposant à la mesure de son medium favori un master binaural après réduction du master immersif. C’est là la politique menée par Apple avec ses catalogues musicaux en Dolby Atmos. Mais plutôt que de ne réserver ceux-ci qu’aux enregistrements stéréo, il serait aujourd’hui opportun de se pencher sur le cas des enregistrements mono. En effet, bien que nous le pensions encore améliorable, notre remixage en son immersif de B-A-B-Y a provoqué chez plusieurs participants une immersion si forte que pour la première fois en écoutant cette chanson de 1966, ils se sont sentis devant les musiciens entre les murs du studio d’enregistrement. Cette sensation a capté leur imaginaire, et leur a donné envie, comme bien d’autres, d’écouter les autres chansons du label Stax dans les mêmes conditions. L’intérêt culturel du remixage en son immersif de masters monophoniques des années 1950-60 est donc prolongé par un intérêt historique, puisque cette pratique, via la sensation de réalisme, pourrait permettre de construire pendant trois minutes un pont virtuel entre le moment actuel d’écoute et le jour d’enregistrement d’une chanson. Cette idée rejoint celle de Martin lorsqu’il a remixé Pet Sounds : « Ce que j’ai essayé de faire, c’est d’être plus proche de l’enregistrement […] et de trouver un sens à ce que c’est d’être dans le studio avec le groupe » (Tamarkin, 2023). Bien que les participants immergés auraient peut-être été plus nombreux si nous avions basé notre remixage sur la construction d’une scène sonore réaliste, ce phénomène donne en tout cas une réelle indication sur le potentiel perceptif de l’approche immersive. Notre étude illustre enfin la grande avancée aujourd’hui que représente la séparation de sources par apprentissage profond. Celle-ci satisfait un désir, celui de se réapproprier le son des enregistrements anciens, aux bandes multipistes alors inexistantes.
Grâce à sa détection décisive des harmoniques du signal, RipX nous a permis de remixer B- A-B-Y sans la moindre limitation, et le démasquage spatial des sources n’a pas fait ressortir d’artefact issu de la séparation. Pourtant, avant de le découvrir, nous avions opté pour l’outil SpectraLayers, pensant alors que retoucher aussi précisément les spectrogrammes des sources allait nous offrir un meilleur résultat de séparation que tous les autres outils automatiques du marché. Cette orientation spontanée, qui peut s’expliquer par notre expérience manuelle d’ingénieur du son, a conduit à une limite de notre étude, celle de ne pas avoir utilisé RipX en vue de l’expérience n°1. Cependant, découvrir successivement ces deux outils nous a permis d’approfondir notre connaissance de l’état de l’art de la séparation de sources et de choisir chaque outil en fonction de nos besoins. En particulier, si nous n’avions pas découvert l’éditeur SpectraLayers, nous n’aurions pas pensé pouvoir optimiser par retouche manuelle la séparation livrée par RipX, ultime étape qui a ouvert la voie de notre remixage final.
Par ailleurs, pour faciliter et donc améliorer encore la séparation de sources de RipX, nous aurions pu plutôt lui fournir le master stéréo de B-A-B-Y. Comme celle-ci a été enregistrée sur un magnétophone 2 pistes, toutes les sources sont totalement situées sur le canal gauche ou droit de la stéréo. Cette image sonore offre un démasquage avantageux entre les sources, ce qui permettrait donc pour elles une séparation plus aisée, plus proche encore d’une véritable bande multipiste. Par exemple, les accords secs de guitare confondus avec la caisse claire dans le master mono, auraient été mieux séparés depuis le master stéréo, où ils le sont déjà dans l’image.
Mais ces deux limitations n’ont ni entravé nos objectifs musicaux de remixage de B-A-B-Y, ni altéré les choix de remixage des premiers participants. En profitant des outils actuels de séparation de sources, nous sommes d’ailleurs finalement heureux d’avoir pu réaliser dans l’expérience n°1 le projet de Clavel (2003, p.5) de « proposer à [ceux-ci] d’effectuer [eux-mêmes leur] opération de mixage en [leur] laissant la possibilité de placer les sons à [leur] convenance ».
Avec les progrès constants des techniques de séparation de sources et l’engouement pour l’audio immersif, les perspectives de recherches s’avèrent exaltantes. Remixer en son immersif d’autres répertoires, d’autres époques d’enregistrement, en désigne sûrement une. En particulier, mesurer la grandeur acoustique d’un big band des années 1930-40 et se sentir soudain devant cette masse de musiciens est un projet crédible, mais hautement exigeant. Pour l’apprentissage supervisé, cela impliquerait de constituer un catalogue d’enregistrements de big band multipistes, caractérisés par un souffle, des timbres, un espace et une dynamique typiques de cette époque. Et recueillir une part de réalisme induirait d’améliorer sensiblement la bande passante originale. Parmi les méthodes actuelles d’apprentissage profond, les réseaux adverses génératifs (GAN) se démarquent. Ils peuvent générer de nouvelles données en analysant les modèles existants, redéfinir ainsi une image, en créant de nouveaux pixels à partir des pixels voisins. Il serait alors stimulant d’observer dans quelle mesure ce réseau est capable de créer de nouveaux harmoniques aux sources d’un enregistrement ancien. L’apprentissage profond peut-il donc créer l’illusion sonore ? Pour Yann Le Cun (2019), l’un des inventeurs de l’apprentissage profond, le réseau GAN est « l’idée la plus intéressante des 10 dernières années en matière d’apprentissage automatique ».
Conclusion
En constatant que les enregistrements de blues, R&B, soul des années 1950-60 ne sont plus aussi largement écoutés qu’autrefois, notre étude vise à évaluer le sens musical, culturel et historique de les remixer aujourd’hui en son immersif, et à savoir si cette pratique répond en effet à une envie des consommateurs actuels vis-à-vis de ces enregistrements. Finalement, elle démontre l’intérêt musical, culturel et aussi historique de cette pratique, qui ne répond certes pas à une envie particulière des consommateurs, n’ayant pas eu connaissance de son existence, mais qui suscite en eux un vif intérêt au regard de la musique.
Pour y parvenir, nous avons lié deux expériences. La première visait à observer les comportements de réflexion, d’écoute et de remixage de 24 ingénieurs du son, musiciens et experts du répertoire ciblé, face à trois masters originaux des années 1950-60. Sur deux morceaux, les résultats ont montré que leur version remixée présentait en moyenne un rendu sonore plus favorable à la musique que la version originale. À l’aide d’un outil de séparation de sources détectant les harmoniques, nous avons alors réalisé un remixage en son immersif l’une de ces deux chansons, que nous avons présenté dans une seconde expérience. Un premier test d’écoute comparative avec le master original visait à mesurer l’intérêt musical et culturel de présenter notre remixage au grand public. Huit professionnels de l’industrie phonographique ont jugé notre version respectueuse de l’œuvre originale, et le nouvel espace sonore éclairant musicalement. Presque tous ces experts du label ou du mixage immersif ont affirmé qu’ils la commercialiseraient s’ils dirigeaient un label. Un second test comparatif demandait à 45 consommateurs de musique leur préférence d’écoute entre les deux versions. La majorité, qui a préféré écouter notre remixage, a été ravie d’entendre tout ce que cette chanson contenait. Comme les professionnels, ils ont vu le grand intérêt musical du remixage immersif : valoriser l’arrangement qui a été pensé pour une œuvre en donnant une place nouvelle à tous les instruments. Un intérêt culturel ressort également, puisque les consommateurs ont été très nombreux à exprimer l’envie d’écouter cette chanson plus souvent en son immersif qu’en mono, et de découvrir ainsi le reste du catalogue du label. L’atout historique de cette pratique réside enfin dans l’illusion de certains d’avoir été projetés devant les musiciens de l’enregistrement. Remixer en son immersif des masters monophoniques peut donc établir pendant trois minutes une passerelle entre deux époques lointaines. Tous nos objectifs de recherche ont été atteints, bien que, si nous l’avions découvert plus tôt, nous aurions pu utiliser dès l’expérience n°1 l’outil RipX, avec lequel nous avons séparé les sources de cette chanson. Toutefois, cela n’a pas faussé nos résultats. Toujours guidé par un sens musical, ce procédé peut être étendu à d’autres catalogues d’enregistrements et bientôt des effectifs plus denses, grâce aux progrès constants des systèmes de séparation de sources par apprentissage profond.
Bibliographie
Apple. Audio Spatial, 2023. https://music.apple.com/us/curator/apple-music-audio- spatial/1564180390?l=fr-FR
Ausseil, D., Contamine, C.-H., & Chapoullié, D., La Route du blues. Éditions d’Art J. P. Barthélémy, 1995.
Barry, E. D., High-fidelity sound as spectacle and sublime, 1950–1961. Dans Sound in the Age of Mechanical Reproduction, pp.115-138, 2010. DOI: 10.9783/9780812206869.115
Bas-Rabérin, P., Le blues moderne, 1945-1973. Paris: Albin Michel, 1973.
Bode, H., History of electronic sound modification. Dans Journal of the Audio Engineering Society, 32(10), pp.730-739, 1984.
Bowman, R., Soulsville, U.S.A.: The Story of Stax Records. New York: Schirmer Books, 1997. Cabanillas, R., Mixing Music In Dolby Atmos [Capstone Projects and Master’s Theses].
California State University, Monterey Bay (Fresno, États-Unis), 2020.
Chalot, C., & Guittet, H., NomadPlay : FAQ, 2017. https://www.nomadplay.app/fr/faq Clavel, C., Séparation des sons musicaux. Approche bayésienne et méthode de Monte-Carlo [Stage DEA ATIAM]. Télécom Paris (Paris-Saclay, France), 2003.
Cogan, J., & Clark, W., Temples of sound : Inside the great recording studios. San Francisco: Chronicle Books, 2003.
Cruse, R., Les « Pet Sounds » séminaux des Beach Boys arrivent dans le mix Dolby Atmos de Giles Martin. Dans Maison Du Jeu !, 2023.
Dolby, Webinar 1/3 : Introduction Dolby Atmos [Vidéo], 2020. https://www.youtube.com/watch?v=naTJwllCmCw
Dolby, Webinar 3/3 : Mixage Dolby Atmos [Vidéo], 2021. https://www.youtube.com/watch?v=rGCngKQOxpw
Dobrev, L., SpectraLayers 7: More AI, less clicks for Steinberg’s spectral editor. Dans Gearnews, 2020.
Erard, N., La spatialisation dans le spectacle vivant : Quelles différences entre la chaîne audio de sonorisation d’un spectacle traditionnel et d’un spectacle spatialisé ? [Mémoire FSMS]. CNSMDP (Paris, France), 2020.
Ewert, S., & Müller, M., Using score-informed constraints for NMF-based source separation. Présenté à la IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) à Kyoto, Japon, 2012. DOI: 10.1109/ICASSP.2012.6287834
Facciotto N., Troiani E., Martinez M. J., Source Identification and Classification of Acoustic Emission Signals by a SHAZAM Inspired Pattern Recognition Algorithm. Présenté l’International Workshop on Structural Health Monitoring (IWSHM) à Palo Alto, États-Unis, 2017. DOI: 10.12783/shm2017/13989.
Garofalo, R., Crossing Over : From Black Rhythm & Blues to White Rock’n’Roll. Dans Rhythm and Business: The Political Economy of Black Music, Kelley, N., New York: Akashit Books, pp.112-137, 2002.
Gilotaux, P., La fabrication des disques. Dans Groupe d’Acoustique Musicale (28), 1967. Glaser B. G., & Strauss A. L., The Discovery of Grounded Theory: Strategies for Qualitative Research. Piscataway: Aldine Transaction, 1967.
Gordon, R., Respect Yourself: Stax Records and the Soul Explosion. Bloomsbury Publishing USA, 2013.
Goto, M., RWC Music Database, 2002. https://staff.aist.go.jp/m.goto/RWC-MDB/ Gover, M., Score-Informed Source Separation for Choral Music [Master Thesis]. McGill University (Montréal, Canada), 2019.
Guralnick, P., Sweet Soul Music: Rhythm & Blues et rêve sudiste de liberté. Paris: Editions Allia, 2003.
Hennequin, R., Khlif, A., Voituret, F., & Moussallam, M., Spleeter: A fast and efficient music source separation tool with pre-trained models. Dans Journal of Open Source Software, 5(50), 2020.
Hennequin, R. & al., Spleeter by deezer, 2021. https://github.com/deezer/spleeter Hit’n’Mix, History of Audio Separation 2001 to Now, 2021. https://hitnmix.com/2023/07/17/history-of-audio-separation/
Hofstein, F., Le rhythm and blues (coll. Que sais-je ?), Paris: Presses universitaires de France, 1991.
I’MTech, Gaël Richard, chercheur du son. Dans I’M Tech, 2020.
International Federation of the Phonographic Industry (IFPI). Engaging with Music, 2022. Jolibert, B., Le blues et sa musique. Dans Expressions (20), pp.171 187, 2002.
Kagan, A., How To Listen to Immersive Audio. Dans Sonarworks Blog, 2022.
Kimizuka, M., Historical Development of Ma0gnetic Recording and Tape Recorder. Dans
Survey reports on the systemization of technologies, vol.17, pp.185-273, 2012.
Lambert, P., Brian Wilson’s Pet Sounds. Dans Twentieth-Century music, vol.5(1), pp.109-133, 2008. DOI: 10.1017/S1478572208000625
Le Cun, Y., L’apprentissage profond, une révolution en intelligence artificielle. Dans La lettre du Collège de France, (41), p.13, 2016.
Le Cun, Y., Quand la machine apprend : La révolution des neurones artificiels et de l’apprentissage profond. Paris: Odile Jacob, 2019.
Lemesle, P., Il était une fois… La T.S.F. : Les Années 60…, 2015. https://radio- passion.pagesperso-orange.fr/annees60/frameannees60.htm
Licata Caruso, D., Les insolentes ventes d’écouteurs sans-fil portées par les AirPods d’Apple. Dans Le Parisien, 2022.
Liutkus, A., Durrieu, J.-L., Daudet, L., & Richard, G., An overview of informed audio source separation. Présenté au 2013 14th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS) à Paris, France, 2013. DOI: 10.1109/WIAMIS.2013.6616139 Mercier D. & al., Le livre des techniques du son (4e ed.). Paris: Dunod, 2010.
Miron, M., Carabias-Orti, J. J., Bosch, J. J., Gómez, E., & Janer, J., Score-informed source separation for multichannel orchestral recordings. Dans Journal of Electrical and Computer Engineering, (11), p.1-19, 2016. DOI: 10.1155/2016/8363507
Müller, M., Fundamentals of Music Processing : Using Python and Jupyter Notebooks (2nd ed.). Cham: Springer, 2021.
Mulligan, M., Music subscriber market shares Q2 2021. Dans MIDiA Research, 2022. https://www.midiaresearch.com/blog/music-subscriber-market-shares-q2-2021 Mulligan, M., Music subscriber market shares 2022. Dans MIDiA Research, 2022. https://www.midiaresearch.com/blog/music-subscriber-market-shares-2022
Pirenne, C., Vocabulaire des musiques afro-américaines. Paris: Minerve, 1994.
Poole, A., The strange career of Jim Crow archives: Race, space, and history in the mid- twentieth-century American south. Dans The American Archivist, vol.77(1), pp.23-63, 2014. Rastogi, H., Apple First to Capture 8 Spots in List for Global Top 10 Smartphones. Dans Counterpoint Research, 2023.
Rémond, A., L’enregistrement magnétique : Vers la bande magnétique et le magnétophone. Dans Radiofil Magazine, (69), pp. 16-25, 2015.
Richard, G., Sundaram, S., & Narayanan, S., An overview on perceptually motivated audio indexing and classification. Dans Proceedings of the IEEE, vol.101(9), pp.1939-1954, 2013. Ripani, R. J., The New Blue Music : Changes in Rhythm & Blues, 1950-1999. Jackson: University Press of Mississippi, 2006.
Rumsey, F., & McCormick, T., Son & enregistrement. Paris: Eyrolles, 2002.
Schulze-Forster, K., Informed audio source separation with deep learning in limited data settings [PhD Thesis]. Institut polytechnique de Paris (Palaiseau, France), 2021.
Simon, G., Vers une salle d’écoute dédiée à la musique spatialisée [Mémoire FSMS]. CNSMDP (Paris, France), 2018.
Singleton, M., Apple Music’s Spatial Audio Strategy Is Paying Off With More Listeners, Major Releases. Dans Billboard, 2022.
Spotify. Qualité Audio, 2023. https://support.spotify.com/fr/article/audio-quality/
Stotzer, S., VisualAudio : Caractéristiques matérielles des disques phonographiques. Dans
Département d’informatique, Université de Fribourg, 2003.
Tamarkin, J., ‘Pet Sounds’ in Dolby Atmos: Respect the feelings. Dans Tidal Magazine, 2023. The Beach Boys, Giles Martin introduces The Beach Boys’ ‘Pet Sounds’ in Atmos [Vidéo]. https://www.youtube.com/watch?v=2drX6yEhktg
Thornton, M., Dolby Atmos – Remastering Music – An Introduction [Vidéo], 2020. https://www.production-expert.com/home-page/2020/1/6/remastering-music-in-immersive- audio
Woods, C., Development Arrested: The Blues and Plantation Power in the Mississippi Delta. New York: Verso Books, 2017.
Annexes
Annexe B1 : Expérience n°1 – Informations relatives aux enregistrements sélectionnés
- Wonder What is Wrong with Me – Lightnin’ Hopkins (1956), du répertoire blues

Compositeur, parolier : Lightnin’ Hopkins
Enregistrée en avril 1954 aux studios ACA à Houston, Texas
Sortie chez Ace Records sous ce titre, puis chez Herald Records sous le titre
Lightnin’ Don’t Feel Well
Disques :[45T] Wonder What is Wrong with Me / Bad Boogie, Ace Records [Ace 516], mai 1956 [45T] Lightnin’ Don’t Feel Well / My Little Kewpie Doll, Herald Records [H-520], mai 1958
Labels : Ace Records / Herald Records ISWC : ACA 45-3313
Lightnin’ Hopkins – voix, guitare Donald Cooks – basse
Ben Turner – batterie
- Oh, Marie – Louis Prima (1959), du répertoire jazz/R&B

Compositeurs : Eduardo di Capua, Alfred Mazzucchi Parolier : Vincenzo Russo, Louis Prima
Enregistrée aux studios Capitol à Los Angeles, Californie, pour le film Hey Boy! Hey Girl! de David Lowell Rich, sorti le 5 août 1959
Album : [33T] Music from the Soundtrack of the Columbia Picture “Hey Boy! Hey Girl!” [T- 1160]
Label : Capitol Records Producteur : Voyle Gilmore ISWC : T-902.878.576-4
Louis Prima – voix, trompette
with Sam Butera & The Witnesses:
Sam Butera – saxophone ténor, chœurs Lou Sino – trombone, chœurs
Robert J. Carter – piano
Bob Roberts – guitare, chœurs
Antony Liuzza – basse, chœurs Paul Ferrara – batterie
- B-A-B-Y – Carla Thomas (1966), du répertoire soul

Compositeur : Isaac Hayes Parolier : David Porter
Arrangeurs : Booker T. Jones, Steve Cropper
Enregistrée les 18-19 juillet 1966 aux studios Stax à Memphis, Tennessee
Sortie en 45T [S-195] le 27 juillet 1966, puis en 33T dans l’album Carla [S-709] en octobre 1966 Label de production : Stax Records
Label de distribution : Atlantic Records Ingénieur du son : Tom Dowd Producteur : Jim Stewart
ISWC : T-070.232.055-5
Classement : N°3 R&B / N°14 pop
Carla Thomas – voix, chœurs with Booker T. & the MG’s :
Booker T. Jones – orgue Hammond Steve Cropper – guitare
Donald “Duck” Dunn – basse Al Jackson Jr. – batterie
and The Memphis Horns : Wayne Jackson – trompette
Andrew Love – saxophone ténor Floyd Newman – saxophone baryton
- Just Call Me Lonesome – Jim Reeves (1959), du repertoire country [test de remixage]

Compositeur et parolier : Rex Griffin
Enregistrée le 19 décembre 1958 aux studios RCA Victor à Nashville, Tennessee
Sortie en septembre 1959 dans l’album Songs to Warm the Heart [LSP-2001] Label : RCA Victor
Ingénieur du son : Bob Farris Producteur : Chet Atkins
Jim Reeves – voix, guitare Chet Atkins – guitare Floyd Cramer – piano Bob Moore – basse Buddy Harman – batterie
Annexe B2 : Expérience n°1 – Questions de l’entretien préliminaire semi-dirigé
QA1 : Comment définiriez-vous l’« esthétique sonore » d’un enregistrement musical ? Que vous évoque ce terme ?
QA2 : En général, comment considérez-vous la relation entre une œuvre musicale et l’esthétique sonore choisie pour son enregistrement ?
- Comment considérez-vous la relation entre l’esthétique sonore choisie et notre perception postérieure de l’œuvre enregistrée ?
- Selon vous, à quoi ressemblerait l’esthétique sonore qui serait dans une « relation idéale » avec l’œuvre musicale qu’elle doit embrasser ? Vous pouvez brièvement illustrer vos propos par un exemple d’artiste ou d’enregistrement dans lequel vous pensez que cette relation est idéale, et un autre dans lequel vous pensez qu’elle ne l’est pas.
Plaçons-nous dès à présent dans le contexte des musiques écrites et enregistrées dans les années 195067 (Ray Charles, Ella Fitzgerald, Miles Davis, Art Blakey, Muddy Waters, Elvis Presley, Little Richard, Johnny Cash, The Chordettes, Edith Piaf, Georges Brassens…).
QA3 : Comment pensez-vous cette même relation ?
- Conceptuellement, l’œuvre musicale et l’esthétique sonore qui a été choisie pour son enregistrement sont-ils selon vous deux éléments aujourd’hui dissociables ou indissociables ? Pouvez-vous illustrer vos propos par un exemple d’artiste ou d’enregistrement qui vous est familier ?
Si cela n’est déjà fait, pensez à un enregistrement de musiques dites « actuelles » que vous connaissez des années 1950, pour lequel le rendu sonore, voire l’esthétique sonore dans son ensemble, dessert selon vous la musique qui a été pensée et composée.
Imaginez qu’il en soit possible de modifier le rendu sonore dans le but d’optimiser la relation œuvre/esthétique.
QA4 : Quel regard porteriez-vous sur cette pratique ?
- Cela impliquerait-il de toucher à l’œuvre musicale elle-même selon vous ? Si oui, qu’en pensez-vous ?
QA5 : Si vous aviez la possibilité d’en modifier certains aspects sonores, le feriez-vous ?
→ Oui : dans quel(s) but(s) ? Travailleriez-vous avec l’idée d’une certaine fidélité vis- à-vis de l’œuvre musicale originale, vis-à-vis de l’esthétique sonore originale, ou bien en toute indépendance ? Pensez-vous à un aspect sonore en particulier ?
→ Non : pourquoi ?
Annexe B3 : Expérience n°1 – Questionnaire d’écoute du master original
QB1 : Qu’entendez-vous dans cette musique ? Qu’est-ce qui y est important pour vous ? Que vous inspire-t-elle ? Quelle image, quel sentiment vous vient en l’écoutant ? Vous pouvez par exemple évoquer le genre, le style, les instruments, le tempo, les nuances, le caractère… et toute considération personnelle.
QB2 : Comment évaluez-vous le rendu sonore de ce master original, au regard du morceau et de ses caractéristiques musicales précédemment évoquées ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QB3 : Comment évaluez-vous le rendu de l’équilibre entre les différentes sources sonores, au regard du morceau et de ses caractéristiques musicales ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QB4 : Comment évaluez-vous le rendu du timbre des différentes sources sonores, au regard du morceau et de ses caractéristiques musicales ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QB5 : Comment évaluez-vous le rendu de l’espace des différentes sources sonores, au regard du morceau et de ses caractéristiques musicales ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QB6 : Finalement, si à vos yeux la relation œuvre/esthétique sonore n’est ici pas idéale, et si vous en aviez la possibilité, quelles modifications sonores prioritaires apporteriez-vous pour que ce morceau connaisse selon vous son rendu sonore idéal ? N’hésitez pas si possible à en préciser le but.
Annexe B4 : Expérience n°1 – Enoncé de la séance de remixage en son spatialisé
Selon votre convenance, vous allez avoir la possibilité de modifier certains aspects sonores de ces trois enregistrements précédemment entendus.
Les sources de chaque enregistrement ont alors été préalablement séparées par un dispositif technique spécifique, afin de vous permettre d’agir individuellement sur chacune d’elles pour cette séance personnelle de remixage.
- Phase d’entraînement
Tout d’abord, vous disposez d’un temps illimité pour prendre connaissance des outils qui sont face à vous et qui vous permettront, si vous le souhaitez, d’effectuer selon votre convenance un remixage de ces trois extraits musicaux des années 1950-60. Porté sur un enregistrement-test de musique country, ce temps d’entraînement vous est réservé pour vous familiariser avec la présente interface, et en particulier avec l’action des 4 paramètres de mixage qui vous sont proposés pour chaque source sonore :
- Gain (= volume)
- Egalisation spectrale (= timbre)
- Localisation spatiale
- Niveau de réverbération
Chacun de ces paramètres influe sur un aspect sonore précis et facilement audible de la source envisagée. Pour entendre leur impact respectif distinctement, vous pouvez par exemple les poussez à leurs extrêmes.
Ne passez donc à la phase suivante que lorsque vous vous sentez bien à l’aise avec l’outil en main, et que vous avez bien entendu et intégré l’action de ces paramètres de mixage.
- Phase de réalisation : remixage des morceaux A, B et C
Une fois l’outil bien en main et le morceau A bien en tête, la phase de remixage commence.
Une règle se présente à vous : vous avez jusqu’à 12 manipulations pour remixer ce morceau selon vos envies. La manipulation d’un paramètre est comptabilisée à partir du moment où vous commencez à en manipuler un autre, et ainsi de suite. Donc par exemple : si vous modifiez le gain d’une source en plusieurs fois d’affilée, cela sera compté comme 1 manipulation. En revanche, si après cela vous décidez de modifier le niveau de réverbération pour cette même source et que vous recorrigez ensuite le gain, l’ensemble sera compté comme 3 manipulations (gain – réverbération – gain). Le seul contre-exemple est le suivant : toucher successivement aux différents potentiomètres d’égalisation d’une même source ne comptera que comme 1 manipulation.
Important : si tel est votre choix, vous pouvez très bien signifier que vous avez terminé votre remixage sans même avoir atteint ce nombre de 12 modifications.
Vous pouvez à tout moment et librement déplacer la tête de lecture pour vous concentrer sur les sections du morceau qui vous intéressent.
Cette séance unique n’est pas un examen, mais une expérience : il n’y a donc ni bon, ni mauvais choix. Sentez-vous simplement vous-même, et surtout, faites-vous plaisir !
Annexe B5 : Expérience n°1 – Questionnaire d’autocritique de chaque nouveau master remixé par les participants
QD1 : Comment évaluez-vous le rendu sonore de ce nouveau master, que vous venez de produire, au regard du morceau et de ses caractéristiques préalablement évoquées ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Pouvez-vous brièvement expliquer votre notation et le but de vos manipulations de remixage ? Lesquelles sont particulièrement à vocation corrective ?
Lesquelles sont particulièrement à vocation esthétique ?
QD2 : Comment évaluez-vous le rendu de l’équilibre entre les différentes sources sonores, au regard du morceau et de ses caractéristiques ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QD3 : Comment évaluez-vous le rendu du timbre des différentes sources sonores, au regard du morceau et de ses caractéristiques ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QD4 : Comment évaluez-vous le rendu de l’espace des différentes sources sonores, au regard du morceau et de ses caractéristiques ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (Hors de propos) | (Idéal) |
Expliquez brièvement votre notation.
QD5 : Avez-vous été perturbé(e) par un quelconque élément durant :
- l’écoute du master original du morceau ? Précisez si possible.
- le remixage du morceau ? Précisez si possible.
- l’écoute de votre propre master ? Précisez si possible.
- un autre moment de l’expérience ? Précisez si possible.
QD6 : Le processus préalable de séparation de sources a pu restituer des signaux incomplets ou endommagés par divers artefacts. Vous ont-ils perturbé(e), limité(e) dans vos différents choix de remixage ? Illustrez vos propos le cas échéant.
QD7 : Avez-vous d’autres remarques que vous souhaitez formuler pour ce morceau ?
Annexe B6 : Expérience n°1 – Retours généraux
Légende : IS = Ingénieur du son / M = Musicien / P = Expert 1950-60
| Participant | Retour général de l’expérience n°1 |
| IS1 | Pas l’habitude de me poser ces questions, qui m’ont finalement animée. |
| IS2 | Expérience intéressante. C’est une pratique très utile et fructueuse pour modifier l’équilibre général et certains timbres. Mais la qualité des signaux limite fortement la possibilité d’élargir l’image sonore de ces masters. La génération d’harmoniques sur ces signaux pourrait ouvrir le champ des possibles sur l’aspect spatial. |
| IS3 | – |
| IS4 | – |
| IS5 | Expérience vraiment intéressante, très cool. Analyser et critiquer ce qu’on fait. Je me rends compte que ce n’est pas simple d’enregistrer des vieux enregistrements. Exercice ludique, c’est agréable. Seule frustration : 12 manipulations. Je me rends compte ici que le bouton « solo » ne sert à rien ici. L’interface de remixage est bien. |
| IS6 | Vos choix de morceaux sont bien, à la fois peu et beaucoup de sources. J’ai été très surpris sur les morceaux R&B (première fois que je vois une piste dégradée (piano) apporter au mix musicalement ET esthétiquement) et soul (amélioration très rapide du rendu sonore avec si peu de manipulations et de paramètres, très agréablement surprenant). J’ai été intéressé par cette expérience, qui me confirme que le bouton « solo » devrait été banni. On s’en fout comment une source sonne seule. Le bouton « mute », lui, est beaucoup plus musical, on doit le conserver, car c’était avec celui-ci qu’on se rend compte de l’apport de la source dans l’arrangement musical. |
| IS7 | Très sympa, on devrait faire ça plus souvent. Le fait de mixer change la perception par rapport à une phase d’écoute. |
| IS8 | C’était marrant ! |
| M1 | – |
| M2 | Très rigolo ! |
| M3 | – |
| M4 | – |
| M5 | Super ludique. Super intéressant. C’est un terrain sur lequel je vais peu avec la parole. Cette expérience me permet de revoir beaucoup de termes, d’être précis dans ce que je dis. L’outil de remixage est instinctif, ce qui permet de se concentrer sur l’essentiel et rend l’écoute plus fine et plus directe, ce qui est très important, c’est cool. |
| M6 | C’est fou de sentir qu’on peut isoler un instrument et l’entendre seul… La séparation de sources serait très utile pour retranscrire des partitions, « repiquer un solo ». J’en ai rêvé plein de fois dans ce but musical, pour savoir dans l’orchestre ce qui fait que ça groove autant, « chercher les fonds de sauce », pour pouvoir le réappliquer à l’identique dans un autre morceau, une composition personnelle. Il faudrait à la limite refaire les mêmes défauts à la prise, pour préparer ce processus de son. C’est un outil pédagogique fabuleux. Retoucher le son d’enregistrements passés m’intéresse, il est vrai… |
| M7 | C’était trop bien ! |
| M8 | Très riche expérience, qui permet d’analyser ses propres analyses. |
| P1 | J’attendais ce genre d’expérience depuis longtemps. Je m’attendais un petit peu à cela, j’étais un peu excité. Cela a tout à fait répondu à mes attentes. J’avais connaissance de la chose [la séparation de sources], mais je n’avais jamais pu remixer des œuvres de cette époque, que je connais bien. Je pourrais rester pendant longtemps devant la machine à remixer … |
| P2 | Expérience intéressante ! Je comprends la nécessité de limiter les outils pour le remixage. La séparation de sources ne permet pas encore de remixer en profondeur ou au moins selon nos envies… |
| P3 | Mon idée de ne pas toucher à la mono d’un master mono s’est confirmée à travers cette expérience. Cela doit rester mixé et écouté en mono, si l’on s’appuie sur le même objet d’origine (au contraire d’un réenregistrement). |
| P4 | Le son, cela me passionne. Cette salle est un laboratoire, c’est super. Voir qu’on peut améliorer le rendu sonore, cela m’intéresse beaucoup, même sur des enregistrements plus récents. |
| P5 | Très intéressant. Avec ces exemples, je me rends compte que c’est intéressant d’avoir ces outils pour remixer. La technologie de séparation est impressionnante, cela pose des questions sonores et éthiques qu’on ne se posait pas avant, parce que ce n’était tout simplement techniquement pas possible. |
| P6 | Vous atteignez toutes mes capacités à travers vos questions après l’écoute des masters originaux : vos questions sont très bonnes, c’est très intéressant. Heureusement que je n’ai pas cet outil à la maison, je ne dormirais plus ! Je serais plus addict à cela qu’aux jeux vidéo, on joue à l’apprenti sorcier ! (rires) |
| P7 | Cela peut être un très bon outil pour la pédagogie d’oreille, pour les personnes qui apprennent la musique. Super intéressant. |
| P8 | Super intéressant. Cela donne envie de bidouiller pour voir comment on peut changer ces rendus. J’ai toujours tendance à penser qu’il manque quelque chose en mono, un manque de relief, d’espace. Cela est lié à mes pratiques d’écoute car j’écoute beaucoup au casque. L’audio immersif m’a déjà fasciné dans quelques expériences passées, j’ai voulu appliquer cela ici à ma manière. |
Annexe C1 : Expérience n°2 – Tableau récapitulatif de l’amélioration progressive de la qualité des signaux isolés de la chanson B-A-B-Y de Carla Thomas
| Stem/Source | SpectraLayers brut | SpectraLayers retouché | RipX brut | RipX retouché |
| Global | Souffle conservé | – | Souffle retiré | – |
| Aucune perte de signal | – | Perte d’harmoniques aigues (cymbales/piano/chœurs) | – | |
| Spectre entièrement conservé | – | Coupure des fréquences >20 kHz | – | |
| Voix | Cohabitation avec orgue/cuivres | Peu d’interférences orgue | Cohabitation avec orgue | Faibles interférences orgue |
| Interférences batterie | Interférences batterie/piano/guitare/cuivres | Aucune interférence | – | |
| Présence de souffle | – | Aucun souffle | – | |
| Réverbération perçue | – | Peu de réverb perçue | – | |
| Cuivres | [Stem « Autres »] Cohabitation avec piano/orgue/guitare / Interférences basse | Pas de cohabitation | [Stem « Strings »] Cohabitation avec orgue/guitare | Pas de cohabitation |
| Interférences guitare/batterie | – | Faibles interférences guitare | ||
| Spectre légèrement plus complet que RipX | Spectre rarement plus complet que SpectraLayers | Spectre moins complet que SL retouché / Spectre incomplet à 2’20 car mélange accord guitare | ||
| Orgue | [Stem « Autres »] Cohabitation avec cuivres/piano/guitare / Interférences basse | Pas de cohabitation | [Stem « Strings »] Cohabitation avec cuivres/guitare | Pas de cohabitation |
| Peu de transitoires | Transitoires un peu plus nombreuses | |||
| Piano | Quasiment aucun signal, fréquences parasites | Piano sans main gauche, donc étriqué vers l’aigu | Piano complet, récupération de la main gauche | – |
| Instabilité de la réponse du signal isolé (alors qu’ostinato) | Stabilité de la réponse du signal | – | ||
| Transitoires manquantes en tutti | Transitoires récupérées en tutti | – |
| Artefacts | Très peu d’artefacts | – | ||
| Interférences basse/batterie/voix | Aucune interférence | Faibles interférences cuivres | ||
| Récupération du souffle en intro | Aucun souffle repris | – | ||
| Guitare | [Stem « Autres »] Cohabitation avec cuivres/piano/orgue / Interférences basse | Aucune cohabitation | Cohabitation avec cuivres | Pas de cohabitation |
| Interférences voix | Interférences piano/orgue/basse | Faibles interférences cuivres | ||
| Spectre incomplet (bas, harmoniques) / Instrument parfois méconnaissable | Spectre complet | Spectre plus dense que SpectraLayers retouché (bas, harmoniques) / Instrument net | ||
| Basse | Enveloppe floue (pas d’attaque, pas de release) | Enveloppe floue (pas d’attaque, pas de release) / Aucune perception du jeu du bassiste | Enveloppe beaucoup plus définie (perception attaque/release) / Perception du jeu et du groove du bassiste | – |
| Interférences cuivres/orgue/piano/ guitare/kick | Interférences minimes kick | Interférence orgue | Aucune interférence | |
| Irrégularité harmonique du signal | Régularité harmonique du signal | – | ||
| Batterie | Stem Percussions unique | Stem Percussions unique | Stem Kick (interférences snare) Stem Drums Stem Percussions | Stem Kick (aucune interférence) Stem Drums (« Drums » + « Percussions ») |
| Interférences voix/cuivres/orgue/ guitare | Interférences harmoniques voix/guitare | Interférences orgue/guitare | Brèves interférences guitare (sur les coups de snare) | |
| Coups de kick inégaux en niveau | Coup de kick égaux en niveau | – | ||
| Irrégularité harmonique du signal (snare) | Régularité harmonique du signal (snare) | – |
Annexe C2 : Expérience n°2 – Questionnaire du test d’écoute pour « producteurs » Bienvenue à ce test d’écoute comparative ! Pour vous connaître un peu mieux…
QE1 : Vous participez en tant que…
□ Ingénieur(e) du son □ Réalisateur(rice) artistique □ Producteur(rice) musical(e) QE2 : Quel âge avez-vous ?
QE3 : Connaissez-vous le label Stax Records ?
□ Oui □ Non
QE4 : Connaissez-vous le « son Stax », aussi appelé « Memphis Sound », caractéristique du label Stax Records ?
□ Oui □ Non
QE5 : Connaissez-vous le format audio Dolby Atmos ?
□ Oui □ Non
QE6 : Pratiquez-vous le mixage en son immersif ?
□ Oui □ Non
Ecoute du master original de B-A-B-Y
QF1 : Après cette écoute, comment évaluez-vous le rendu sonore global du master original B-A- B-Y, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QF2 : Comment évaluez-vous le rendu de l’équilibre entre les différentes sources, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QF3 : Comment évaluez-vous le rendu du timbre des différentes sources, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QF4 : Comment évaluez-vous le rendu de l’espace des différentes sources, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QF5 : Pouvez-vous expliquer en quelques mots vos notations et vos impressions du rendu sonore du master original de la chanson B-A-B-Y, au regard de ce que suggère selon vous la musique ?
QF6 : Avez-vous été perturbé(e) par un ou des éléments sonores extérieurs durant l’écoute du master original ?
Ecoute du master remixé en son immersif de B-A-B-Y
QG0 : Quelles sont vos toutes premières pensées générales au sortir de cette seconde écoute ? (Facultatif)
QG1 : Comment évaluez-vous le rendu sonore global du master remixé de B-A-B-Y, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QG2 : Comment évaluez-vous le rendu de l’équilibre entre les différentes sources dans le master remixé, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QG3 : Comment évaluez-vous le rendu du timbre des différentes sources dans le master remixé, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QG4 : Comment évaluez-vous le rendu de l’espace des différentes sources dans le master remixé, au regard des caractéristiques musicales et stylistiques de la chanson ?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Hors de propos | Idéal |
QG5 : Pouvez-vous expliquer en quelques mots vos notations et vos impressions du rendu sonore du master remixé de la chanson B-A-B-Y, au regard de ce que suggère selon vous la musique ?
QG6 : Avez-vous été perturbé(e) par un ou des éléments sonores extérieurs durant l’écoute du master remixé ?
Comparons les deux masters…
QH1 : Selon vous, l’âme (soul) de la chanson est…
□ mieux retranscrite dans le master original □ mieux retranscrite dans le master remixé
□ également retranscrite dans les deux masters □ Je ne sais pas
QH2 : Lequel des deux masters entendus vous fait le plus ressentir le groove de la chanson ?
□ Le master original □ Le master remixé □ Les deux à égalité □ Je ne sais pas
QH3 : Selon vous, lequel des deux masters entendus met le mieux en valeur l’arrangement de la chanson ?
□ Le master original □ Le master remixé □ Les deux à égalité □ Je ne sais pas
Conclusion
QI1 : Toute considération matérielle exclue, pensez-vous que le master remixé en son immersif donnerait envie au grand public d’écouter la chanson B-A-B-Y plus souvent qu’avec la version originale ?
□ Oui □ Non □ Je ne sais pas
QI2 : Toute considération matérielle exclue, pensez-vous que le master remixé en son immersif donnerait envie au grand public d’écouter dans les mêmes conditions sonores le reste du catalogue du label Stax ?
□ Oui □ Non □ Je ne sais pas
QI3 : Pouvez-vous justifier ces deux dernières réponses ?
QI4 : Si vous étiez le producteur de Stax ou d’un autre label, engageriez-vous les démarches pour commercialiser ce master remixé en son immersif de la chanson B-A-B-Y ?
□ Oui □ Non □ Je ne sais pas
QI5 : Pouvez-vous justifier votre réponse ?
QI6 : Merci de votre participation à ce test d’écoute ! Souhaitez-vous ajouter quelque chose ?
Annexe C3 : Expérience n°2 – Commentaires des « producteurs » sur le rendu sonore du master original et celui de notre master remixé en son immersif de la chanson B-A-B-Y
Légende : IS = Ingénieur du son / RA = Réalisateur artistique / PM = producteur musical
- Spécialiste de Stax Records / * Spécialiste du mixage en son immersif
| Participant | Commentaire du master original | Commentaire du master remixé |
| IS1 | Les timbres m’ont dérangé à cause de leur hétérogénéité : certains très durs (voix, cuivres) d’autres très mous, effacés (piano, drums). Les espaces sont très différents entre les sources (piano et drums lointains). Le propos musical passe mal à | Wow ! Assez impressionnant. Le groove passe très bien, les sources sont équilibrées. Les timbres sont plus agréables mais ils restent souvent pauvres et parfois agressifs. La saturation de la voix est moins gênante mais continue de me sortir de la musique |
| cause des « défauts » de mix, de prises et de support. Si le morceau reste agréable, c’est grâce à l’ancrage historique de cette musique et de ce son. La saturation et le souffle m’ont aussi parfois sorti de la musique. | parfois. Le placement dans l’espace « stéréo » complimente le groove. La réverbération est subtile, naturelle et agréable. Au tout début du morceau on entend des artefacts sur la basse mais rapidement ils disparaissent et on est dans la musique. Solo de cuivres à droite trop fort et snare au même moment trop fort aussi. Le mix devient assez déséquilibré et l’énergie trop à droite. | |
| IS2* | Compte tenu du format, la balance des sources est super, on entend tout bien, malgré une voix très devant et peut-être un peu trop dynamique, le propos musical est là pour moi. Parfois, la voix est un peu rêche et certains éléments se perdent mais ça ne change pas la musique pour moi. | Le rendu sonore a gagné en précision, le son est plus clair. Le piano semble plus beau, c’est mieux pour le coup. Mais je trouve que la dissociation basse / batterie fait perdre du groove, et la batterie placée à droite fait perdre le fil car trop agressive. Ce qui est super, c’est l’air gagné et le respect de la musique dont fait preuve le mixage en format immersif. Mais il est sobre, il aurait peut-être fallu prendre plus de parti sur la spatialisation de certaines choses. |
| IS3* | Enregistrement conforme à ce que l’on peut attendre de Stax. Les défauts que l’on pourrait noter après une écoute analytique font partie de la signature sonore du label, c’est donc tout à fait conforme. | Avec cette musique et cette interprétation, on est en attente de quelque chose de bien précis, et là, il nous est proposé autre chose. Cela peut être perturbant car on n’est plus dans le « contrat d’écoute » initial. Cela donne par contre un nouvel éclairage pour cette musique. C’est presque autre chose. Mieux ou moins bien, ce n’est à mon sens pas la question. On peut considérer qu’écouter ces musiques sous ce nouvel angle apporte réellement quelque chose d’intéressant au même titre qu’il est intéressant d’écouter des versions plus ou moins datées d’œuvres de musique classique. Impression d’un rendu moins dynamique (peut-être moins de groove ?) que la version mono. Plus équilibré spectralement. Donne plus à entendre l’arrangement. On en entend bien tous les détails. |
| IS4* | J’aime le master original au regard de la façon dont la musique était censée sonner à cette époque avec leur type de support (l’esthétique sonore fait corps avec la technologie utilisée). Dans une approche d’écoute réaliste en concert, les timbres et l’espace sont en deçà des performances que peuvent donner ce genre d’instruments joués en groupe. | De l’espace et de l’air. Super boulot, ça sonne. Bravo pour la séparation des sources, on n’entend aucun artefact. L’esthétique de production est conservée (avec ses défauts sur les timbres mais ça fait partie du truc) mais avec l’espace frontal en plus. Il n’y a pas de démasquage spatial car il n’y avait pas de masquage avant, même en mono (merci à l’arrangement et au démasquage fréquentiel déjà réalisé sur le mix original). C’est juste plus agréable et ça reste stable avec les déplacements (mais la mono était stable aussi ;-). L’immersion est quasi absente dans le sens où il n’y a pas (ou très peu) de sensation de pièce ajoutée par les surrounds. C’est donc pour moi un master surtout frontal immersif avec quasiment pas d’immersif (ou en tout cas pas assez perceptible). |
| IS5 | Cet enregistrement me donne l’impression que beaucoup d’éléments de cet enregistrement ont été contraints par la technique. À mon sens les enregistrements d’Isaac Hayes pour Stax sont autrement beaucoup plus qualitatifs (certes ils sont plus récents) et représentatifs du son Stax. Il n’en reste pas moins que ce style de musique est ancré dans une époque et donc tous les « défauts » ou imperfections techniques des enregistrements de cette époque sont intrinsèquement liés à la musique. | Tout est mieux pour moi sauf une chose. Plus de place à la voix, c’est bien. Meilleur équilibre entre les différents éléments de l’orchestration. La ligne de basse est mieux définie, moins bourrue, et plus constante tout au long du morceau. L’espace aussi est plus agréable, on a moins le sentiment que tout le monde est ou veut être au premier plan. Le côté négatif : la batterie à droite est une étrangeté pour moi, car cela place l’enregistrement de la chanson à un autre moment de l’histoire de la musique enregistrée (une certaine époque où ingénieurs du son et producteurs expérimentaient la stéréo). Est-ce que la version remixée a toujours le son Stax ? Musicalement oui, mais d’un point de vue historico- culturel, je me pose la question. |
| RA1 | Avec de la stéréo sur certains éléments, on profiterait mieux de l’arrangement. Le son est splendide mais manque d’aigus sur certaines sources (orgue, cymbales). | Impressionnant. C’est très beau. Je suis moins dans l’écoute de la voix principale que dans la version originale. En revanche j’ai une meilleure impression de rendu de la dynamique du groupe, des espaces. Je perçois mieux les arrangements. J’ai plus |
| l’impression d’une captation live où j’identifie le placement des instruments. Je trouve cependant l’ensemble un peu trop large (orgue trop à gauche, piano trop loin de basse/batterie, qui ne fait plus bloc avec eux comme dans la version originale). On a les mêmes « marqueurs » esthétiques (rimshot de snare très fort, peu de réverb, équilibres de l’orchestre, timbre vintage saturé). Les timbres me semblent plus beaux. Version très chic donc pour moi. | ||
| RA2* | Excellent rendu de la spatialisation grâce au mix. On retrouve l’atmosphère enfumée d’un club, dont un enregistrement tel que celui-ci est une tentative de reproduction. | Le master remixé à la fois améliore et respecte le morceau, je trouve cela très bien fait. C’est un « gadget » intelligemment utilisé, car il ne cherche pas à dénaturer l’original. Au contraire, j’y vois une grande fidélité. Je pense que l’autre avantage est de nettoyer la « vitre sale » qui était entre le master original et l’auditeur. Je pense que ce master nous permet de voir à quel point une écoute est subjective, et à quel point notre cerveau recrée entièrement l’espace dans la version originale. La spatialisation reçue ici se fait naturellement, la consommation est plus directe, il y a moins d’efforts à faire. Je trouve tout de même cela un peu trop frontal, j’aurais aimé avoir des éléments sur les côtés, avoir plus d’immersion. Je trouve aussi les cuivres un peu trop au centre, j’aurais aimé les entendre plus à droite. |
| PM1* | La basse est trop envahissante. Je suis habitué à la mono pour cette musique. La source du master est importante : numérisé ? disque ? Beaucoup de différences déjà entre rendu un 45T et un 33T. | Le changement est dément… Les instruments sont magnifiés. La batterie est beaucoup plus mise en avant (caisse claire claque trop parfois). La basse est plus agréable, elle n’envahit plus, elle est très présente sans écraser le son. Elle remplit enfin son rôle. Meilleure distinction des instruments. Mais le grand point gênant : la voix est trop en retrait. Cela est gênant par rapport à l’idée originale de l’enregistrement : enregistrer pour la chanteuse. Si ces enregistrements sont disponibles au grand public, il faut absolument renseigner qu’il ne s’agit pas du master original mais d’un master retravaillé. Ce master remixé me rappelle beaucoup ce qu’on pouvait obtenir à partir des égaliseurs Hi-Fi de l’époque, surtout au niveau des aigus très surélevés. |
Annexe C4 : Expérience n°2 – Avis des « producteurs » sur le potentiel culturel et commercial de notre master remixé en son immersif de la chanson B-A-B-Y
Légende : IS = Ingénieur du son / RA = Réalisateur artistique / PM = producteur musical
- Spécialiste de Stax Records / * Spécialiste du mixage en son immersif
| Participant | Avis sur le potentiel culturel du master remixé en son immersif de B-A-B-Y | Avis sur le potentiel commercial du master remixé en son immersif de B-A-B-Y |
| IS1 | Son global moins repoussant, moins daté. On est beaucoup plus facilement dans la musique et pas dans les défauts sonores. Musique soul toujours très populaire aujourd’hui. Catalogue Stax très bon (j’imagine). | Mode du multicanal grand public en ce moment (binaural, Apple). |
| IS2* | Je ne sais pas à quel point le grand public est sensible et est capable de dissocier le rendu entre la mono et ce remixage car il est très respectueux ce qui est super mais la spatialisation reste quand même assez discrète. À moins de les sensibiliser à ce genre de format pour qu’ils aient déjà un élément de comparaison et qu’ils comprennent le gain en termes d’espace et de dynamique. | Je ferais changer certaines choses mais c’est quand même intéressant de donner une nouvelle relecture et de le partager. |
| IS3* | Je ne sais pas répondre car le public pourrait être déstabilisé par le changement de « contrat d’écoute », mais en même temps pourrait être intéressé par ce nouvel éclairage de cette musique. Par contre, je pense que dans le cadre d’une écoute au casque, il y aurait sans doute un vrai avantage à avoir une version spatialisée de ces musiques uniquement disponibles en mono, qui me semblent plus gênantes à écouter au casque qu’aux enceintes. | Apporter un nouvel éclairage sur une musique me semble toujours intéressant. |
| IS4* | L’immersion n’est pas assez flagrante pour un public lambda. Tout juste entendrait-il l’élargissement de l’image. Un public mélomane et passionné de ce label serait enthousiaste avec ce remix, un public lambda pas sûr… | Le label Spatial Audio serait juste un argument commercial mais ça ne révolutionne pas ce genre de musique (qui sonnerait toujours avec ces timbres un peu fragiles, ce qu’un public lambda entend). |
| IS5 | Musicalement, les modifications sonores apportent un plus à la chanson. Mais encore une fois, je ne suis pas sûr que le grand public y soit très sensible (le mp3 128kb a malheureusement encore de beaux jours devant lui, je pense). | Marketing… |
| RA1 | – | L’éclairage apporté me semble très intéressant, j’imagine que la VO et cette version pourraient cohabiter. |
| RA2* | Je pense que le master remixé faciliterait l’accès de cette musique au grand public. S’ils peuvent découvrir cette musique ainsi, tant mieux ! | Si cela favorise l’accès à cette musique aux gens qui ne la connaissent pas, oui bien sûr ! Et on pourra toujours avoir accès au master original, donc quel est le problème ? J’aimerais bien que cette version remixée existe. Je pense que j’écouterais plus volontiers la version originale, mais cela m’amuserait d’accéder aux deux versions pour les comparer. |
| PM1* | Cela va attirer beaucoup de curieux, tant mieux ! | Cela permettrait d’éveiller la curiosité des gens, la connaissance de ce répertoire ! |
Annexe C5 : Expérience n°2 – Questionnaire du test d’écoute pour « consommateurs »
Bienvenue à ce test d’écoute comparative !
Pour vous connaître un peu mieux…
QJ1 : Quel âge avez-vous ?
QJ2 : Vous êtes…
□ un homme □ une femme
QJ3 : A quelle fréquence écoutez-vous de la musique soul/rhythm and blues ?
□ Jamais □ Rarement □ Occasionnellement □ Souvent □ Tout le temps
QJ4 : Connaissez-vous le label Stax Records ? En voici quelques artistes : Otis Redding, Sam & Dave, Rufus Thomas, Carla Thomas, Johnnie Taylor, The Staple Singers…
□ Oui □ Non
QJ5 : Connaissez-vous le « son Stax », aussi appelé « Memphis Sound », caractéristique du label Stax Records ?
□ Oui □ Non
Placez-vous sur la chaise haute…
[Ecoute des deux versions sonores A et B]
Après ces deux écoutes
QK1 : Quelles sont vos toutes premières pensées générales au sortir de ces deux écoutes ? (Facultative)
QK2 : Connaissez-vous cette chanson ? Il s’agit de B-A-B-Y, interprétée par Carla Thomas en 1966 pour le label Stax.
□ Oui □ Non
QK3 : Comment aimez-vous cette chanson telle que vous l’avez entendue dans la version A ?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Pas du tout | Follement |
QK4 : Comment aimez-vous cette chanson telle que vous l’avez entendue dans la version B ?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Pas du tout | Follement |
QK5 : A travers laquelle des deux versions sonores entendues préférez-vous écouter la chanson B- A-B-Y de Carla Thomas ?
□ La version A □ La version B □ Les deux à égalité, par choix
□ Les deux à égalité, par indifférence □ Je ne sais pas
QK6 : Selon vous, laquelle des deux versions sonores entendues retranscrit le mieux l’âme (soul) de la chanson ?
□ La version A □ La version B □ Les deux à égalité □ Je ne sais pas
QK7 : Laquelle des deux versions sonores entendues vous fait le plus ressentir le groove de la chanson ?
□ La version A □ La version B □ Les deux à égalité □ Je ne sais pas
QK8 : Selon vous, laquelle des deux versions sonores entendues met le mieux en valeur l’arrangement de la chanson ?
□ La version A □ La version B □ Les deux à égalité □ Je ne sais pas
QK9 : Appréciez-vous plus le rendu sonore de certains instruments dans la version A que dans la version B ? Si oui, lesquels ?
Pouvez-vous détailler vos réponses ?
QK10 : Appréciez-vous plus le rendu sonore de certains instruments dans la version B que dans la version A ? Si oui, lesquels ?
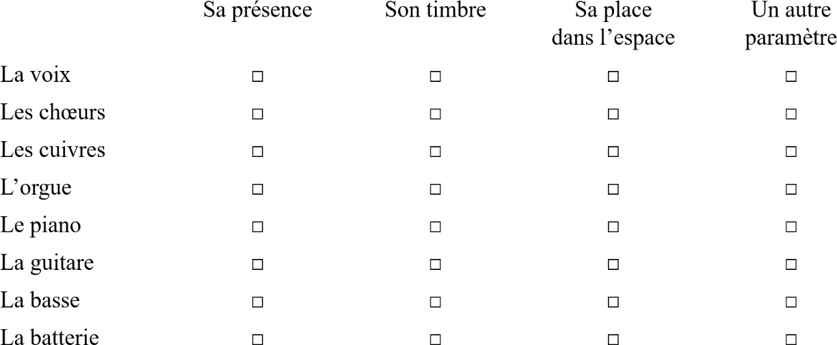
Pouvez-vous détailler vos réponses ?
QK11 : Si vous connaissez le « son Stax », laquelle des deux versions sonores entendues en désigne selon vous la plus fidèle illustration ?
□ La version A □ La version B □ Les deux à égalité □ Je ne sais pas
□ Je ne connais pas le son Stax
QK12 : A quelle époque vous sentez-vous en écoutant la version A ? QK13 : A quelle époque vous sentez-vous en écoutant la version B ?
QK14 : Pouvez-vous en donner les causes ?
Comment appréhendez-vous cette différence (ou similitude) d’époques ressenties depuis une même interprétation musicale ?
QK15 : Avez-vous été perturbé(e) par un ou des éléments sonores extérieurs pendant l’écoute de la version A ?
QK16 : Avez-vous été perturbé(e) par un ou des éléments sonores extérieurs pendant l’écoute de la version B ?
Information : la version A (ou B) est la version sonore originale de la chanson / la version B (ou A) en est une version remixée.
Conclusion
QL1 : Toute considération matérielle exclue, pensez-vous que la version remixée vous donnerait envie d’écouter la chanson B-A-B-Y plus souvent qu’avec la version originale ?
QL2 : Toute considération matérielle exclue, pensez-vous que la version remixée vous donnerait envie d’écouter dans les mêmes conditions sonores le reste du catalogue du label Stax ?
QL3 : Merci de votre participation à ce test d’écoute ! Souhaitez-vous ajouter quelque chose que vous n’avez pas dit ?
Annexe C6 : Expérience n°2 – Commentaires de fin d’expérience des « consommateurs »
Légende : P = Expert 1950-60 / M = Musicien / NM = Non musicien
| Participant | Commentaires de fin d’expérience des « consommateurs » |
| P1 (= P8 Test 1) | Beau travail ! |
| P2 (= P1 Test 1) | Bravo et encore bravo ! On aurait rêvé faire la chose pour ces artistes merveilleux de Memphis Tennessee, et leur faire écouter ! |
| P3 (= P5 Test 1) | |
| M1 | |
| M2 | |
| M3 | |
| M4 | |
| M5 | |
| M6 | |
| M7 | L’espace les amis, l’espace ! |
| M8 | |
| M9 | |
| M10 | C’est intéressant déjà de comparer différentes versions, mais là de voir même au sein du même morceau, des différences à l’écoute, c’est bluffant. Ça fait réfléchir sur l’importance du matériel d’écoute. Par exemple pour mon cas personnel, si quelqu’un découvrait l’opéra sur un enregistrement bon mais avec un mauvais matériel, alors il n’apprécierait peut-être pas à sa juste valeur l’œuvre ou même dans ce cas le genre ! Donc très important. |
| M11 | Je préfère garder le côté original pour comprendre l’objet artistique de l’époque et non pas vu de 2023. |
| M12 | |
| M13 | |
| M14 | |
| M15 | J’étais concentré sur le timbre des instruments dans la première écoute [remixée], parce que je m’attendais à trouver là les différences entre les deux versions. Après, j’ai changé mon écoute, je me suis aperçu de l’espace, de la présence des instruments et du souffle, ce qui m’a aidé à décider finalement. Cela a été positif d’avoir changé d’écoute et de m’être concentré sur d’autres paramètres. Les questions m’ont aidé à cela. |
| M16 | |
| M17 | J’ai été surpris par le fait que la version A soit le remix, mais très agréablement, car ce dernier rajoute de l’âme et du caractère au morceau, et permet de faire mieux entendre l’arrangement. |
| M18 | Etonnement positif quant à découvrir que la version que je croyais être l’original est en fait le remixage, bon travail de mixage ! |
| M19 | |
| M20 | |
| M21 | Bravo |
| NM1 | |
| NM2 | |
| NM3 | C’était passionnant merci beaucoup |
| NM4 | |
| NM5 | |
| NM6 | Eh ben c’est ouf ! Je pensais instinctivement que la version studio originale était la première [remixée] et je ne pensais pas que ce genre de technique de mixage existait. |
| NM7 | J’aurai imaginé que la version B [remixée] était l’original, cela a été surprenant d’apprendre l’inverse. Même si une fois l’information donnée, cela fait sens, la version B [remixée] me semblant plus moderne et plus équilibrée. Découvrir que le positionnement des instruments joue à ce point sur les émotions procurées est dingue. Il y a une vraie douceur, une sensibilité et en même temps de la puissance dans cette seconde version [remixée] qui est étonnante. Cela donne envie de mieux comprendre et d’écouter différemment la musique et donne des clefs d’analyse qui sont précieuses pour pouvoir profiter encore mieux des instruments, du rythme et des petits chamboulements que cela crée dans le ventre. Alors un grand merci pour cette découverte. |
| NM8 | |
| NM9 | Merci |
| NM10 | C’était trop bien 🙂 |
| NM11 | C’était une drôle expérience. Merci beaucoup ! |
| NM12 | J’ai été surprise de voir que la version A [remixée] était une version remixée, je pensais l’inverse. Notamment par rapport à la place plus assumée de l’orgue dans la version B [originale] qui, à mon sens, rend l’écoute plus intéressante et change totalement le style de la musique (ça la rend plus contemporaine). Je trouve ça très étonnant que la version B [originale] date des années 60, je dois avoir une vision trop cliché du style de musique de cette époque. |
| NM13 | Merci beaucoup c’était super ! (Vive l’orgue) |
| NM14 | Bon travail ! |
| NM15 | Surprise d’apprendre que la version B est l’originale, un peu « mono », mais logique quand on sait pourquoi. Je serais curieuse d’entendre la version A [remixée] avec une bonne qualité d’écoute et la version B [originale] dans ma cuisine sur la radio. |
| NM16 | Merci |
| NM17 | |
| NM18 | Je tombe des nues d’apprendre que la version B est la version originale. Je trouve ça surprenant qu’on puisse donner un tel « grain » à une musique remixée, comme si elle datait de plusieurs décennies. C’est une surprise positive. |
| NM19 | |
| NM20 | Vive la version B [remixée], on sent beaucoup plus le groove et le rôle de chaque instrument ! |
| NM21 |
Remerciements
Je tiens à remercier profondément Valentin Bauer, mon directeur de mémoire qui, par son écoute et son engagement, a été mon moteur pendant un an. Je lui dois énormément.
Merci à tous les ingénieurs du son, réalisateurs artistiques, producteurs, professeurs, musiciens, non musiciens, journalistes, disquaires, pour leur précieuse participation à l’une des deux expériences, leur sincère intérêt, et toutes les informations essentielles qu’ils m’ont transmises. J’y ai fait là des rencontres importantes que je ne suis pas près d’oublier.
Merci aux chercheurs et développeurs qui m’ont accordé de leur temps pour me confier des clefs de compréhension dans un domaine d’étude captivant et que je ne connaissais pas.
Merci à Nicolas Erard et à François Longo pour leur aide et leur disponibilité.
Merci à l’ensemble de l’équipe pédagogique de la FSMS qui m’a beaucoup appris et m’a donné toutes les clefs pour réaliser de merveilleux projets artistiques, visuels et sonores dans cette formation unique en son genre. Une mention spéciale à Olivier Montagnon, Justine Huet, Virginie Evennou et Denis Vautrin, qui m’ont offert tous les moyens pour mener à bien ce mémoire.
Merci à ma famille, mes parents pour leur soutien important pendant ces quatre années.
Et un remerciement très spécial à celle qui, par son écoute, sa patience, sa tendresse, a été d’un soutien de tous les instants durant plus d’une année.
- L’Arrivée d’un train en gare de La Ciotat (1896) de Louis Lumière, restaurée en 4K et 60 i/s par Denis Shiryaev : https://www.youtube.com/watch?v=gwSw_WLgekE ↩︎
- Chants de travail. ↩︎
- Il s’inspire du titre It Must Be Jesus des Southern Tones pour écrire I Got A Woman (1954). ↩︎
- Dès 1943, les techniciens allemands parviennent même à enregistrer des concerts sur une bande contenant deux pistes, permettant déjà une reproduction stéréophonique. Au sortir de la guerre, l’URSS retrouve à Berlin des centaines de bandes, mais seulement trois stéréophoniques (Rémond, 2015). ↩︎
- Pour la suite de notre étude, nous abrégerons parfois le terme « monophonique » par « mono ». ↩︎
- Le magnétophone bipiste contient une bande dont les deux pistes sont séparées par un intervalle de garde qui garantit une diaphonie minimale entre elles. À l’inverse, il est impossible de ne traiter qu’une seule des deux pistes d’un magnétophone stéréo, destiné à générer un master (Rumsey & McCormick, 2002). ↩︎
- Réenregistrement. ↩︎
- Le label de R&B/soul Atlantic Records est en 1958 le premier studio à posséder un enregistreur 8 pistes, mais rarement avec l’idée de pratiquer l’overdubbing (Moorman, 2003). ↩︎
- Smokestack Lightnin’ (1956, Chess Records) : https://www.youtube.com/watch?v=PnXTpkugcHo ↩︎
- Ole Man Trouble (1965, Volt Records) : https://www.youtube.com/watch?v=oKsiukdz0xI ↩︎
- Hound Dog (1956, Peacock Records) : https://www.youtube.com/watch?v=ucqhmFyzMgs ↩︎
- Mess Around (1953, Atlantic Records) : https://www.youtube.com/watch?v=u37gVPLpRNE ↩︎
- Beaucoup de labels de blues/R&B/soul continuent de travailler avec des enregistreurs 2, 3 ou 4 pistes. ↩︎
- Ain’t No Mountain High Enough (1967, Motown) : https://www.youtube.com/watch?v=7PItshAEAC4 ↩︎
- « L’usine à tubes », le surnom de Motown Records. ↩︎
- SPAT Revolution : https://www.flux.audio/project/spat-revolution/ ↩︎
- International Federation of the Phonographic Industry (IFPI). ↩︎
- Sans perte. Perte générée par l’échantillonnage des données audio. ↩︎
- La scène sonore suit les mouvements de la tête. ↩︎
- Souvent, les sources séparées des enregistrements de jazz sont les fichiers multipistes eux-mêmes, car la stratégie de prise de son en proximité le permet. ↩︎
- Non-negative matrix factorization (NMF). ↩︎
- Machine learning. ↩︎
- Deep learning. ↩︎
- Graphics Process Unit : processeur graphique. ↩︎
- Natural Language Processing (NLP) en anglais. ↩︎
- Computer vision en anglais. ↩︎
- Marius Miron (2016) a élaboré une méthode de séparation de sources d’un orchestre symphonique par apprentissage supervisé et informée de la partition. Pour s’affranchir de la contrainte de réverbération des enregistrements existants et donc pour concevoir sa propre base de données pour l’apprentissage du réseau (mixages stéréo et sons isolés), il a réenregistré individuellement chaque section de l’orchestre et en a reconstitué artificiellement un mixage stéréo. Cette innovation a été intégrée par l’application The Orchestra, qui permet désormais d’entendre isolément chaque section de l’orchestre. ↩︎
- Ces experts sont des personnes connaissant bien le répertoire blues/R&B/soul des années 1950-60 pour l’avoir abondamment écouté, sans forcément en connaître parfaitement toutes les références. Ils en connaissent surtout l’esprit de la musique. Ils ne peuvent pas être ingénieurs du son mais musiciens. ↩︎
- Spat Revolution Remote : https://www.flux.audio/project/spat-revolution-remote/ ↩︎
- Open Sound Control. Langage de transmission unidirectionnelle de données en temps réel entre plusieurs logiciels, possiblement actifs sur plusieurs appareils numériques (ordinateur, smartphone, synthétiseur…). ↩︎
- Open Stage Control : http://openstagecontrol.ammd.net/ ↩︎
- Afin de bien distinguer les profils et leurs comportements, les experts 1950-60 ne peuvent pas être ingénieurs du son. Cependant, afin de recruter plus facilement, ils peuvent être musiciens. ↩︎
- Voir retours généraux des participants de l’expérience en annexe B6. ↩︎
- Faites à partir des réponses aux questions QB2 à QB5 (II.A.3.2.b.) et QD1 à QD4 (II.A.3.2.d.). ↩︎
- Provenant du fichier texte généré par l’interface présentée en II.A.2.2. ↩︎
- Un aperçu seulement, car nous n’entendons pas recouvrir la totalité des répertoires musicaux ciblés avec ces trois seuls enregistrements. ↩︎
- Voir définition donnée par les participants en section II.B.2.1. ↩︎
- Prépondérant dans un remixage en son immersif ↩︎
- Qualité rythmique qui incite à bouger, à danser. ↩︎
- Surnommée “The Queen of Memphis Soul”. ↩︎
- Au-delà du masquage des sources engendré par la mono, ces défauts de balance peuvent s’expliquer par le fait que l’ingénieur du son Tom Dowd a dû mixer en direct les 8 entrées micro sur 2 mixettes 4 voies Ampex 3761, à cause d’un simple magnétophone stéréo en sortie, le Scully 280. ↩︎
- La limitation à 8 entrées micro a obligé l’ingénieur du son Tom Dowd à ne placer qu’un seul micro par instrument, ce qui a pu créer des inégalités de qualité de captation entre divers instruments. ↩︎
- Nous pourrons ainsi nous rapprocher du son Stax de la batterie, dont notre référence sera Tramp (1967), interprétée par la même Carla Thomas en duo avec Otis Redding, au tempo proche. ↩︎
- Grâce à son magnétophone stéréo Scully 280, Stax a aussi publié un master stéréo de B-A-B-Y mais qui n’a en fait pas été à l’origine du succès de la chanson, révélée comme tous les autres hits par la radio. ↩︎
- Classée n°3 des meilleures ventes de disques R&B et n°14 des meilleures ventes de disques pop US. ↩︎
- Envie spatiale formulée par deux ingénieurs du son de l’expérience n°1 (figure 38c). ↩︎
- Caractéristique musicale mentionnée par un ingénieur du son de l’expérience n°1. ↩︎
- Jim Stewart, fondateur de Stax Records : « Il n’était question que de coopération et d’implication totale. Il n’y avait aucune limite imposée à l’apport de chacun. Il n’y avait pas parmi nous de producteur au sens qu’a pris aujourd’hui ce terme. Les crédits disaient juste : « Produit par l’équipe Stax. » » ↩︎
- Bien que nous informions le participant qu’il écoutera d’abord le master original, puis le master remixé, nous ne lui disons ni comment ni par qui ce dernier a été généré, afin qu’il conserve sa neutralité et continue de guider sa critique des masters par la musique. ↩︎
- En vérité, à l’aide de SPAT Revolution, nous transposons actuellement en binaural le remixage immersif de B-A-B-Y que nous avons réalisé sous le dôme de haut-parleurs du plateau 1. ↩︎
- Nous vérifierons cette hypothèse des « producteurs » dans le test « consommateurs » en section III.C.4. ↩︎
- Ceci explique le déséquilibre démographique entre les différentes classes d’âge (figure 43b), qui est la contrepartie d’inviter beaucoup de participants à notre expérience, en particulier des musiciens. ↩︎
- Faute de pouvoir obtenir davantage d’experts 1950-60, après de multiples tentatives de recrutement auprès de divers musiciens, disquaires et dans les groupes spécialisés des réseaux sociaux. ↩︎
- Moins essentielle que pour l’expérience n°1 qui comparait les comportements des différents profils. ↩︎
- Il est important que le participant puisse conserver sa concentration pour mémoriser tous les aspects positifs et négatifs qui lui sont apparus dans la première écoute et les confronter dans la seconde. ↩︎
- Durant tout le test, nous nous plaçons en retrait dans la salle pour altérer le moins possible la relation entre la musique et l’auditeur (figure 41). ↩︎
- Nous avons créé un questionnaire pour chaque ordre d’écoute : A (original) / B (remixage) pour la moitié des participants, A (remixage) / B (original) pour l’autre moitié. ↩︎
- « Toute considération matérielle exclue » comporte le même sens que dans le test pour « producteurs ». ↩︎
- Si suffisamment de participants connaissent le son Stax. ↩︎
- Responsables de l’âme et du groove de la chanson, d’après les remarques orales des « consommateurs ». ↩︎
- Corrigeant ainsi l’aspect « mal intégrée dans le groupe » soulevé dans l’expérience n°1 (figure 38a). ↩︎
- Guitare et batterie manquaient de présence dans la version originale d’après l’expérience n°1. ↩︎
- Permise aussi par RipX, qui indirectement a retiré le souffle de l’enregistrement (section III.A.1.1.). ↩︎
- Une version stéréo a bien été exportée et publiée par le label Stax en 1966, mais très différente de notre présente version immersive (espace très latéralisé, aucune source au centre de l’image sonore, etc.). ↩︎
- 5 de ces participants ont préféré écouter notre version remixée, 4 la version originale et un a autant aimé l’une que l’autre. ↩︎
- Voir l’intégralité des commentaires de fin d’expérience en annexe C6. ↩︎
- Nous avons décidé de réduire cette question aux seules années 1950, car l’aspect mono de l’enregistrement, essentiel à notre propos, est de moins en moins fréquent dans les années 1960 (premières commercialisations stéréo en 1958). ↩︎
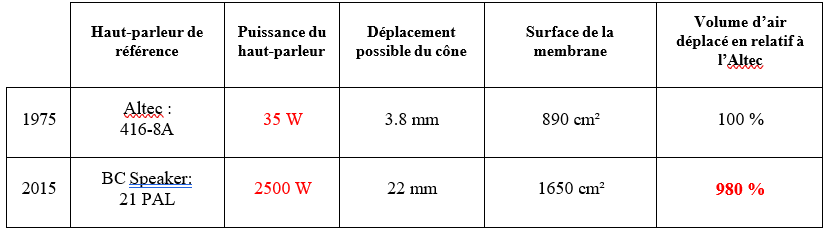
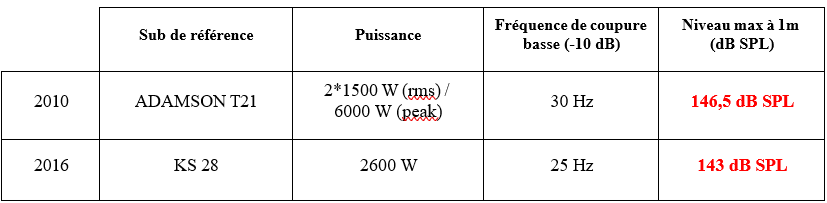
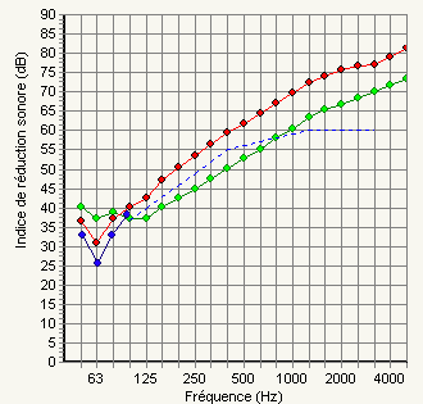
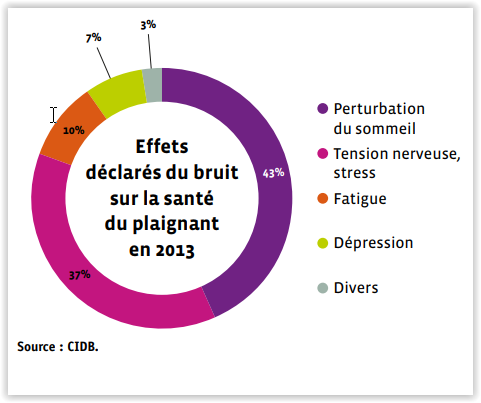
![Figure 2 : (A) un obstacle très petit devant la longueur d'onde (B) un obstacle plus grand que la longueur d'onde (Everest F. Alton, [5])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-56.png)
![Figure 3 : Cas en 2D d'ondes stationnaires entre deux parois rigides et réfléchissantes (Jouhaneau J., 1992, [13])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-113707.png)
![Figure 4 : Vue dans l'espace. Modes axiaux 1D (a), Modes tangentiels 2D (b) et modes obliques 3D (c) (Jouhaneau J., 1992, [13])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-58.png)
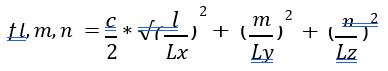
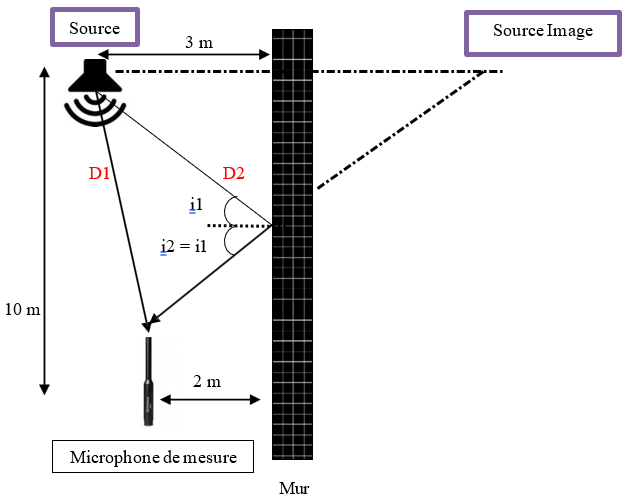
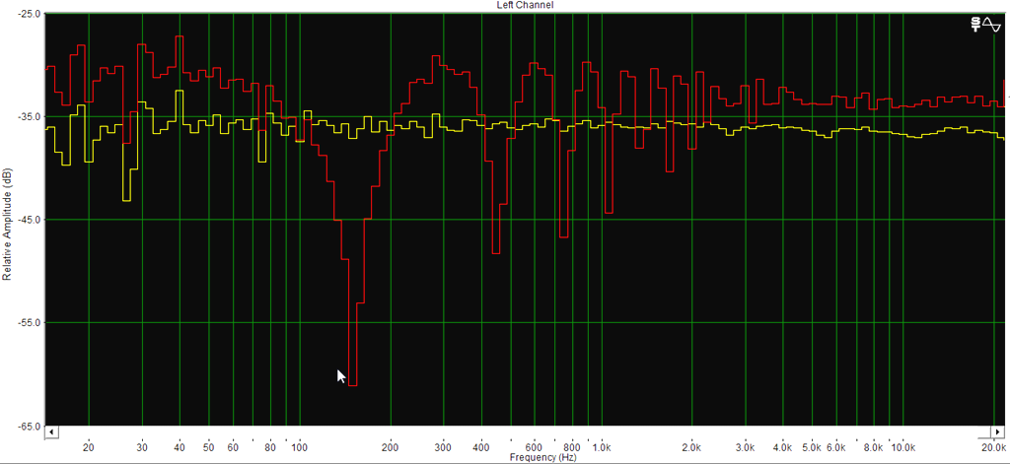
![Figure 8 : Phase et longueur d'onde (Pietquin D. 2008, [18])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-61.png)
![Figure 9 : Cercle des phases et valeurs d'annulation pour deux signaux de même niveau (Van Veen M., 2008, [24])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-114904.png)
![Figure 10 : niveaux de sommation en fonction du niveau relatif et de la phase entre les deux signaux (Mc Carthy B., 2016, [24]) (NB : « ripple » signifie maximum de variation entre l’addition et la soustraction)](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-64.png)
![Figure 11 : zones de sommation en fonction des fréquences et du décalage temporel (McCarthy B., 2016,[6]])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-65-373x1024.png)
![Figure 12 : Courbe de réponse d'un HP dans 3 situations différentes : Chambre anéchoïque (1), Angle d’une cabine en bois (2), Centre de la cabine en bois (3) (Rossi M., 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-115541.png)
![Figure 13 : Gain en SNR3 en fonction de temps de mesure du sweep en relatif à une mesure en bruit rose (Rousseau D.,[22])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-67.png)
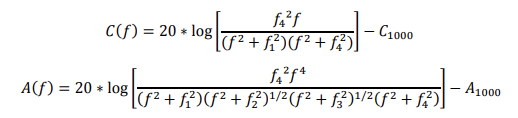
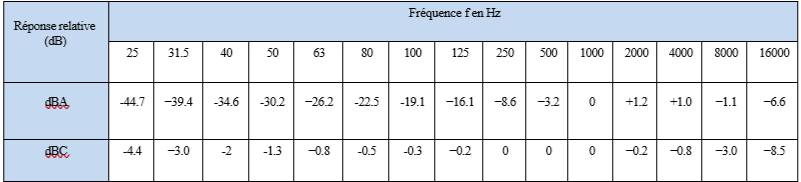
![Figure 16 : courbe du champ auditif et de pondération acoustique (HCSP, [26])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-70.png)
![Figure 18 : Influence de la taille de la FFT sur la résolution fréquentielle (Van Veen M., 2017, [24])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-72.png)
![Figure 19 : Analyse des discontinuités introduites dans le signal temporel lors de l'utilisation d'une fenêtre rectangulaire (01dB, [27])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-75.png)
![Figure 20 : Effet de la fenêtre de Hanning sur une fonction (01DB, 1996, [27])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-76.png)
![Figure 21 : fréquences (Hz) en tiers d'octave et octave (Mario Rossi, 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-77.png)
![Figure 22 : spectre en bande d'octave, tiers d'octave et 24e d'octave de la trompette jouet de Toutankhamon (Mario Rossi, 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-79.png)
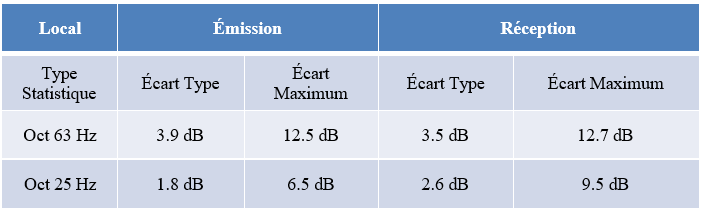
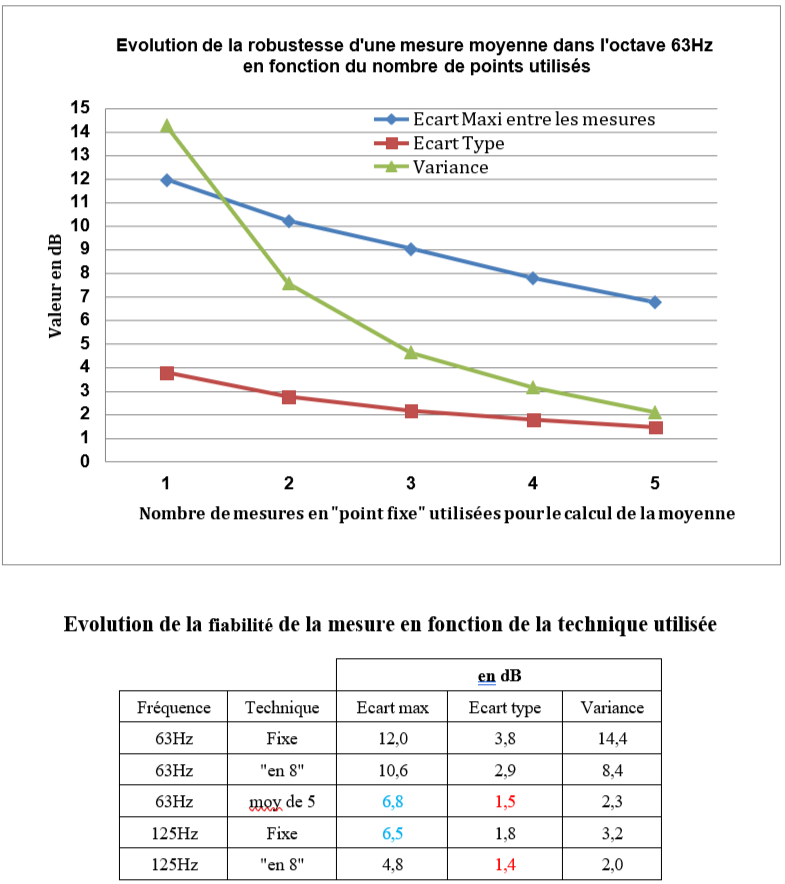
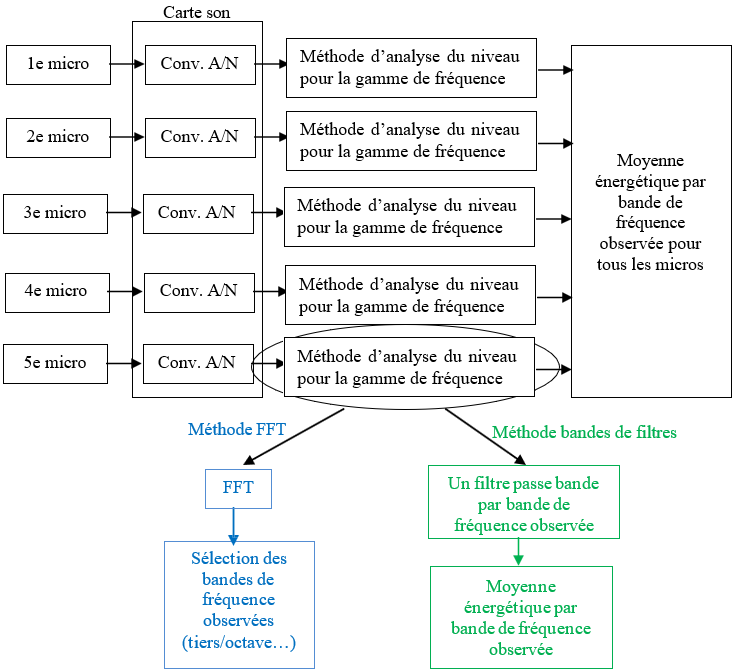
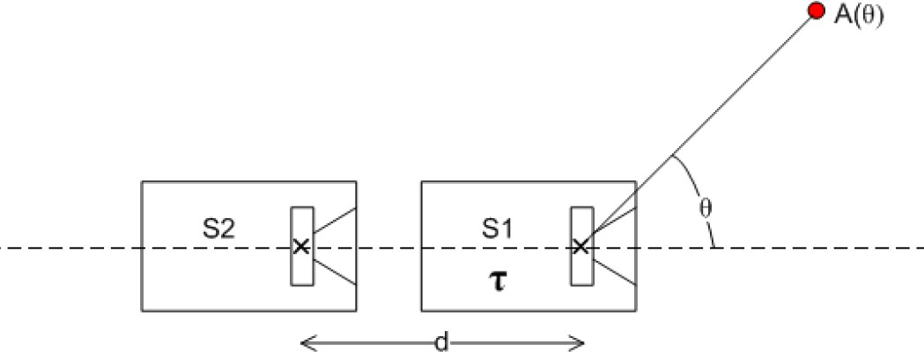
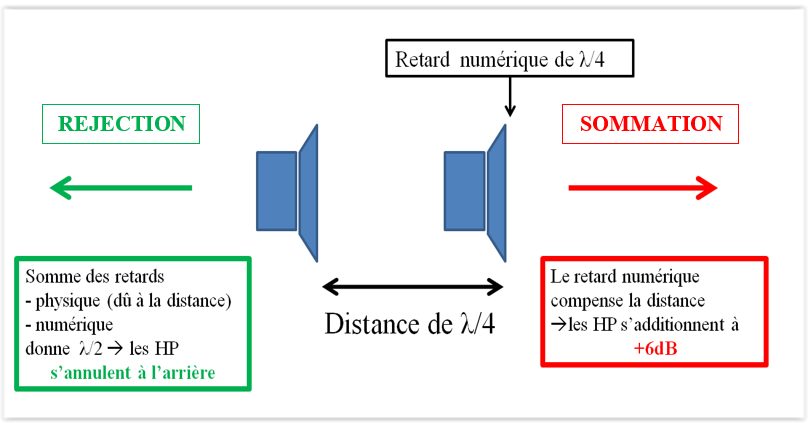
![Figure 23 : Configuration cardioïde à gradient (Bob Mc Carthy, 2016, [6])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-82.png)
![Figure 24 : Configuration End Fire (Bob Mc Carthy, 2016, [6])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-83.png)
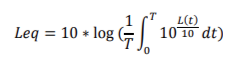

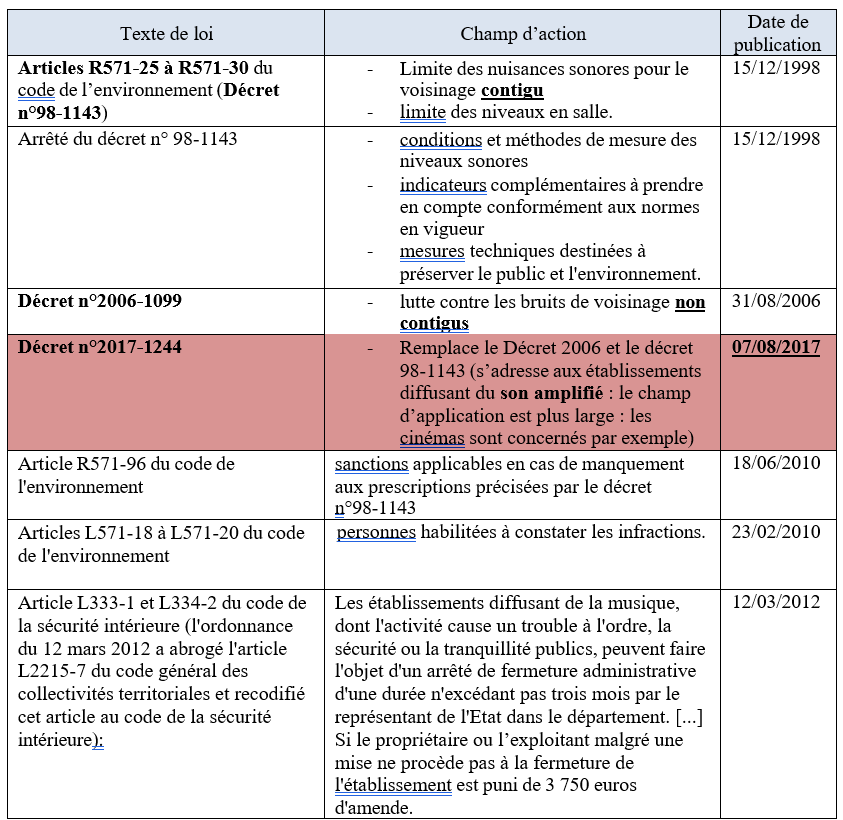
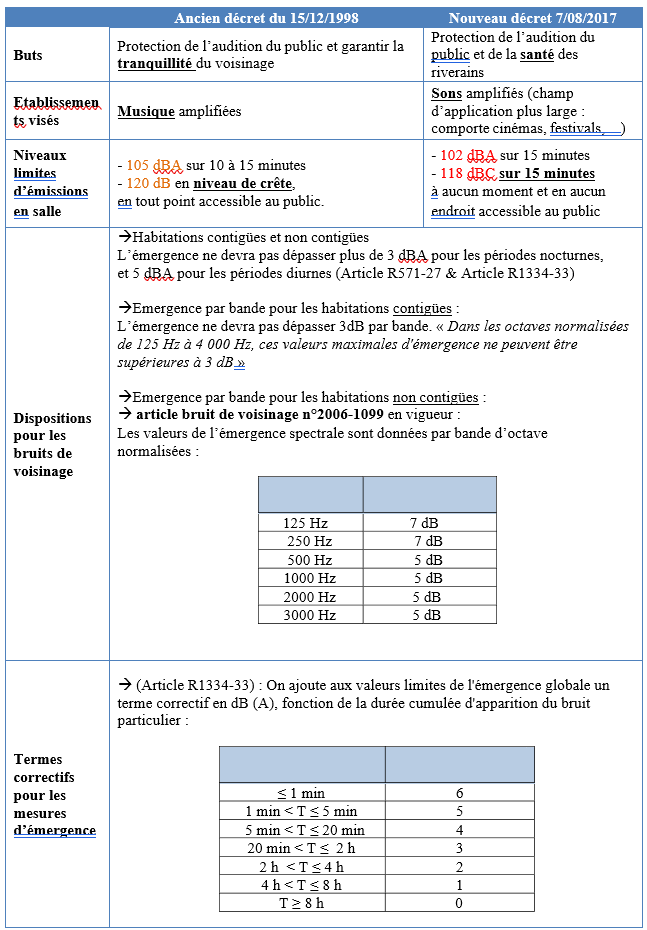
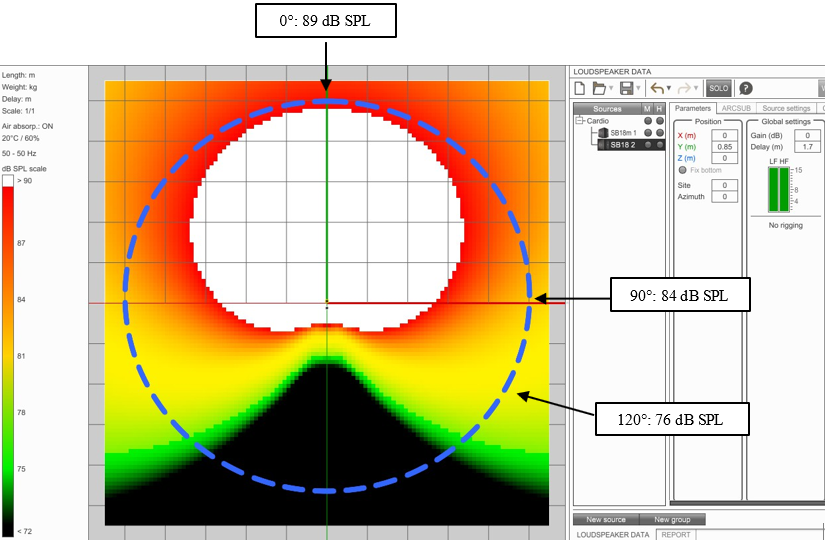
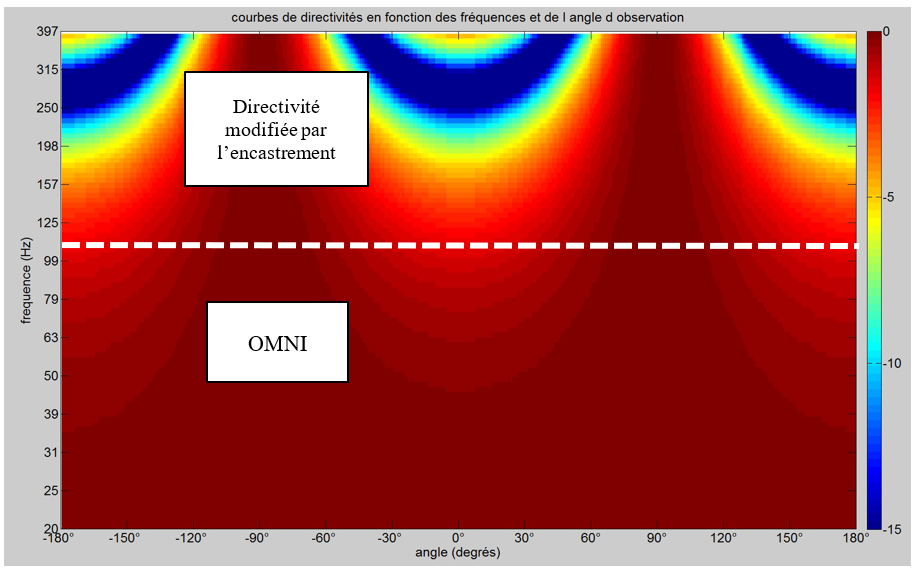
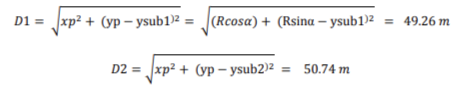
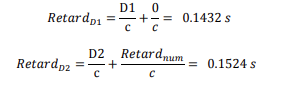
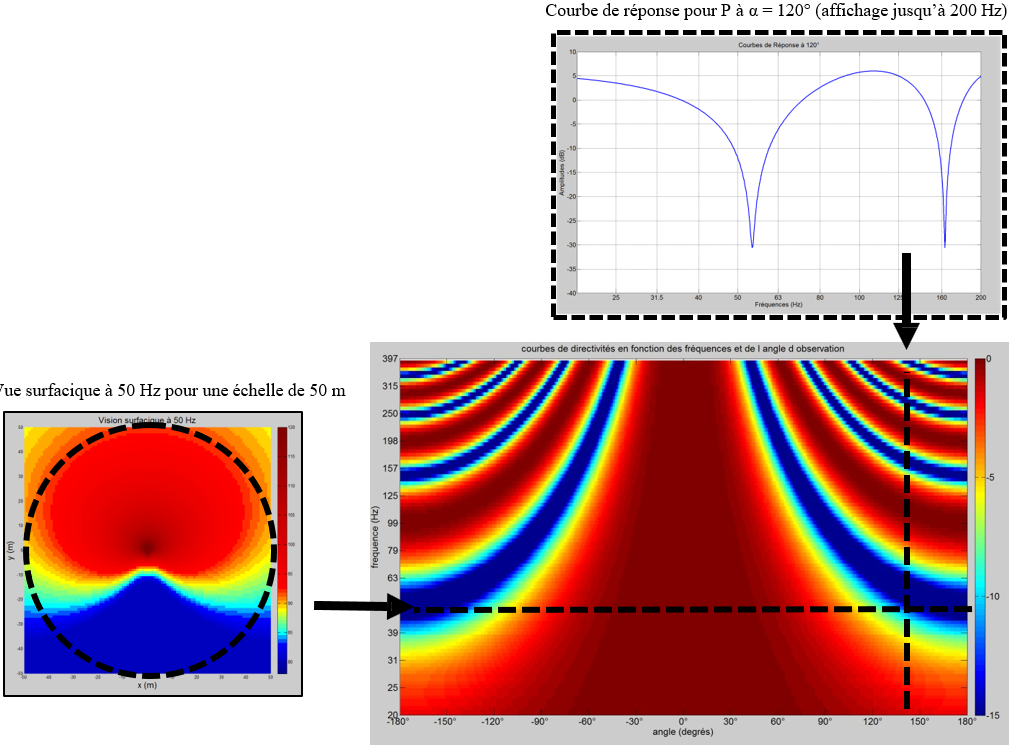
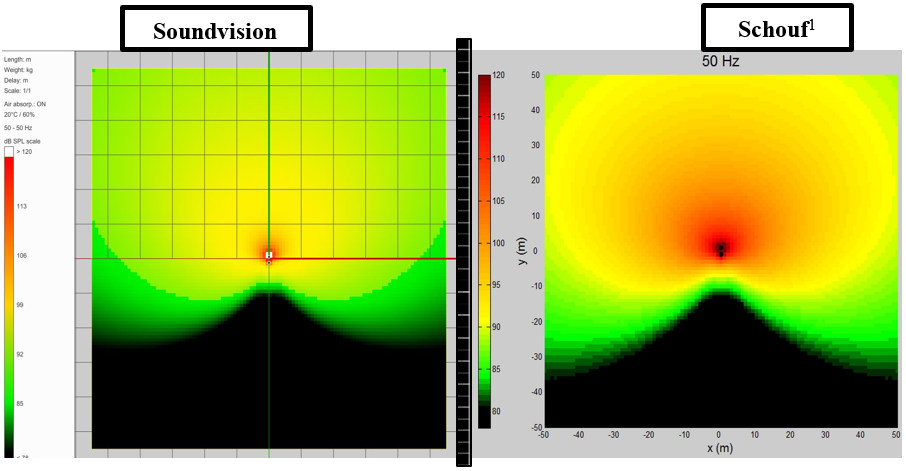
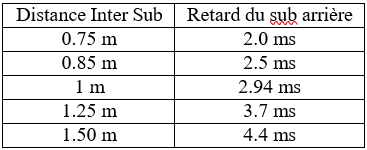
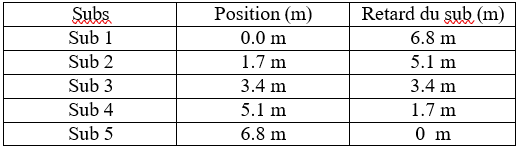
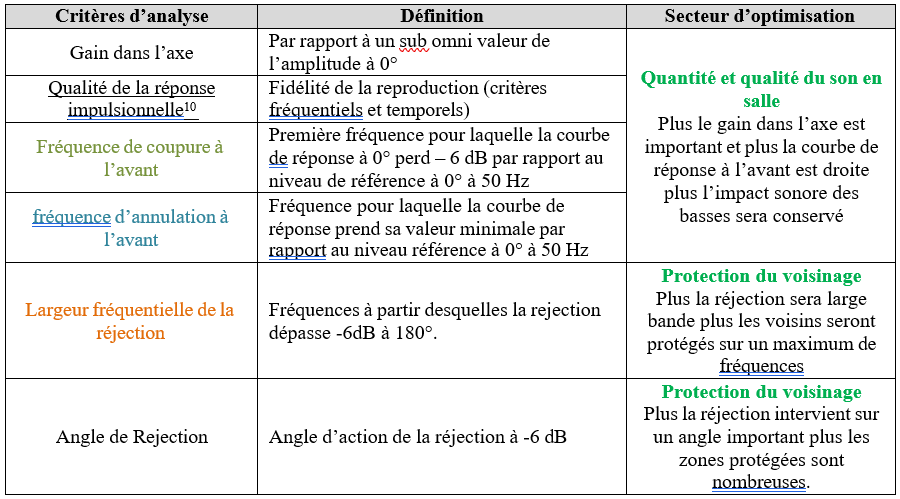
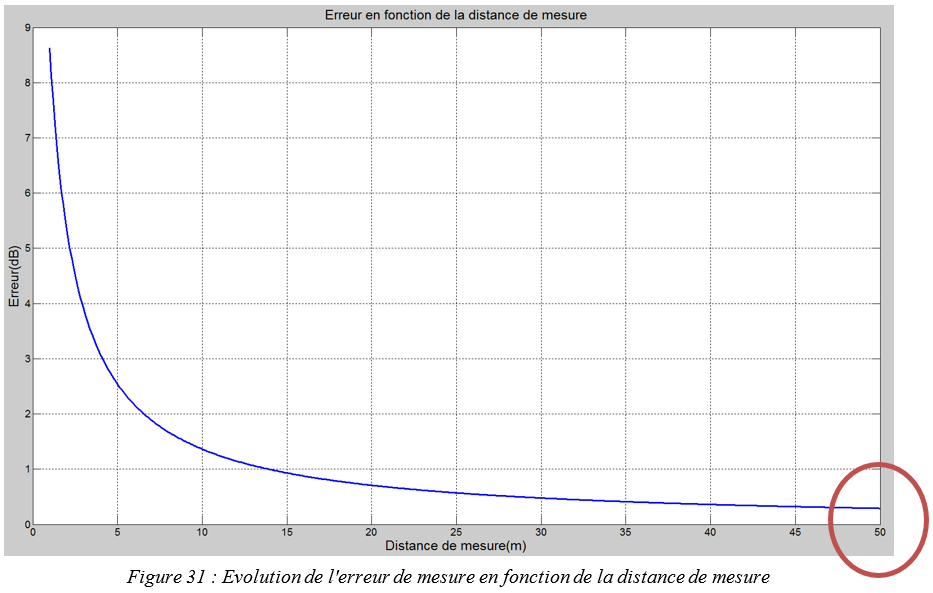
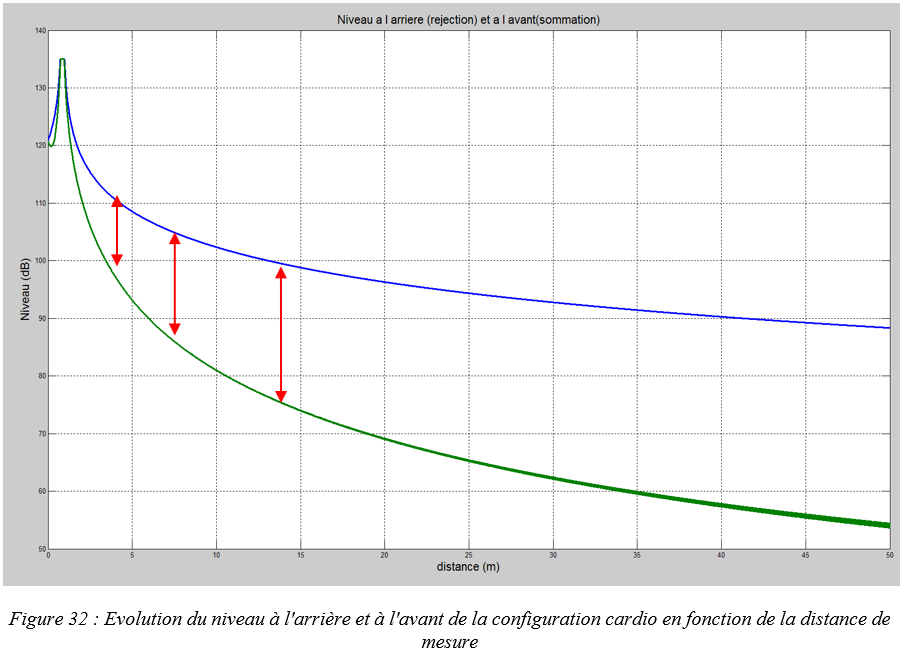
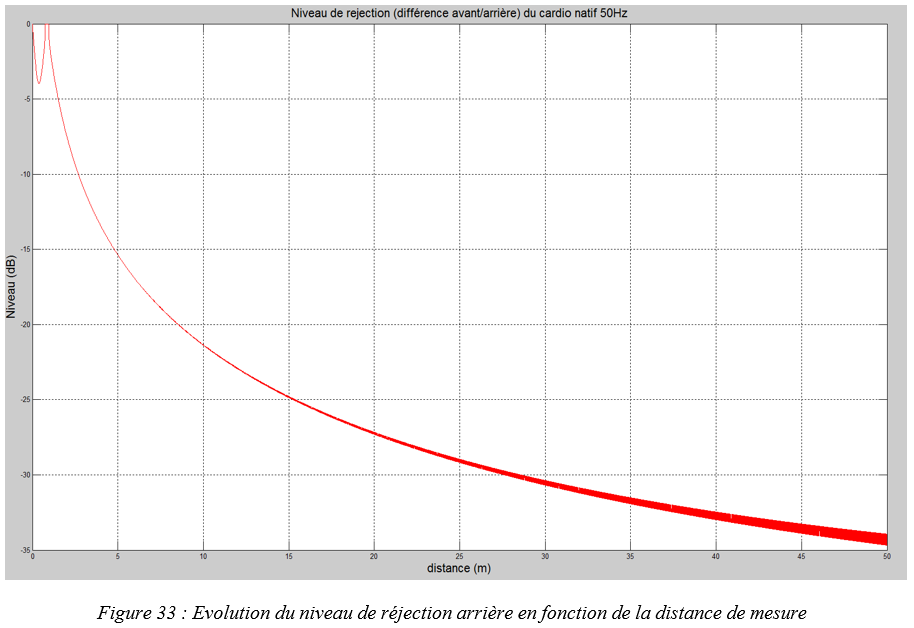
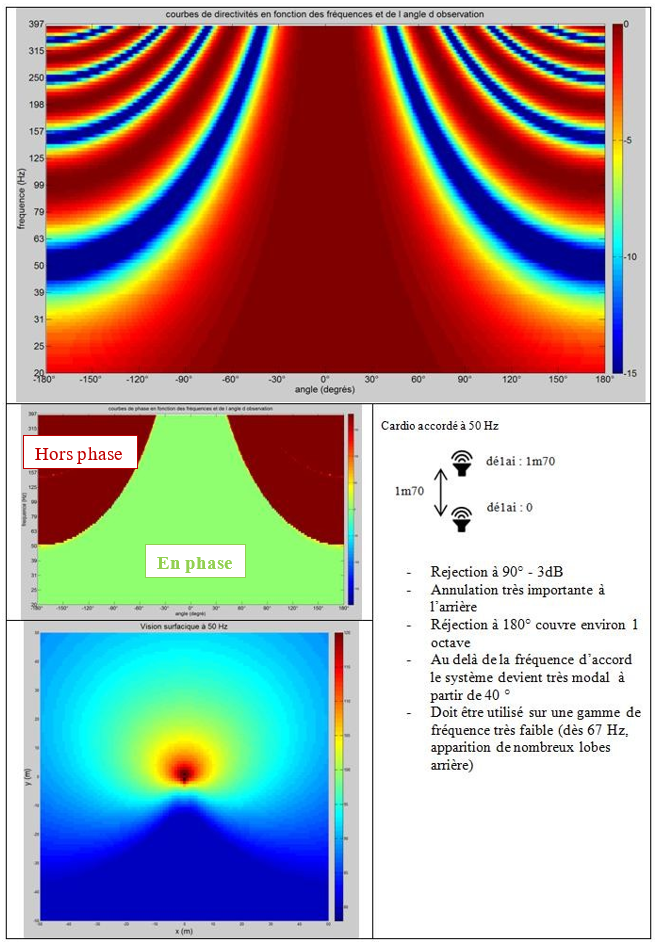
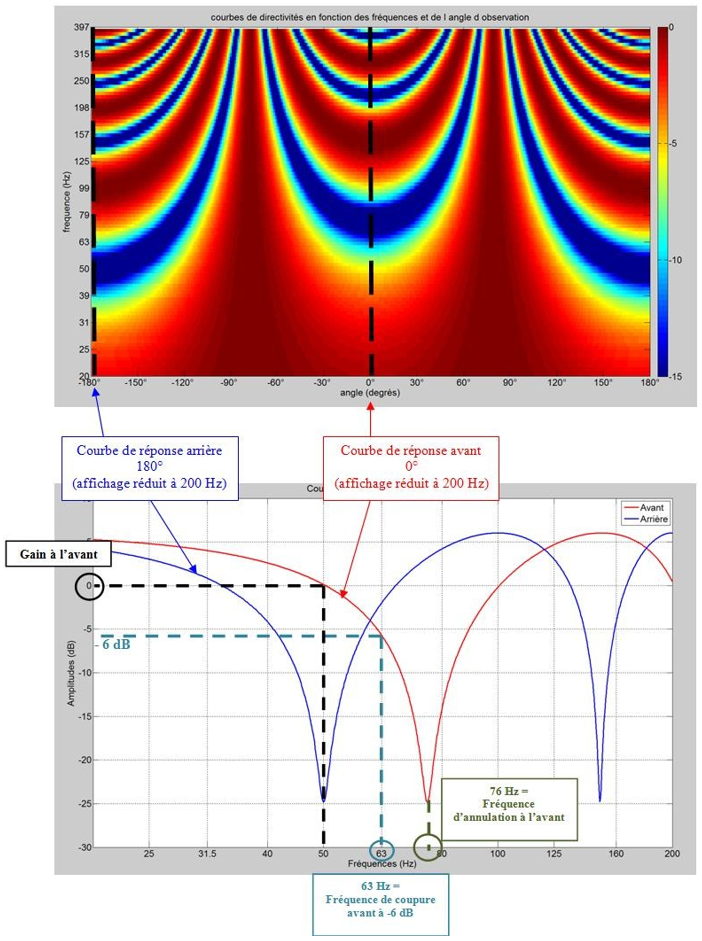
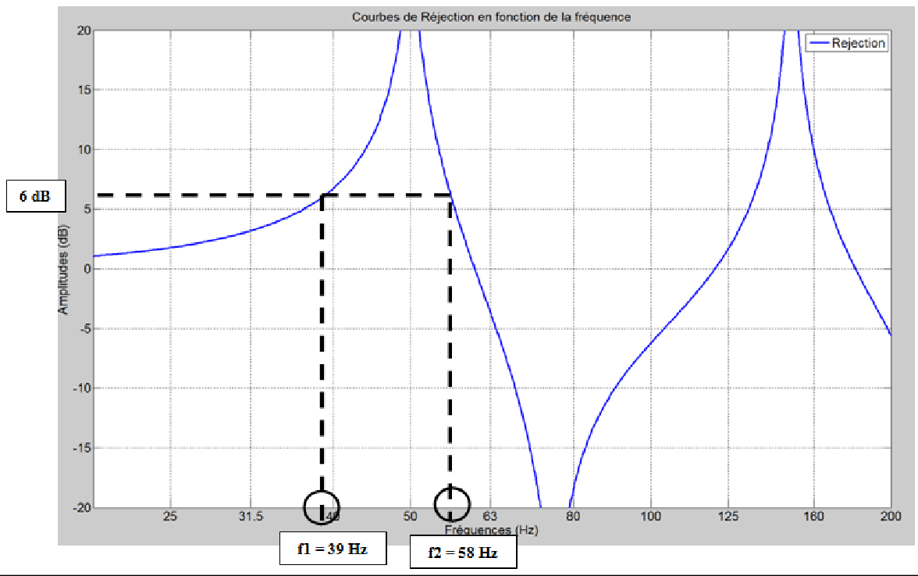
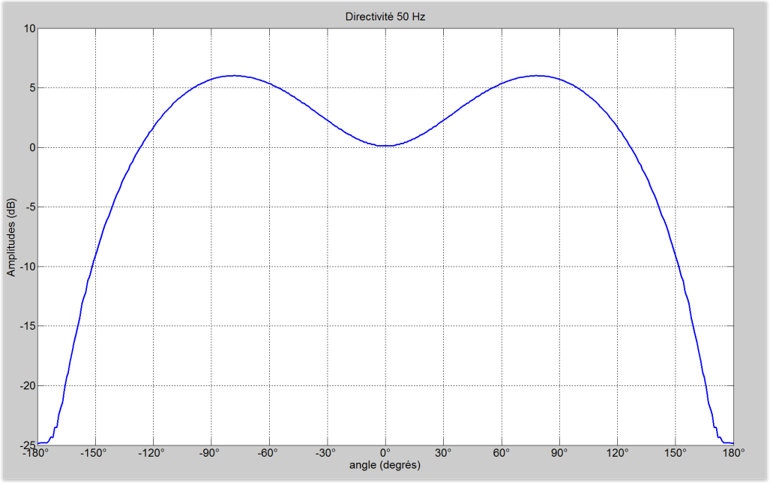
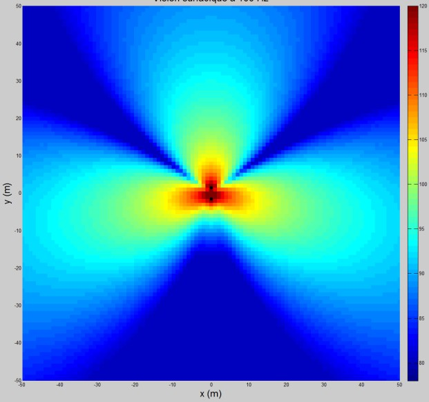
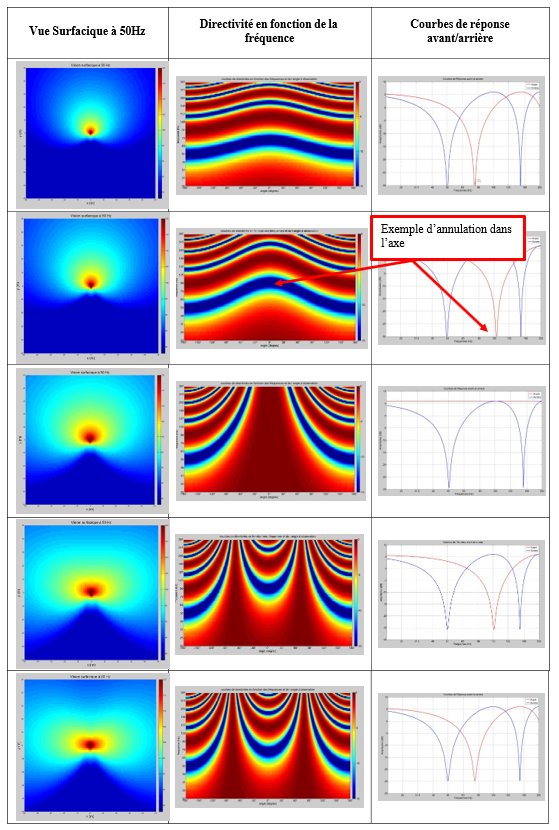
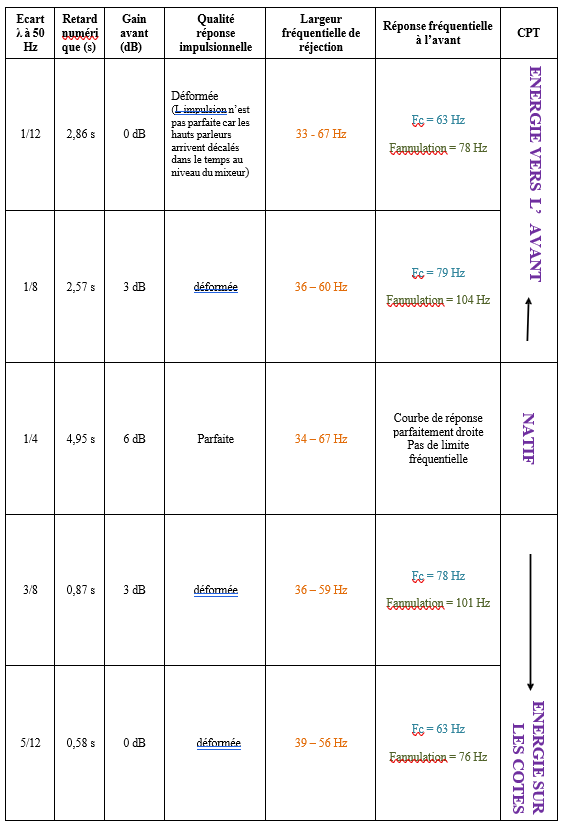
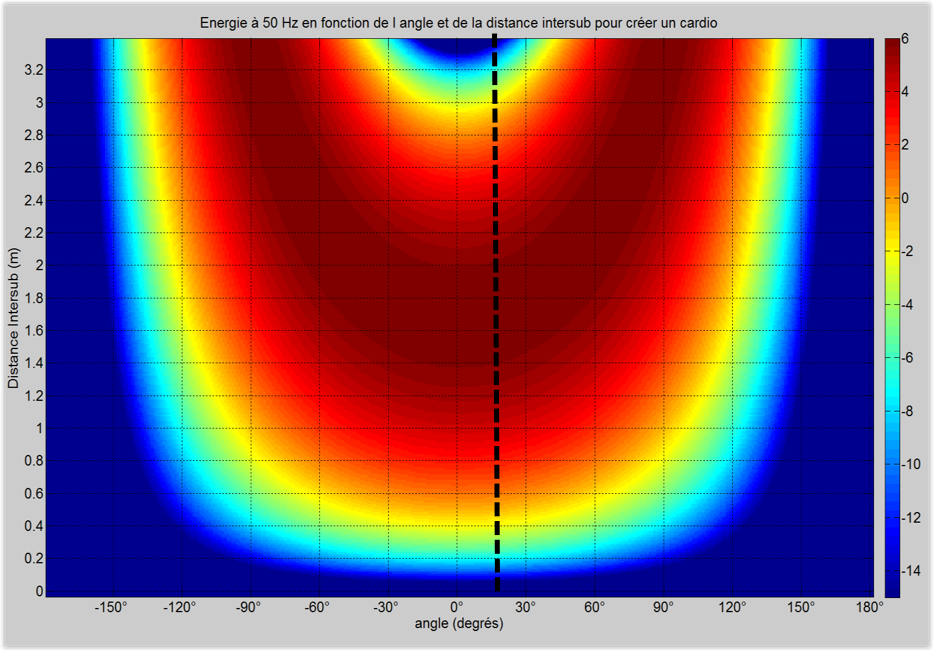
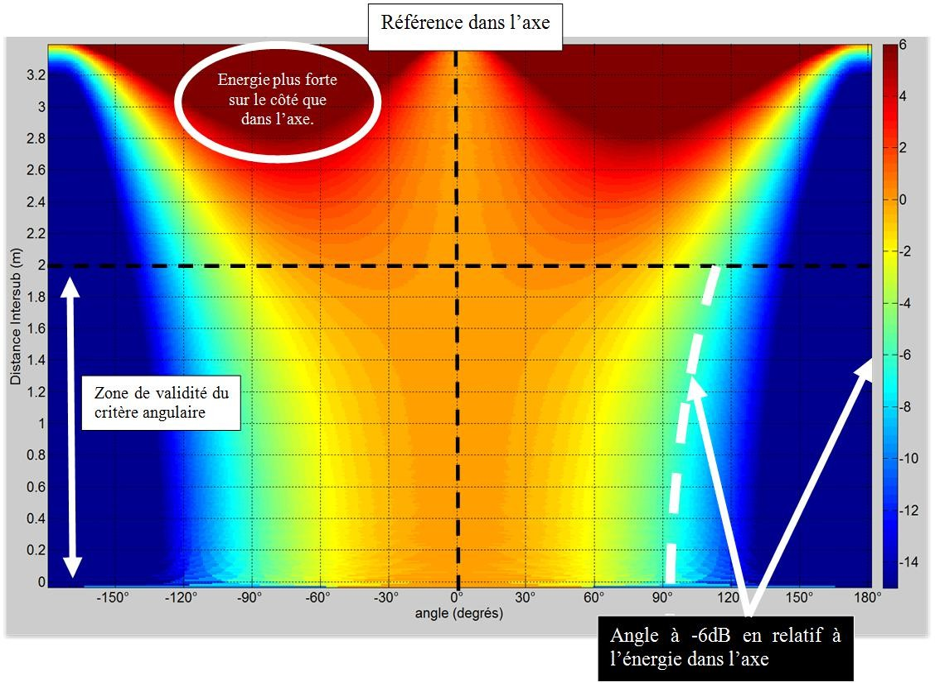
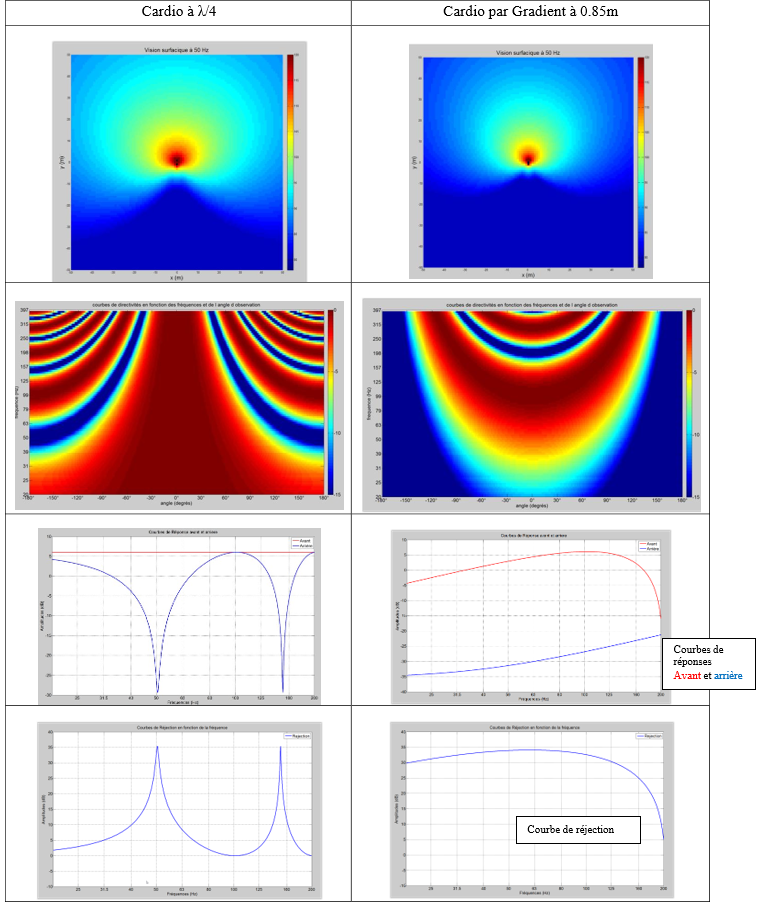
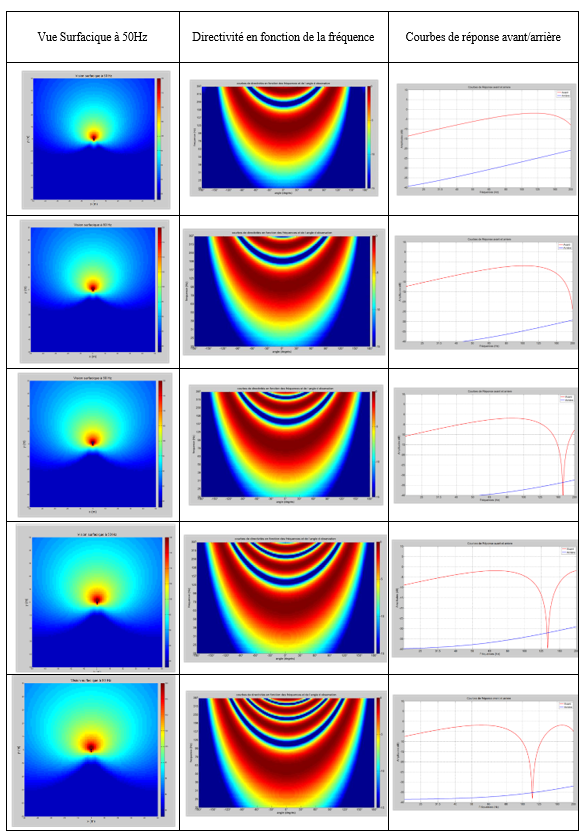
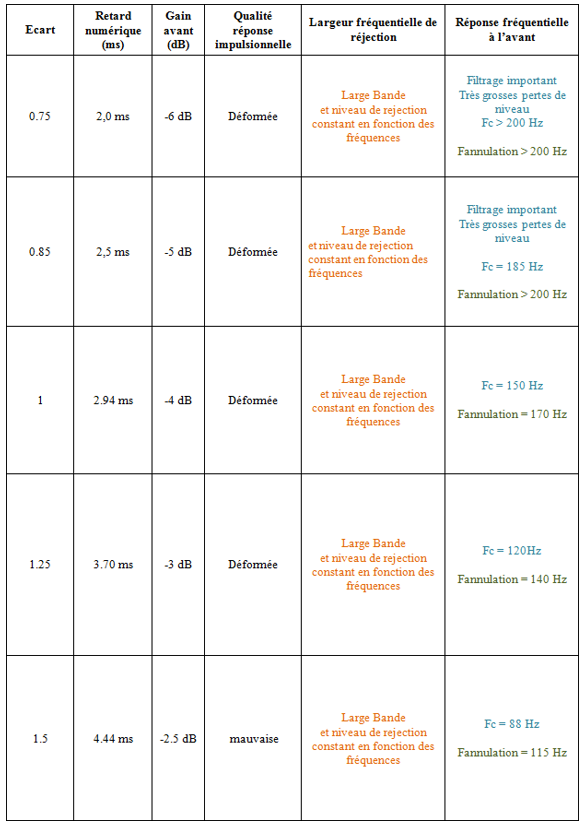
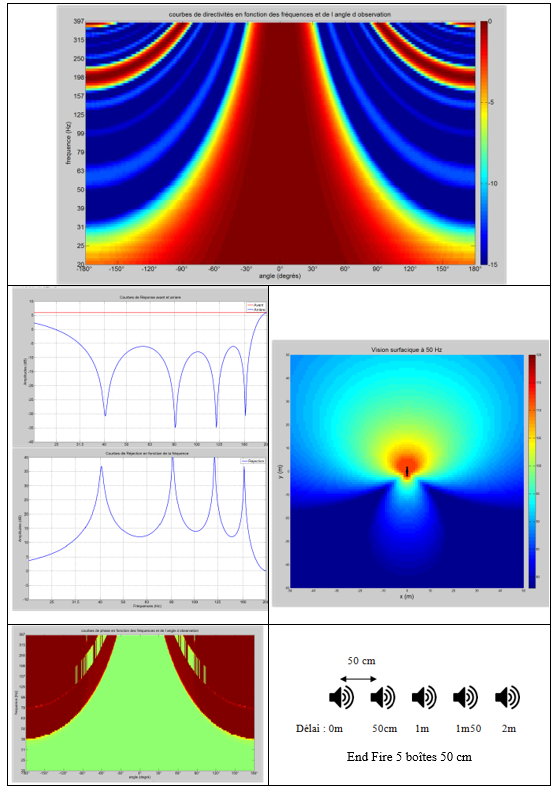
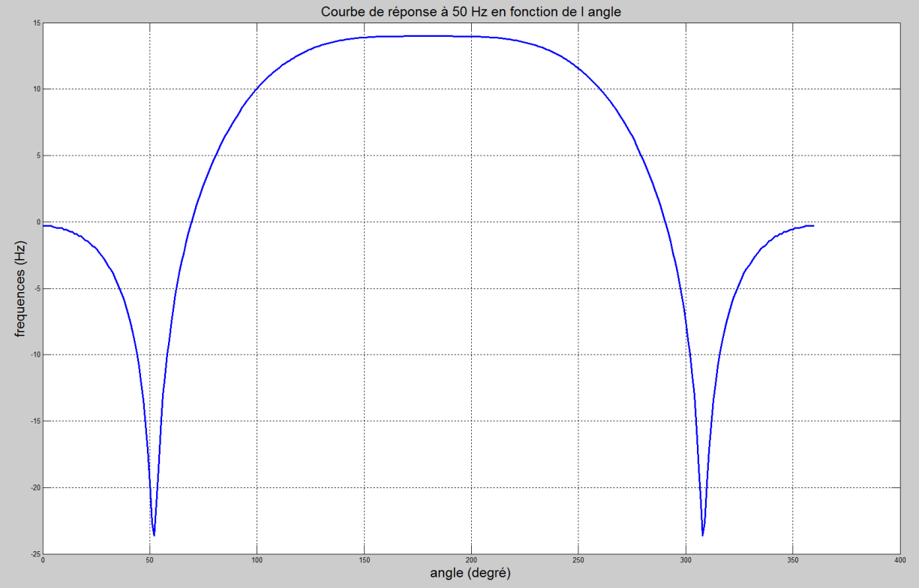
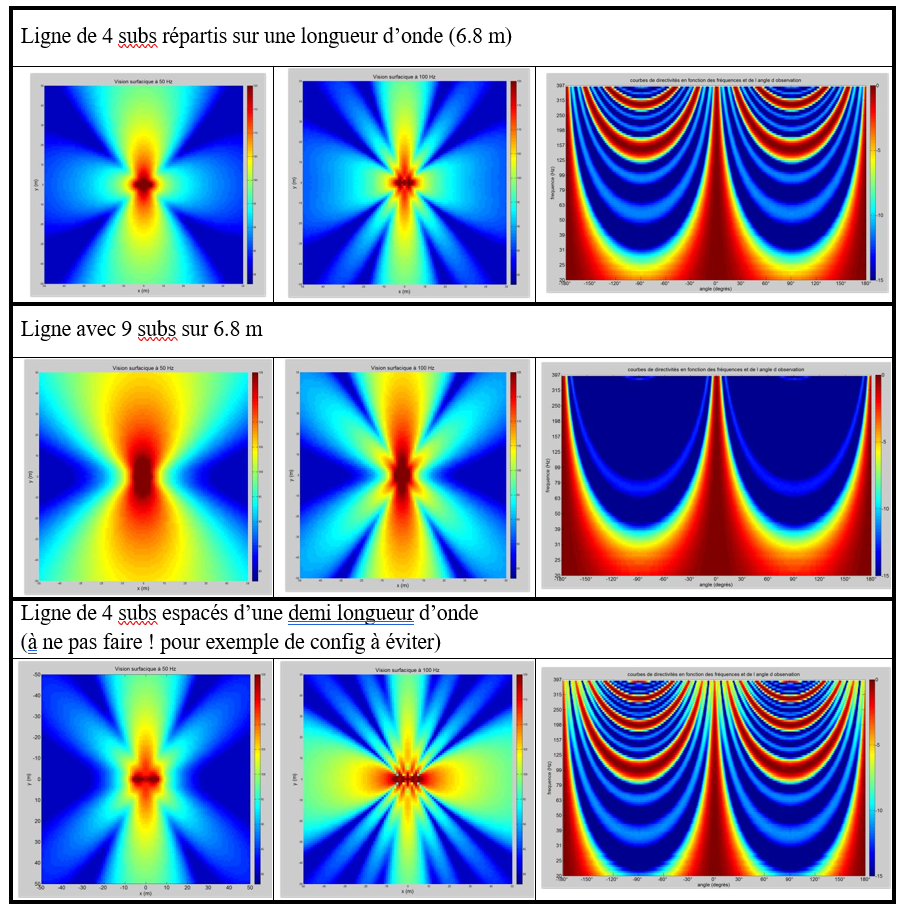
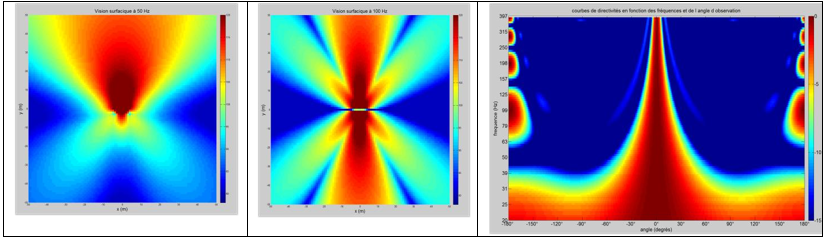
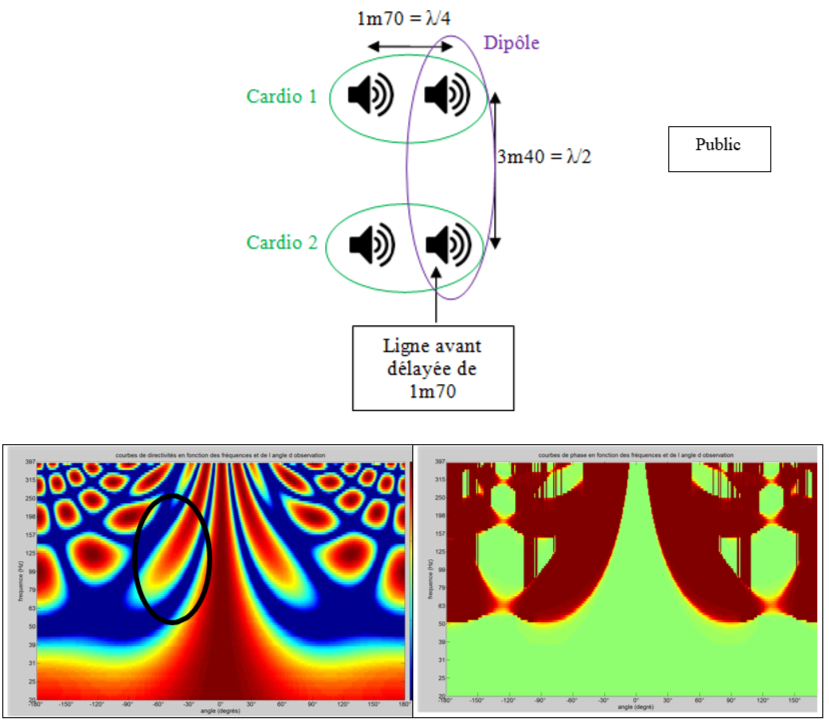




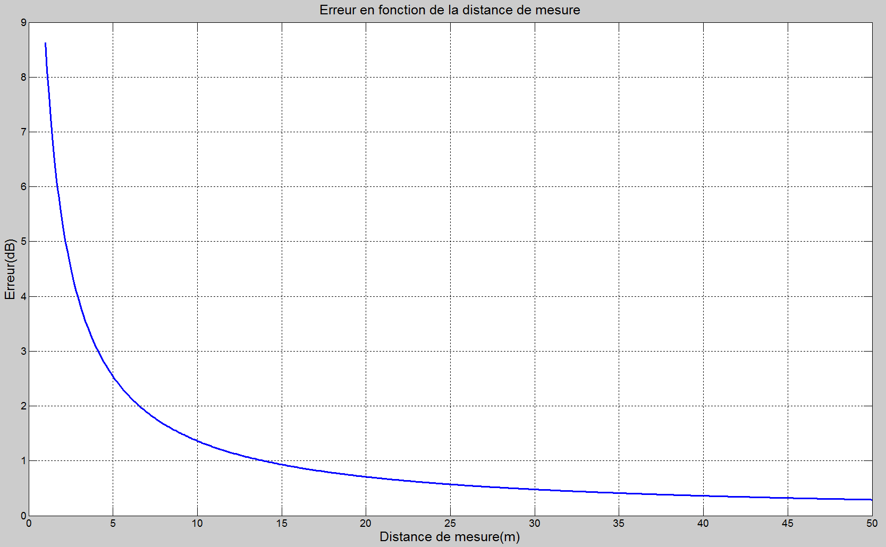
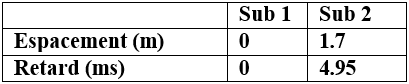

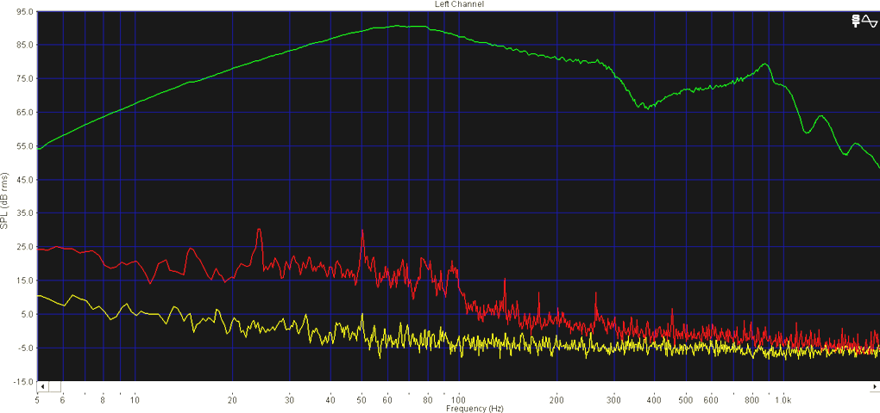
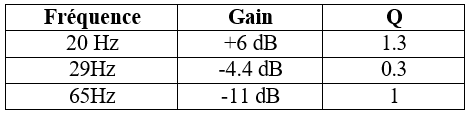
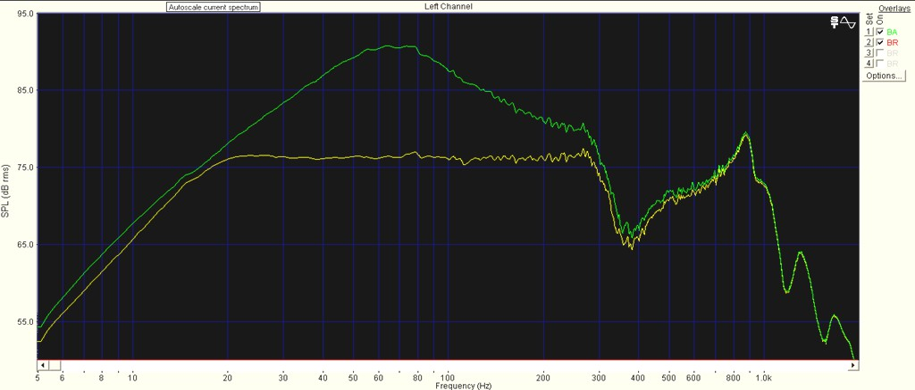
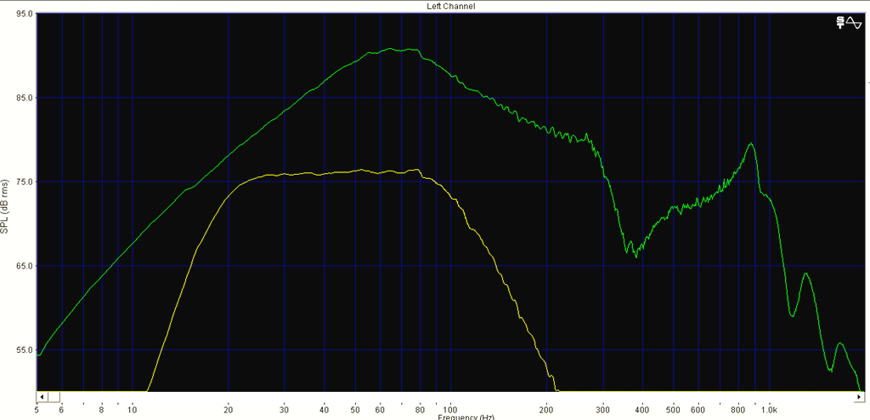
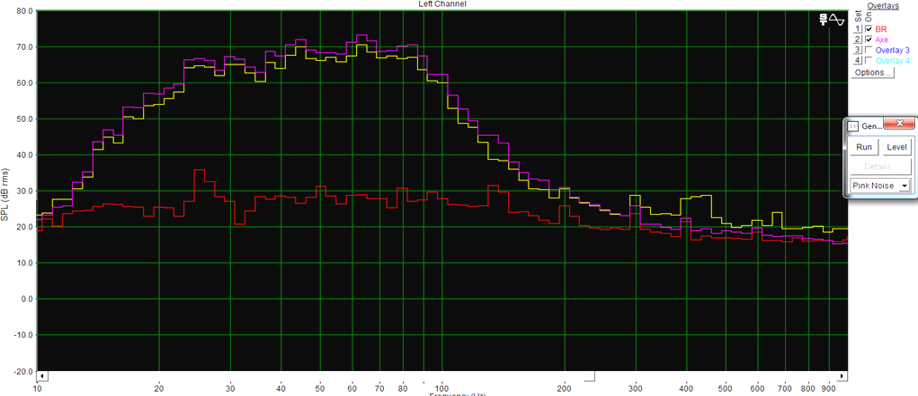
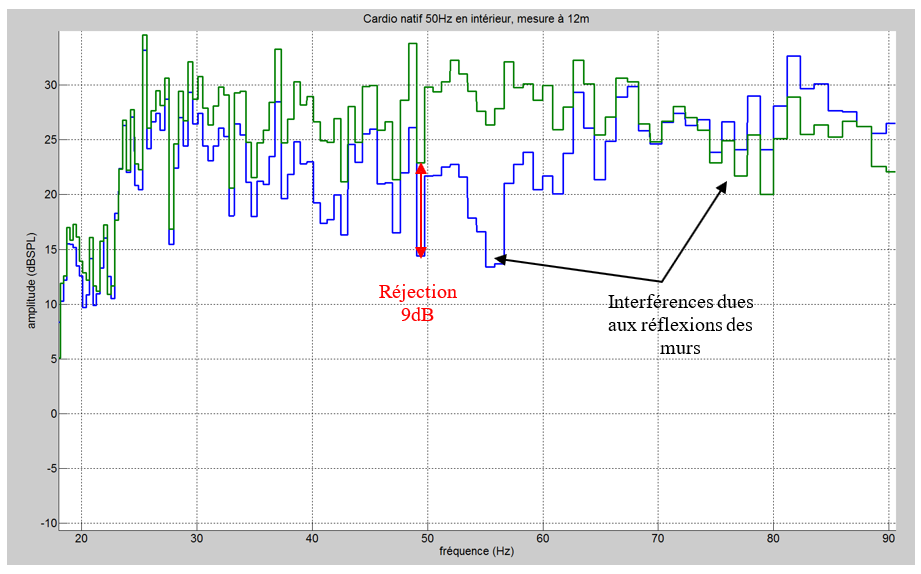
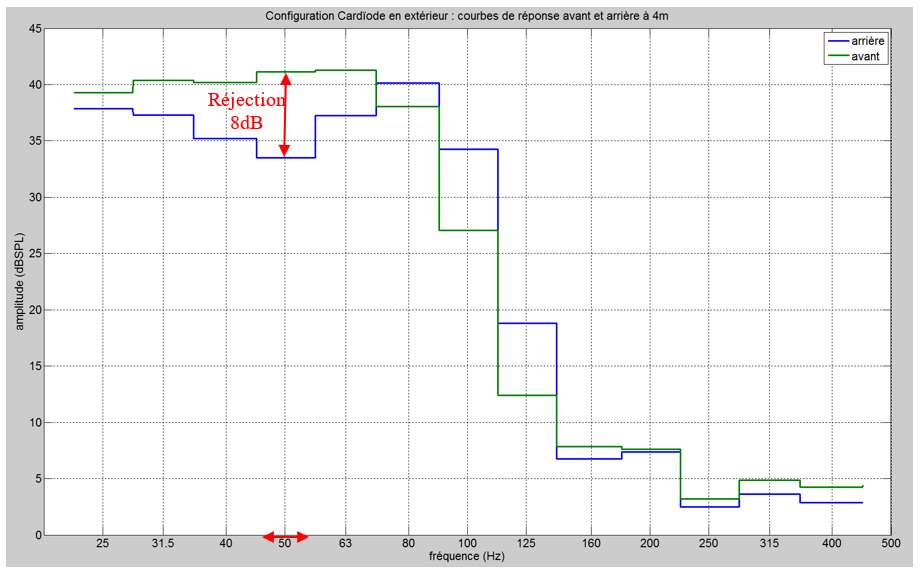
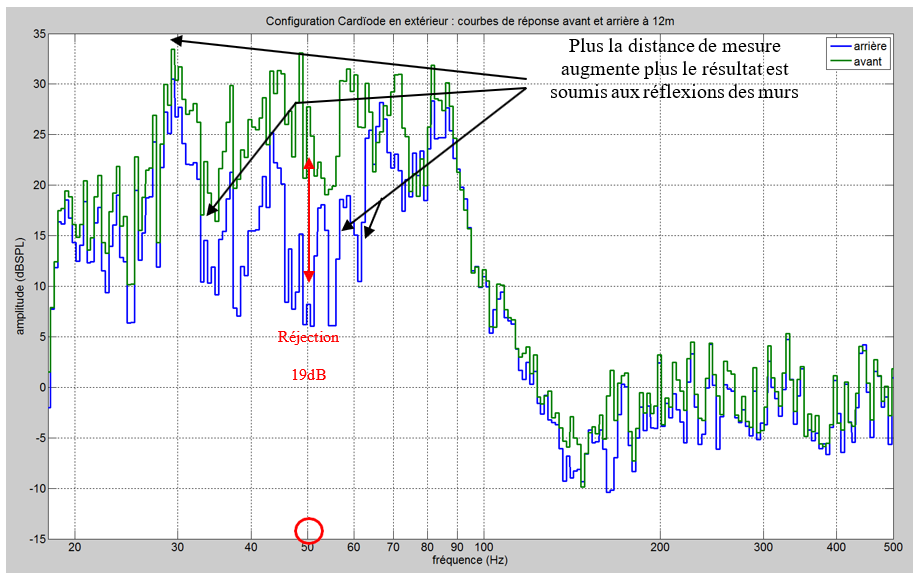
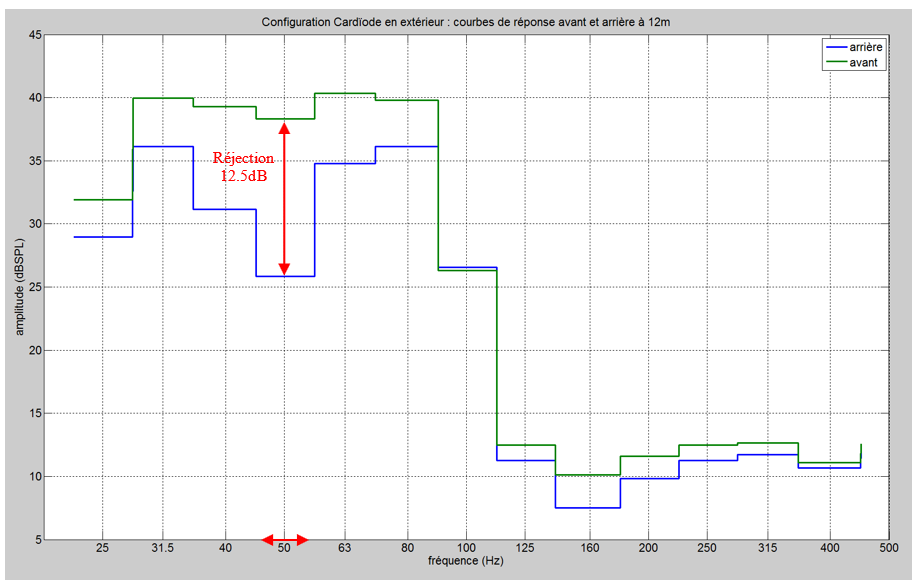
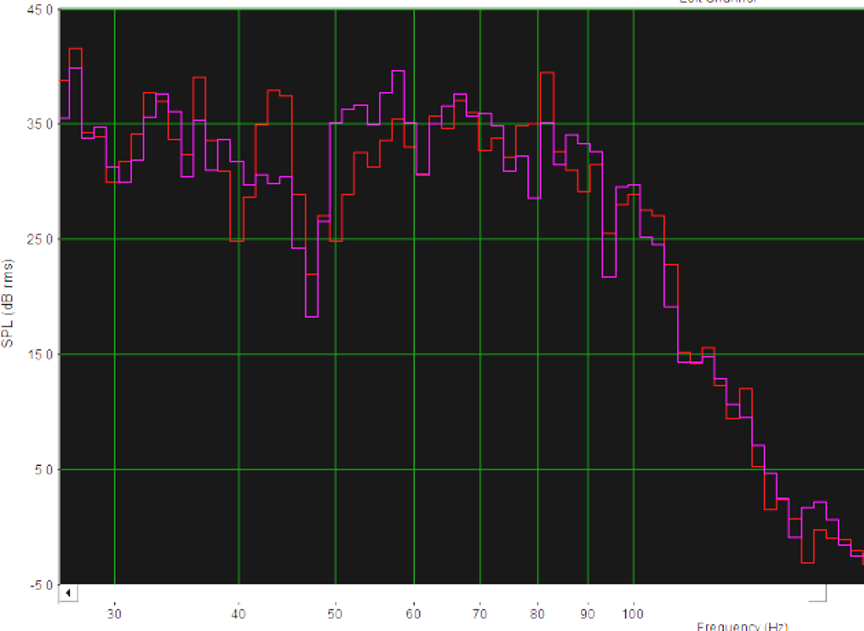
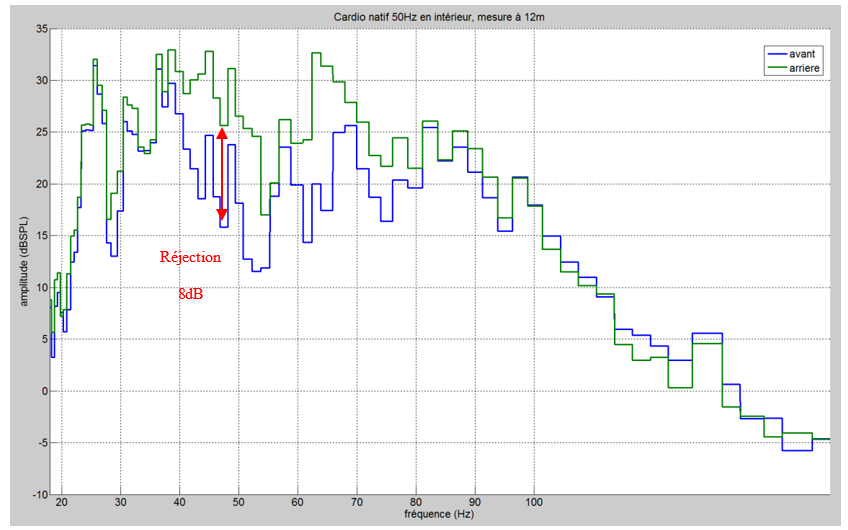
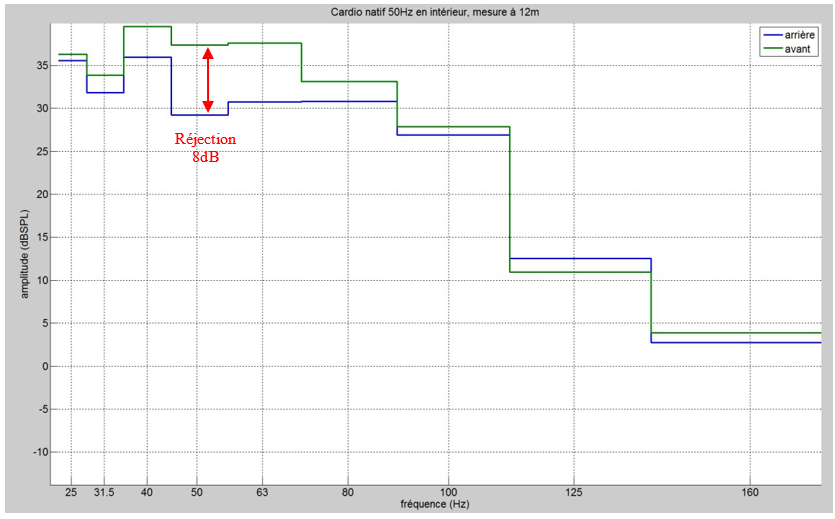

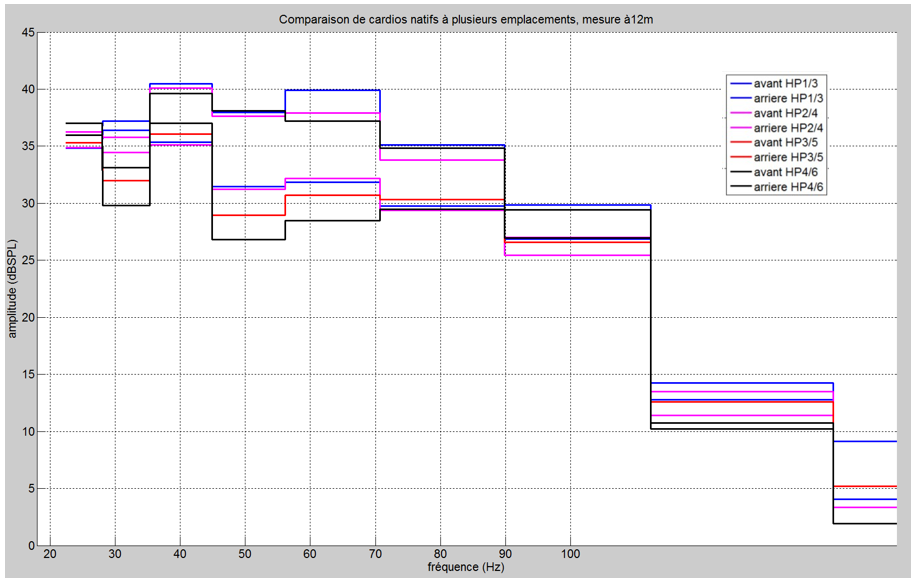
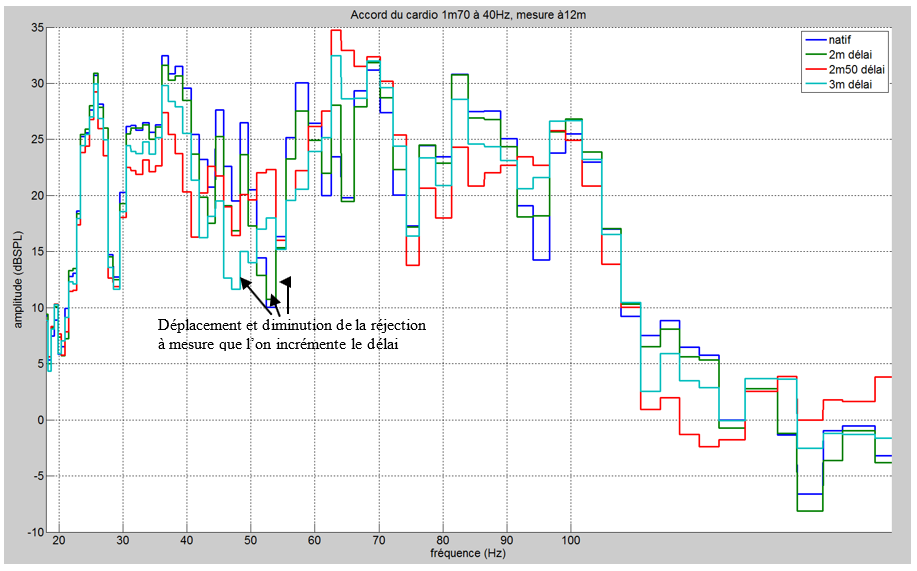
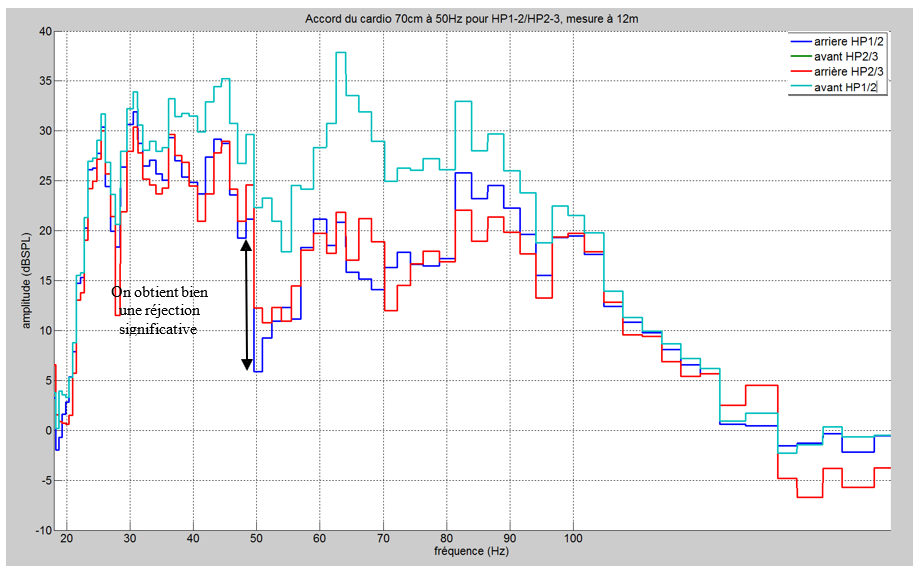

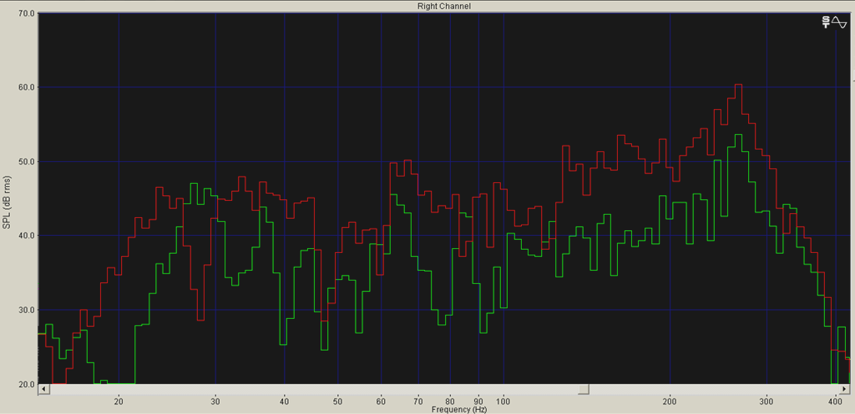
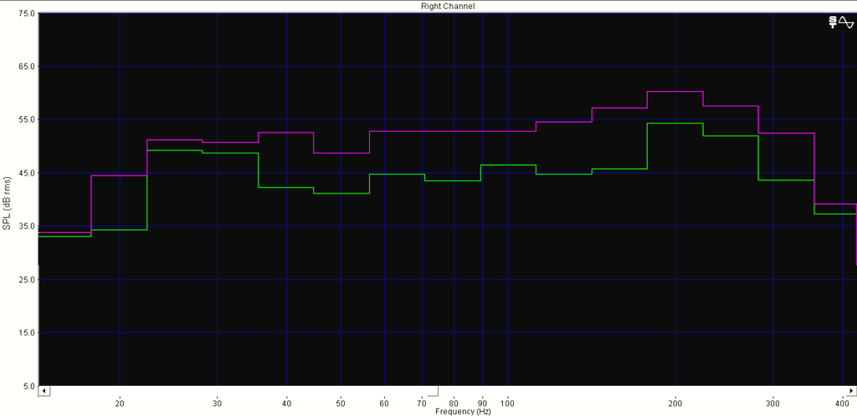
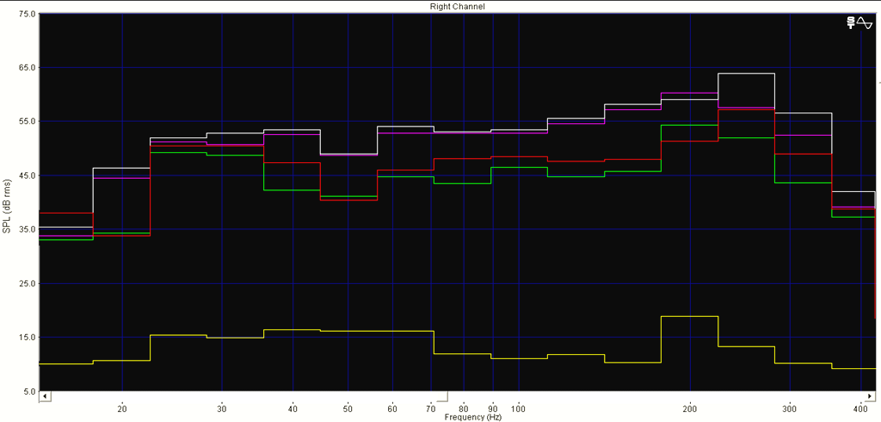
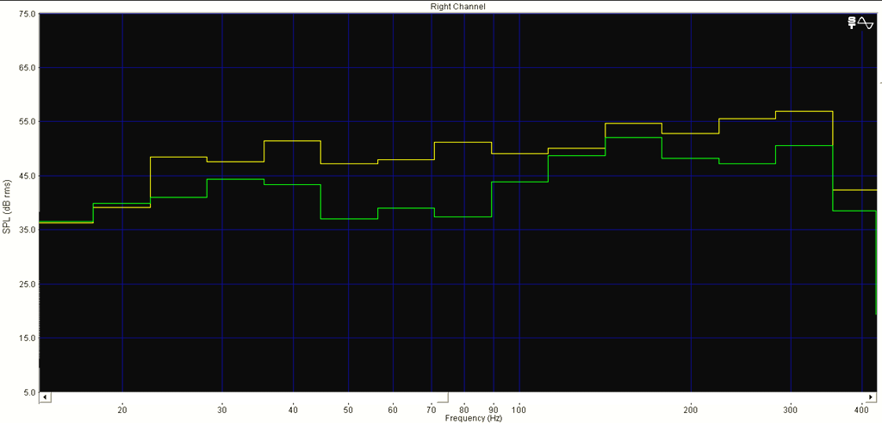

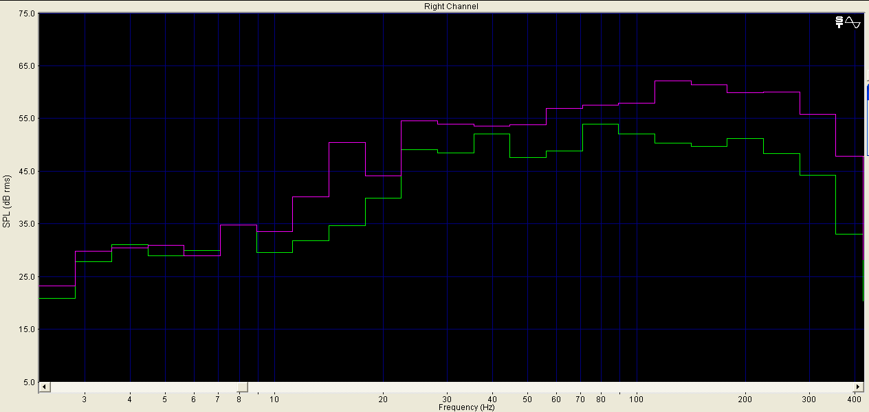

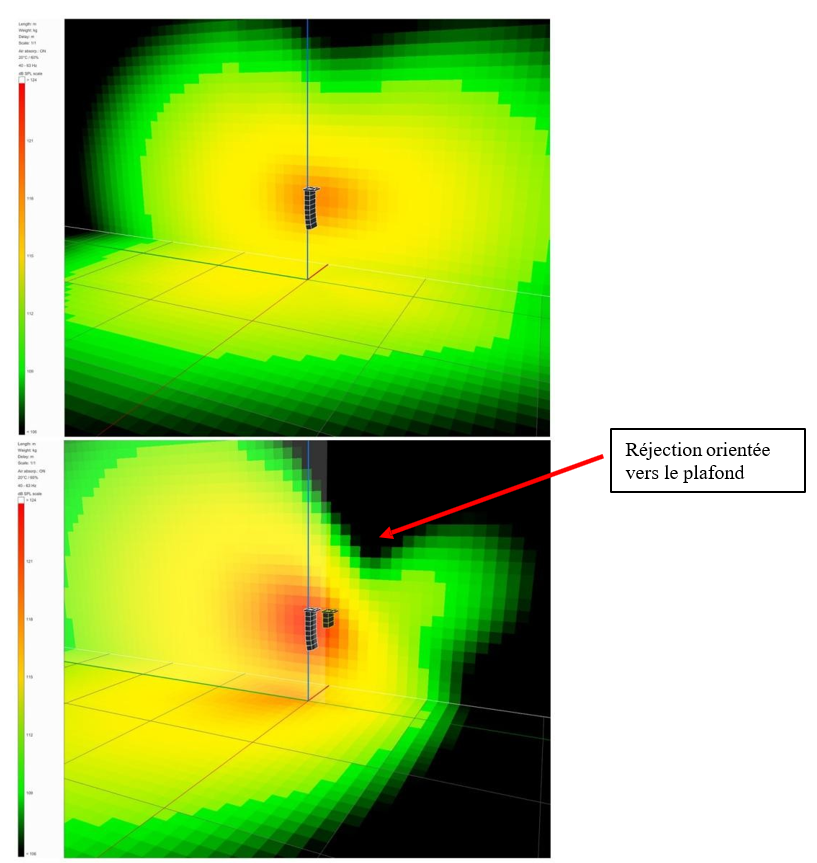

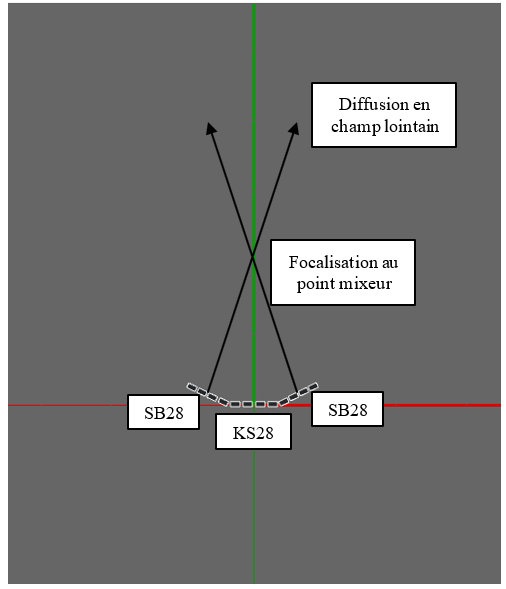

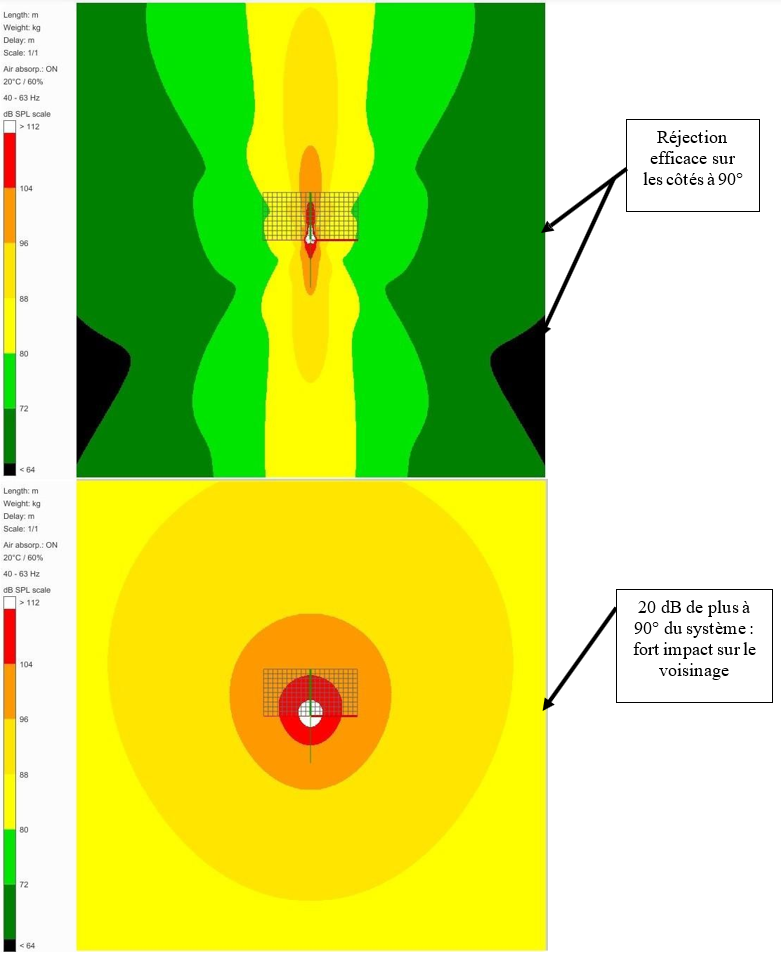
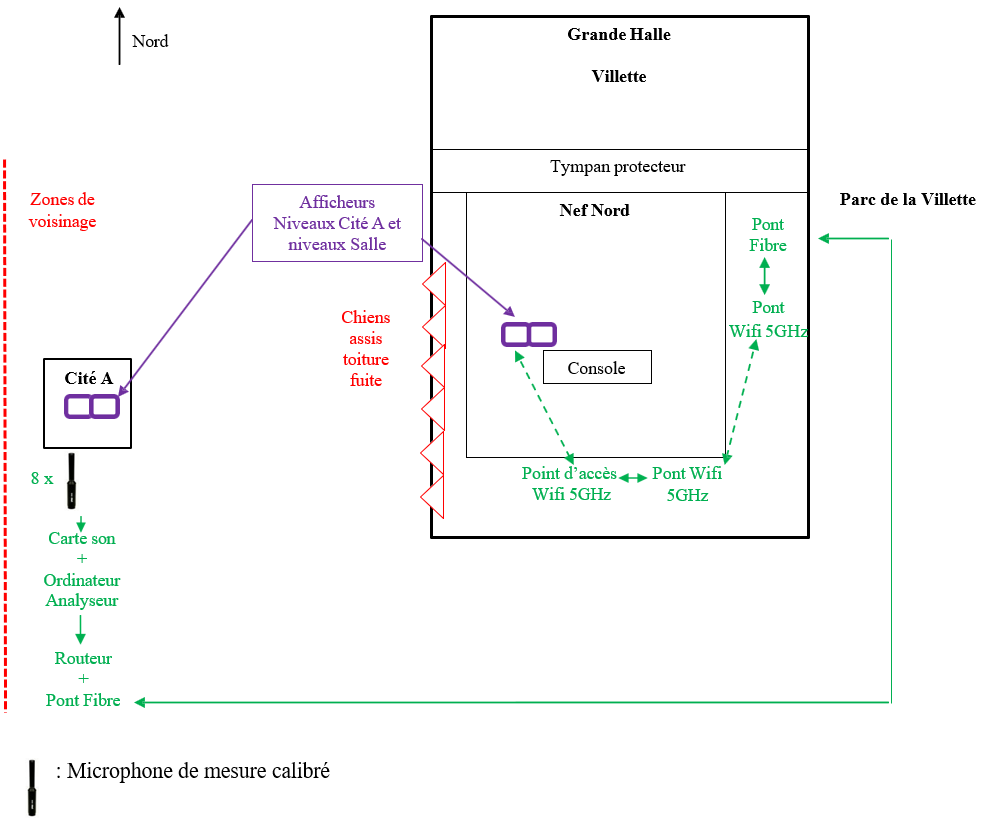

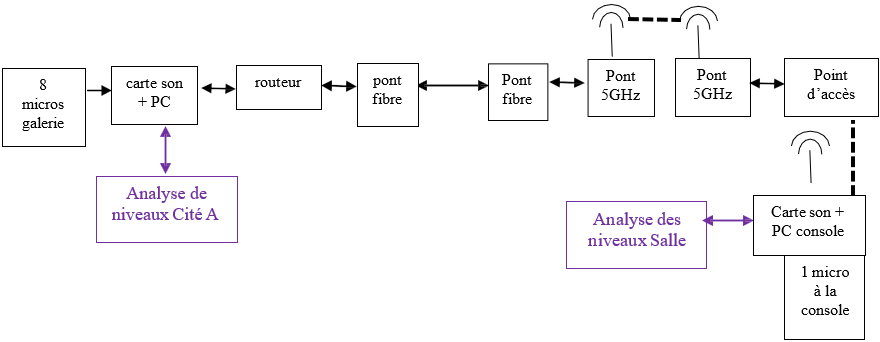
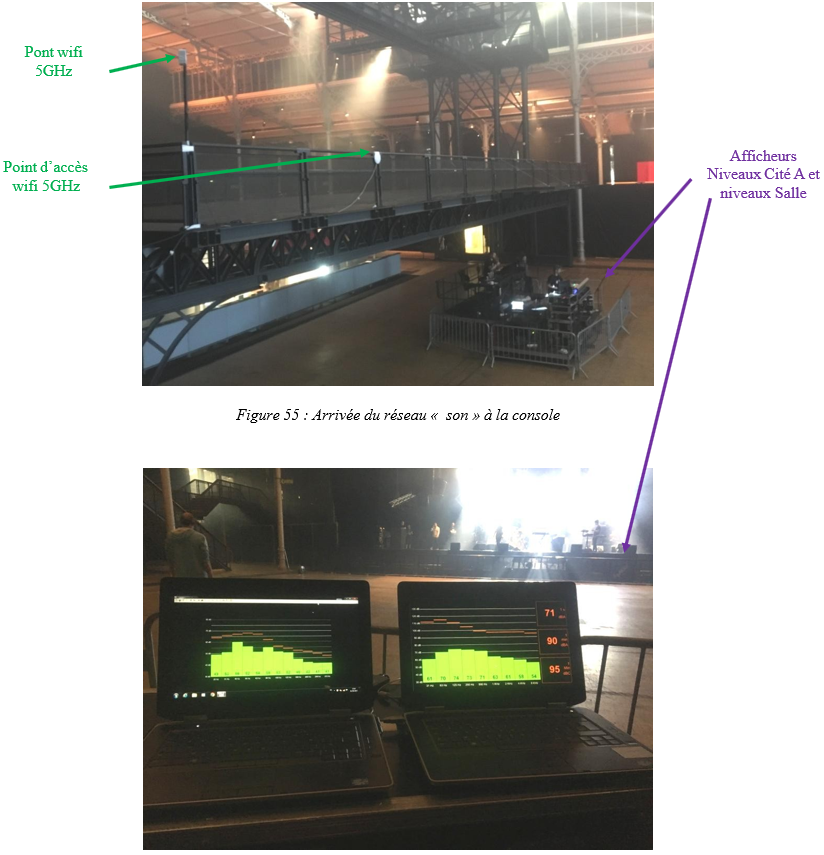
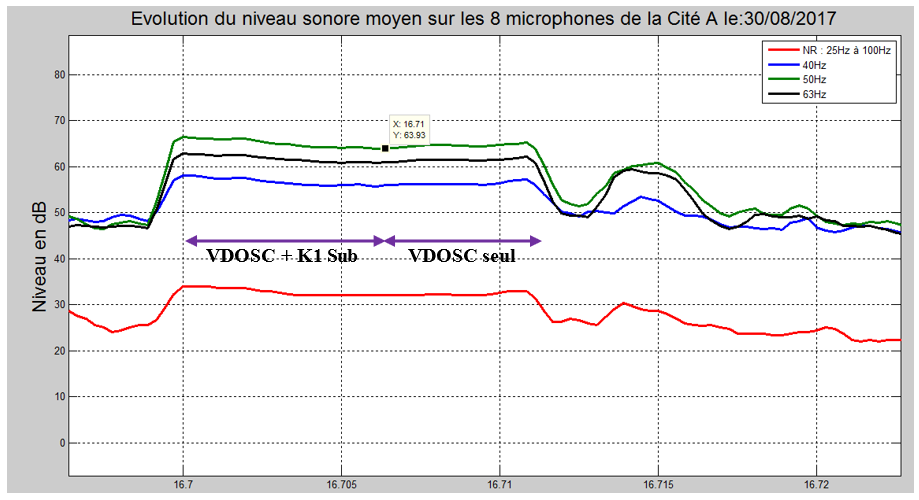
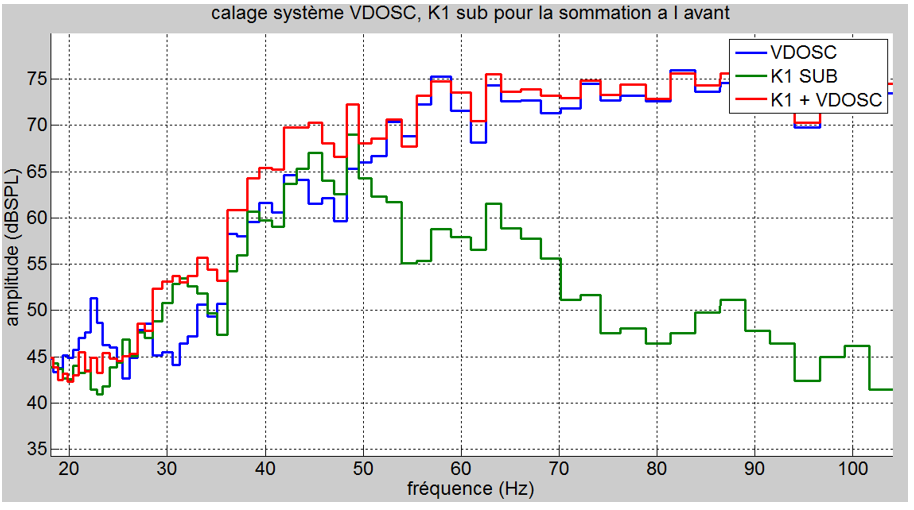
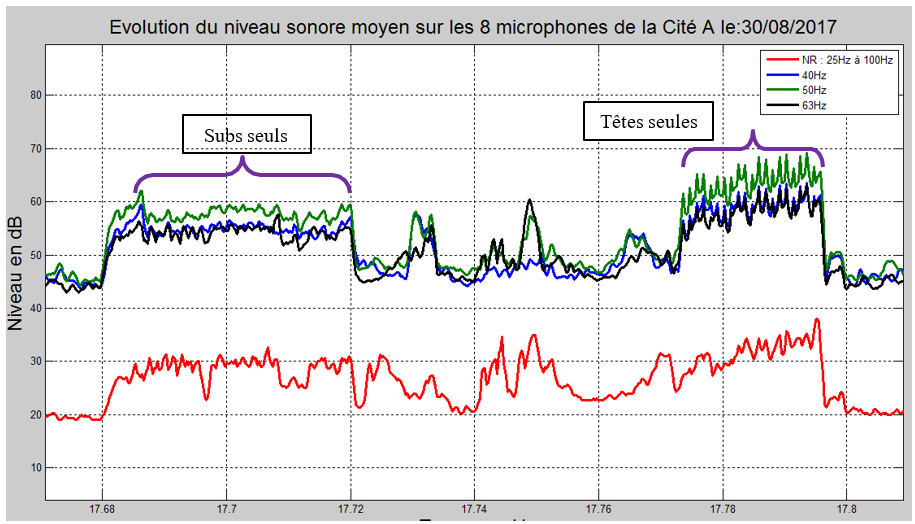
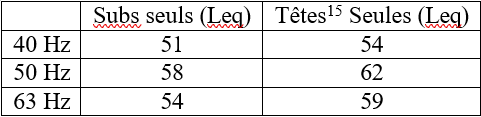
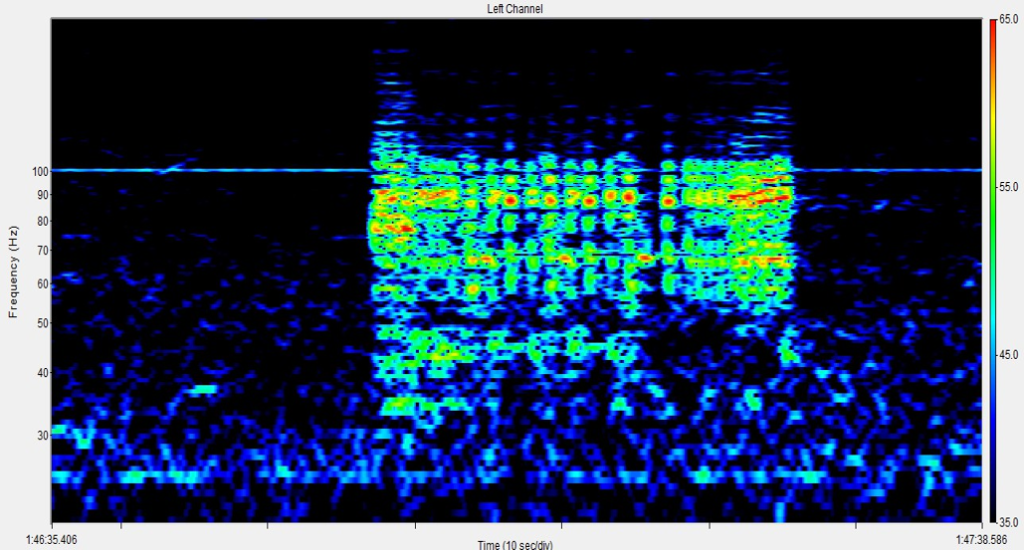
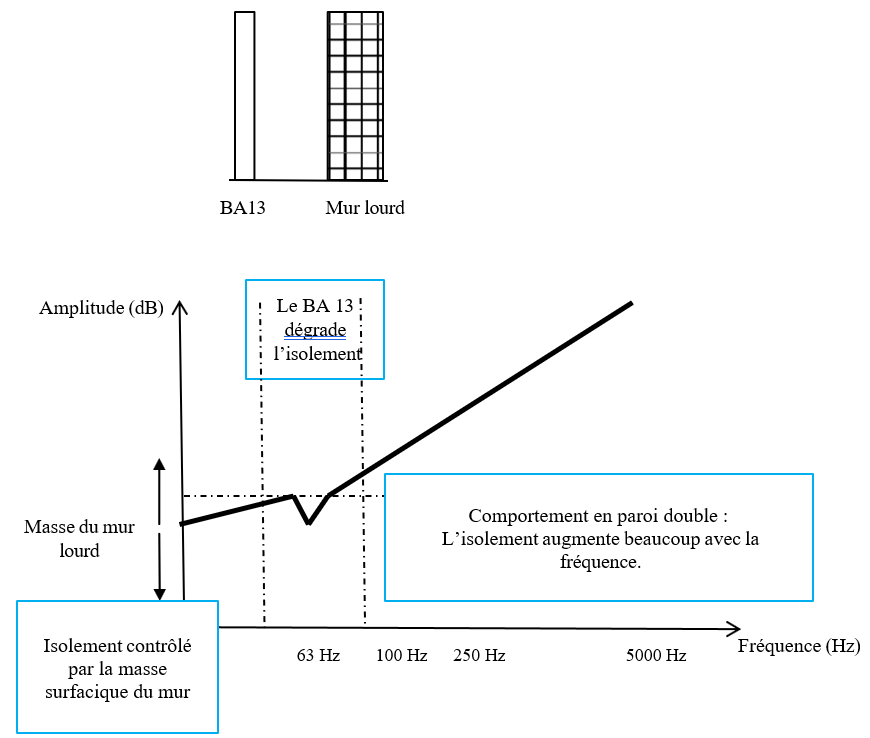

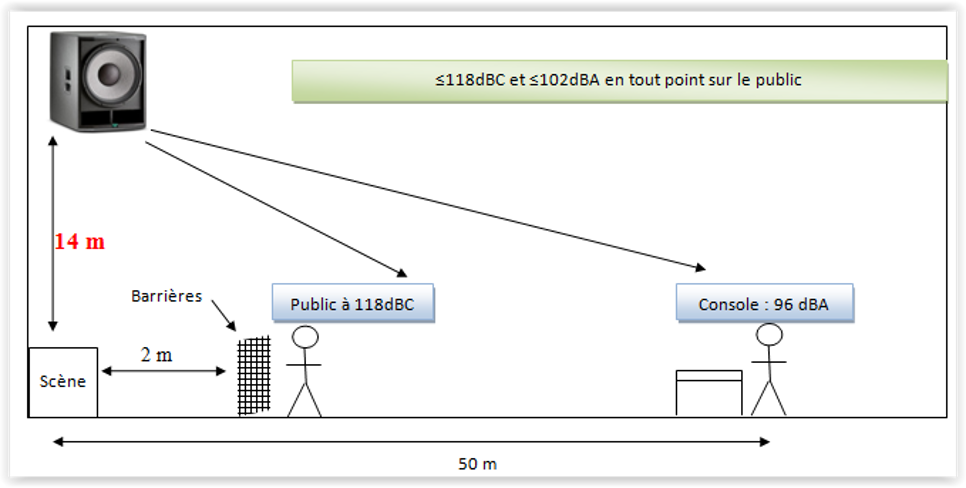
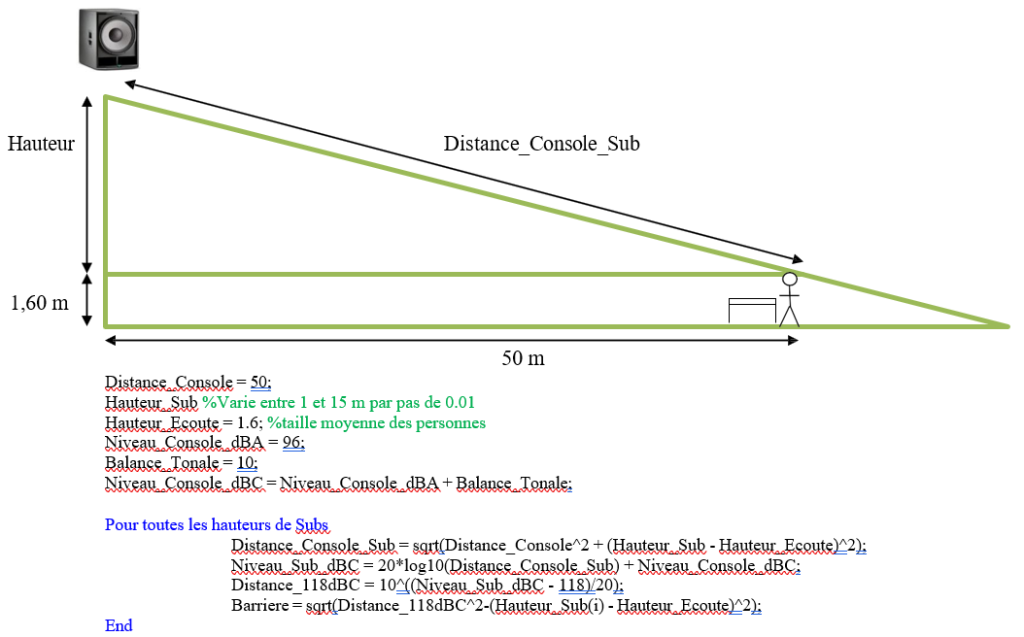
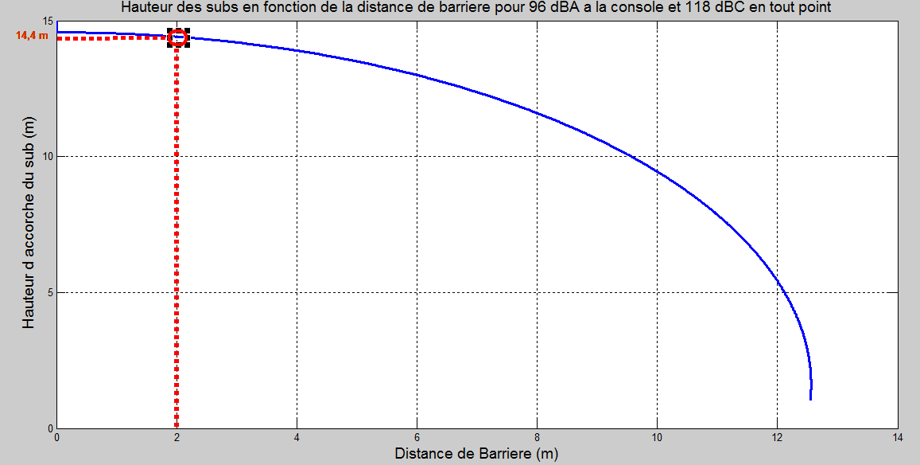
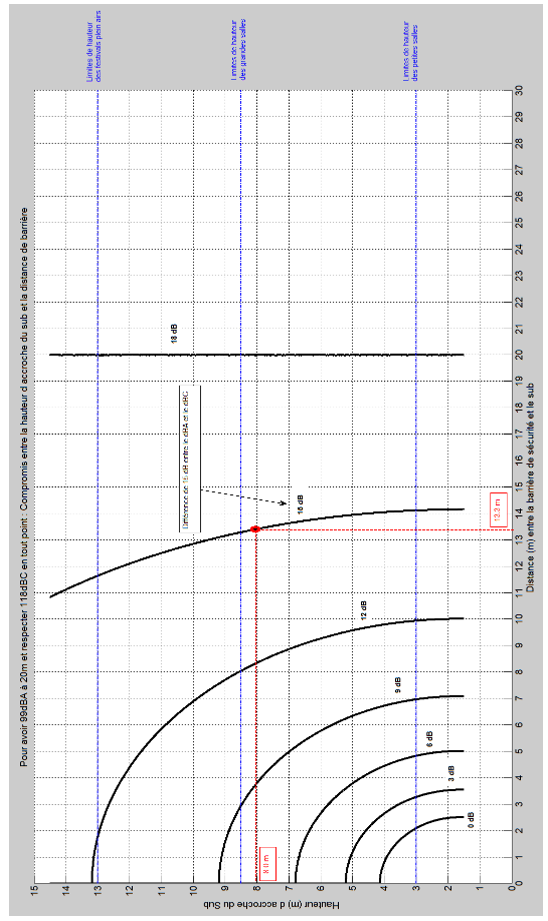

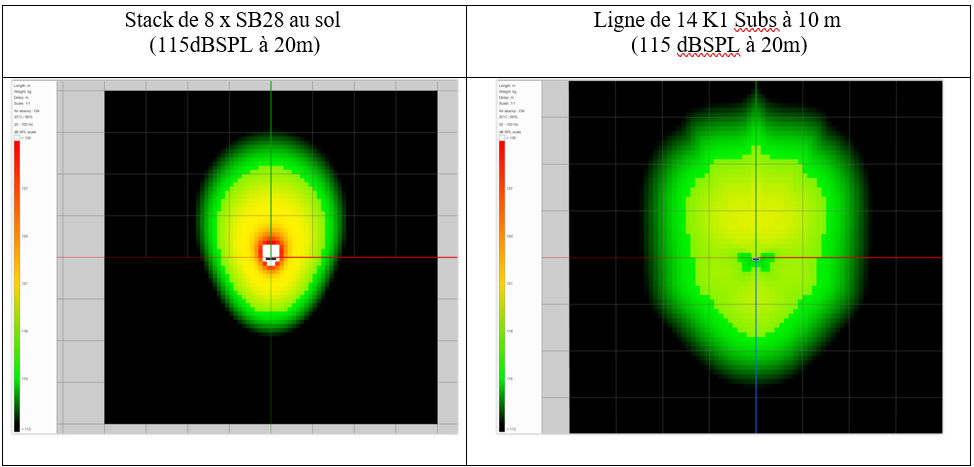
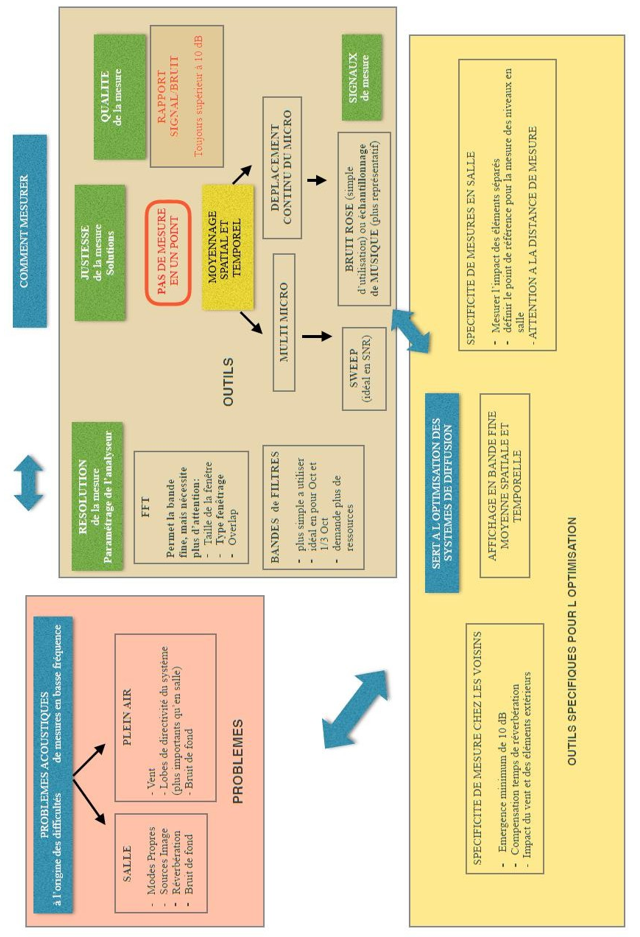
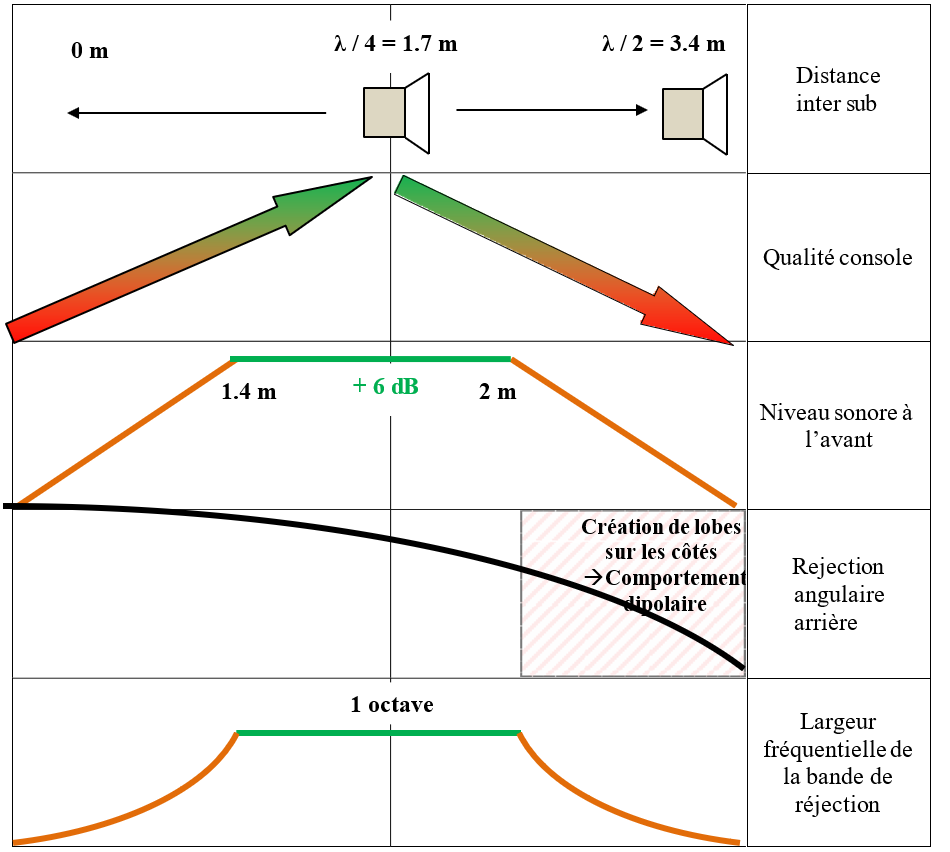
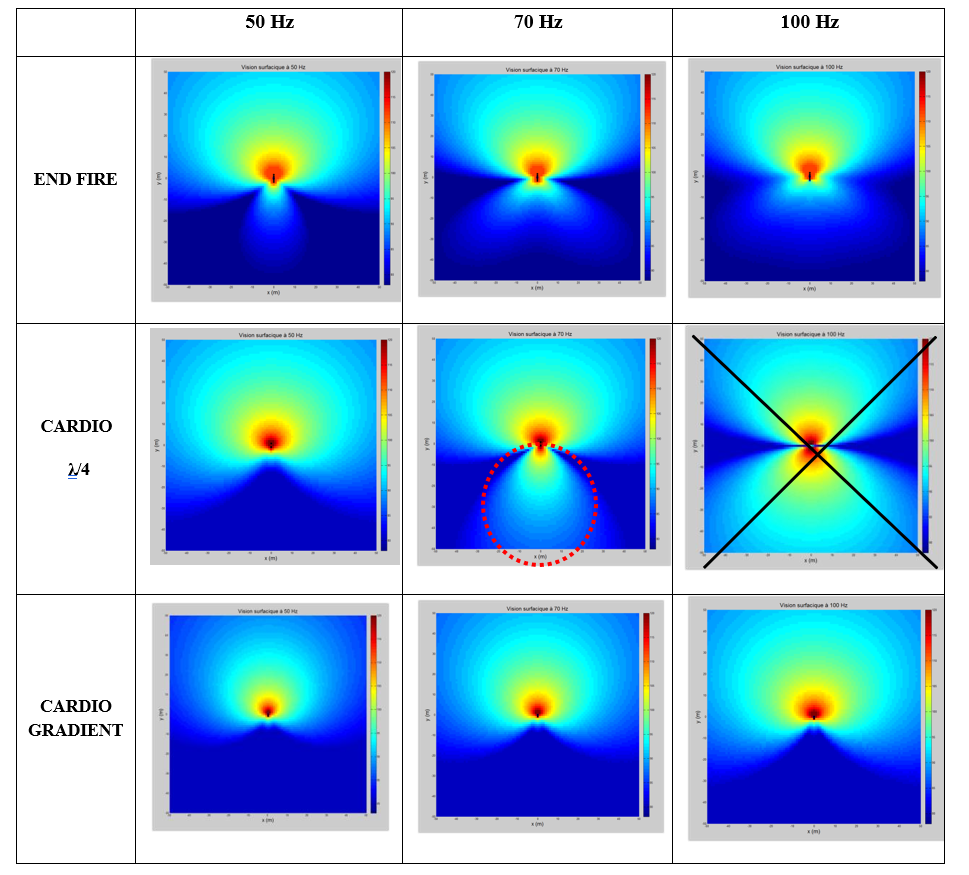
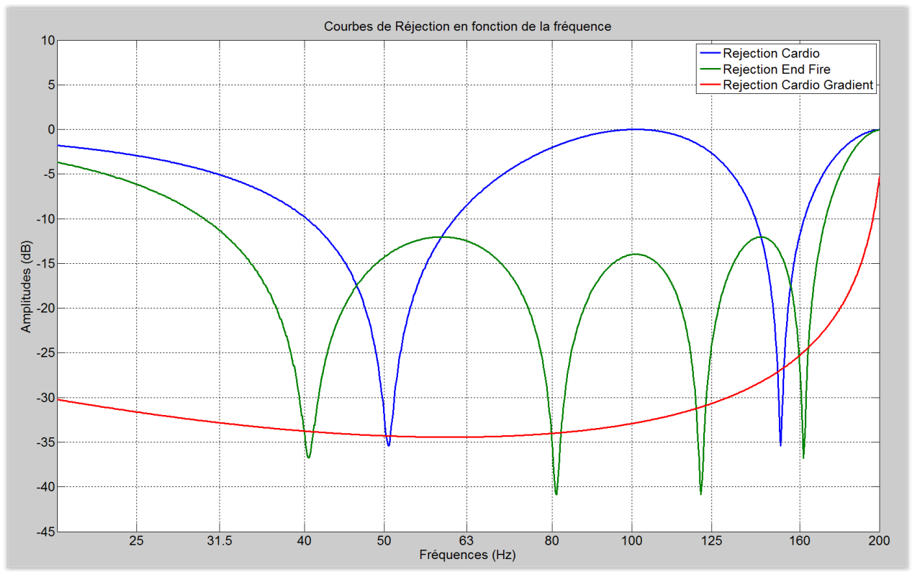
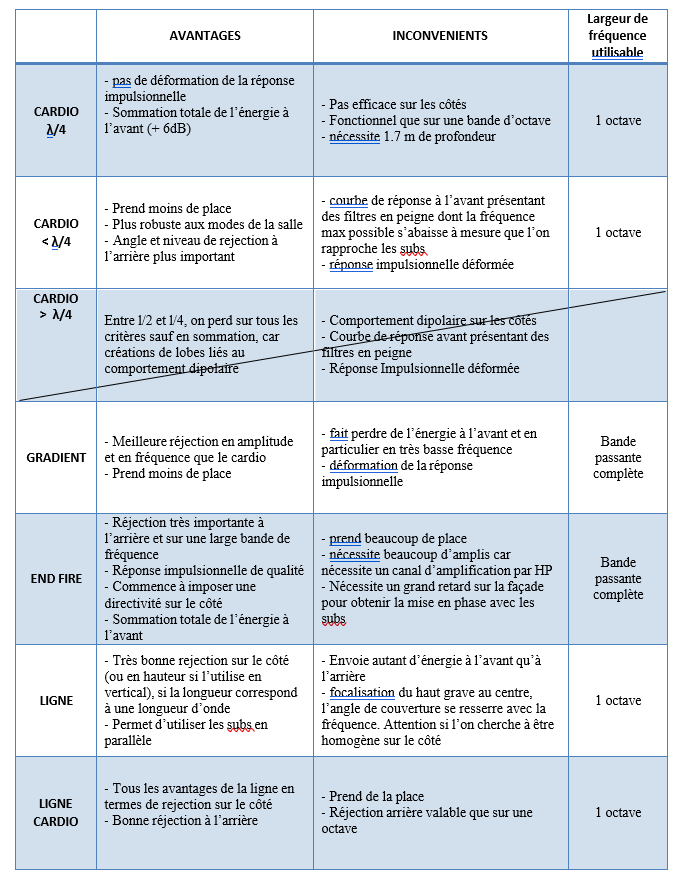
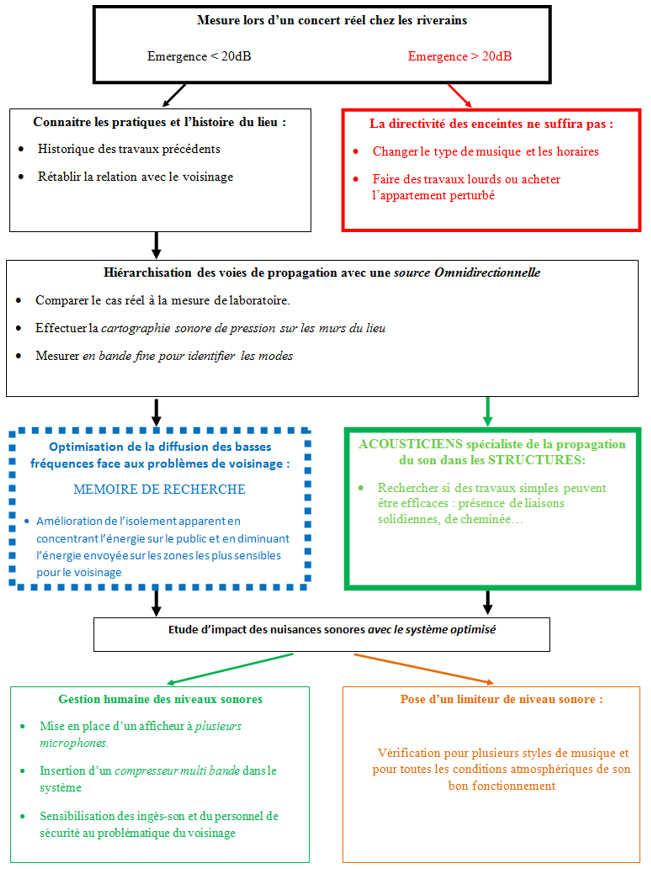
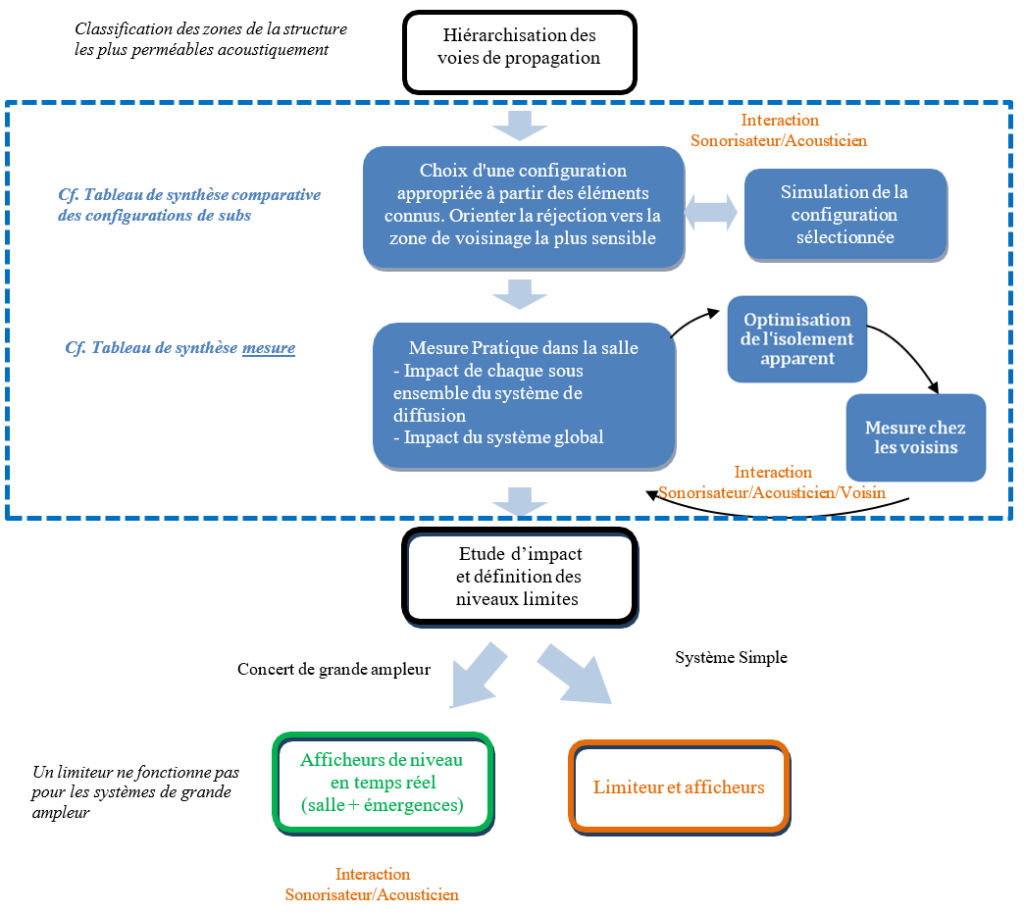
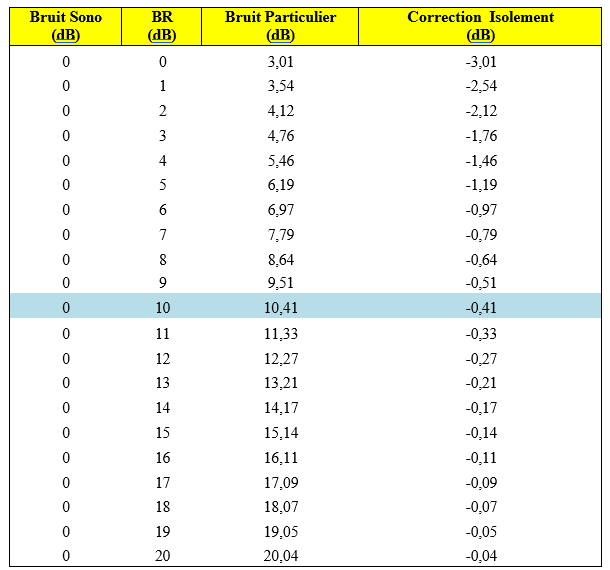
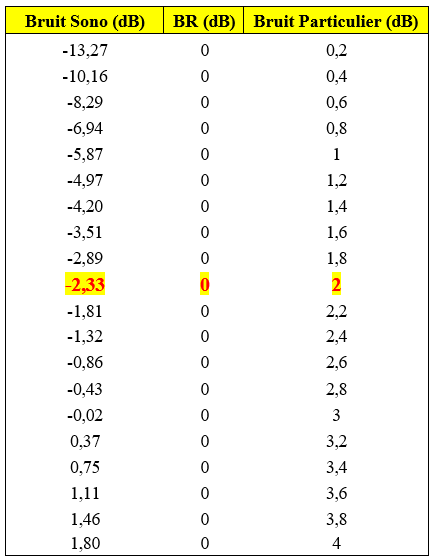
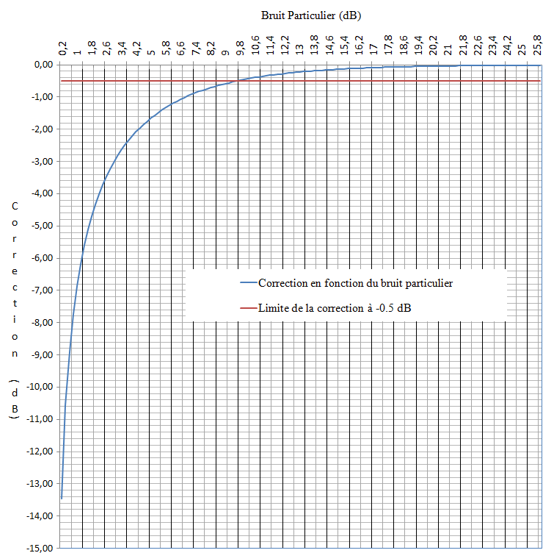

















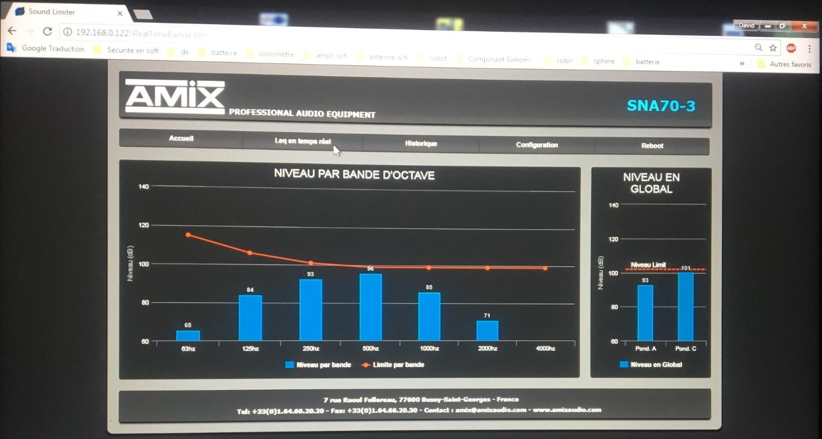

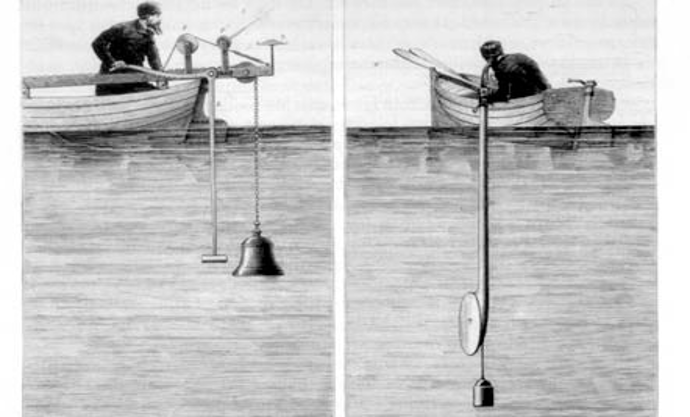
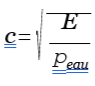
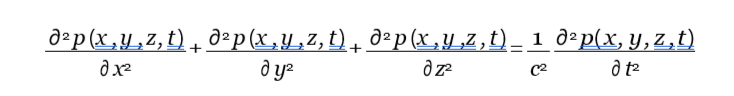
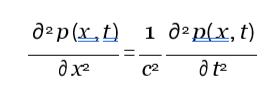
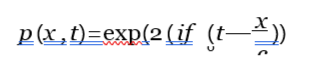
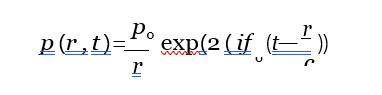
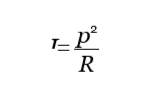
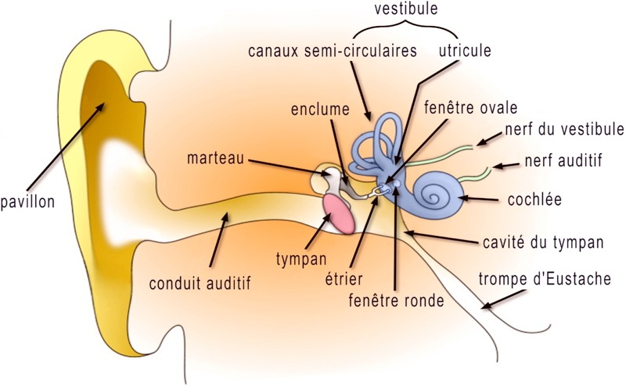
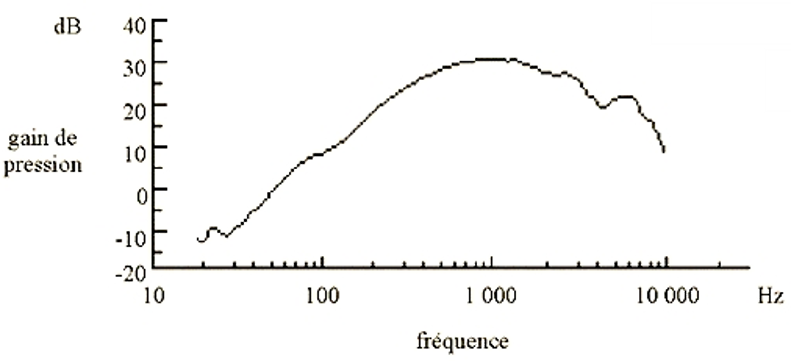
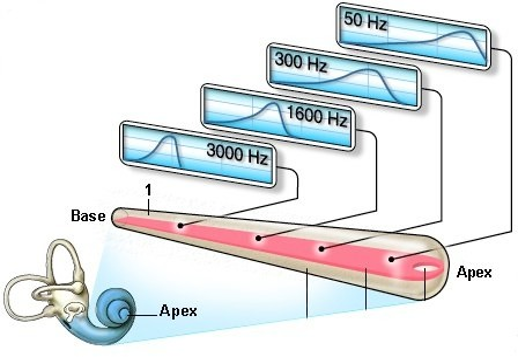
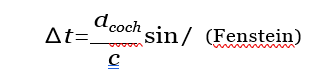
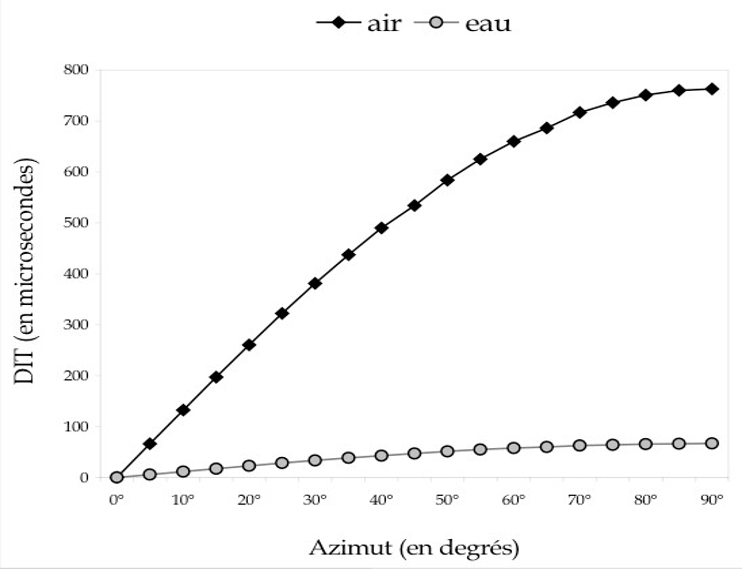

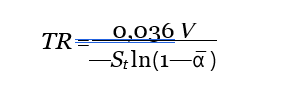








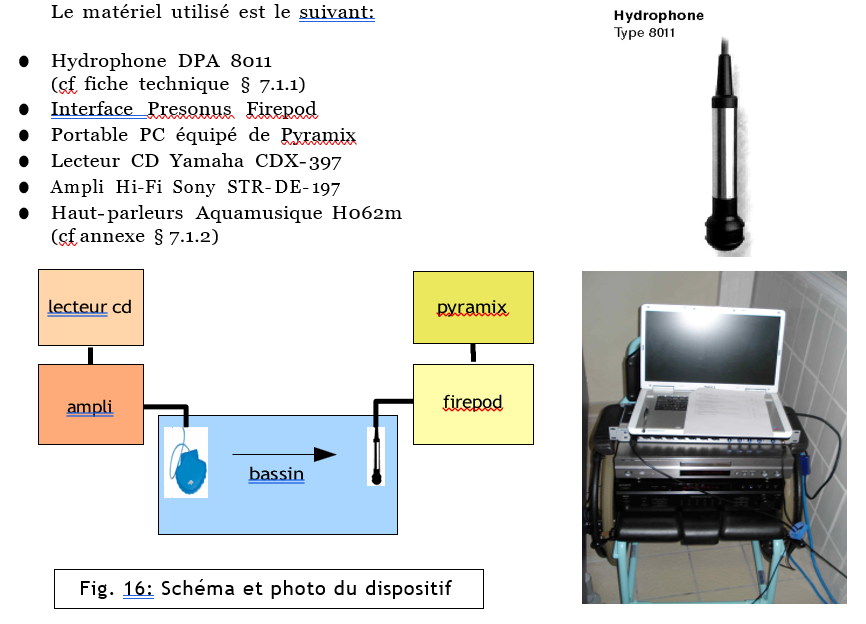
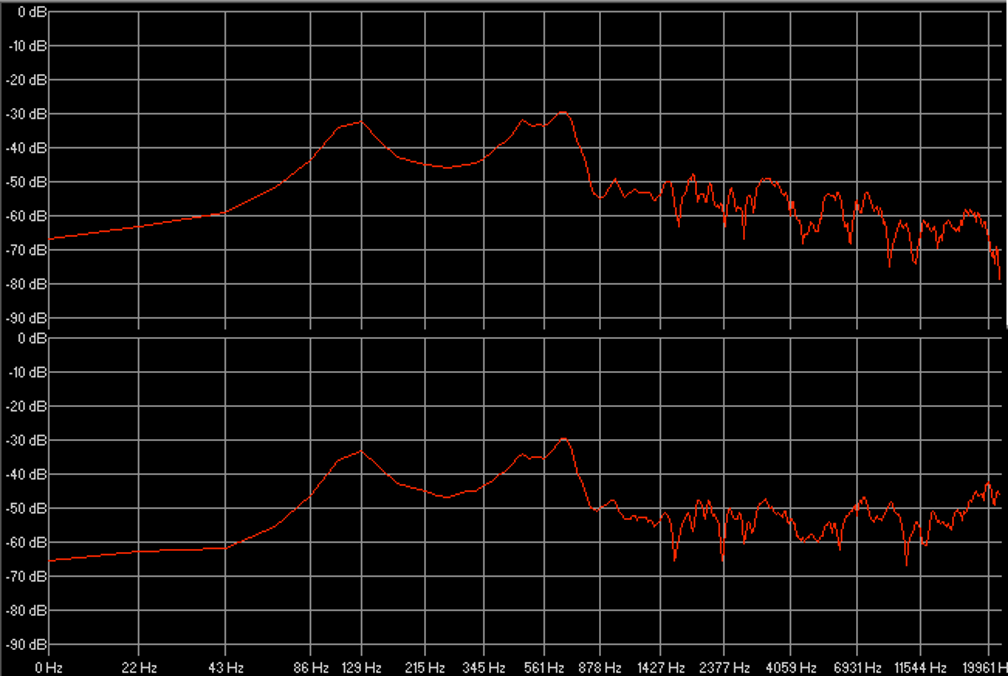
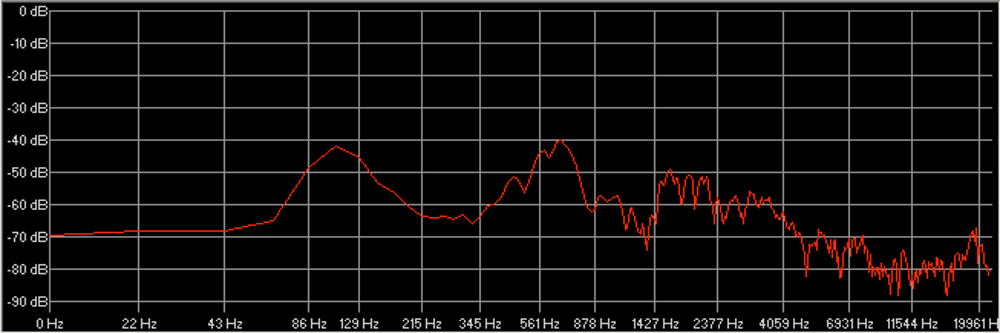
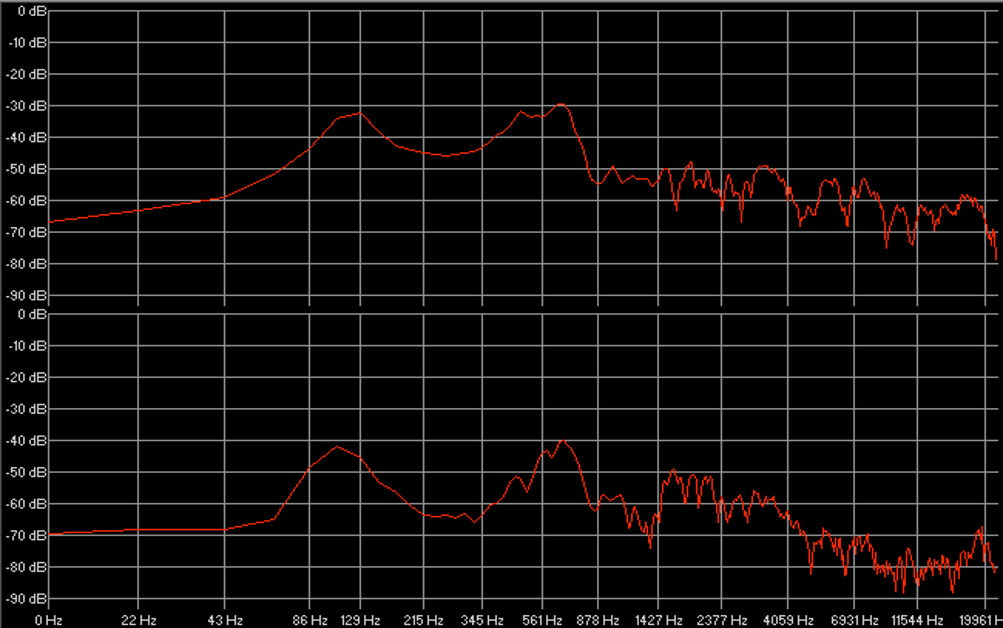

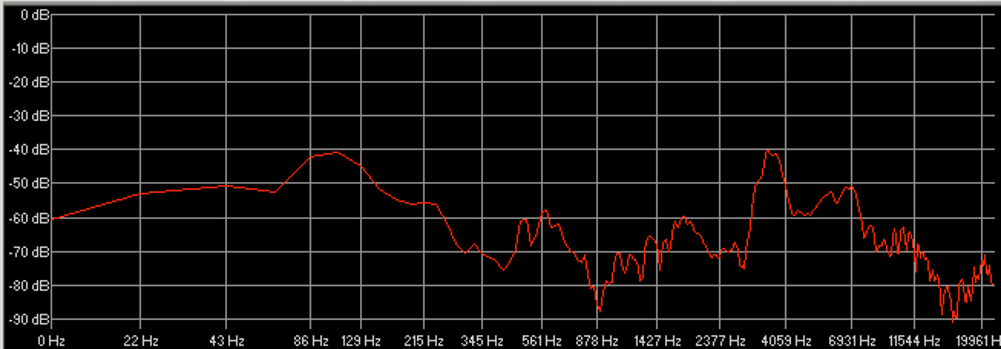
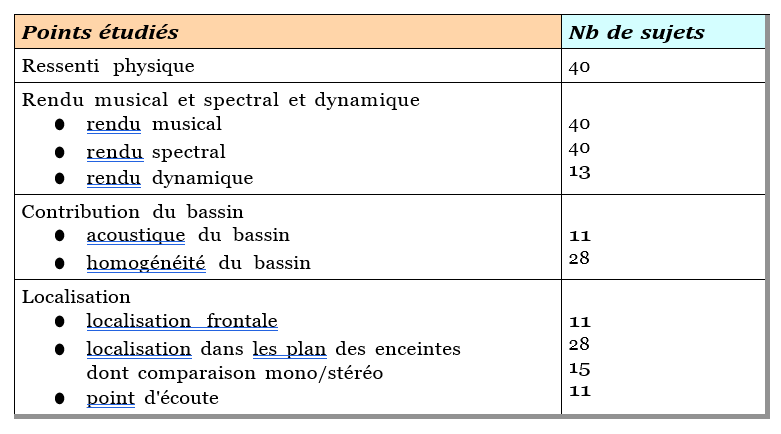
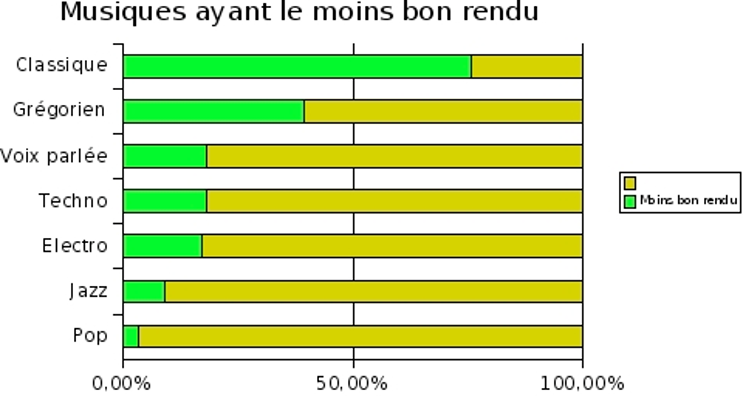
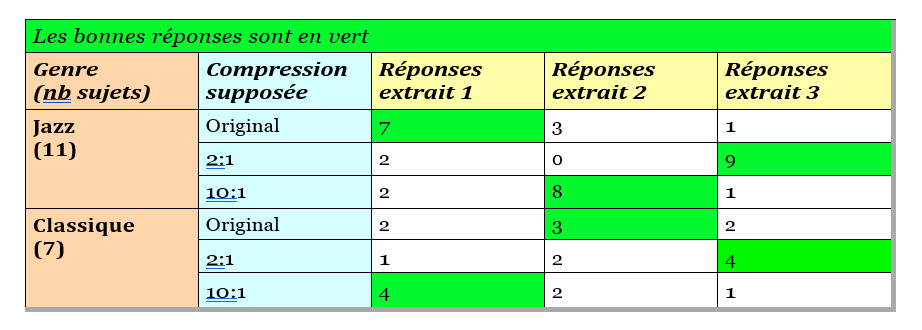



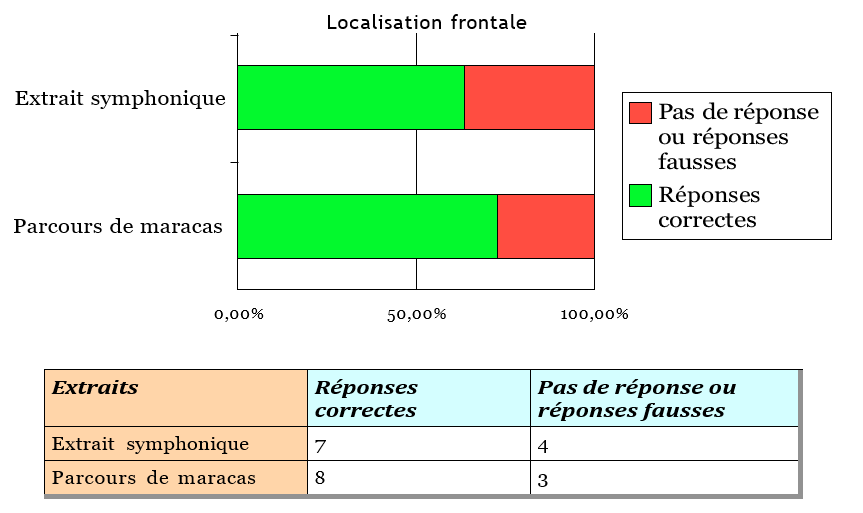

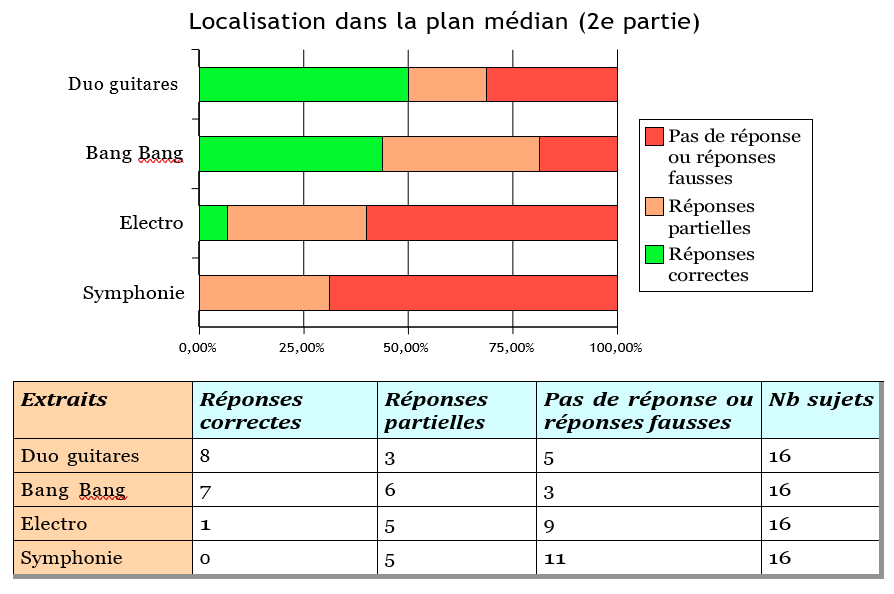

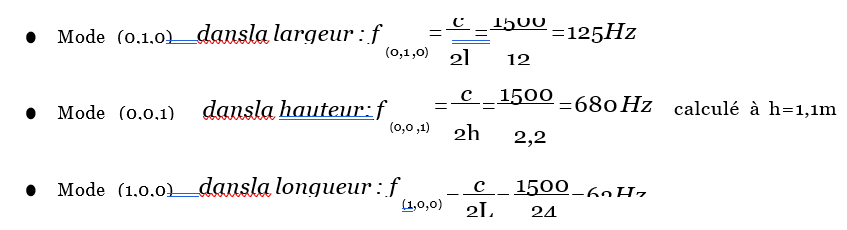

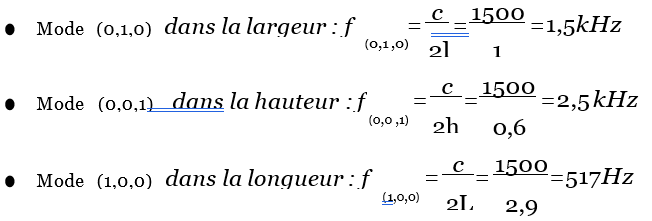
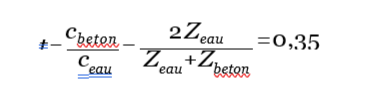




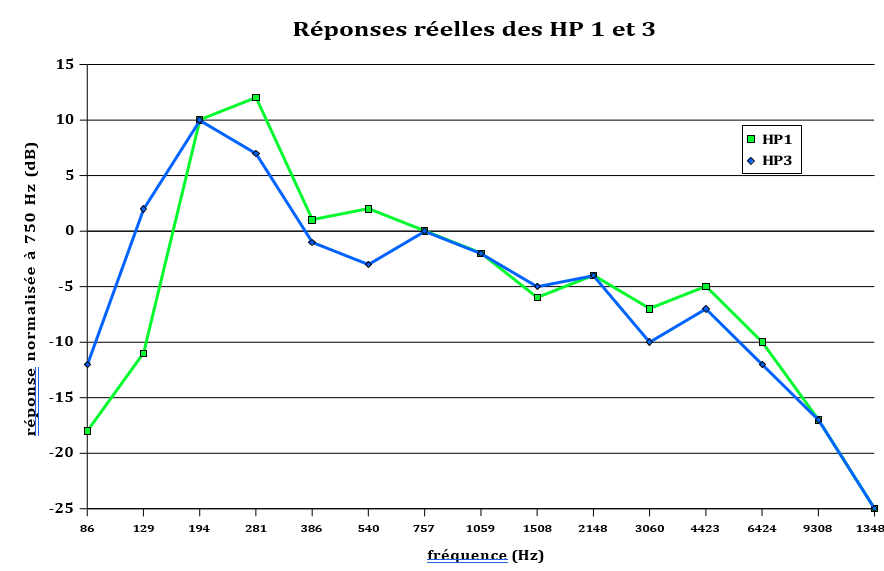






















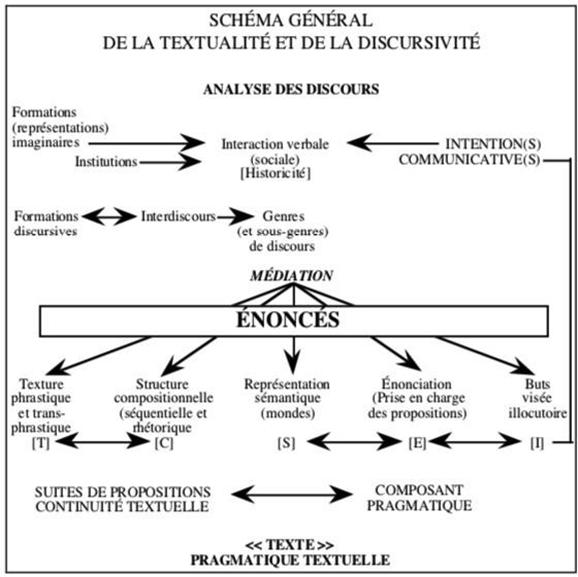





























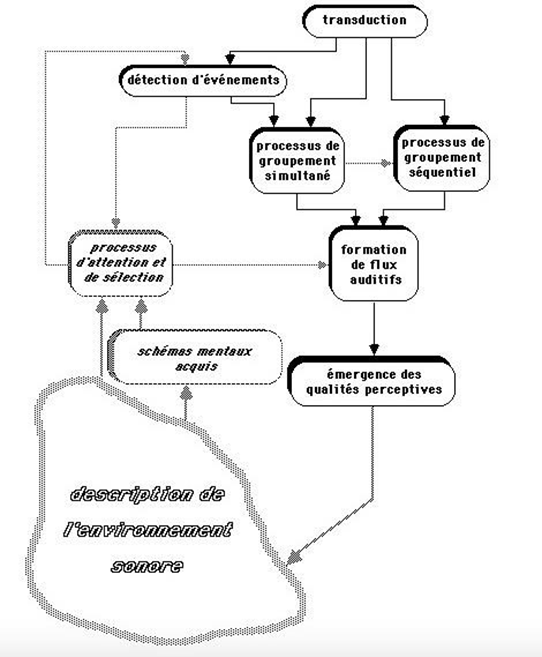
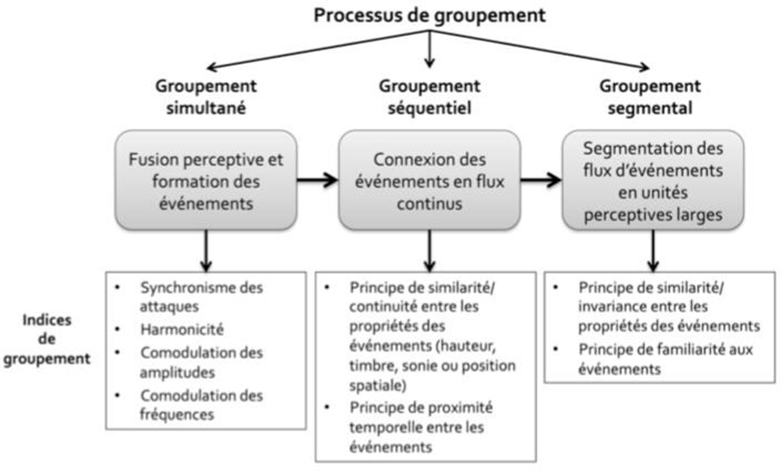







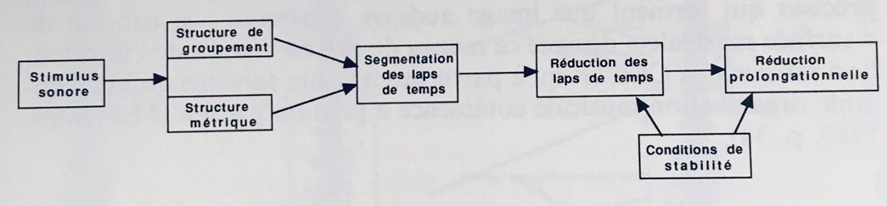
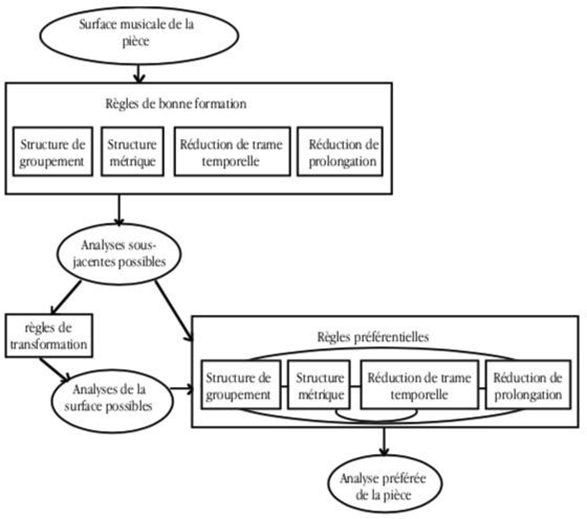

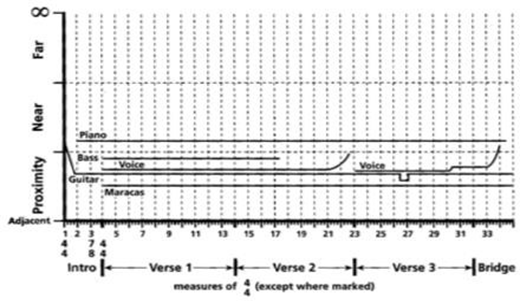
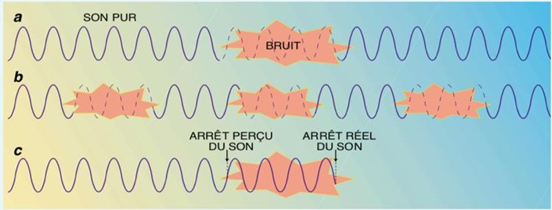
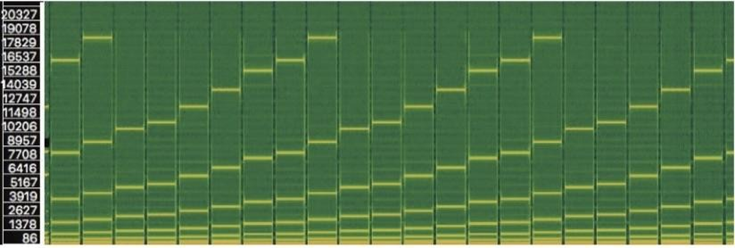


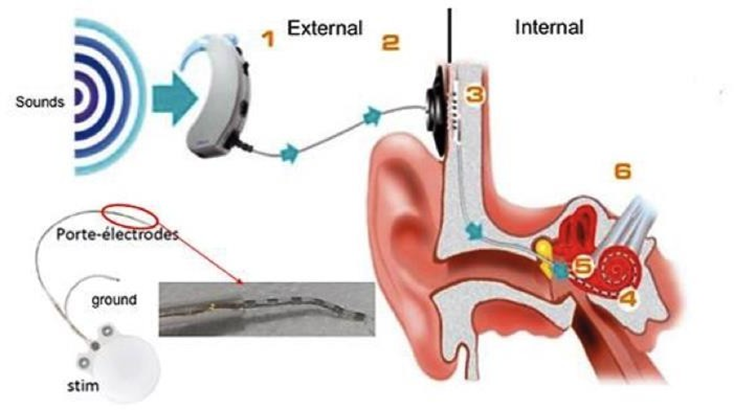








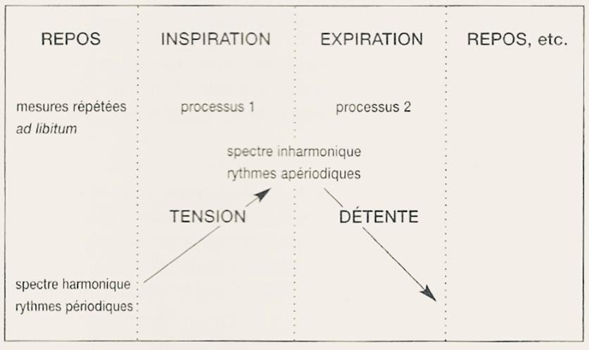



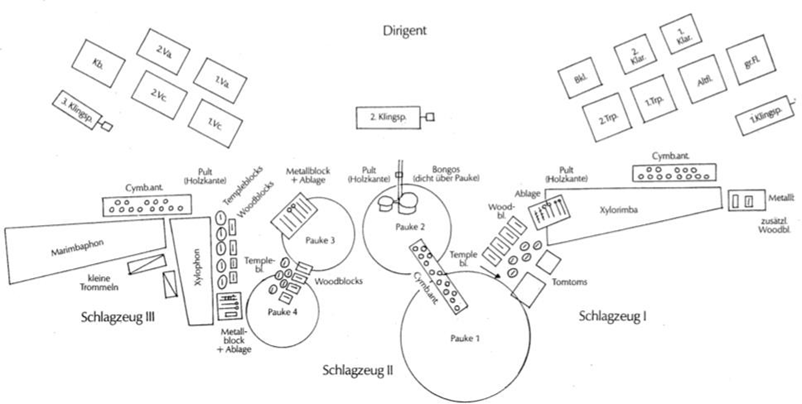



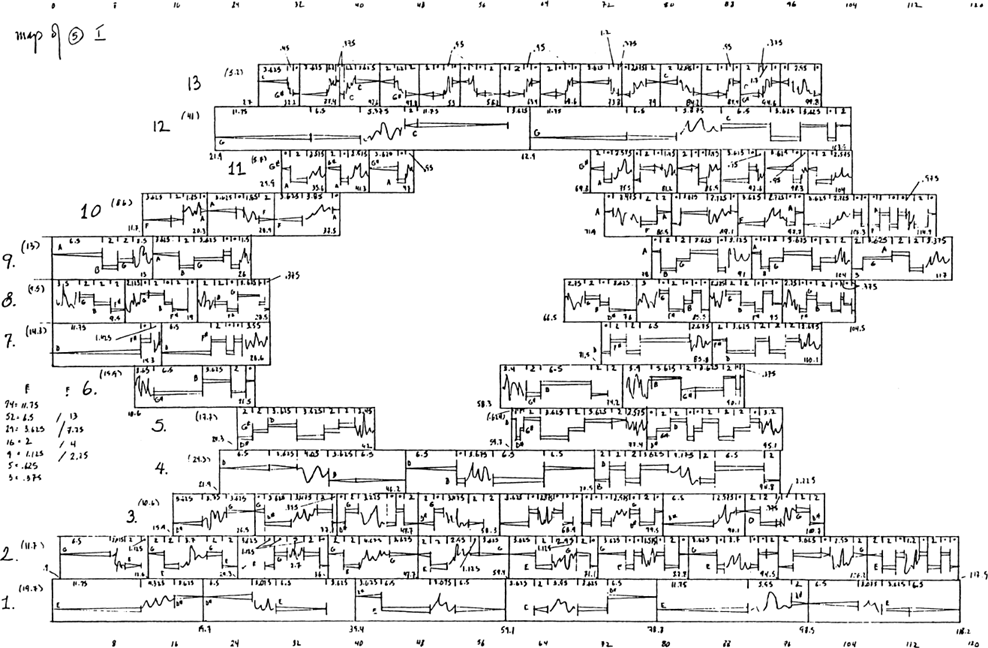
![Figure 102 : extrait de la partition Symphony [Myths] de Roger Reynolds, éditions Peters.](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-506-607x1024.png)
![Figure 103 : Symphony [Myths], de la mesure 1 à 51.](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-40.jpeg)





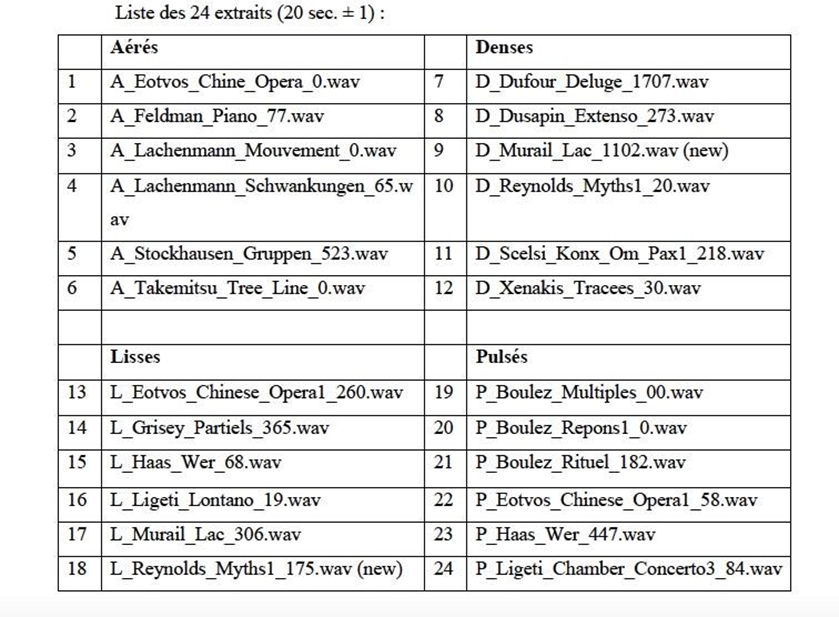

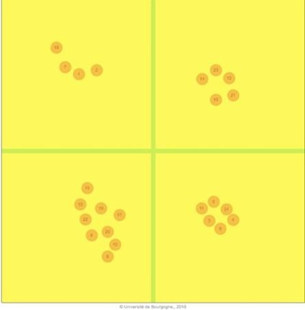
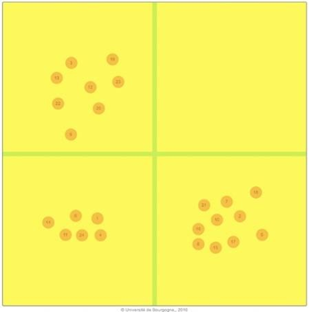
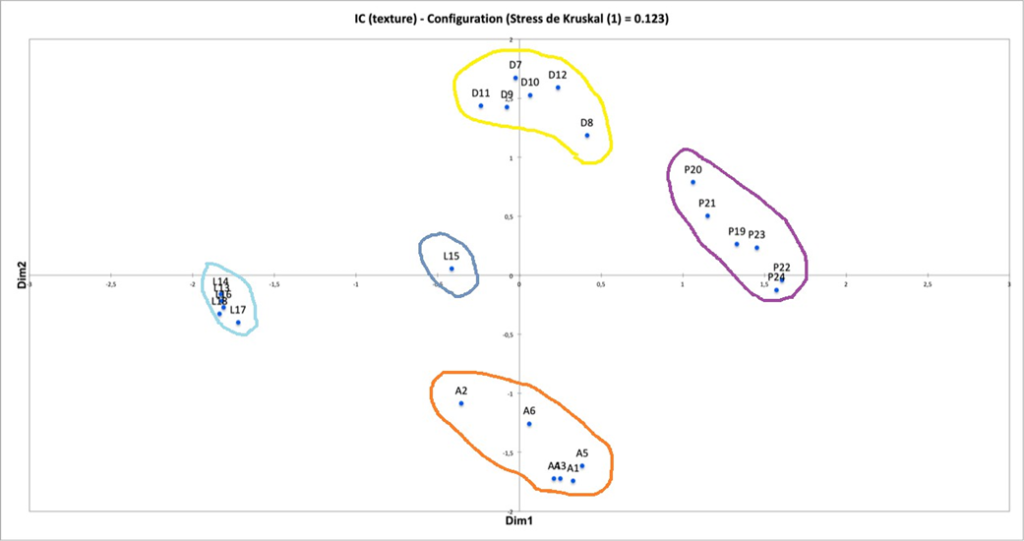
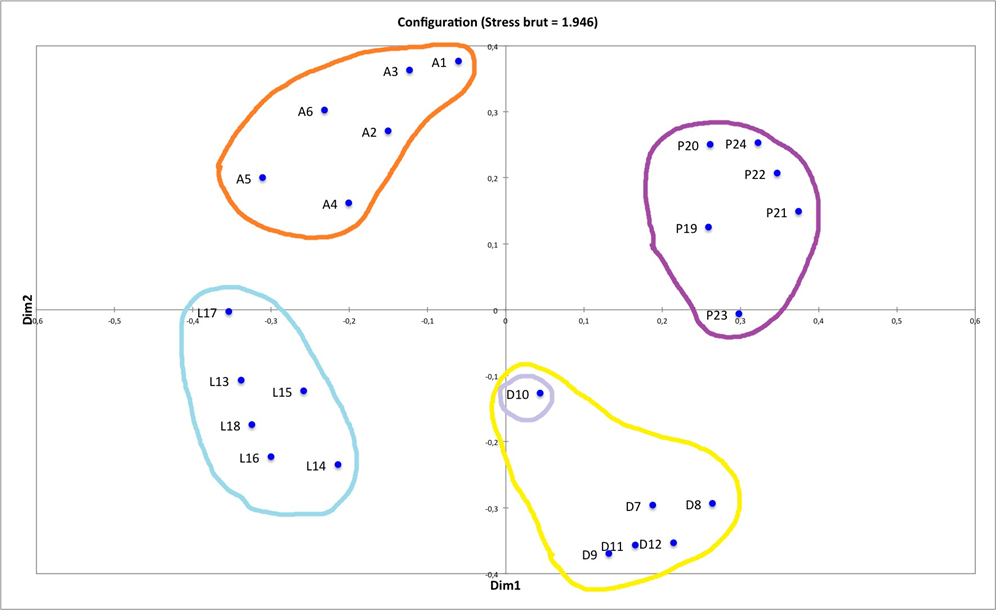
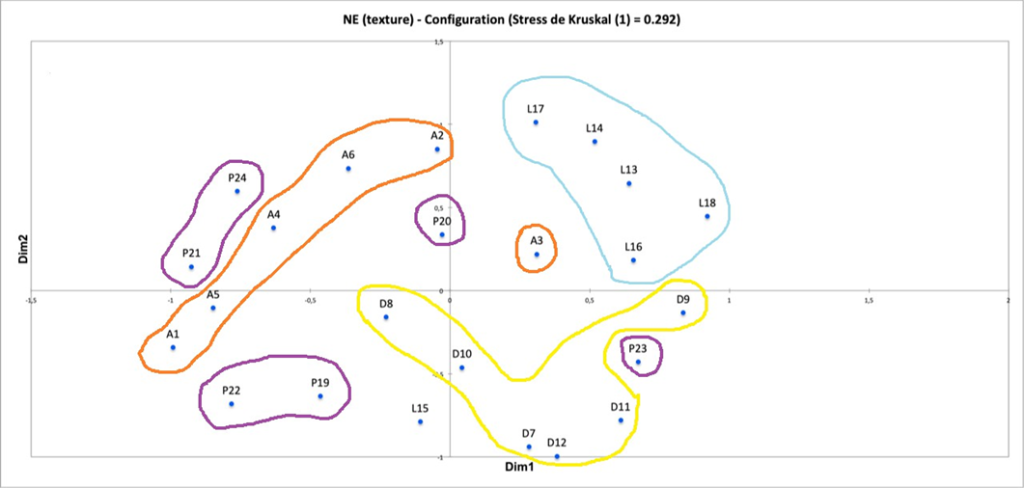
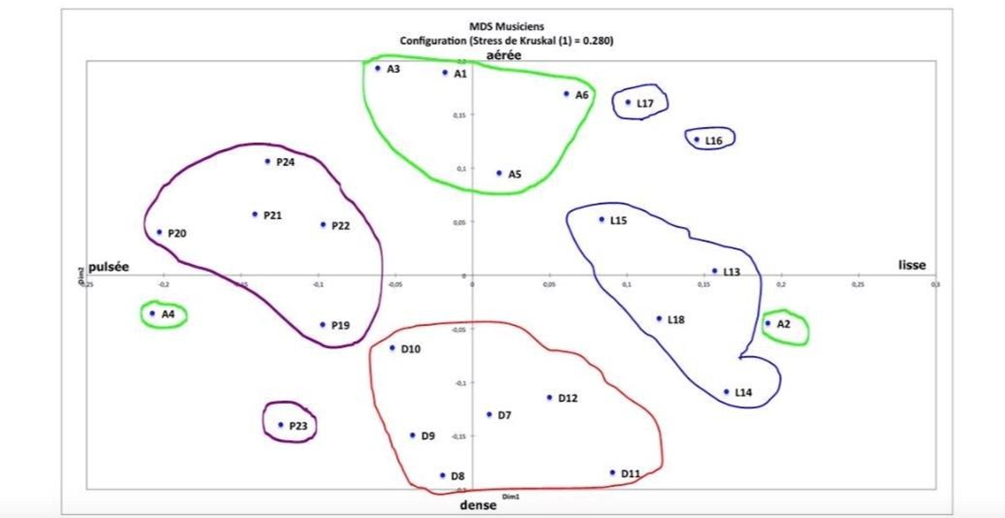
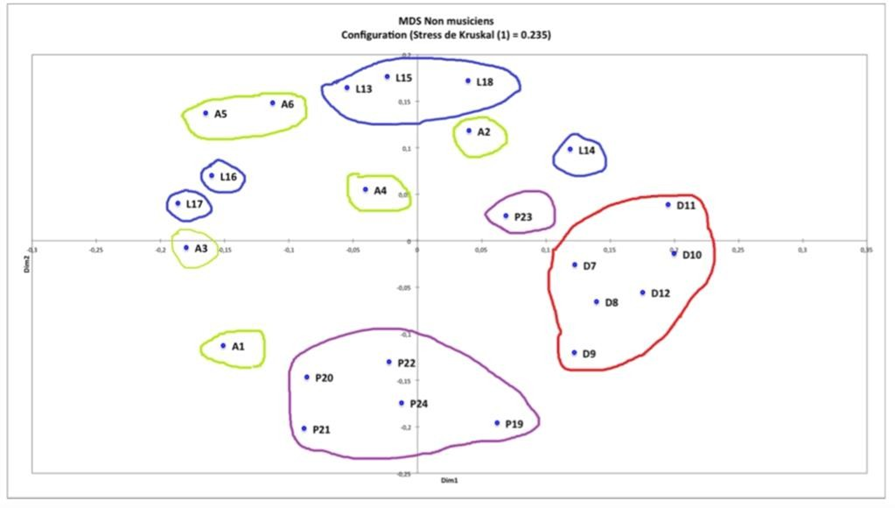

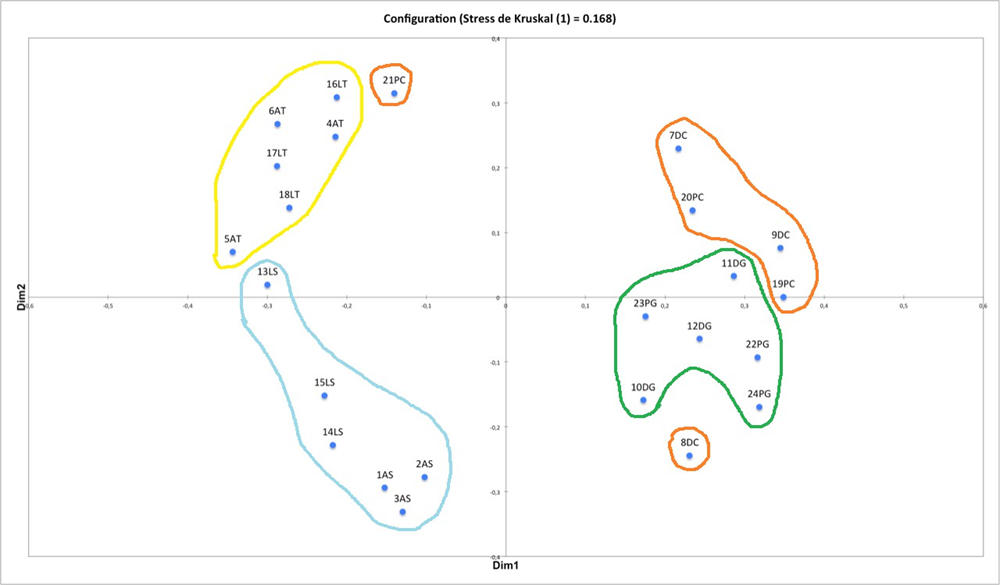
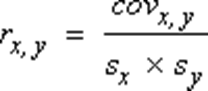
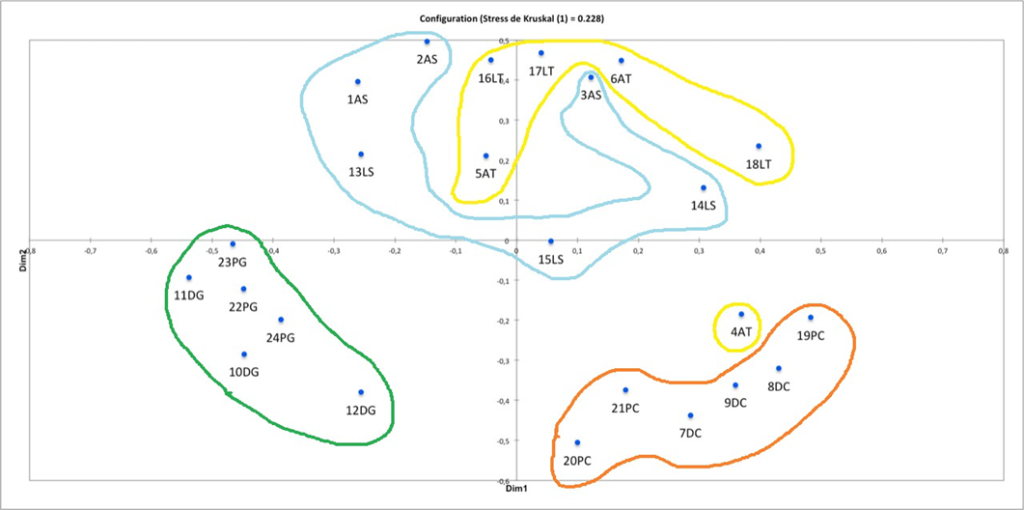
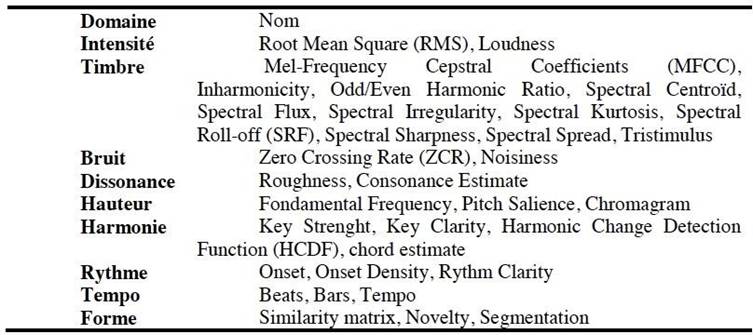
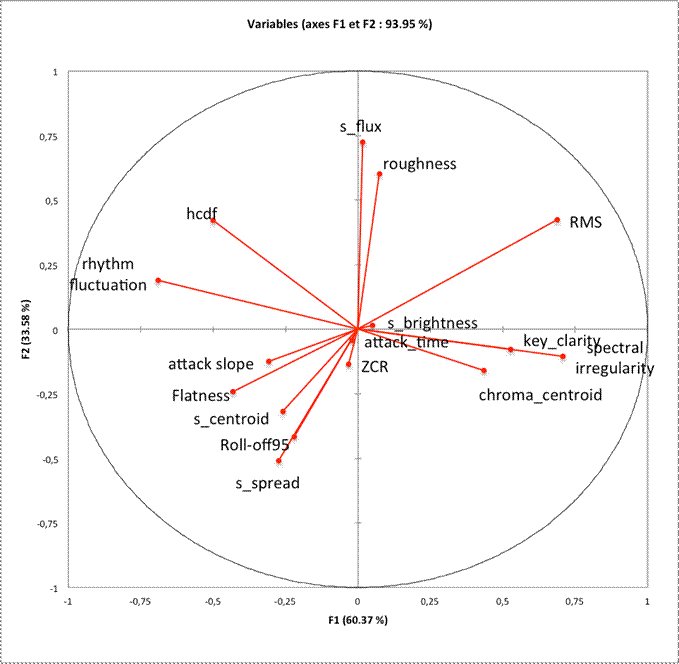
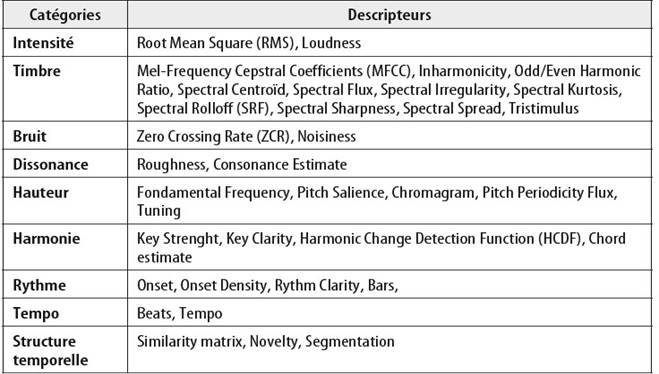
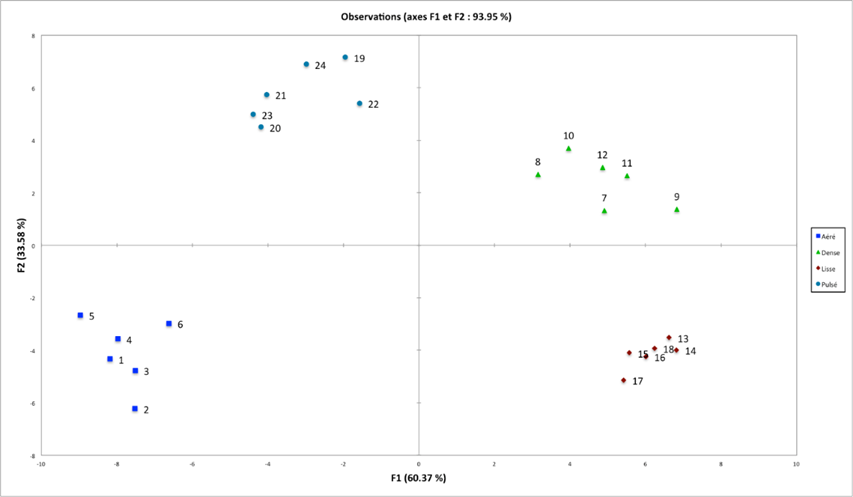
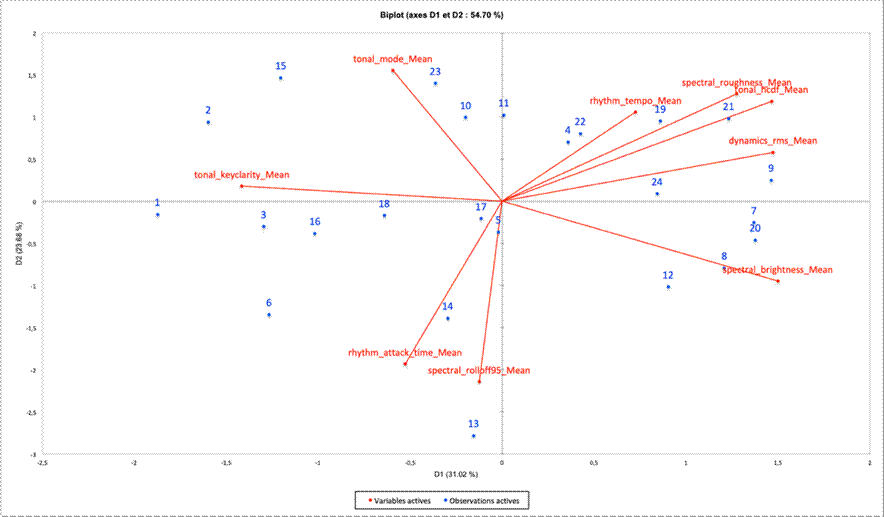
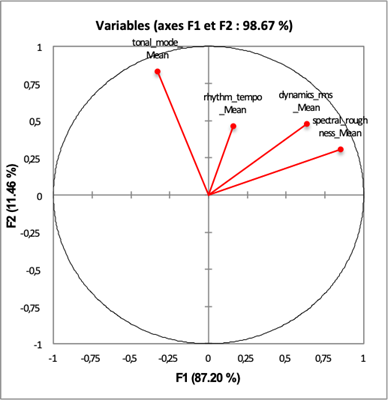
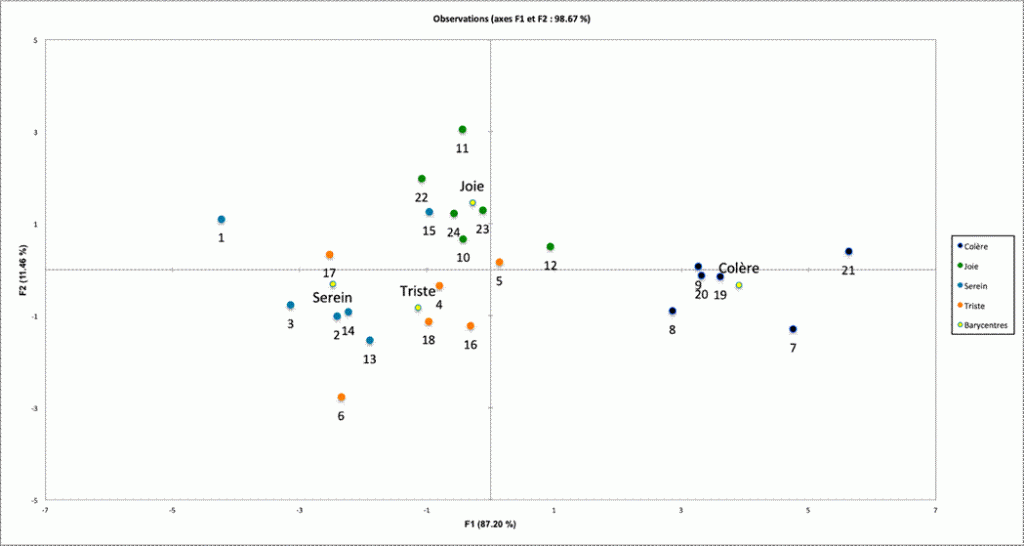


























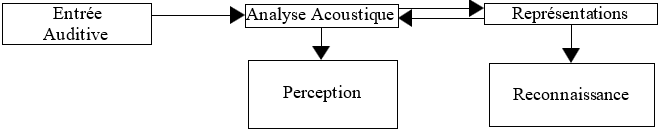
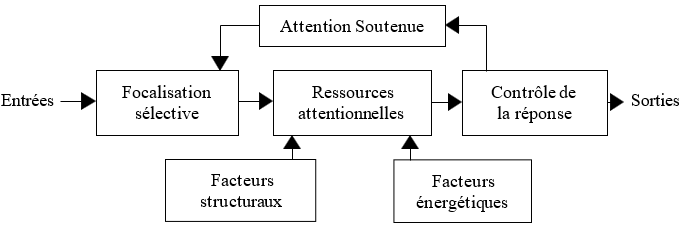
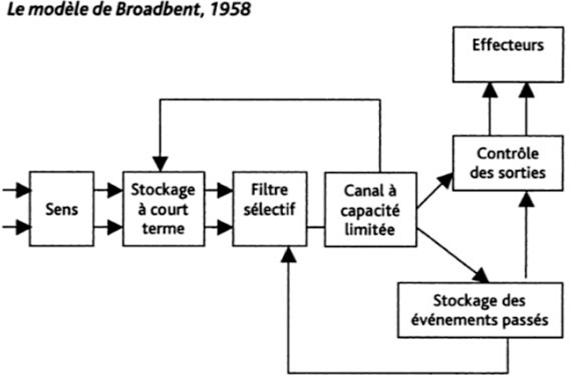
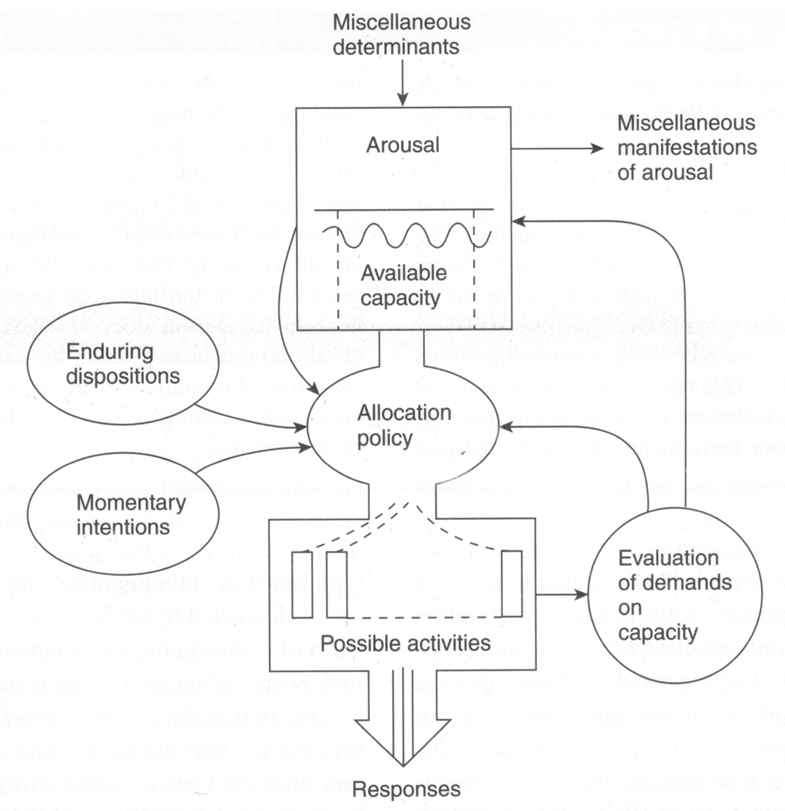
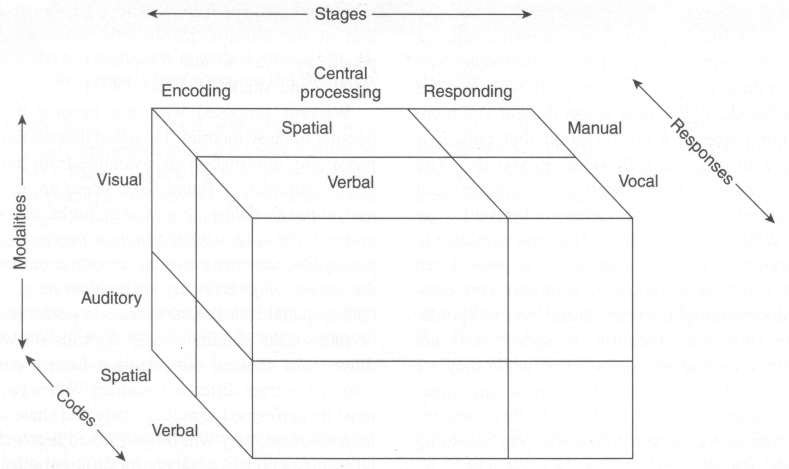
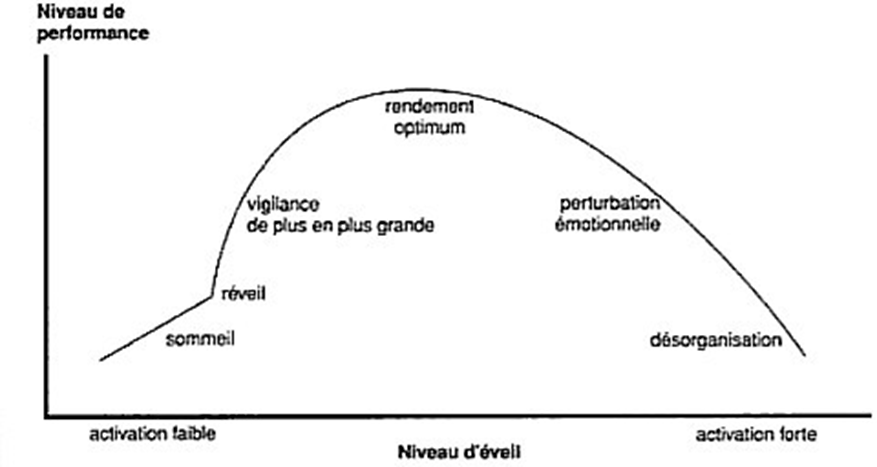

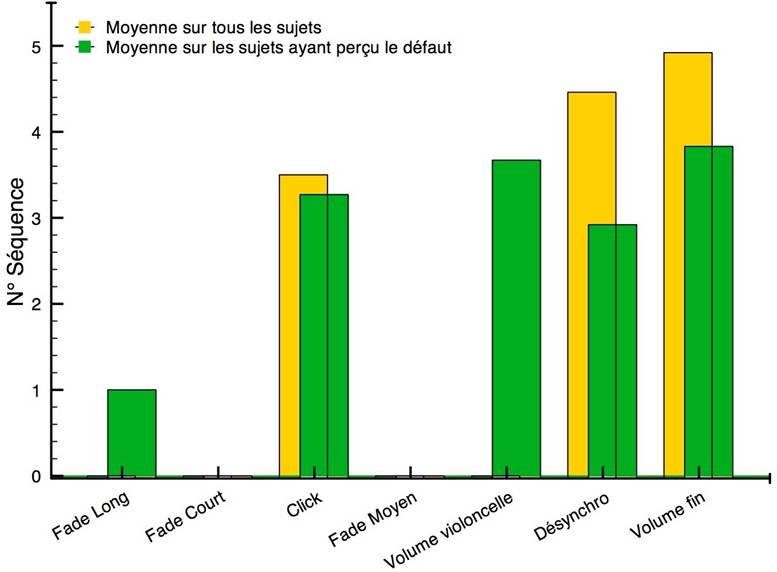
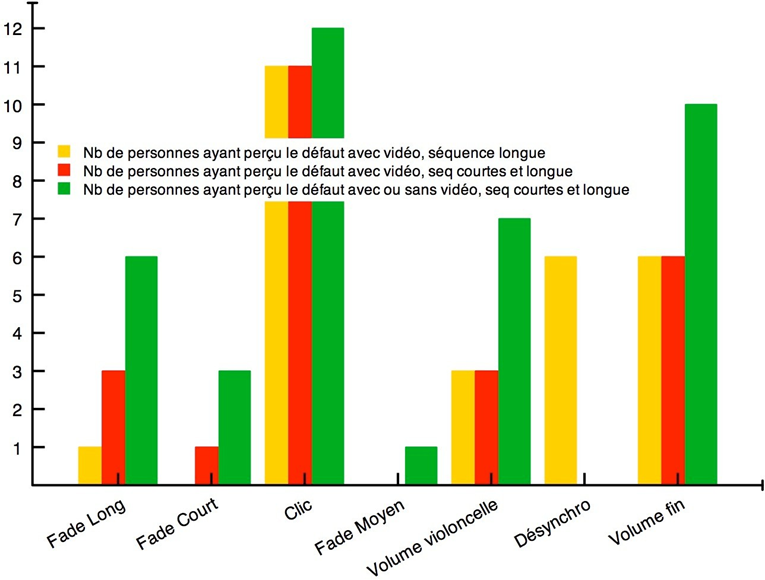
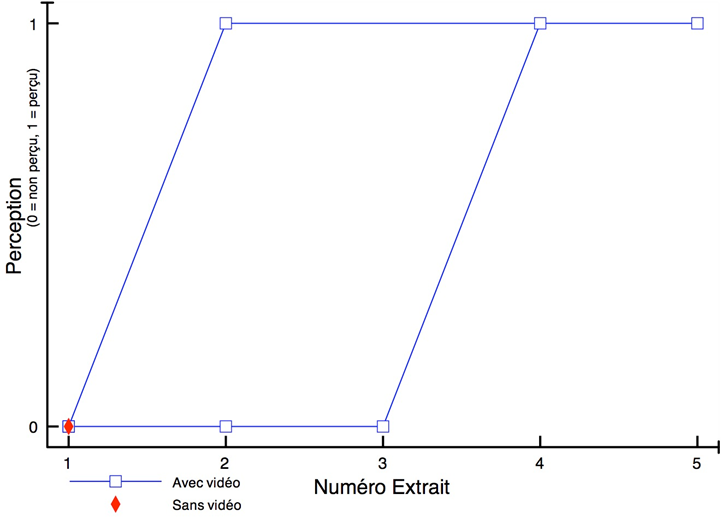
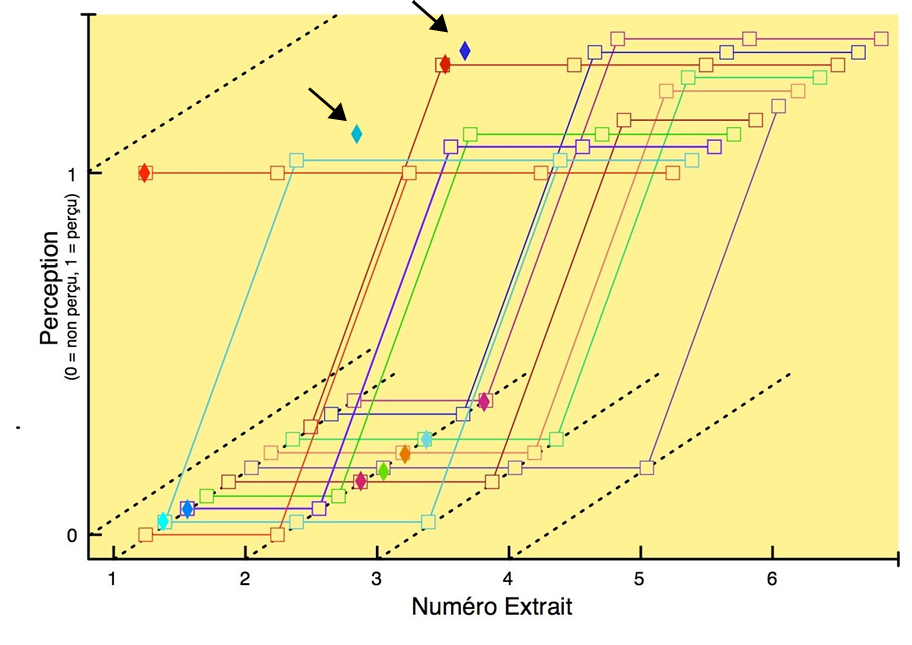
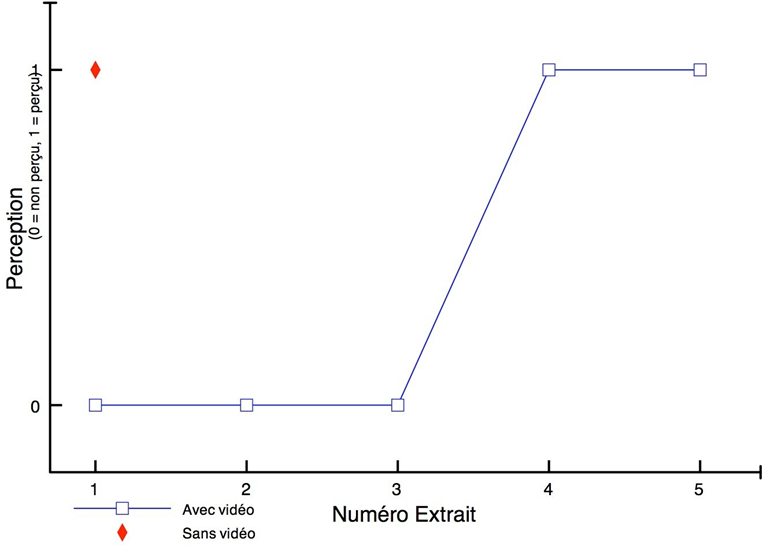
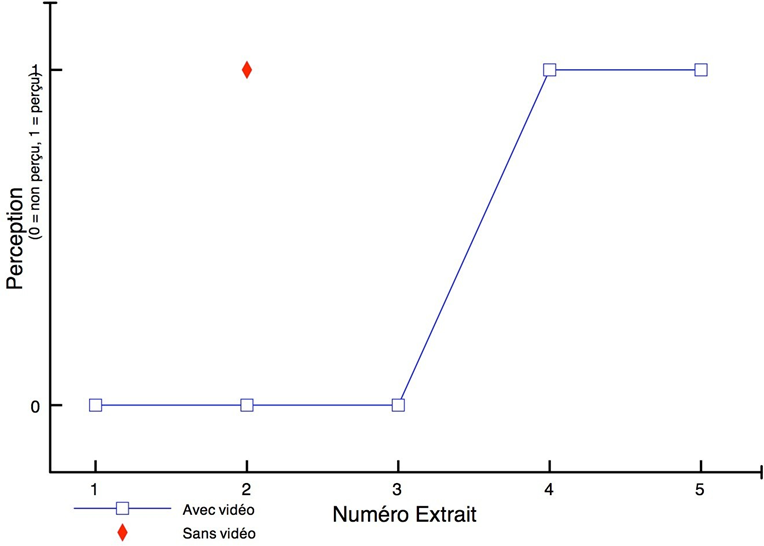
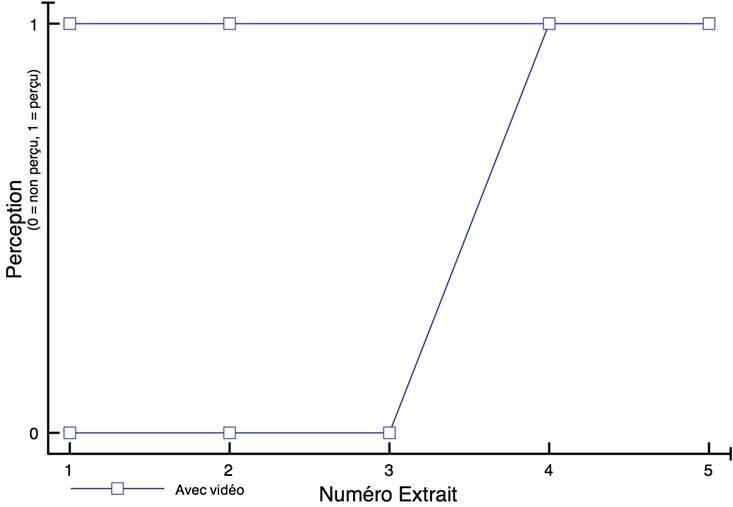
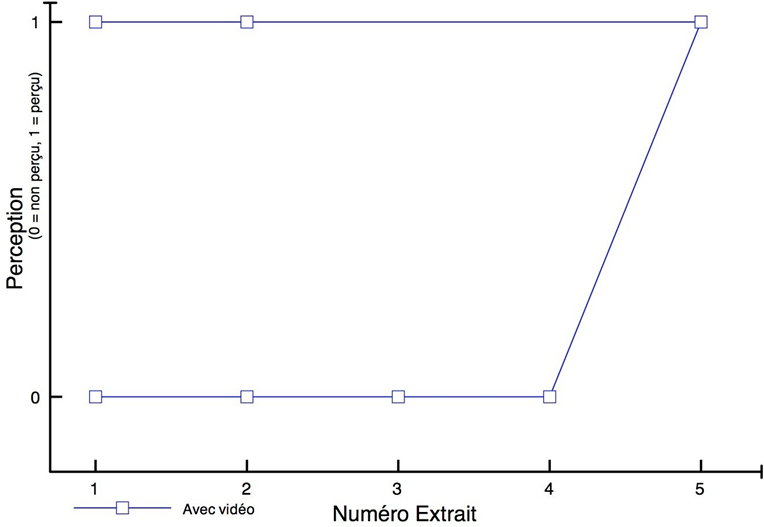
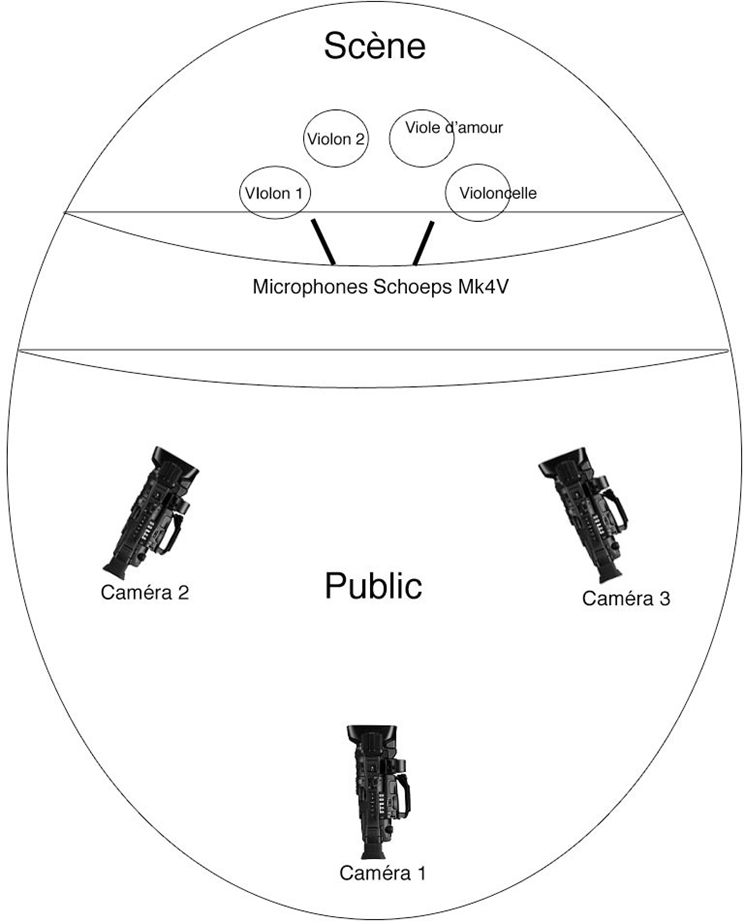








![Figure 1.4 – La grande salle de l'Arsenal de Metz. - Crédits photos : [11]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-323.png)
![Figure 1.4 – L'Auditorium de Dijon - Crédits photos :[12]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-324.png)


![Figure 1.7 – Deux configurations de Decca Tree - A gauche : configuration avec obstacle acoustique. A droite : 5 microphones M50 (dont deux ailes) - Crédits photos : [19]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-327.png)

![Figure 1.9 – Session d'enregistrement Philips - Crédits photo : [21]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-330.png)
![Fig. 1.10 – Utilisation d’un syst`eme XY lors d’un enregistrement Deutsche Grammophon Cr´edits photo : [17]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-332.png)
![Figure 1.11 – Enregistrement Deutsche Grammophon à la Jesus-Christus-Kirche, Dahlem, Berlin - Crédits photo : [17]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-333.png)