Théo Terracol
Sous la direction de François-Xavier Féron Novembre 2019
Résumé
Contexte de recherche. Ce mémoire est l’aboutissement d’un travail de recherche mené au Conservatoire National Supérieur de Musique et de Danse de Paris dans le cadre de la Formation Supérieure aux Métiers du Son.
Introduction. L’enregistrement musical est un processus complexe mettant en jeu un grand nombre de paramètres d’ordre artistique, technique, pratique et relationnel. Nous avons choisi de mener une réflexion autour des enjeux et des spécificités qu’implique la collaboration professionnelle entre le directeur artistique et le chef d’orchestre. Notre étude s’incrit donc dans le contexte spécifique des enregistrements d’ensembles musicaux dirigés.
Méthodologie. Nous avons effectué une série d’entretiens auprès de dix personnalités francophones du monde de la direction artistique et de la direction d’orchestre, dans le but de recueillir leur point de vue sur le sujet étudié. Les données issues de ces entretiens ont ensuite été confrontées à deux méthodes d’analyse : l’analyse de contenu et l’analyse par théorisation ancrée.
Résultats. Il apparaît dans notre étude que la collaboration professionnelle entre le directeur artistique et le chef d’orchestre s’articule autour de quatre axes principaux : les Aspects relationnels, l’Expertise du directeur artistique, la Nature des échanges et l’Organisation du travail.
Conclusions. Cette étude est l’une des premières à aborder spécifiquement la collaboration professionnelle entre directeurs artistiques et chefs d’orchestre. Elle a ainsi pu permettre d’élargir et de préciser le champ de recherche autour du domaine de la direction artistique.
TERRACOL, T., Enjeux et spécificités de la collaboration professionnelle entre directeurs artistiques et chefs d’orchestre. Mémoire de Master 2, Formation Supérieure aux Métiers du Son, Conservatoire National Supérieur de Musique et de Danse de Paris, 2019.
Introduction
Ce mémoire s’inscrit dans la continuité d’une réflexion personnelle et critique vis-à-vis du rôle du directeur artistique dans le contexte spécifique de l’enregistrement d’orchestre. Cette réflexion, née de notre propre expérience de directeur artistique et de chef d’orchestre, s’est manifestée tout au long de nos quatre années d’études au Conservatoire National Supérieur de Musique et de Danse de Paris.
Nous avons noté l’existence de nombreuses similitudes entre la fonction du chef d’orchestre et celle du directeur artistique telle qu’on l’enseigne en Formation Supérieure aux Métiers du Son. Ces deux activités requièrent des qualités analogues tant sur le plan artistique que sur le plan humain. Tout d’abord, directeur artistique et chef d’orchestre doivent tous deux faire preuve d’une bonne compréhension musicale et esthétique des œuvres. Ils doivent posséder un bagage d’idées sur la musique et sur son interprétation. L’écoute est un atout indispensable, tout comme la capacité à entretenir de très bons rapports humains. Enfin, directeur artistique et chef d’orchestre travaillent avec d’autres musiciens dans un but commun : celui de servir au mieux le compositeur et son œuvre.
Alan Gilbert, chef d’orchestre et directeur musical de l’Orchestre Philharmonique de New York de 2009 à 2017, décrit dans une vidéo publiée par le journal Times le rôle du chef d’orchestre (New York Times, 2012). Il axe son discours autour de l’importance du geste et de l’écoute et souligne la nécessité de faire part de ses aspirations en terme d’interprétation :
« L’une des façons d’améliorer la sonorité [d’un orchestre], c’est de montrer qu’on écoute vraiment les choses et qu’on accorde une réelle importance au son. En réalité, cela ne relève pas de la direction d’orchestre. Il s’agit plutôt d’incarner, de représenter une certaine aspiration, et il est troublant de voir à quel point cela peut faire toute la différence. Si nos oreilles sont grandes ouvertes et qu’on se sent concerné par la qualité du son, alors celle-ci en sera affectée.”1
Cette citation, aussi surprenante qu’elle puisse paraître à première vue, peut tout à fait s’appliquer au rôle du directeur artistique. A l’instar d’un chef d’orchestre en situation de répétition ou de concert, le directeur artistique doit faire preuve d’une oreille attentive, active et bienveillante, guider et encourager les artistes pour parvenir au meilleur résultat possible. En situation d’enregistrement, le directeur artistique incarne donc une figure tutélaire et avertie pouvant avoir sa propre influence sur le projet artistique final.
De ce fait, il nous semble légitime de nous interroger sur la collaboration professionnelle qu’entretiennent le chef d’orchestre et le directeur artistique, deux acteurs majeurs de la production d’un disque de musique orchestrale. Bien qu’il n’existe que très peu de littérature approfondie sur ce sujet, il est néanmoins possible de trouver un certain nombre d’écrits dans lesquels des directeurs artistiques et des chefs d’orchestre mentionnent les enregistrements qu’ils ont effectués au cours de leur carrière. Cependant, le contenu de ces écrits ne se limite qu’à quelques anecdotes, parfois amusantes, mais qui ne permettent pas de comprendre pleinement les enjeux et les spécificités de la collaboration professionnelle entre un directeur artistique et un chef d’orchestre.
Pour répondre à ce questionnement, nous avons donc choisi d’articuler notre raisonnement en quatre étapes consécutives. Dans un premier temps, nous avons effectué une recherche documentaire axée autour de l’essor de l’enregistrement de musique d’orchestre et du rôle du directeur artistique. Puis, à travers une série de plusieurs entretiens, nous avons recueilli la parole de personnalités expertes issues des milieux de la direction artistique et de la direction d’orchestre. Dans le but de parvenir à formuler les enjeux du phénomène étudié, nous avons soumis les données collectées à deux types d’analyse : l’analyse de contenu et l’analyse par théorisation ancrée. Enfin, en guise de conclusion, nous procéderons à une discussion critique de notre démarche et des résultats obtenus.
I.Contextualisation et enjeux d’une pratique artistique
1. L’enregistrement de la musique orchestrale
a) Les premières réalisations
Réalisée en 1913 à Berlin et considérée à tort comme le premier enregistrement de musique orchestrale de l’histoire du disque (Badal, 1996), la Cinquième Symphonie de Beethoven d’Arthur Nikisch avec l’Orchestre Philharmonique de Berlin, doit avant tout sa postérité au prestige de ses interprètes. Le premier enregistrement d’une pièce orchestrale serait en réalité attribué à la maison de disques allemande Odeon Records qui publia en 1909 la Suite du ballet Casse-Noisette de Tchaïkovsky, interprétée par le London Palace Orchestra sous la direction d’Hermann Finck (Eyser, 1986).
À partir de la décennie 1920, les techniques de prise de son et de diffusion se perfectionnent de manière significative. L’invention du microphone électrostatique au sein des laboratoires Bell, l’émergence d’une nouvelle technique d’amplification électrique du son ainsi que l’avènement de la radiodiffusion participent à l’essor de l’industrie du disque. C’est à ce moment-là que les chefs d’orchestre vont véritablement se confronter au nouveau médium qu’est l’enregistrement. Parmi les plus représentatifs, citons Arturo Toscanini qui réalise lors d’une tournée américaine en 1921 ses premiers enregistrements (Mozart, Beethoven, Berlioz, Massenet, Bizet) avec l’Orchestre de La Scala de Milan pour une jeune maison de disques qui deviendra par la suite RCA Victor. Félix Weingartner, chef d’orchestre très prolifique en studio, grave dès 1923 pour Columbia les cycles complets des symphonies de Beethoven et de Brahms (Badal, 1996). Enfin, à partir de 1926, le compositeur et chef d’orchestre Richard Strauss se lance dans l’enregistrement de ses propres œuvres et de celles de Mozart, Wagner et Beethoven.
b) Un nouveau cadre de travail
Confrontés au monde du studio, les chefs d’orchestre et les musiciens doivent appréhender une nouvelle forme d’interprétation dont l’absence de public s’avère être l’un des facteurs les plus troublants (Chanan, 1995). Du fait de la durée limitée de chacune des faces d’un disque, les œuvres sont découpées et enregistrées en plusieurs sections. Des microphones envahissent le plateau et captent le moindre son émis par les musiciens. Malgré cette avancée technologique notable, permettant une plus large diffusion du répertoire symphonique, un certain nombre de chefs d’orchestre sont longtemps restés hermétiques à l’enregistrement. Wilhelm Furtwängler, bien qu’ayant légué une discographie considérable, n’en a jamais vraiment mesuré la plus-value : pour lui, la malhonnêteté du disque réside dans le fait de découper indéfiniment une œuvre en plusieurs morceaux (Shirakawa, 1992). Il considère que l’expérience du concert est bien plus en phase avec la réalité de la musique et donc qu’elle est la seule digne d’intérêt. Son homologue Otto Klemperer dénonçait lui aussi le processus du montage avec une certaine ferveur, le qualifiant de fraude, d’arnaque, “ein Schwindel !” (Badal, 1996). Le chef wagnérien Hans Knappertsbusch, déconcentré par les conditions du studio, considérait le processus d’enregistrement comme absurde et refusait catégoriquement d’en écouter le résultat final. Notons enfin qu’à toutes ces controverses s’ajoutent très tôt de nombreuses objections esthétiques et éthiques formulées par un bon nombre d’intellectuels, parmi lesquels figurent Theodor Adorno (Adorno, 1990 et Levin, 1990) et Walter Benjamin (2008).
À l’inverse, certains chefs d’orchestre ont dès le début manifesté un réel intérêt pour l’enregistrement et se le sont rapidement approprié. Au début des années 1930, Leopold Stokowksi a mené avec l’Orchestre de Philadelphie un certain nombre d’expérimentations au sein des Laboratoires Bell à New York. C’est l’enregistrement monophonique qui l’amènera à penser un nouveau placement de l’orchestre selon lequel les premiers et seconds violons sont situés en bloc à la gauche du chef et les violoncelles à sa droite. Dans les années 1960, Stokowksi souhaite retranscrire le plus fidèlement possible les sensations de l’auditeur dans les conditions réelles d’une salle de concert : il poursuit ses expérimentations en travaillant avec la stéréophonie Phase 4 de la firme Decca et suggère lui-même de nouvelles idées en termes de placement microphonique, d’acoustique, de spatialisation et de mixage (Smith, 1990). L’expérimentation la plus populaire est probablement celle que Stokowski a réalisé en collaboration avec Walt Disney dans le film d’animation Fantasia sorti en 1940. Soucieux d’explorer les nouvelles possibilités liées aux innovations technologiques du son multicanal, Stokowski a divisé l’orchestre en plusieurs parties, le tout capté sur huit pistes et restitué sur un nouveau format de diffusion sonore immersif baptisé Fantasound (Garity & Hawkins, 1941).

c) Un outil de diffusion et de démocratisation du répertoire
À partir des années 1990, fort d’un recul de près de 80 ans sur l’expérience de l’enregistrement, plusieurs chefs d’orchestre se sont exprimés sur son rôle et sa plus-value. Lorin Maazel et Christoph Von Dohnàny soulignent tous deux l’aspect historique de l’enregistrement qui constitue une précieuse archive attestant de l’interprétation d’une œuvre par un interprète à un instant donné. L’enregistrement permet de laisser une trace durable dans le temps et témoigne de l’évolution de l’interprétation au fil des décennies. Pour Pierre Boulez, c’est une voix royale vers la démocratisation de la musique : l’action d’enregistrer garantit à chacun un accès facile et immédiat au meilleur du grand répertoire. Sir Colin Davis considère l’enregistrement comme une véritable source d’information et y voit un fort potentiel éducatif : en témoigne son acharnement et sa volonté à enregistrer pour Philips dans les années 1960-1970 l’intégrale des œuvres de Berlioz, dont la production mal connue du grand public était jusqu’ici peu enregistrée et rarement jouée. Le disque devient donc avec le concert l’un des meilleurs moyens de découvrir les œuvres de tel ou tel compositeur. Enfin, l’enregistrement est pour Kurt Masur une opportunité pour un chef comme pour un orchestre de se faire connaître et de rayonner à travers le monde (Badal, 1996).
Dans un documentaire (Burton, 1992) consacré au premier enregistrement studio de la tétralogie de Richard Wagner, le chef d’orchestre hongrois Georg Solti identifie plusieurs contraintes liées au contexte de l’enregistrement d’orchestre : la gestion du temps, la nécessité de rester musicalement cohérent sur plusieurs jours (notamment en matière de tempo), ainsi que la difficulté à avoir une vision globale et un recul nécessaires sur le projet. Solti compte alors sur la collaboration de John Culshaw, directeur artistique, pour le seconder.

2. La direction artistique
a)Terminologie
Dans un premier temps, il convient de mentionner que la terminologie relative à la fonction du directeur artistique varie selon les différents pays. En France et dans les pays francophones, le terme de directeur artistique est majoritairement utilisé. Certains parlent également de directeur d’enregistrement. Tout comme le mot chef et son autorité sous-jacente peuvent aujourd’hui déranger certains chefs d’orchestre, de plus en plus de directeurs artistiques insistent sur le fait que le mot directeur n’est pas synonyme de pouvoir absolu. Dans les pays germaniques, c’est le terme de Tonmeister (de l’allemand Ton : son et Meister : maître) qui est très largement utilisé. Celui-ci se rapporte exclusivement au répertoire de la musique classique occidentale. Enfin, dans les sphères anglophones, on parle de producer ou de recording producer. Notons que ce terme s’applique aussi bien au répertoire de la musique classique occidentale qu’au répertoire des musiques actuelles.
b) Emergence d’une profession
Borwick (1973) attribue la théorisation du concept de Tonmeister au compositeur viennois Arnold Schoenberg qui dès 1946 prône l’éducation de « maîtres du son » qualifiés dans les domaines de la musique et de la prise de son :
« Ceux-ci devront être formés dans les domaines de la musique, l’acoustique, la physique et la mécanique de façon à ce qu’ils puissent être capables de contrôler et d’améliorer la qualité sonore des enregistrements. […] L’étudiant devra être formé à repérer les différences entre l’image mentale qu’il se fait de la pièce lorsqu’elle est parfaitement jouée et le jeu réel des musiciens ; il sera capable de nommer ces différences et de dire comment les corriger. »2
Il convient cependant de nuancer les propos de Borwick. En effet, Schoenberg théorise ici davantage le concept d’éducation des directeurs artistiques que le concept de directeur artistique en lui-même. Et qui dit théorisation d’un concept ne dit pas invention. La fonction de directeur artistique telle que nous la connaissons aujourd’hui existait déjà bien avant 1946.
Dès ses débuts, l’enregistrement a nécessité un jugement avisé au sujet des décisions artistiques : validation ou ré-enregistrement d’une prise, montage, prise de son, choix des artistes, etc. Ces décisions étaient coordonnées par une personne appelée producer dont le rôle n’a cessé d’évoluer tout au long du XXᵉ siècle (Robert, 2004). Fred Gaisberg, employé par la Gramophone Company et His Master’s Voice, eut un rôle plus ou moins similaire à celui du directeur artistique moderne tel que nous l’entendons aujourd’hui. Gaisberg était en charge de l’ensemble du processus d’enregistrement et veillait à ce que celui-ci soit d’un point de vue artistique aussi satisfaisant que possible (Moore, 1999).
Mais l’importance du rôle de directeur artistique est intimement liée à l’âge d’or des grandes firmes. Au sortir de la Seconde Guerre mondiale, Deutsche Grammophon, Decca et EMI emploient des personnalités fortes pour mener à bien des projets d’enregistrement ambitieux et créer les meilleures collaborations artistiques qui soient avec leurs artistes. Parmi les noms les plus marquants, il convient de mentionner Walter Legge et John Culshaw.
Legge a travaillé de nombreuses années durant pour EMI avec Herbert von Karajan, Wilhelm Furtwängler, Otto Klemperer et Victor de Sabata. Méticuleux, il tenait à ce que chaque enregistrement soit le plus vivant et le plus intense possible, et n’avait aucun scrupule à utiliser les nouvelles techniques de montage pour y parvenir. Selon sa compagne la soprano Elisabeth Schwarzkopf, aucun chef d’orchestre, pas même Karajan, ne pouvait ignorer son avis, surtout s’il s’agissait d’une question d’interprétation (Schwarzkopf, 1983).

John Culshaw a longuement travaillé pour Decca et collaboré avec Georg Solti, Herbert von Karajan et Fritz Reiner. Culshaw, « magicien de la technique et philosophe passioné de musique » (Badal, 1996), est le représentant d’une certaine génération de directeurs artistiques à la fois perfectionnistes et innovants, utilisant les nouvelles technologies de prise de son sans concession comme en témoignent ses deux enregistrements majeurs : Elektra3 de Richard Strauss, très largement critiqué pour ses audacieuses prises de risques (Culshaw, 1968) et l’intégrale de la Tétralogie de Richard Wagner4, un projet ambitieux d’une envergure démesurée.

c) Le rôle du directeur artistique : état de l’art
Selon Haas (2003), le rôle du directeur artistique est simple et se résume à retranscrire sur un support audio la performance d’un chef et de son orchestre. Chanan (1995) le présente comme une oreille extérieure qualifiée d’un point de vue musical et technique. Auditeur privilégié, il sert de médiateur entre la partition, l’artiste et les moyens technologiques d’enregistrement (Frith & Zagorski-Thomas, 2012). Selon King (2016), la fonction principale du directeur artistique consiste à soutenir l’artiste dans la réalisation de ses idées musicales et à le guider tout au long du processus d’enregistrement.
Culshaw (1968) met en regard la figure du directeur artistique et celle du chef d’orchestre. Il pointe les nombreuses similitudes qui existent entre ces deux fonctions et affirme que chacun des deux protagonistes possède une idée parfaitement claire de comment l’œuvre doit être jouée. L’un comme l’autre, ils impriment leur marque sur l’enregistrement. Badal (1996) conçoit la relation qu’entretiennent le chef d’orchestre et l e recording producer comme un véritable partenariat artistique qui conditionne la qualité artistique du disque, pour le meilleur et pour le pire. Ravet (2015) considère le directeur artistique comme un co-auteur de l’interprétation avec qui le chef d’orchestre partage l’autorité créatrice. C’est lui qui contrôle le temps d’enregistrement et qui donne le feu vert pour passer d’une prise à une autre. De façon plus générale, il est garant de la qualité obtenue au moment de l’enregistrement tant d’un point de vue artistique et esthétique que d’un point de vue technique.
Des travaux de recherche sur la direction artistique d’enregistrements ont déjà vu le jour. Hennion (1989) étudie le rôle du directeur artistique dans le contexte de la musique de variété. Proposant une approche sociologique, il le considère comme un intermédiaire entre la musique et son industrie, entre l’artiste et son public. Cotelle (2001) interroge plusieurs directeurs artistiques sur la vision qu’ils ont de leur métier et met en lumière l’importance de l’aspect relationnel. Enfin, Patmore et Clark (2007) proposent une réflexion autour de l’influence esthétique que peut avoir le directeur artistique dans le milieu de la musique classique à travers la personnalité de John Culshaw.
3. Enjeux épistémologiques
a) Les recherches d’Amandine Pras
Amandine Pras est ingénieure du son, directrice artistique et chercheuse. Elle a réalisé un grand nombre d’études liées au domaine des pratiques d’enregistrement. Sa thèse de doctorat (Pras, 2012) a pour objet l’investigation de meilleures pratiques d’enregistrement studio à l’ère du numérique. Son approche en tant que chercheuse fait appel à divers domaines comme la sociologie et la linguistique.
Pras a mené deux études qualitatives visant à documenter les pratiques de la direction artistique et plus précisément les compétences et qualités nécessaires à la fonction de directeur artistique. Amandine Pras et Catherine Guastavino (2011) ont effectué une série d’entretiens auprès de seize musiciens et six ingénieurs du son de milieux différents, dans le but de parvenir à une formulation du rôle idéal du directeur artistique. Les données issues de ces entretiens ont ensuite été confrontées à la méthode d’analyse par théorisation ancrée que nous définirons plus tard dans ce mémoire. Pras et Guastavino ont identifié trois catégories relatives à la fonction de directeur artistique : mission (son rôle), skills (ses compétences) et interaction (rapport avec les musiciens).
En 2013, pour compléter les résultats obtenus, Pras, Guastavino et Cance ont décidé de collecter des données supplémentaires auprès d’une population de directeurs artistiques professionnels (Pras et al., 2013). Six experts du monde de l’enregistrement ont donc été interrogés par le biais de questionnaires et d’entretiens. En combinant plusieurs méthodes d’analyse qualitative du domaine des sciences sociales et de la linguistique, Pras, Guastavino et Cance ont identifié et hiérarchisé les compétences du directeur artistique. Une partie des résultats identifiés en 2011 grâce au corpus de musiciens et d’ingénieurs du son ont été confirmés par cette nouvelle étude. Des résultats complémentaires sont apparus.
La fonction de directeur artistique selon Pras se résume en trois catégories :
- la mission de direction artistique : en fonction du contexte esthétique, rôle d’oreille extérieure, guide, critique, recherche du meilleur résultat artistique.
- la relation avec les musiciens : observation, adaptation, managing, conserver la sensibilité des artistes, adapter son langage et rôle de pont entre les artistes et le public.
- les compétences en matière de communication : créer une bonne atmosphère, permettre la confiance et l’honnêteté.

Comme le montrent les études menées par Pras, Guastavino et Cance, la direction artistique est une activité complexe impliquant une multitude de problématiques à la fois musicales et relationnelles. Cependant, ces travaux ne se limitent pas à un cadre d’étude particulier et abordent le rôle du directeur artistique de manière globale, sans spécification de répertoire, d’esthétique ou de formation enregistrée.
b) Objet et problématique de recherche
Nous avons choisi d’inscrire notre étude dans un contexte spécifique : celui des enregistrements de musique d’ensemble dirigée. Nous nous limitons donc au contexte des ensembles instrumentaux dirigés par un chef d’orchestre : grand orchestre symphonique, orchestre de chambre, orchestre à cordes ou à vents, petit ensemble baroque ou contemporain. L’enregistrement doit être supervisé par un directeur artistique, capable d’interagir avec le chef d’orchestre et les musiciens.
Bernard Lehmann, chercheur dans le domaine de la sociologie de la musique, affirme que pour un orchestre, la répétition est en réalité « une série de négociations effectuées entre les musiciens et le chef sur la définition du ton à donner à l’œuvre». Il ajoute que cette définition « a d’autant plus de chances d’être acceptée par les musiciens que le chef sait y mettre la forme » (Lehmann, 2002, p.203). Les propos tenus par Lehmann nous semblent tout à fait transposables dans le domaine de l’enregistrement, qui s’avère être une série de négociations effectuées entre le chef et le directeur artistique sur la définition du ton à donner à l’œuvre. De ce fait, quelle relation professionnelle entretient le directeur artistique avec son interlocuteur privilégié : le chef d’orchestre ? De quelle manière travaillent-ils ensemble ? Quelles sont les problématiques mises en jeu ? Existe-t-il des spécificités liées à ce contexte particulier ?
Nous tenterons d’apporter des éléments de réponse à ces interrogations au moyen d’une étude pratique fondée sur la collecte et l’analyse de données discursives recueillies auprès de dix professionnels du milieu de la direction artistique et de la direction d’orchestre.
II. Méthodologie de collecte de données
1. Techniques d’entretien
« L’enquête par entretien est l’instrument privilégié de l’exploration des faits dont la parole est le vecteur principal.»5
L’objectif de notre étude étant à la fois de documenter la pratique de la direction artistique dans le contexte d’un enregistrement de musique d’ensemble et d’interroger les relations existantes entre le chef d’orchestre et le directeur artistique, nous avons choisi de fonder la base de notre recherche sur la technique de l’entretien permettant de collecter la parole d’experts.
« L’enquête par entretien est […] particulièrement pertinente lorsque l’on veut analyser le sens que les acteurs donnent à leurs pratiques, aux évènements dont ils ont pu être les témoins actifs ; lorsque l’on veut mettre en évidence les systèmes de valeurs et les repères normatifs à partir desquels ils s’orientent et se déterminent. »6
Nous avons donc fait appel à dix professionnels francophones afin qu’ils nous fassent part de leurs expériences et de leurs points de vue sur le sujet étudié. On distingue traditionnellement trois différents degrés de directivité d’un entretien : l’entretien non directif, l’entretien semi-directif et l’entretien directif (Fenneteau, 2007).
L’entretien directif consiste à interroger le participant en lui posant des questions correspondant à la problématique de l’enquête. Le discours de la personne interrogée est par conséquent cadré et fortement orienté. Bien que cette technique permette d’obtenir des informations précises sur le phénomène étudié, elle présente un inconvénient non négligeable puisqu’elle ne permet pas d’explorer en profondeur l’opinion du participant. En effet, les questions directives empêchent d’exprimer une partie des pensées et des sentiments et il ressort souvent des réponses superficielles.
L’entretien non directif favorise une parole plus libre et engage à s’exprimer librement. Le participant adopte alors un discours plus fluide et parcourt le sujet plus en profondeur. Ce qui fait la force de l’entretien non directif peut dans certains cas s’avérer être une faiblesse. En effet, une trop grande liberté peut amener la personne interrogée à s’éparpiller et à perdre une certaine continuité dans son discours. De plus, les propos de chacun des participants sont difficilement comparables, ce qui complique lourdement le travail d’analyse.
Ainsi, nous avons choisi d’opter pour une forme mixte combinant à la fois directivité et non-directivité en réalisant des entretiens semi-directifs. C’est par le biais d’un guide d’entretien rédigé préalablement par le chercheur que celui-ci va orienter le discours du participant, sans pour autant le cadrer explicitement. Si un thème particulier figurant dans le guide d’entretien n’est pas évoqué spontanément par le participant, le chercheur peut alors intervenir pour orienter la discussion. L’entretien semi-directif nous a semblé être un bon compromis pour pouvoir collecter un matériau riche et avoir un réel aperçu des principales dimensions du phénomène étudié.
2. Protocole expérimental
a) Panel des participants à l’étude
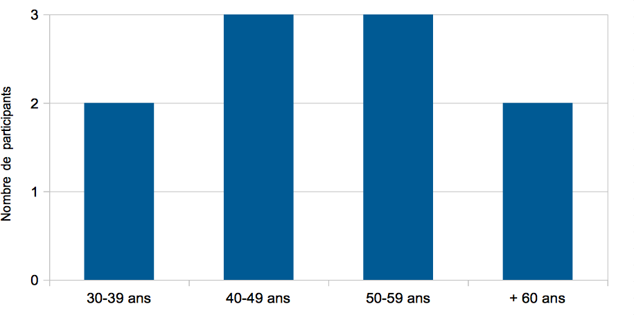
Sélectionner les participants à une enquête est une étape majeure : il s’agit de « déterminer les acteurs dont on estime qu’ils sont en position de produire des réponses aux questions que l’on se pose » (Blanchet & Gotman, 2007). Dans le cas de notre étude, la définition de la population est incluse dans la définition du phénomène étudié, à savoir des directeurs artistiques et des chefs d’orchestre. Seuls deux critères de choix ont été définis et ce, par souci de méthode et d’analyse. Tout d’abord, chaque participant devait parfaitement parler le français : une langue commune est nécessaire pour pouvoir mettre en regard les propos des uns avec ceux des autres. De plus, chacun devait obligatoirement avoir au minimum une expérience d’enregistrement de musique d’ensemble dirigée, soit en tant que directeur artistique, soit en tant que chef d’orchestre. L’âge, le sexe et le nombre d’années d’expérience sont trois aspects que nous souhaitions être relativement hétérogènes sur l’ensemble des participants. Cependant, il convient de mentionner que, malgré plusieurs prises de contact, aucune femme chef d’orchestre n’a participé à cette étude.
Malgré nos tentatives d’obtenir un corpus équitable de cinq directeurs artistiques et cinq chefs d’orchestre, nous n’avons malheureusement pas été en mesure de respecter cette condition : deux entretiens ont dû être annulés par deux chefs d’orchestre pour des raisons professionnelles. Cependant, nous avons pu réunir un corpus de dix participants. Parmi eux, six sont des directeurs artistiques, et quatre sont des chefs d’orchestre. Bien qu’un plus vaste corpus de participants est préférable dans toute étude, nous avons dû nous concentrer sur une dizaine de profils riches, sensibles au sujet étudié et fortement impliqués dans le domaine de l’enregistrement de musique d’ensemble dirigée. En amont de chaque entretien, nous avons fait remplir à chacun des participants un court questionnaire permettant de cerner son profil et son parcours professionnel (cf. Annexe 1) . Par souci de confidentialité et conformément aux conditions énoncées en préambule de chaque entretien, nous avons choisi de ne pas divulguer le nom des participants à notre étude. Garantir l’anonymat est un bon moyen d’inciter les personnes interrogées à s’exprimer plus librement.
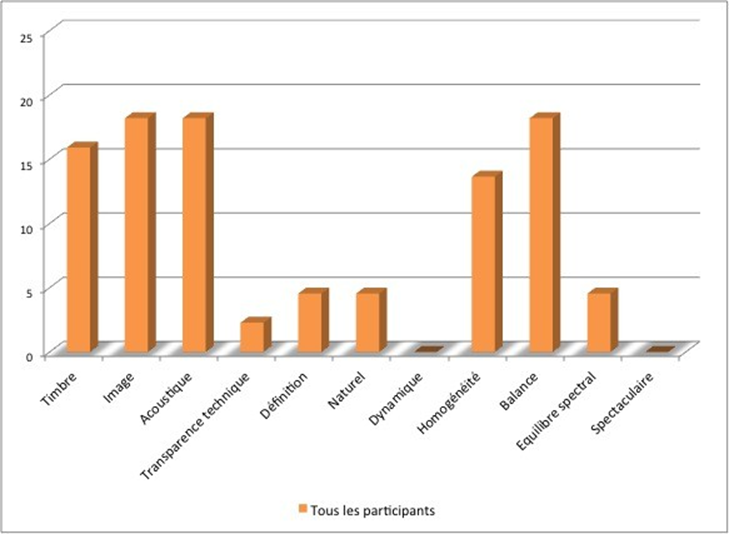
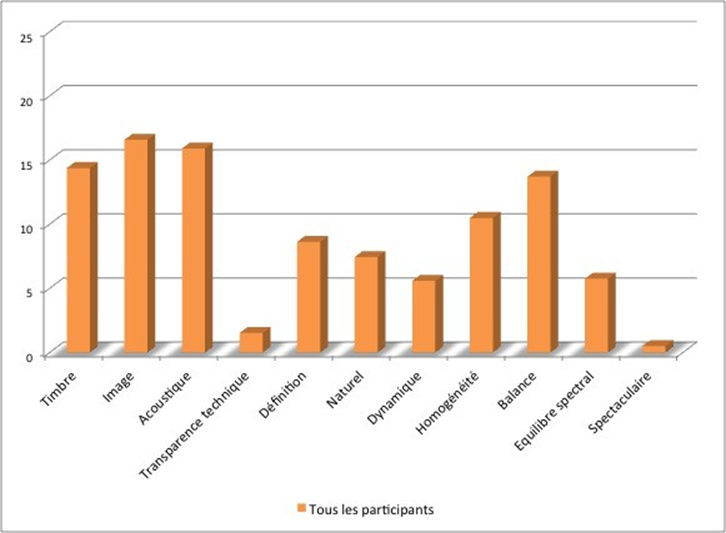
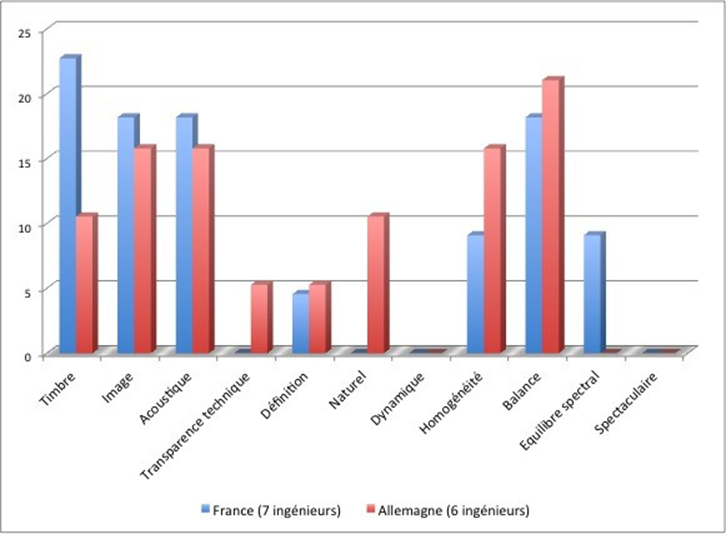
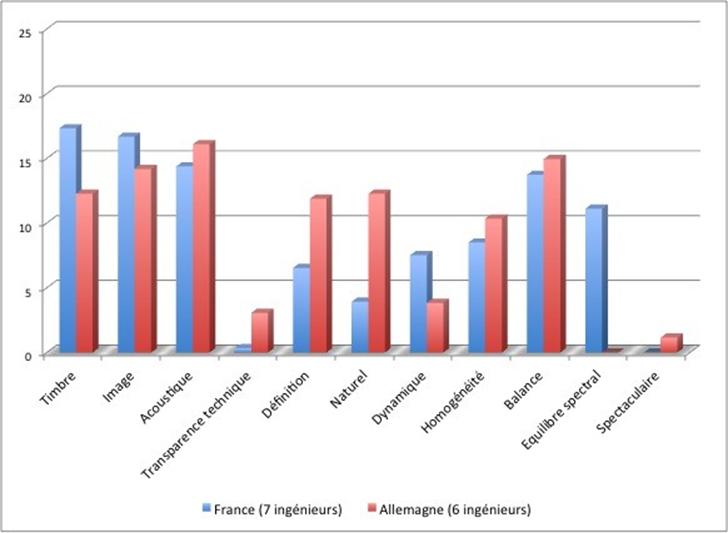
Les cinq figures ci-dessous présentent le profil de l’ensemble des participants à l’étude.
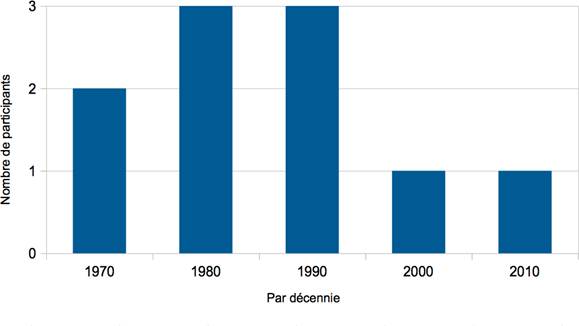
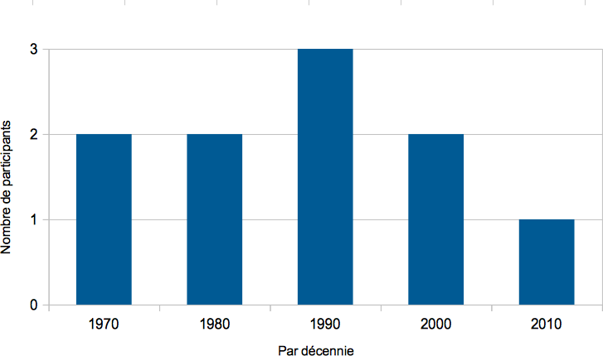
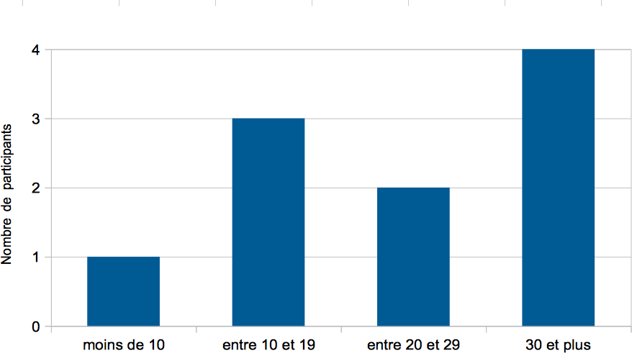
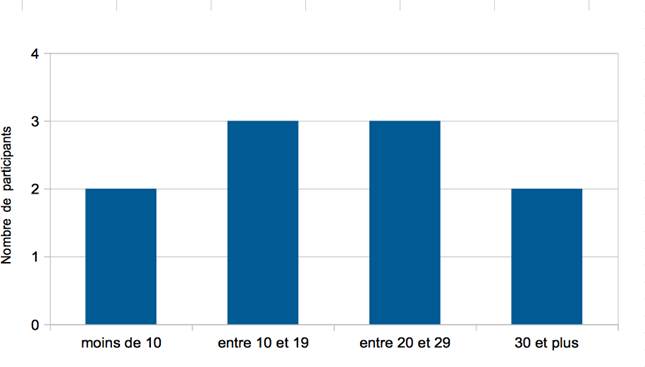
La prise de contact avec les participants de cette enquête s’est effectuée de deux manières. Ayant dans notre entourage certaines connaissances dont les profils correspondent tout à fait aux critères définis dans cette étude, nous avons directement pris contact avec ces personnes par e-mail ou par téléphone. Nous avons néanmoins été en mesure de souligner le cadre institutionnel et d’adopter une attitude tout à fait formelle avec ces personnes et ce, pour le bien de l’étude. Pour ce qui est des autres participants, la majorité d’entre eux, précisons-le, nous avons été mis en contact de manière indirecte, en passant par l’entremise d’assistants ou de personnel institutionnel. Bien que cette méthode ne soit pas neutre, dans la mesure où nos demandes étaient doublées d’une demande tierce (sociale ou professionnelle), celle-ci a pour réel avantage de maximiser les chances d’acceptation de la part de l’expert sollicité.
b) Guide d’entretien
L’élaboration du guide d’entretien (Annexe 2) est une étape cruciale puisque c’est son contenu qui va conditionner la nature des informations collectées. Par souci de méthode et de cohérence, nous avons choisi d’utiliser le même guide d’entretien pour les deux groupes de participants : les directeurs artistiques et les chefs d’orchestre. Ainsi, chaque thème a pu être abordé avec chaque participant de manière uniforme. Une fois notre guide élaboré, nous avons choisi de le tester auprès de deux participants pilotes (un jeune chef d’orchestre et un jeune directeur artistique), dans le but de vérifier la pertinence des thèmes abordés et la cohérence des questions posées. Cette étape nous a permis de voir les faiblesses de notre guide et d’y apporter les modifications et reformulations nécessaires.
Les questions n’ont pas forcément toujours été posées dans le même ordre, puisqu’il nous a semblé préférable de nous adapter au discours de notre interlocuteur afin de mener une discussion plus fluide. Pour chercher à fluidifier le discours, inciter les participants à approfondir un sujet ou les inviter à aborder un nouveau point, nous avons utilisé trois stratégies d’intervention énumérées par Blanchet et Gotman (2007) :
- la contradiction : action ayant pour but de s’opposer au point de vue développé par le participant afin l’amener à approfondir ou clarifier son opinion. Ainsi, l’enquêteur est certain de bien comprendre les arguments de son interlocuteur ou bien comment il relate certains faits.
- la consigne : il s’agit d’une intervention qui a pour but d’inviter la personne interrogée à parler d’un autre sujet. La consigne peut induire deux types de discours selon sa formulation : un discours d’opinion dans lequel le participant expose son point de vue, ou bien un discours de narration qui permet de relater des faits. Nous avons à plusieurs reprises utilisé des consignes au cours de nos entretiens (« J’aimerais que vous me parliez de… »).
- la relance : de nature plus spontanée, telle un commentaire, la relance de l’intervieweur permet de souligner, reformuler, synthétiser. Elle peut indirectement induire de la part du sujet une confirmation du discours ou une précision.
c) Cadre de l’entretien
Il est nécessaire d’attacher beaucoup d’attention au choix du cadre de l’entretien. En effet, l’environnement dans lequel la personne interrogée se situe peut avoir tendance à influencer sa réflexion et son discours. Il convient de définir trois paramètres pouvant être décisifs : le choix du lieu et du moment, le contexte humain et le cadre contractuel de l’entretien (Fenneteau, 2007) :
Choix du lieu et du moment
Pour la plupart des entretiens, nous nous sommes efforcés de choisir les moments les plus propices ainsi que des lieux pertinents, porteurs de sens et traduisant les préoccupations de la personne interrogée. Les entretiens avec les chefs d’orchestre se sont déroulés la plupart du temps dans la loge d’une salle de concert à l’issue d’une répétition ou bien au domicile du participant dans lequel nous avions été convié. Les entretiens avec les directeurs artistiques se sont pour la plupart déroulés à l’issue d’une séance d’enregistrement, dans un studio ou au Conservatoire National Supérieur de Musique et de Danse de Paris. Lorsque l’éloignement géographique était trop important, nous avons pu aisément convenir d’un entretien par appel vidéo via Skype. Ainsi, nous avons ainsi souhaité mettre chaque participant en confiance en l’interrogeant dans un lieu qui lui était familier et en choisissant le moment le plus propice au regard de son agenda bien souvent très chargé.
Contexte humain
Le contexte humain est défini selon « les interactions entre le profil psychosociologique de l’interviewer et celui de l’interviewé » (Fenneteau, 2007). Afin de rendre ces interactions les plus profitables au bon déroulement des entretiens, je me suis efforcé d’adopter une attitude respectueuse et arrangeante et de spécifier en amont de la rencontre mon statut d’étudiant, mon fort intérêt pour le sujet ainsi que mes connaissances en matière de direction artistique, d’enregistrement et de direction d’orchestre.
Cadre contractuel de l’entretien
Nous nous sommes efforcés d’établir clairement le cadre de mes entretiens dès la prise de contact avec les experts que je souhaitais interroger. Toutes les prises de contact ont été effectuées par courriel, ce qui a permis aux participants de garder une trace écrite du cadre de l’entretien. Afin d’être certain que toutes les conditions aient été clairement énoncées et comprises, nous avons pris l’initiative de rédiger un formulaire de consentement préalable à l’entretien (Annexe 3) et de le faire signer par toutes les personnes interrogées. Ce formulaire avait pour objectif de rappeler :
- mon statut d’étudiant au sein de la Formation Supérieure aux Métiers du Son au Conservatoire National Supérieur de Musique et de Danse de Paris ;
- le cadre de mes recherches (mémoire de Master) ;
- la finalité de l’étude ;
- la procédure d’entretien et sa durée approximative ;
- l’enregistrement audio ayant pour but de recueillir l’intégralité des propos du participant ;
- les droits du participant ;
- la confidentialité des données issues de l’entretien ;
- l’anonymat du participant.
d) Transcription des données orales
Nous avons réalisé nos entretiens sur une durée de six mois, entre janvier 2019 et juin 2019. La durée approximative de chaque entretien était comprise entre 25 et 55 minutes. Nous avons par la suite procédé à la retranscription des données collectées, ce qui consiste à transposer par écrit à l’aide d’un logiciel de traitement de texte les propos des participants recueillis oralement. La taille totale des données atteint près de 35 000 mots. L’entretien le plus court en compte environ 2050 et l’entretien le plus long en compte 5000. Par souci de clarté et pour faciliter l’analyse, nous nous sommes efforcés de gommer certaines fautes de langage, hésitations, onomatopées et ce, en restant le plus fidèle possible au discours original de l’interrogé. Par souci de confidentialité et conformément aux conditions énoncées en préambule de chaque entretien, nous avons choisi de ne pas publier l’intégralité des retranscriptions des entretiens. Cependant, précisons que de nombreux extraits seront par la suite cités, dans le but d’illustrer notre analyse. C’est au terme des retranscriptions qu’a pu débuter cette étape.
L’analyse des discours a été effectuée sur l’ensemble des entretiens retranscrits de manière littérale. Le principal objectif de cette analyse est de tenter de produire des résultats répondant aux objectifs de la recherche. Autrement dit, l’analyse contribue à façonner le discours des participants à l’étude pour en dégager un sens global et intelligible.
III. Analyse de contenu
1. Principe de la méthode
Dans un premier temps, nous avons choisi de faire appel à l’analyse de contenu, une méthode directement issue du domaine des sciences humaines et sociales. Celle-ci est définie par Berelson comme étant « une technique de recherche pour la description objective et quantitative d’un contenu » (Ghiglione & Matalon, 1998, p.155). Cette définition implique qu’il s’agit d’une approche mixte, à la fois qualitative et quantitative. Le contenu étudié étant signifié dans un texte d’origine écrit ou dans un discours oral, cette forme d’analyse relève donc du domaine de la sémantique (Blanchet, 1985).
a) Approche qualitative
L’analyse de contenu permet avant tout d’avoir une première approche des choses dans leur globalité : elle vise à identifier et à quantifier les principaux éléments présents dans un discours. Elle ne permet pas de répondre à la question comment ? mais plutôt de quoi est-il question ? Le chercheur est amené à comprendre et synthétiser les données. L’analyse de contenu sert à décrire et à déchiffrer tout passage de signification d’un émetteur à un récepteur (Bardin, 1989). Elle porte donc sur le signifié et cherche à rendre l’information la plus accessible possible avec une réduction minimale des informations.
b) Approche quantitative
L’approche quantitative de cette méthode découle de son approche qualitative. En effet, une fois les problématiques mises en jeu identifiées, il est parfois pertinent et utile de poursuivre la démarche en passant par une phase de quantification. Dans le cas d’une étude comme la nôtre, basée sur un grand nombre de données, l’approche quantitative peut permettre d’évaluer le poids de chaque élément du discours identifié au regard de l’ensemble du corpus.
2. Outil d’analyse
Pour procéder à l’analyse de contenu, nous avons fait appel à l’un des nombreux outils informatiques mis à la disposition des chercheurs. Sketch Engine est une plateforme en ligne conçue pour des applications d’analyse de textes. Développée par la compagnie Lexical Computing Limited en 2003, elle permet l’ajout de contenus écrits (dans notre cas la transcription de nos entretiens) et la création de corpus de textes. Sketch Engine permet d’entreprendre plusieurs démarches pour une première approche purement quantitative : de nombreux outils nous sont proposés parmi lesquels figurent le comptage fréquentiel de lemmes et la mise en évidence d’associations entre plusieurs lemmes. En linguistique, un lemme (ou item lexical) est défini comme une unité de langage autonome pouvant regrouper plusieurs mots de formes différentes mais associés à la même signification. À titre d’exemple, les mots « échanger », « échange », « échanges », « échangé » sont regroupés sous le même lemme « échanger » : tous présentent un radical commun (le lexème).
Afin de procéder à l’analyse des données sur Sketch Engine, nous avons réalisé deux corpus de textes : un corpus dédié aux directeurs artistiques et un autre corpus dédié aux chefs d’orchestre. Cela nous permettra par la suite de pouvoir les confronter.
3. Résultats
a) Wordlist : liste de lemmes
L’outil Wordlist de Sketch Engine permet d’afficher sous la forme d’un tableau la liste des lemmes de chaque corpus selon leur ordre d’apparition fréquentiel. Par souci de cohérence et dans le but d’obtenir un résultat plus explicite, nous avons choisi de retirer de la liste tous les mots non porteurs de sens comme les articles définis et indéfinis (le, la, les, un, une, des…), les conjonctions de coordination et de subordination (et, mais, ou, que, qui…), et les auxiliaires (a, est…). La liste des lemmes classés par fréquence d’emploi selon chaque corpus de textes est disponible en Annexe 4. Nous remarquons que les lemmes utilisés par les directeurs artistiques et les chefs d’orchestre sont globalement assez similaires et relatifs aux thématiques suivantes :
- actions liées au processus d’enregistrement (faire, écouter, travailler, jouer, enregistrer, montage…)
- communication (échanger, discuter, demander, parler…)
- collaboration (confiance, ensemble, besoin, relation…)
- gestion du temps (temps, séance, vite, gérer…)
Il convient d’ajouter que les pronoms « je » (personnel) et « on » (impersonnel) ont été volontairement conservés dans ces listes. En effet, selon Pras (dans Bénet, 2018), ces mots sont « indicateurs de l’implication de celui qui parle dans son discours ». Ainsi « je » et « moi » révéleraient un discours plutôt individuel et personnel, alors que « on » semblerait traduire une conception plus collective du phénomène évoqué. En prenant en compte cette règle, il semblerait que les directeurs artistiques adoptent une conception de l’enregistrement plus collective (2,84% de « on », 1,57% de « je ») que les chefs d’orchestre (3,69% de « je », et de « moi », 2,10% de « on »).
b)Thésaurus
Sketch Engine permet également de créer automatiquement un thésaurus et de le rendre explicite grâce à un outil de visualisation. Dans le domaine de la linguistique et de l’analyse de contenu, un thésaurus est un répertoire de plusieurs lemmes structuré autour d’un mot-clé préalablement défini. Dans le cas d’un corpus constitué de transcriptions d’entretiens, le thésaurus se révèle être un outil très utile puisqu’il permet de voir rapidement les associations de mots ou d’idées qui ont été faites par les participants à l’étude. Nous avons ici choisi de représenter trois thèmes clés abordés continuellement au cours de nos entretiens : l’enregistrement, les échanges et le temps.
L’enregistrement
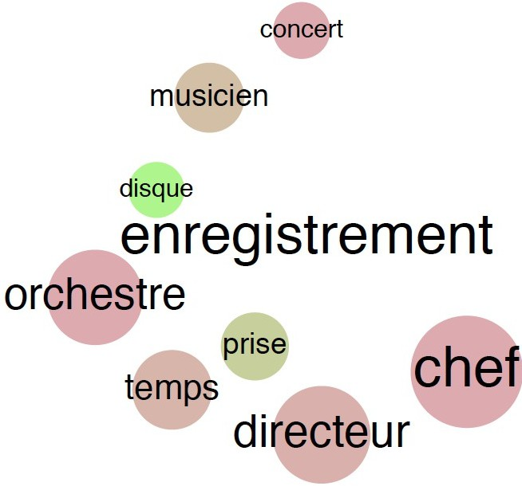

Les représentations schématiques du thésaurus sont immédiatement lisibles et compréhensibles. Ainsi, nous pouvons voir que pour les directeurs artistiques comme pour les chefs d’orchestres, l’enregistrement est associé à la notion de temps et à ses différents acteurs : le chef, le directeur (artistique) et les musiciens. Pour les chefs d’orchestre, l’enregistrement semble être un travail qui implique des prises de décisions (choix) et des discussions (remarque). Enfin, les directeurs artistiques associent l’enregistrement à la notion de résultat final (le disque) et au déroulé des séances (les prises).
Les échanges

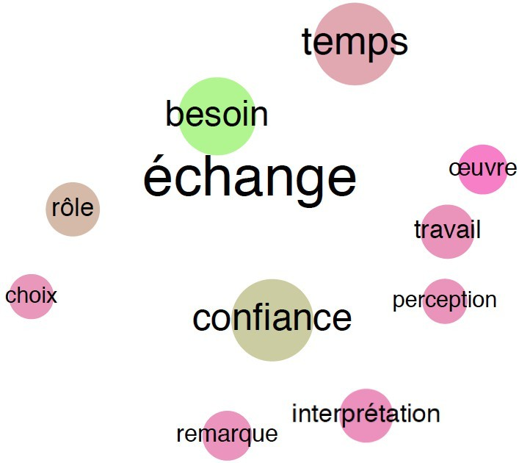
La notion de temps est ici encore mise en lumière. Elle pourrait être l’un des principaux sujets d’échange entre le directeur artistique et le chef d’orchestre. Des idées d’ordre artistique (interprétation, tempo, œuvre) y sont également associées. Enfin, les chefs d’orchestre semblent sensibles à la notion de confiance et au besoin de dialoguer.
Le temps
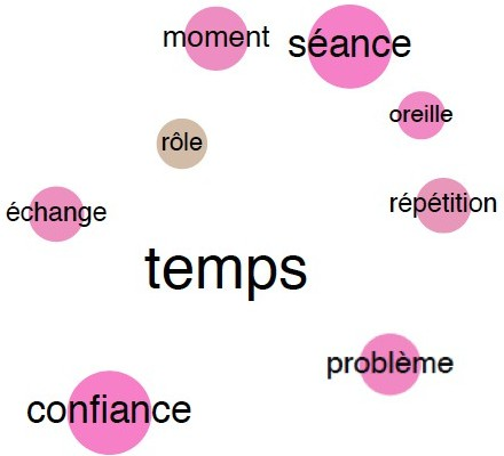
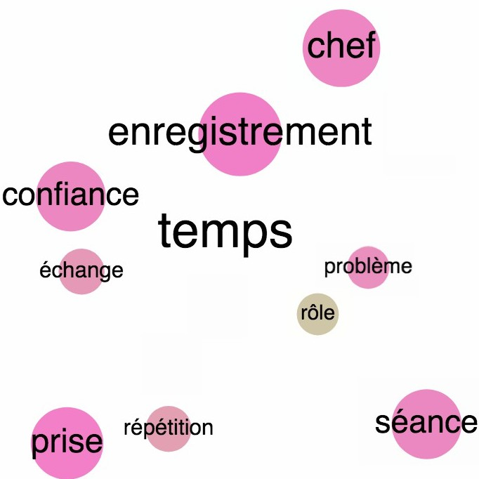
Nous avons choisi d’approfondir les résultats obtenus jusqu’ici en étudiant les termes associés par les directeurs artistiques et les chefs d’orchestre au lemme temps. On retrouve dans les deux corpus les notions de dialogue (échange) et de confiance. Le temps semble être un facteur décisif dans la réalisation d’un enregistrement puisqu’il est associé par les directeurs artistiques et les chefs d’orchestre à la notion de problème.
c) Discussions
Au vu de ces résultats, il semble que l’analyse de contenu ne permette d’appréhender que de façon globale les propos recueillis. Néanmoins nous avons pu identifier certains thèmes abordés par les directeurs artistiques et les chefs d’orchestre : la communication, la collaboration artistique et la gestion du temps. Élaborer comme nous l’avons fait une liste de lemmes classés par occurrence et un thésaurus est un premier point d’entrée dans l’analyse. C’est une approche qui a le mérite de mettre en évidence dans les grandes lignes certains concepts abordés par les personnes interrogées. Cependant, cette démarche analytique semble insuffisante puisqu’elle ne permet pas d’extraire en profondeur le sens des données collectées. Le discours est découpé et les mots sont étudiés hors de leur contexte précis. L’analyse de contenu ne permet pas de formuler des réponses concrètes à notre problématique de recherche.
Ainsi, il nous paraît essentiel de compléter notre démarche d’investigation en utilisant une autre méthode d’analyse qualitative pour réévaluer, confirmer et préciser les résultats obtenus jusqu’ici.
IV. Analyse par théorisation ancrée
« L’analyse qualitative se présente comme un acte à travers lequel s’opère une lecture des traces laissées par un acteur ou un observateur relativement à un événement de la vie personnelle, sociale ou culturelle. »7
1. Principe de la méthode
Développée en 1967 par Glaser et Strauss sous le terme de « grounded theory » (Glaser & Strauss, 2017), l’analyse par théorisation ancrée est une démarche itérative progressive d’un phénomène qui, contrairement à l’analyse de contenu, n’est ni prévue ni liée à l’itération ou à l’ordre d’apparition des lemmes. Paillé parle d’un « acte de conceptualisation » (Paillé, 1994).
La singularité de cette méthode réside dans le fait que la collecte des données et l’analyse se font de manière simultanée et ce, contrairement aux méthodes plus habituelles qui préconisent d’abord une longue phase de collecte, puis une phase d’analyse de l’ensemble du corpus. A intervalles réguliers de deux entretiens, nous avons procédé à la transcription des données, puis à leur analyse. Cette analyse, au début relativement élémentaire voire superficielle, a le mérite de s’affiner et de se complexifier au fil des entretiens. Cette démarche de recherche inscrit le chercheur dans un “processus de questionnement” (Paillé, 1994, p.152) constant qui amène à vouloir toujours mieux comprendre et expliquer l’objet d’étude.
En théorie, il est possible de discerner six étapes dans le processus d’analyse par théorisation ancrée (Paillé, 1994) :
- la codification : les propos sont déconstruits en groupes de mots et sont par la suite codifiés, étiquetés selon le sens qu’ils véhiculent (de quoi me parle-t-on ?) ;
- la catégorisation : permet d’affiner la phase de codification, début de la conceptualisation (de quel phénomène est-il réellement question ?) ;
- la mise en relation : les différentes catégories sont regroupées (pourquoi et comment le sont-elles ?) l’intégration : permet de cerner l’enjeu du propos et de centrer l’analyse sur un objet précis ;
- la modélisation : synthèse des trois premières étapes faisant suite aux résultats de l’intégration (comment le phénomène étudié fonctionne-t-il si l’on se base sur les catégories identifiées précédemment ?)
- la théorisation : étape finale du processus.
Afin de présenter notre analyse, nous avons choisi de regrouper nos résultats sous la forme de tableaux synthétiques. Chaque tableau correspond à une catégorie identifiée et regroupe les sous-catégories et les concepts émergents correspondants et leurs occurrences totales dans tout le corpus.
| CATÉGORIE | |||
| Sous-catégorie 1 | Concept émergent 1 | partagé par… | occurrence totale |
| Concept émergent 2 | partagé par… | occurrence totale | |
| … | partagé par… | occurrence totale | |
| Concept émergent n | partagé par… | occurrence totale | |
| Sous-catégorie 2 | Concept émergent 1 | partagé par… | occurrence totale |
| Concept émergent 2 | partagé par… | occurrence totale | |
| … | partagé par… | occurrence totale | |
| Concept émergent n | partagé par… | occurrence totale | |
| … | … | … | … |
| Sous-catégorie n | Concept émergent 1 | partagé par… | occurrence totale |
| Concept émergent 2 | partagé par… | occurrence totale | |
| … | partagé par… | occurrence totale | |
| Concept émergent n | partagé par… | occurrence totale | |
2. Présentation des résultats
Il convient avant toute chose de mentionner la convention adoptée pour référencer de manière anonyme les participants. L’acronyme CO se rapporte aux chefs d’orchestre. L’acronyme DA se rapporte aux directeurs artistiques. Les chiffres de 1 à 6 n’ont pas de signification particulière et sont simplement utilisés pour compléter le référencement.
37 concepts ont émergé de l’analyse, que nous avons regroupés en 4 grandes catégories :
- ASPECTS RELATIONNELS : ensemble des rapports professionnels (hors échanges) qui lient le directeur artistique et le chef d’orchestre ;
- EXPERTISE DU DIRECTEUR ARTISTIQUE : ensemble des compétences du directeur artistique dans le contexte particuler imposé par l’étude ;
- NATURE DES ÉCHANGES : présentation des discussions mises en place entre le directeur artistique et le chef d’orchestre ;
- ORGANISATION DU TRAVAIL : ensemble des éléments relatifs ayant trait à la logistique de l’enregistrement dans le contexte particulier imposé par l’étude.
Le tableau ci-dessous synthétise les résultats obtenus après analyse des données.
| CATÉGORIES | SOUS-CATÉGORIES |
| ASPECTS RELATIONNELS | Dimension collaborative |
| Relation de confiance | |
| Rapports hiérarchiques | |
| Dimension psychologique | |
| EXPERTISE DU DIRECTEUR ARTISTIQUE | Action artistique |
| Responsabilités | |
| Adaptation selon le contexte d’enregistrement | |
| NATURE DES ÉCHANGES | D’ordre musical |
| D’ordre organisationnel | |
| D’ordre technique | |
| ORGANISATION DU TRAVAIL | En amont |
| En post-production | |
| Contraintes temporelles | |
| Méthodes d’enregistrement |
a) Aspects relationnels
La direction artistique est un domaine dans lequel les relations humaines occupent une place de premier plan. Tous les participants se sont exprimés à ce sujet. La catégorie Aspects relationnels regroupe l’ensemble des éléments ayant trait aux rapports professionnels entretenus par le directeur artistique et le chef d’orchestre.
Le tableau suivant synthétise les propos tenus et les rassemble dans quatre sous-catégories : “Dimension collaborative”, “Relation de confiance”, “Rapports hiérarchiques” et “Dimension psychologique”.
| ASPECTS RELATIONNELS | |||||
| Dimension collaborative | complémentarité du chef d’orchestre et du directeur artistique | CO1, CO3, DA6 | DA1, DA3, | CO2, CO4, | 17 |
| partage d’une vision artistique commune | CO2, DA4 | CO4, | DA2, | 6 | |
| communication | CO1, DA2, CO4, DA6 | DA3, | 5 | ||
| Relation de confiance | nécessité d’une confiance mutuelle | CO1, CO2, CO3, CO4, DA5, DA6 | 14 | ||
| délégation du travail | CO2, CO3, CO4 | 6 | |||
| Rapports hiérarchiques | existence d’une autorité | CO1, CO3, DA6 | DA1, DA3, | CO2, DA4, | 12 |
| rapports modifiés en cas de présence d’une tierce personne | DA1, DA2, DA4, DA6 | DA3, | 8 | ||
| Dimension psychologique | trouver une entente commune | DA1, CO3, DA6 | CO2, DA3, | DA2, CO4, | 9 |
| comprendre son interlocuteur | DA2, CO3, DA4, DA5 | DA3, | 12 | ||
| pression et fatigue | CO1, DA2, DA5 | CO2, DA3, | CO3, DA4, | 10 | |
Dimension collaborative
Ce qui relève de la dimension collaborative dans les aspects relationnels touche à l’ensemble des paramètres relatifs à l’élaboration d’un travail effectué en commun par le directeur artistique et le chef d’orchestre.
Complémentarité des rôles
La collaboration entre le directeur artistique et le chef d’orchestre semble se construire sur la complémentarité des rôles de chacun. Le travail du directeur
artistique et celui du chef d’orchestre sont interdépendants. Tous deux œuvrent ensemble et convergent vers un but artistique commun.
✔ “C’est pour moi un métier très important. Le directeur artistique est quelqu’un qui accouche du résultat avec l’artiste.” (CO2)
✔ “Il existe entre le chef et le directeur artistique un partenariat très enrichissant et le plus souvent très intense. C’est vraiment un duo qui fonctionne main dans la main.” (CO1)
Pour certains participants, cette complémentarité se traduit par le fait que le rôle du chef d’orchestre et celui du directeur artistique sont parfois similaires. La fonction de chacun requiert des qualités musicales et relationnelles.
✔ “Chacun a son rôle mais il y a une partie des activités qui pourraient être faites et par l’un et par l’autre.” (DA1)
✔ “J’ai besoin de quelqu’un qui a effectivement la lecture presque d’un chef d’orchestre de la partition, et qui soit capable de l’entendre comme moi. S’il y a une erreur que j’ai pu laisser passer, alors le directeur artistique sera capable d’en faire part.” (CO3)
✔ “Pour moi ce sont deux métiers très complémentaires… je dirais même que c’est un peu le même métier. On doit écouter, comprendre l’oeuvre, gérer des musiciens…” (CO4)
L’un des participants à notre étude affirme que le directeur artistique est en fait un chef d’orchestre assistant. Son action serait de soutenir et si besoin de compléter la vision artistique du chef.
- “À plusieurs reprises j’ai eu l’impression d’avoir le rôle d’assistant du chef, parce que finalement c’est un boulot assez similaire : noter sur la partition ce qui n’allait pas, aider dans la balance générale de l’orchestre, donner un point de vue sur l’interprétation si c’est demandé, etc.” (DA6)
Enfin, s’il le juge nécessaire, le directeur artistique peut compléter les propos du chef d’orchestre, par exemple en signalant un problème que celui-ci n’aurait pas évoqué ou en approfondissant une remarque faite à l’orchestre.
- “Le directeur artistique peut proposer des choses complémentaires mais non redondantes avec ce que j’ai déjà dit à l’orchestre.” (CO1)
- “Parfois il m’arrive de préciser les propos du chef aux musiciens. Si jamais un détail lui a échappé, je me permets d’intervenir pour compléter son intervention.” (DA4)
Partage d’une vision artistique commune
L’aspect collaboratif peut aussi se manifester à travers le partage d’une vision artistique commune. L’action de tendre ensemble vers un but commun permet de mobiliser les esprits et les compétences. Cela incite chacun à investir le maximum de lui-même pour atteindre le résultat souhaité.
- “Il faut que tout le monde travaille dans le même sens, il faut que le chef d’orchestre, le directeur artistique et l’orchestre travaillent en harmonie, le plus efficacement possible et ce, pour le bien du projet artistique.” (DA4)
- “C’est tout de suite beaucoup plus riche quand le chef et moi on sait qu’on veut travailler ensemble dans une direction artistique commune. On a vraiment envie de s’investir à fond. Et le résultat sera tout de suite plus intéressant.” (DA3)
L’un des participants à l’étude souligne cet aspect en affirmant que toute collaboration professionnelle entre un directeur artistique et un chef d’orchestre sera conditionnée par les goûts de chacun.
- “Je pense qu’on ne peut pas marier n’importe quel directeur artistique avec n’importe quel chef d’orchestre, parce qu’à un moment donné, artistiquement parlant, il va s’agir de goût dans un sens très profond.” (CO2)
Communication
Avoir les mêmes objectifs artistiques et donner un sens commun au projet d’enregistrement ne suffit pas. Le dialogue étant la base de toute relation professionnelle, il est nécessaire que le directeur artistique et le chef d’orchestre puisse clairement communiquer.
- “Il faut parler. C’est la base du rapport que j’entretiens avec le directeur artistique.” (CO1)
- “Tout passe par le dialogue.” (DA3)
Cependant, certains participants nous ont fait part de leurs difficultés à communiquer avec leur interlocuteur. Un manque de communication peut s’avérer problématique et même ruiner une séance d’enregistrement.
- “J’ai récemment fait un enregistrement avec un chef qui n’était pas compétent, pas collaboratif avec moi. Il y avait un très gros problème de communication. On ne se comprenait pas. On perdait énormément de temps et ça compromettait grandement le devenir de l’enregistrement en question.” (DA6)
- “Je me souviens d’un très mauvais incident. Le directeur artistique, au lieu de passer par moi, commençait à prendre le pouvoir sur tous les musiciens et finalement à faire mon boulot. C’est devenu ingérable parce qu’il arrêtait lui-même l’orchestre, il commençait à prendre des initiatives qui étaient complètement déplacées. Ma légitimité a été un peu remise en cause et on n’arrivait pas à communiquer. C’était quelqu’un qui prenait trop de place et qui n’avait pas conscience des rôles que lui et moi on devait avoir.” (CO4)
Bien que la communication soit un point crucial dans toute collaboration professionnelle, elle peut parfois faire défaut. Nous étudierons ultérieurement dans une catégorie dédiée la nature intrinsèque des échanges entre le directeur artistique et le chef d’orchestre.
Relation de confiance
Cette catégorie regroupe les propos des participants ayant trait à la notion de confiance dans le rapport entretenu par le directeur artistique et le chef d’orchestre.
Nécessité d’une confiance mutuelle
Une collaboration artistique est efficace si elle s’inscrit dans un contexte où la confiance est de mise. Pour la majorité des participants à notre étude, la confiance est nécessaire afin de garantir le bon déroulement de l’enregistrement : elle simplifie les relations sociales et favorise le dialogue.
- “Je pense que le mot le plus important c’est la confiance. Quand je n’ai pas totalement confiance en le directeur artistique, je trouve que ça fragilise tout l’objet parce que je ne sais plus sur quels œufs marcher, je ne sais plus dans quel sens aller. Pour moi, notre relation doit absolument être basée sur une totale confiance.” (CO3)
- “Toute cette collaboration ne fonctionne que si le duo marche bien et que le travail se fait à deux, dans un climat de confiance qui favorise l’échange artistique.” (CO1)
La relation de confiance doit être réciproque. Le directeur artistique se doit de considérer le chef d’orchestre comme un interprète ayant ses propres conceptions musicales et ses propres objectifs à atteindre. En retour, le chef d’orchestre doit accorder toute sa confiance au directeur artistique qui est là pour le conforter dans ses idées musicales, mais aussi pour gérer l’ensemble des paramètres du projet,
- “Le directeur artistique est un partenaire privilégié. Je dois lui faire confiance et il doit me faire confiance, car sinon notre collaboration sera stérile.” (CO3)
- “Le directeur artistique doit avoir confiance en mes idées musicales d’interprète, même si je suis prêt à les discuter, mais seulement quand c’est pertinent.” (CO2)
- “En séance, vu qu’on a peu de temps, les chefs sont vraiment obligés de nous faire confiance.” (DA5)
Délégation
Une relation de confiance mutuelle se manifeste quand les chefs d’orchestre prennent la décision de déléguer certaines tâches au directeur artistique, dans le but de se focaliser sur des éléments qui leur paraissent plus essentiels.
- “S’il croit en lui, le directeur artistique est une personne sur laquelle le chef se repose pendant la séance, de manière à ce qu’il n’ait qu’à se concentrer sur l’interprétation de l’œuvre.” (CO4)
- “Personnellement, je n’aime pas forcément avoir la main sur le déroulé de la séance et j’aime bien compter sur quelqu’un comme le directeur artistique pour déléguer la gestion du temps.” (CO3)
Rapports hiérarchiques
Cette catégorie regroupe l’ensemble des éléments relatifs à la notion d’autorité au sein des aspects relationnels. La collaboration entre le chef d’orchestre et le directeur artistique se construit aussi selon les lois de la hiérarchie.
Existence d’une autorité
Pour la majorité des participants, l’existence d’une autorité est indiscutable : il s’agit de celle de l’interprète. Par conséquent, le chef d’orchestre, de par sa position légitime d’interprète, a dans la plupart des cas toujours le dernier mot.
- “S’il y a une prise de décision, c’est moi qui en aurait le dernier mot et pour une raison que j’argumente toujours à chaque fois.” (CO2)
- “Le chef d’orchestre, c’est l’acteur principal puisque c’est lui l’interprète, c’est lui qui dirige. Si on a une divergence de type musical, je laisse faire le chef d’orchestre parce que c’est lui qui décide. Il aura toujours le dernier mot.” (DA5)
- “Des fois, on a beau faire des suggestions, et même si on croit que ce qu’on propose est meilleur, si le chef ne veut pas, il le veut pas.” (DA3)
Le directeur artistique, est lui aussi en mesure de faire valoir une certaine forme d’autorité sur les musiciens et sur le chef. Il se doit cependant de la justifier auprès d’eux. La vision globale qu’il possède de l’ensemble du projet est telle que le directeur artistique peut très bien prendre une décision et l’imposer s’il considère que c’est dans l’intérêt de l’enregistrement.
- “Le directeur artistique est en cabine, il sait exactement ce qu’il fait, c’est lui qui est aux commandes et s’il dit qu’il faut refaire une prise, c’est qu’il faut la refaire parce que ce qu’on a fait avant n’était pas bon.” (CO1)
- “Le directeur artistique assied en quelque sorte une certaine autorité ou du moins un impact positif par rapport au groupe. C’est quelqu’un dont les musiciens voient que j’attends sa validation pour aller plus loin.” (CO3)
L’un des participants à l’étude nous a fait part d’un avis plus nuancé sur la question : il considère qu’aucune hiérarchie n’existe entre le directeur artistique et le chef d’orchestre. Tous deux sont sur le même pied d’égalité.
- “Et tout ça dans un échange d’égal à égal, sans hiérarchie, comme deux alter ego travaillant ensemble. Et quand c’est comme ça, ça marche bien.” (CO3)
Modification des rapports hiérarchiques
Les rapports hiérarchiques entre le directeur artistique et le chef d’orchestre semblent être impactés si l’enregistrement implique une troisième personne décideuse et force de proposition. La plupart des directeurs artistiques interrogés ont mentionné diverses situations liées à la présence d’un soliste ou d’un compositeur. Dans le cas d’un concerto, le soliste sera l’interlocuteur privilégié du directeur artistique et du chef d’orchestre. Il sera aussi la plupart du temps le décideur final car c’est avant tout son disque. Dans le cas d’une pièce contemporaine, la présence du compositeur va également changer les rapports entre le directeur artistique et le chef d’orchestre.
- “La relation qu’on a avec le chef va aussi changer si le compositeur est présent ou si on fait un concerto avec soliste. Dans le cadre d’un concerto traditionnel, ça rajoute une personne avec qui je vais avoir un échange et dont l’avis sera aussi important.” (DA3)
- “Le compositeur est le plus souvent en cabine avec moi. Il peut être une sorte de deuxième directeur artistique et va parfois se placer entre le chef et moi. Si quelque chose ne lui plaît pas, il le dira directement au chef ou me demandera de relayer sa remarque.” (DA1)
- “Évidemment, ça peut ajouter des complications mais ça peut aussi être plutôt divertissant d’avoir une troisième personne qui vient elle aussi apporter une vision de la musique qu’on joue. Ce n’est pas nécessairement une complication sur le plan musical, mais c’est sûr que le cadre devient encore un peu plus serré.” (DA2)
Dimension psychologique
Nous définissons la dimension psychologique comme l’ensemble des paramètres liés au domaine comportemental et affectif. Le directeur artistique et le chef d’orchestre doivent prendre en compte ces paramètres dans la relation professionnelle qu’ils entretiennent.
Trouver une entente commune
Pour le bon déroulement de l’enregistrement, les participants soulignent qu’une atmosphère de bonne entente est nécessaire. Il est ici question pour le directeur artistique et le chef d’orchestre de savoir nouer une relation de qualité avec son entourage professionnel.
- “Je vais toujours voir le chef avant et après la séance, ne serait-ce que pour dire bonjour, pour créer quelque chose de positif entre nous. C’est important de tisser un minimum de lien avec la personne avec qui on travaille.” (DA1)
- “J’ai beaucoup aimé Harnoncourt, notamment à cause de sa qualité humaine. Il était d’une gentillesse et d’une grande générosité. On s’entendait à merveille et tout se déroulait très bien.” (DA2)
Comme dans toute collaboration professionnelle, certains problèmes liés à des questions de personnalité peuvent se poser. Comme nous l’avons vu précédemment, une atmosphère de confiance réciproque est nécessaire au bon déroulement de l’enregistrement. Cependant, il semble pertinent de parler ici d’un sens du feeling : certaines collaborations fonctionnent bien, d’autres non.
- “On peut avoir des points de divergences qui soient liés au fait que nos deux personnalités ne correspondent pas. C’est parfois une question de feeling. C’est aussi une question d’avoir envie de travailler avec telle ou telle personnalité.” (CO3)
- “Certains chefs ont vraiment des personnalités difficiles. Je me souviens avoir été viré d’un projet parce que ça ne fonctionnait vraiment pas avec le chef qui faisait preuve d’une mauvaise foi sans nom…” (DA6)
- “Je me souviens d’un enregistrement avec un chef d’orchestre au caractère très spécial et très froid. La séance s’est très mal déroulée, il n’avait aucune envie de faire, il laissait passer des choses pas en place ou fausses… Et il a quitté la séance au bout de 10 minutes car il en avait marre.” (DA4)
Comprendre son interlocuteur
Le directeur artistique doit être capable de comprendre son interlocuteur, de cerner ses envies artistiques pour pouvoir s’adapter en conséquence.
- “J’ai besoin de quelqu’un qui se rapproche de ce que je suis et de ce que j’ai envie d’essayer de faire avec l’orchestre avec lequel je travaille. Le directeur artistique doit avoir la capacité à comprendre les artistes qui sont de l’autre côté des micros et pour le coup savoir adapter sa personnalité à ce qu’il reçoit.” (CO3)
- “Il faut être capable de ressentir les interprètes qu’on a en face de nous, et de s’adapter en conséquence.” (DA4)
- “En fait, le directeur artistique c’est beaucoup de psychologie. Le plus difficile c’est de trouver la limite à ne pas franchir. On voit bien dans le ton quand ça commence un peu à se raidir et qu’on se dit qu’on est allé trop loin.”
Pression et fatigue
Pour le chef d’orchestre, l’enregistrement est une source de fatigue et de pression psychologique auxquelles il est indispensable de faire face. Le directeur artistique doit en être conscient et tenir compte des contraintes qui en découlent.
- “Le chef d’orchestre est sur la sellette avec les musiciens et il ressent l’atmosphère, l’ambiance et les tensions psychologiques qu’il peut y avoir parmi les musiciens. Il faut savoir que les enregistrements ce sont des moments très tendus pour les musiciens. Il y a parfois une tension assez extrême parce qu’on est à nu, on est à découvert, on entend tout, il faut que tout soit parfait. Dès qu’il y a un truc qui ne va pas, si c’est un instrument qui ne va pas, ça fait refaire la prise pour les 80 autres musiciens qui sont là. Du coup c’est une pression psychologique qui est énorme pour tous les musiciens.” (CO1)
- “L’enregistrement est un moment où le bonheur, la joie, le bien-être ne sont pas forcément au rendez-vous. C’est un moment très particulier pour un artiste qui se retrouve devant un espèce de super-miroir en face de lui, qui lui renvoie une super image de ce qu’il est, de ses qualités comme de ses faiblesses.” (CO2)
- “Et la fatigue, la lassitude, ce sont aussi des facteurs à prendre en compte.” (DA4)
b) Expertise du directeur artistique
La catégorie Expertise du directeur artistique se rattache à l’ensemble de compétences qui transparaissent chez le directeur artistique dans l’exercice de sa fonction. Nous avons identifié trois sous-catégories : “Action artistique”, “Responsabilités” et “Adaptation au contexte d’enregistrement”.
Le tableau ci-dessous synthétise les résultats.
| EXPERTISE DU DIRECTEUR ARTISTIQUE | |||
| Action artistique | oreille extérieure | CO1, DA1, CO2, DA2, CO3, DA3, CO4, DA4, DA5, DA6 | 24 |
| conseil musical | DA1, CO2, DA2, CO3, DA3, CO4, DA6 | 16 | |
| accompagner le chef dans le processus d’enregistrement | CO1, CO2, DA2, CO3, DA3, DA5 | 15 | |
| Responsabilités | gestion du projet dans sa globalité | CO1, DA1, DA2, CO3, DA3, CO4, DA4, DA5, DA6 | 18 |
| gestion du temps | DA2, CO3, CO4, DA4, DA5 | 6 | |
| gestion du son | DA2, DA3, CO3, CO4, DA6 | 6 | |
| Adaptation selon le contexte d’enregistrement | selon l’effectif | DA1, CO2, DA2, DA3, DA5 | 7 |
| selon la méthode d’enregistrement | DA1, DA2, DA4, DA5 | 5 | |
| selon la personnalité du chef | DA3, DA4, DA5, DA6 | 6 | |
Action artistique
La sous-catégorie Action artistique rassemble l’ensemble des compétences du directeur artistique d’un point de vue purement musical. Nous regroupons ici les aspects de son métier qui seront exclusivement portés sur les enjeux musicaux et artistiques.
Oreille extérieure
L’intégralité des participants considère que l’une des fonctions premières du directeur artistique est de faire office d’oreille extérieure pour le chef d’orchestre. Une grande partie des chefs nous ont fait part de leurs difficultés à prendre du recul lorsqu’ils sont au pupitre. Diriger un orchestre implique une grande concentration. Il est n’est pas possible pour le chef de pouvoir tout écouter simultanément.
- “Il y a un foisonnement d’activité, de notes, d’interactions, et le chef seul ne peut pas forcément tout entendre.” (CO2)
- “Quand on est dans l’action de diriger on ne peut pas en permanence tout scanner et on peut laisser passer des choses.” (CO3)
Le directeur artistique semble pouvoir répondre à ce besoin en proposant au chef d’orchestre une écoute supplémentaire. De par sa position géographique, en régie, il a le rôle d’un auditeur extérieur.
- “En cabine, avec les écouteurs, on entend beaucoup plus de choses que tous ceux qui sont sur scène et qui jouent.” (CO1)
- “Je suis parfois plus à même que le chef pour entendre certaines choses.” (DA5)
L’écoute du directeur artistique est double. Elle doit tout d’abord se focaliser sur les aspects les plus généraux de l’enregistrement. Le directeur artistique est la seule personne à avoir une vision d’ensemble du projet et à pouvoir la rapporter au chef d’orchestre.
- “J’ai besoin de quelqu’un qui a une perception globale du son, une chose que moi je ne peux avoir que rarement au pupitre.” (CO3)
- “J’ai une vision globale de la séance, mais aussi de la journée, des trois jours d’enregistrement, et de la balance. J’ai aussi la notion de ce qu’on va faire après en post-production, et ça en général les chefs ne le conçoivent pas tout fait. ” (DA5)
Le deuxième aspect de l’écoute du directeur artistique est plus critique et se porte davantage sur les détails : en se basant sur la partition de l’œuvre enregistrée, il doit être en mesure de repérer les erreurs commises par l’orchestre.
- “Mon rôle, de par mon oreille, c’est avant tout d’avoir la capacité à repérer ce qui n’est pas ensemble, ce qui n’est pas juste, etc. Il s’agit de direction artistique de base. Je regarde la partition et il faut que ce qu’on entend ressemble le plus possible à ce qui est écrit.” (DA1)
- “En fait, cette oreille du directeur artistique a une utilité très importante : étant un peu en retrait, elle détecte tout de suite s’il y a quelque chose qui est incohérent.” (DA3)
Par conséquent, le chef d’orchestre a besoin de compter sur une écoute attentive, pertinente et constructive de la part du directeur artistique.
- “J’attends que très vite à la fin d’une prise, le directeur artistique ait entendu et compris comme moi ce qui a été, ce qui n’a pas été, en une demi-seconde.” (CO3)
- “Le directeur artistique, c’est l’écoute active, et constructive, des interprètes qui enregistrent.” (CO2)
Enfin, l’un des participants à notre étude souligne le compromis auquel le directeur artistique doit faire face pour ne pas déstabiliser les interprètes avec une écoute trop critique.
- “Ce qui est difficile pour le directeur artistique, c’est en même temps d’être une oreille très attentive, très rigoureuse et précise sans pour autant être une oreille castratrice ou une oreille trop froide. Il faut donc trouver un juste milieu entre les deux.” (CO2)
Conseil musical
Le terme “conseil musical” regroupe l’ensemble des suggestions et des avis musicaux donnés par le directeur artistique au chef d’orchestre. Il s’agit de la forme la plus concrète de l’influence que peut avoir le directeur artistique. Il peut suggérer des idées musicales et être force de proposition auprès du chef d’orchestre.
- “Le rôle le plus noble et le plus délicat du directeur artistique, c’est d’écouter ce que font les artistes sur un plan purement musical et artistique, et de donner son avis. Selon les cas, on donne son avis plus ou moins librement, mais je ne me prive jamais de dire si je ne suis pas d’accord avec un tempo, une balance, un phrasé, le respect de la partition, etc. J’ai travaillé avec un certain nombre de chefs et d’orchestres pour qui cela était extrêmement important et donc j’ai été imprégné par ce point de vue.” (DA2)
- “On est là aussi pour leur suggérer certaines choses. On peut animer, donner vie d’une autre manière au contenu musical. Et c’est au chef de s’en approprier. S’en approprier, j’insiste bien là-dessus. S’en approprier, sinon ça n’a aucune valeur.” (DA3)
- “Quand j’ai le temps, ce qui est intéressant, c’est de proposer des choses, une lecture différente ou complémentaire de celle du chef.” (DA6)
Plusieurs chefs d’orchestre ont déclaré être sensibles aux suggestions du directeur artistique. Il doit être capable d’exprimer clairement son opinion sur le travail du chef, afin que celui-ci puisse corriger et améliorer certains points en vue de la prise suivante.
- “J’aime bien que le directeur artistique puisse avoir une vue objective et distanciée de ce que je suis en train de faire et qu’il soit capable, et ça c’est une qualité que j’attends, de me dire que non là musicalement, ça ne marche pas, il y a un truc qui ne va pas, ou alors un ralenti qui est mal négocié, etc.” (CO3)
Enfin, si le chef est suffisamment en confiance et réceptif, les conseils du directeur artistique peuvent parfois prendre la forme d’une aide à l’interprétation.
- “J’aime quand le directeur artistique est présent pour me dire qu’il peut y avoir encore plus d’intention, qu’on peut faire un tempo encore plus rapide, ou au contraire étirer les sons, prendre des risques à tel ou tel moment, etc. Finalement, il s’agit beaucoup plus d’enjeux d’interprétation que d’enjeux purement techniques.” (CO2)
- “En musique contemporaine, on me demande parfois comment interpréter, comme faire sonner tel ou tel son, ça peut arriver.” (DA1)
Accompagner le chef
Le rôle du directeur artistique est aussi de guider le chef d’orchestre tout au long du processus musical. Il aide le chef, le conforte dans la réalisation de ses idées.
- “Mon rôle c’est quand même en quelque sorte un rôle de serviteur, de ministre. J’aide le chef à traduire ce qu’il veut au travers de la partition. Et pour cela il a parfois besoin d’être guidé.” (DA2)
Plusieurs chefs d’orchestre ont déclaré vouloir être stimulés, poussés dans leurs retranchements afin de parvenir à un résultat artistique encore meilleur.
- “Mes meilleurs souvenirs avec un directeur artistique, ce sont les moments où cette personne se montre être vraiment surprenante. Surprenante dans un sens qui me stimule dans les limites ou les barrières que je me fixe, et qui du coup stimule aussi l’orchestre.” (CO2)
- “Récemment, j’ai enregistré une œuvre assez compliquée. On a été à fond jusqu’à la dernière minute et c’est un peu grâce au directeur artistique qui nous a constamment poussé à mieux faire et à aller de l’avant. Évidemment, c’est ça que j’attends d’un directeur artistique.” (CO3)
- “Moi, ce que j’ai la prétention de faire, c’est d’essayer d’arriver à motiver les troupes, à motiver l’envie de jouer pour qu’il se passe quelque chose. La nature des relations entre le directeur artistique et le chef est plutôt dans la tentative de renforcement positif et de guidage.” (DA3)
A l’inverse, le directeur artistique est aussi là pour modérer le chef d’orchestre, afin qu’il reste focalisé sur l’essentiel et qu’il ne se perde dans des détails inutiles.
- “Parfois, il faut vraiment que le directeur artistique gère la séance car les chefs ont plutôt tendance à se perdre dans des trucs… Donc si je sais qu’il reste encore des choses à faire, qu’il ne reste pas énormément de temps, je n’hésite pas à reprendre la main de manière délicate pour calmer les choses et rester sur l’essentiel.” (DA2)
- “Moi j’essaye d’être un bulldozer qui avance et j’attends du directeur artistique que parfois, mais pas trop, il me modère et me dise « attention là on a pas tout ».” (CO3)
Responsabilités
Au cours de notre analyse, le rôle du directeur artistique s’est peu à peu affiné avec l’identification de ses responsabilités. Cette catégorie regroupe les éléments relatifs à la gestion de la logistique par le directeur artistique.
Gestion du projet dans sa globalité
Le directeur artistique est la personne responsable du projet dans toute sa globalité et ce, sur toute la durée de la production. Il assure la liaison entre les différents acteurs impliqués dans le processus d’enregistrement : le chef d’orchestre, les musiciens, le producteur, les chargés de production, la régie d’orchestre…
- “Finalement notre rôle, c’est de réaliser un enregistrement de A à Z.” (DA4)
- “Le directeur artistique a une mission importante sur la globalité du projet : il va diriger l’équipe technique et être en relation avec l’équipe artistique (chef, orchestre, chargés de production, etc).” (DA6)
Le directeur artistique est également responsable de la post-production. Afin d’être en mesure de pouvoir proposer un montage complet et cohérent, il doit s’assurer d’avoir enregistré tout le matériel nécessaire.
- “En situation de studio, le directeur artistique ne doit pas oublier qu’il a pour mission de mettre en boîte un enregistrement complet, et donc d’enregistrer toutes les prises nécessaires.” (DA4)
De ce fait, le directeur artistique est le garant de la qualité artistique et du rendu final de l’enregistrement. Il doit penser au projet dans toute sa globalité.
- “Le rôle du directeur artistique, c’est avant tout de garantir la qualité et l’excellence artistique d’un enregistrement.” (CO1)
- “On a vraiment l’obligation, moi directeur artistique avec l’équipe de production, aussi bien technique et artistique, de donner un résultat qui soit à la hauteur de l’espoir et de l’exigence des artistes.” (DA2)
Gestion du temps
Le directeur artistique va aussi avoir la responsabilité de gérer le temps de la séance d’enregistrement. Il doit faire preuve de stratégie et d’efficacité pour parvenir à enregistrer tout le matériel musical nécessaire au montage du disque et ce, dans un temps imparti.
- “Pour un directeur artistique, la gestion du temps est aussi importante que l’avis technique et l’avis musical.” (DA2)
- “Il faut donc être capable de parfaitement gérer les séances en faisant attention à l’horloge, et voir tout ce qu’on pourra faire dans la durée compte tenu du temps restant.” (DA4)
- “Un enregistrement, ça se fait dans un laps de temps court, et il faut savoir gérer le temps, être réactif, faire les choses rapidement, dans le temps qui est le temps de l’orchestre, qui est un temps très rapide.” (CO3)
- “C’est au directeur artistique de me dire si oui on non on a du temps, c’est sa responsabilité. Je ne peux pas constamment avoir mes yeux sur ma montre. ” (CO2)
Gestion du son
Le directeur artistique doit également répondre de la prise de son et des éventuels problèmes techniques qui pourraient survenir pendant l’enregistrement.
- “Le directeur artistique est là pour donner son avis d’abord d’un point de vue technique : il collabore avec l’équipe d’enregistrement pour élaborer ensemble une prise de son.” (DA2)
- “La frontière entre directeur artistique et ingénieur du son n’est pas si évidente que ça, on est quand même très impliqué dans la réalisation sonore de la captation.” (DA3)
- “Ce qui fait plus peur c’est vraiment les pannes techniques au son et le directeur artistique doit être capable de les gérer, et de gérer 90 musiciens et un chef d’orchestre qui attendent dans le studio.” (DA6)
Adaptation selon le contexte
Dans l’exercice de sa fonction, le directeur artistique doit être capable de faire face à différentes situations. Son rôle est donc variable en fonction du contexte et il doit s’adapter. Les propos relatifs à l’adaptation du directeur artistique sont regroupés dans cette catégorie.
Selon l’effectif
Ce critère ne semble pas faire l’unanimité chez tous les participants, qu’ils soient directeurs artistiques ou chefs d’orchestre. Certains considèrent que le rôle du directeur artistique est identifique quelque soit l’effectif enregistré (et donc la présence ou non d’un chef d’orchestre).
- “Je crois que le rôle du directeur artistique est le même que pour n’importe quel processus d’enregistrement. Il ne diffère pas par exemple avec un disque de musique de chambre ou d’un récital.” (CO2)
- “Pour moi il n’y a pas de différence entre le métier que j’exerce avec un orchestre et celui que j’exerce avec une autre formation.” (DA5)
À l’inverse, l’un des directeurs artistiques interrogés dans cette étude affirme que son métier change considérablement en fonction de la formation enregistrée. Selon lui, musique de chambre et musique d’orchestre auraient chacune une direction artistique propre.
- “De mon point de vue, je différencie vraiment la musique dirigée avec un chef et la musique de chambre. Je ne vais pas du tout faire la même direction artistique, la formation enregistrée est différente et les conditions sont différentes.” (DA1)
Ainsi, la présence du chef pourrait modifier son rôle et l’intéraction que le directeur artistique aura avec les musiciens. Il doit s’adapter en conséquence.
- “En orchestre, il y a quelqu’un entre les musiciens et moi, ce qui n’est pas vrai en musique de chambre, et à partir de là, mon rôle est forcément différent. Ce n’est pas la même chose.” (DA1)
Selon la méthode d’enregistrement
La majorité des directeurs artistiques ont spécifié la nécessité de devoir s’adapter au contexte d’enregistrement.
- “Dans le cas d’un enregistrement de concert, l’influence musicale du directeur artistique est beaucoup plus limité que quand on est en séance. Du coup on a moins l’opportunité de travailler ensemble et il faut s’adapter en conséquence.” (DA2)
- “Mon rôle va être différent si on est en studio ou en concert. Je vais devoir m’adapter au contexte.” (DA3)
Comparé à une situtation d’enregistrement studio, le rôle du directeur artistique dans le contexte d’un enregistrement de concert semble être moins conséquent.
- “En règle générale dans le cas du live, je dirais que le directeur artistique doit encore plus s’adapter et faire la petite souris.” (DA4)
Selon la personnalité du chef
Enfin , le rôle du directeur artistique va varier en fonction de la personne avec qui il travaille. Il doit s’adapter à la personnalité du chef qu’il a en face de lui, à ses envies, ses demandes et ses attentes.
- “Je ferais la différence entre les chefs qui savent ce qu’ils veulent, qui ont des envies, et ceux qui cherchent et ne savent pas trop. Avec ces derniers on peut faire tout ce que l’on veut. Avec les autres c’est différent, il faut s’adapter en fonction de ce qu’ils souhaitent.” (DA3)
- “Je pense que le directeur artistique doit avoir la capacité de s’adapter suivant les chefs d’orchestre. Il doit sentir ce qu’il veut, à savoir est-ce qu’il veut qu’on gère la séance en nous faisant confiance ou bien au contraire est-ce qu’il veut tout gérer et reléguer un peu le directeur artistique à un rang inférieur ?” (DA4)
- “Notre action artistique va dépendre du chef qu’on va avoir en face de nous. Certains chefs vont se reposer à 100% sur le directeur artistique en lui demandant ce qu’il doit faire dès la première prise. A l’inverse il y a des chefs qui ne vont te laisser rien faire. C’est vraiment du cas par cas, il faut s’adapter. Et donc ça va énormément influencer ma façon de travailler.” (DA6)
c) Nature des échanges
L’enregistrement est un terrain propice au dialogue. Précédemment, nous avons étudié les aspects relationnels qui lient le chef d’orchestre et le directeur artistique et nous avons souligné l’importance du dialogue. Étudions maintenant la nature des échanges mis en jeu. Dans cette catégorie sont regroupés tous les éléments relatifs aux discussions que peuvent avoir le directeur artistique et le chef d’orchestre. Nous avons identifié la mise en place d’échanges de trois ordres différents : “ d’ordre musical”, “d’ordre organisationnel” et “d’ordre technique”.
| NATURE DES ÉCHANGES | ||||
| D’ordre musical | paramètres musicaux élémentaires | DA2, CO3, DA4, DA5 | DA3, | 7 |
| balance | CO1, DA2, DA3, DA4, CO4, DA5 | 7 | ||
| tempo | DA2, DA3, DA6 | 6 | ||
| intention musicale | CO2, DA2, CO4 | DA3, | 5 | |
| choix des prises | CO1, CO2, DA3, CO4, DA6 | CO3, DA4, | 9 | |
| D’ordre organisationnel | placement des musiciens | CO1, DA2, CO3, DA3, DA4, DA5 | 14 | |
| organisation du temps | DA1, DA3, DA4, CO4, DA6 | CO3, DA5, | 11 | |
| D’ordre technique | son de l’enregistrement | CO1, DA1, CO3, DA3, DA5, DA6 | DA2, CO4, | 12 |
| imperfections de montage | CO1, CO3 | 3 | ||
Des échanges d’ordre musical
Les échanges d’ordre musical vont influencer positivement la qualité artistique du produit final. Ils visent à corriger des points techniques précis, à améliorer une sonorité ou un phrasé, à façonner une interprétation.
- “Pour arriver à une interprétation intéressante, il y a effectivement des remarques pertinentes qu’on peut faire à la suite d’une prise : qui sont d’une part d’ordre du ménage, mais aussi d’ordre de l’interprétation, des équilibres et de la manière dont l’agogique vit. C’est je trouve le plus intéressant. Un chef est un interprète. Avec lui on peut parler interprétation, parler musique.” (DA3)
Paramètres musicaux élémentaires
Le concept “paramètres élémentaires” regroupe l’ensemble des éléments de base nécessaires à une exécution musicale correcte et cohérente : l’intonation, la mise en place et les nuances générales. Il s’agit du premier palier en termes d’échange artistique. Le directeur artistique note sur sa partition les éventuelles erreurs à retravailler avant d’en faire part au chef d’orchestre. Les participants D A 3 et DA5
soulignent l’importance de ces échanges.
- “Il y a un travail que j’appelle faire le ménage et qui consiste à arrêter le chef quand les choses de bases ne vont pas dans l’orchestre.” (DA3)
- “Je trouve que les chefs ne sont pas toujours assez attentifs sur ce genre de détails (la justesse, la mise en place) alors qu’en disque c’est quand même assez important. C’est mon rôle de dire et de pointer ce genre de choses que le chef n’a pas forcément noté.” (DA5)
Parfois, c’est le chef d’orchestre qui va spontanément demander au directeur artistique de le guider sur ce point.
- “Certains chefs vont me demander s’il y a des choses qui n’ont pas été en terme de justesse, de mise en place, de nuance ou autre chose qu’il n’a pas pu entendre. Basiquement, ça va être “tiens là la flûte est partie en retard et du coup ce n’était pas tout à fait en place” ou bien “là c’était un peu faux”, “les cuivres étaient un peu trop forts”, etc.” (DA4)
L’un des directeurs artistiques interrogés nous a fait part d’un échange avec le chef d’orchestre Nikolaus Harnoncourt au sujet d’un problème de mise en place rythmique. Cette anecdote révèle que les paramètres musicaux élémentaires identifés ici ne sont pas forcément ceux auxquels les chefs d’orchestre accordent la plus grande importance en situation d’enregistrement. De plus, nous n’avons recensé aucun propos relatifs à ce concept dans tout le corpus lié aux chefs d’orchestre.
- “Avec Harnoncourt, s’il y avait un problème de mise en place à certains endroits je lui disais mais il pestait un peu toujours. Parfois je dis « attendez ce n’est pas vraiment ensemble là » et Harnoncourt dit « mais ça ne doit pas être ensemble ! On l’a tellement travaillé pour que ça ne soit pas ensemble ! », on était vraiment pas du même avis.” (DA2)
Balance
Les questions de balance font partie intégrante des discussions musicales et ce, aussi bien pendant l’enregistrement que pendant le mixage en phase de post-production.
- “Pendant la séance il y a une relation entre la cabine et le chef sur la notion des équilibres : est-ce qu’on veut plus de ci, moins de ça, est-ce que c’est bon ? Certains chefs sont à l’écoute et très demandeurs en terme de balance. Nous on a un réel rôle et il est important.” (DA3)
- “Il y avait dans le mix des voix qui ne sonnaient pas assez, que je n’entendais pas assez. J’ai donc appelé le directeur artistique pour qu’on puisse se voir et régler ensemble les questions de balance, les rapports de niveaux entre les bois et les cordes par exemple.” (CO1)
La balance est un critère de discussion parfois subjectif qui varie selon les goûts et les conceptions esthétiques du chef d’orchestre.
- “En mix, on peut avoir des points de vue vraiment différents. Je me souviens d’un projet où le chef me faisait mixer quelque chose d’une façon que je détestais vraiment. Et c’est dur de faire quelque chose qu’on aime pas. Il faut faire le travail jusqu’au bout mais ce n’est pas évident puisqu’on est pas convaincu et que ça ne nous plaît pas.” (DA4)
Tempo
Un certain nombre de participants ont également mentionné de possibles discussions autour du tempo.
- “Je me souviens d’un chef qui avait vraiment une idée très différente du tempo que moi. On a un eu échange artistique très intense, on a discuté longuement parce que moi j’aurais préféré un tempo plus rapide et lui le voulait plus lent. ” (DA2)
- “Je pense que parfois je pourrais être en porte à faux avec certains chefs qui prennent des tempi qui ne me conviennent absolument pas. Mais dans ce cas je ne préfère pas travailler avec eux. Après on peut ne pas être d’accord et trouver des choses incohérentes. Et il y en a beaucoup. On est jamais à l’abri de ça. Mais en même temps, tant que ce n’est pas nous qui jouons, c’est comme ça, on doit l’accepter.” (DA3)
Intention musicale
Le concept “intention musicale” regroupe les propos tenus par les participants relatifs à la mise en place d’un échange autour de la manière dont les interprètes peuvent faire vivre la musique (phrasé, énergie, agogique…).
- “Après chaque prise, le chef me demande mon avis, à la fois musicalement et techniquement et je décris ce que j’ai ressenti. Et ce qui est le plus intéressant, c’est d’échanger sur comment la musique se joue, comment elle vit. Il peut s’agir de la façon dont on amène un crescendo, un rallenti, comment faire sentir un brusque contraste de caractère, etc…” (DA5)
- “J’aime discuter avec le directeur artistique de tout ce qui fait vivre la musique. Il peut parfois me dire que je peux en faire beaucoup plus, étirer plus les sons, prendre plus de risques à tel ou tel moment, phraser davantage et mettre en lumière la courbe mélodique, etc.” (CO2)
Choix des prises
Pendant la phase de post-production, le directeur artistique et le chef d’orchestre peuvent avoir une discussion autour du choix des prises à utiliser dans le montage final. Celle-ci est importante puisqu’il s’agit de la dernière phase d’échange purement artistique.
- “En post-production, quand on a beaucoup de matériel à écouter, il m’arrive parfois d’être un peu perdu et de ne plus savoir quoi choisir. Le directeur artistique peut être la personne qui dit que telle prise est meilleure qu’une autre. Il va donner un argument ou souligner une qualité d’une prise par rapport à une autre.” (CO2)
- “On pourrait certes imaginer de prendre une mesure dans telle prise, tel crescendo dans telle prise, etc, c’est infini, mais au bout d’un moment il faut choisir, je dois faire confiance à la pré-sélection du directeur artistique et ensuite c’est un vrai dialogue entre lui et moi.” (CO3)
- “En post-production, j’ai des échanges vraiment importants avec le chef. Il m’arrive de discuter et d’argumenter auprès d’un chef sur le choix des prises . Certains chefs font eux-mêmes leurs choix.” (DA3)
Des échanges d’ordre organisationnel
La sous-catégorie “échanges d’ordre organisationnel” regroupe l’ensemble des éléments qui évoquent la mise en place d’un échange autour des aspects pratiques et non musicaux de l’enregistrement.
Placement des musiciens
Le concept “placement des musiciens” se rapporte au placement d’un soliste ou d’un choeur par rapport à l’orchestre et à la disposition des musiciens à l’intérieur même de l’orchestre. Ces notions sont couramment évoquées dans les discussions. Dans la plupart des cas, le chef d’orchestre est légitime pour asseoir son autorité sur ce sujet : il décide du placement de son orchestre.
- “En ce qui concerne la disposition de l’orchestre, j’ai toujours eu le loisir de faire comme je voulais et de choisir mon propre placement.” (CO1)
- “Si c’est un orchestre classique, on peut se demander : est-ce que l’on veut ou non les cuivres derrière les bois, est-ce qu’on veut séparer les cors et les trompettes/trombones pour laisser les bois s’exprimer librement au milieu ? C’est ce genre de questions qu’on peut soumettre au chef.” (DA4)
Le directeur artistique peut dans certains cas être prescripteur et proposer une modification du placement des musiciens dans le but d’optimiser la prise de son et d’améliorer le rendu sonore final, ou bien de permettre au chef de bénéficier d’un confort d’écoute plus adapté.
- “Je vais régler avec le chef plusieurs choses à savoir comment l’orchestre est disposé, où mettre les solistes s’il y en a… C’est aussi mon rôle de conseiller le chef sur ces points-là. Si on est en situation de studio, je vais préférer mettre le soliste non pas à la gauche du chef mais plutôt face à lui, un peu surélevé. C’est bien sûr dans l’intérêt de la prise de son.” (DA5)
- “J’ai déjà fait plusieurs enregistrements au cours desquels on a choisi de mettre le choeur et les chanteurs derrière le chef, tout simplement pour qu’il soit proche d’eux, qu’il les entende et qu’il soit bien conscient de la prononciation. C’est une chose que j’ai proposée et à laquelle on a pu aboutir suite à un dialogue entre le chef, le choeur et moi.” (DA2)
Organisation du temps
Les questions relatives au planning de l’enregistrement et à l’organisation des séances sont également évoquées. Ici ressort l’aspect management du rôle du directeur artistique qui doit plannifier le déroulement de l’enregistrement.
- “Préalablement, on se pose surtout des questions de planning. Quand on fait une pièce de Berlioz par exemple, les trompettes ne viennent pas tous les jours et il faut savoir quand est-ce qu’on les fait venir. Et puis il faut décider de comment est-ce qu’on enregistre et dans quel ordre.” (DA6)
- “Le directeur artistique a aussi un côté pratique, organisationnel. Il peut aussi gérer le planning d’enregistrement avec le chef, l’orchestre et la maison de disques, pour prévoir ensemble qu’il faudra tant de temps pour enregistrer ci, tant de temps pour enregistrer ça… Il va y avoir une discussion autour de ça. Par exemple le chef peut considérer que tel mouvement est trop difficile pour une fin de journée donc que ce serait mieux de l’enregistrer un matin, etc.” (DA4)
L’organisation de la séance concerne principalement la manière dont l’œuvre sera enregistrée, à savoir quel découpage adopter et dans quel ordre procéder.
- “En ce qui concerne le découpage de l’œuvre pendant la séance, on en parle ensemble. Mais en général ça va très vite, c’est une demi-seconde. Je dis au directeur artistique “bon maintenant on va de telle mesure à telle mesure”. (CO3)
- “On travaille ensemble pour savoir par exemple quel temps on va se donner pour refaire tel ou tel passage, comment gérer la fin de séance, etc. Donc il y a parfois une discussion sur ce sujet, mais c’est surtout quand il y a une petite tension, une petite contrainte de temps.” (CO4)
Il nous paraît pertinent de souligner que ce point semble être un sujet de désaccord. En effet, certains directeurs artistiques et chefs d’orchestre nous ont fait part des divergences qu’ils pouvaient avoir à ce sujet. L’organisation de la séance est parfois un sujet délicat sur lequel le directeur artistique et le chef d’orchestre doivent trouver un accord commun.
- “Les principaux problèmes que j’ai pu rencontrer ont été des problèmes de gestion de la séance d’enregistrement. Je me souviens d’un ou deux chefs qui ne savaient vraiment pas où il allaient. C’était plutôt embêtant parce que moi je savais quoi faire, comment et où aller.” (CO4)
- “On peut avoir des divergences sur la façon dont on va procéder et dans quel ordre enregistrer la pièce. Certains chefs vont vouloir faire dans tel sens, alors que pour moi ce n’est pas cohérent.” (DA1)
Des échanges d’ordre technique
Le troisième et dernier type d’échanges identifié dans cette étude sont les échanges “d’ordre technique”, c’est-à-dire l’ensemble des discussions liées à des considérations purement technologiques gérées par le directeur artistique et sur lesquelles le chef d’orchestre n’a pas directement la main.
Son de l’enregistrement
Certains chefs d’orchestre affirment avoir un échange avec le directeur artistique autour de la prise de son, en amont ou pendant l’enregistrement.
- “Je demande de plus en plus au directeur artistique de placer un couple de micros derrière moi, et de prendre principalement le son du couple, avec possibilité d’utiliser les micros d’appoints plus tard au mix. Je veux que le son, la bonne balance, ne vienne que de là où moi je suis, comme ça moi ça me permet de vraiment régler la balance.” (CO1)
- “Je peux faire des commentaires sur le son, sur la prise de son. Il m’est arrivé de devoir parler de l’esthétique sonore globale, du placement des micros, de la prise en compte de la salle, etc.” (CO4)
Cependant, il est intéressant de constater que les directeurs artistiques ne partagent pas cet avis et ne considèrent pas la prise de son comme un sujet abordé au cours des discussions.
- “En ce qui concerne l’esthétique de prise de son de l’enregistrement ce n’est pas quelque chose qu’on va discuter.” (DA2)
- “Je n’ai jamais d’échange avec le chef sur la prise de son en amont, non, c’est ma cuisine.” (DA1)
Imperfections de montage
Pendant la phase de post-production, certains échanges gravitent autour d’éventuelles imperfections liées au montage et au mixage.
- “En post-production, je fais part au directeur artistique des points de montage qu’on entend, des bruits parasites qui viennent gêner, etc.” (CO3)
- “Parfois il nous arrive de laisser passer des points de montage mal gérés, ou un instrument qui ne ressort pas dans le mix. L’écoute du chef est aussi là pour nous guider et valider ou non notre première version.” (DA4)
d) Organisation du travail
Les participants à notre étude ont souvent mentionné l’aspect organisationnel de l’enregistrement. Cette catégorie rassemble donc l’ensemble des éléments relatifs au déroulé pratique de l’enregistrement. Nous avons identifié quatre sous-catégories : “ En amont”, “Post-production”, “Contraintes temporelles” et “Méthodes d’enregistrement”. L’organisation du travail est révélatrice du contexte dans lequel s’inscrit la collaboration entre le directeur artistique et le chef d’orchestre.
| ORGANISATION DU TRAVAIL | |||||||
| En amont | prise de contact | DA1, CO2, DA2, CO3, CO4, DA5 | 6 | ||||
| préparation artistique | personnelle | du | directeur | DA1, CO2, DA2 | 3 | ||
| Post-production | investissement du chef variable | CO2, DA2, DA5 | DA4, | 5 | |||
| déroulé du montage | CO1, DA1, CO4, DA4 | DA2, | 6 | ||||
| Contraintes temporelles | manque de temps | DA1, DA2, CO3, DA3, DA6 | CO2, DA5, | 15 | |||
| contrainte de planning du chef | DA1, DA2, DA5 | 6 | |||||
| Méthodes d’enregistrement | live + patchs | DA2, DA, DA5, DA6 | 4 | ||||
| studio | DA4, DA5 | 2 | |||||
| rehearse and record | CO1, DA1, CO3 | 3 | |||||
En amont
Prise de contact
Pour les chefs d’orchestre, une préparation du projet avec le directeur artistique en amont de l’enregistrement n’est pas forcément nécessaire.
- “La prise de contact en amont n’est pas toujours une condition indispensable au bon déroulement de l’enregistrement. C’est préférable, mais ça dépend vraiment des contextes et des personnes. C’est toujours mieux quand il y a un contact, un échange, mais ce n’est pas toujours le cas.” (CO4)
Pour certains directeurs artistiques, une prise de contact – même très succincte – permet cependant de bien débuter la relation professionnelle avec le chef d’orchestre.
- “Il y a un échange mais qui très formel. Avec tous les chefs que j’enregistre, je mets un point d’honneur à les appeler avant et ce, pour une raison simple c’est de créer un minimum de lien entre nous, de façon à ce que le jour de l’enregistrement on se dise «Ah mais oui on s’est eu au téléphone la semaine dernière ! ».” (DA5)
Préparation personnelle du directeur artistique
Trois participants ont montré qu’ils accordaient une certaine importance à la préparation personnelle du directeur artistique.
- “Je considère que le travail à fournir pour préparer un enregistrement d’orchestre est supérieur à un enregistrement de musique de chambre. Il faut arriver en sachant précisément ce qu’on va enregistrer. Et comme on a pas beaucoup de temps pour enregistrer, je me dois d’arriver en étant prêt. Si le chef a besoin de quelque chose et que je n’ai rien préparé, on perd en temps et en crédibilité. ” (DA1)
Post-production
Investissement du chef variable
L’implication du chef d’orchestre dans la phase de post-production semble être variable selon les profils.
- “Je participe toujours au montage des disques et j’aime beaucoup ça. Il y a des artistes qui ne veulent pas être partie prenante du montage et n’entendent qu’un résultat. Moi je préfère travailler avec le directeur artistique pour voir jusqu’où on peut aller.” (CO2)
- “Certains chefs, de grands chefs parfois, s’en foutent un peu de l’enregistrement et considèrent ça comme quelque chose d’annexe. A la fin de l’enregistrement on ne les voit plus. Mais il y a aussi de vrais passionnés comme Harnoncourt, René Jacobs ou encore Kent Nagano qui sont des personnes qui souhaitent obtenir un résultat au-delà du simple spectacle, ou du moins différent d’un spectacle ou d’un concert. Donc ce sont des situations auxquelles on doit s’adapter.” (DA2)
Déroulé du montage
La phase de montage se fait le plus souvent en deux temps. Tout d’abord, le directeur artistique envoie au chef d’orchestre une première proposition de montage. Ce dernier fait ensuite une liste de corrections et la transmet au directeur artistique en vue d’une deuxième phase de montage.
- “Idéalement, j’aime quand le directeur artistique fait toute une première proposition de montage et me l’envoie comme une vraie première proposition artistique. Moi ensuite, je vais écouter et faire mes commentaires. Puis, il y a un deuxième envoi après commentaires et une deuxième écoute de ma part. C’est donc une seconde version que le directeur artistique propose, en tenant compte de mes commentaires, ou pas, selon les choix qui sont fait par lui et par moi.” (CO4)
Contraintes temporelles
Manque de temps
La notion de contrainte temporelle a souvent émergé au fil des entretiens et semble être spécifique à l’enregistrement de musique d’orchestre. La majorité des personnes interrogées déplorent un manque de temps et sont confrontées à une organisation du travail différente. L’un des participants observe ce changement et souligne l’impact que de telles contraintes peuvent avoir sur le métier de directeur artistique.
- “Ce qui a changé entre le moment où j’ai commencé à travailler dans ce milieu et aujourd’hui, c’est évidemment la contrainte de temps. Avant on pouvait dire à l’orchestre de répéter pendant une heure pendant qu’on écoutait nos micros, qu’on les replaçait… Maintenant ce n’est plus le cas, il y a une grande contrainte de temps qui va affecter la prise de son, la balance, et bien sûr le processus de direction artistique. On doit s’organiser d’une autre manière.” (DA1)
Un autre directeur artistique affirme que cet aspect est propre à l’enregistrement d’orchestre, par opposition à un disque de musique de chambre :
- “Un quatuor à cordes, un pianiste ou un chanteur qui viennent enregistrer un disque vont travailler jusqu’à ce qu’ils aient donné le meilleur d’eux-mêmes. Dans le cas d’un orchestre, le temps est un facteur très important. Les musiciens d’orchestre sont en règle générale syndicalisés et veulent qu’on respecte les horaires. Par conséquent, les choses sont différentes.” (DA2)
La principale cause du manque de temps est financière. Un orchestre coûte aujourd’hui très cher et chaque minute d’enregistrement est précieuse.
- “Aujourd’hui enregistrer un orchestre est très onéreux. Les musiciens viennent, doivent dormir à l’hôtel et sont payés individuellement par séance. Ce sont des choses qui coûtent très cher pour le marché tel qu’il se présente aujourd’hui. ” (DA2)
La majorité des participants déplorent donc le peu de temps d’enregistrement auquel ils sont confrontés.
- “Avec un orchestre, il y a un seul chef et c’est la montre : on a tant d’heures pour enregistrer, ni plus ni moins.” (DA6)
- “Il va falloir faire le job dans un temps très limité parce qu’il y a concrètement très peu de temps pour enregistrer. Il faut aussi respecter certaines contraintes comme donner la pause des musiciens au bout d’une heure et quart par exemple, et ça compte énormément dans notre métier.” (DA5)
Le manque de temps va également impacter la réalisation de la balance qui devra se faire dans un temps parfois très limité.
- “Pour une prise de son d’orchestre, dans le cadre d’un disque, on est aujourd’hui sur une balance de 20 minutes en gros. C’est très peu. On a intérêt à avoir bien préparé les choses et à être pertinent vis-à-vis de ce à quoi on veut tendre. ” (DA3)
Néanmoins, l’un des chefs d’orchestre interrogés considère cette pression liée au temps comme bénéfique pour l’enregistrement car stimulante d’un point de vue artistique.
- “Moi j’essaie d’aller très vite, de gérer efficacement la montre. Le temps musical en orchestre est très comprimé. Mais quand on y réfléchit bien, c’est très créatif d’aller vite et je trouve très stimulant le fait d’être dans une intensité permanente.” (CO3)
Contrainte de planning du chef d’orchestre
Les contraintes temporelles sont également présentes en amont de l’enregistrement et pendant la phase de post-production. Le chef d’orchestre est souvent un artiste très demandé au planning chargé. Le directeur artistique doit en tenir compte pour l’organisation du projet.
- “Par rapport à tous les musiciens, le chef d’orchestre est celui qui répond le moins rapidement parce qu’il a en général un emploi du temps monstrueux. On a très souvent du mal à les joindre et il faut parfois l’anticiper.” (DA5)
Méthodes d’enregistrement
Enfin, nous avons pu identifier les différentes méthodes d’enregistrement mises en place pour la réalisation d’un disque de musique d’orchestre.
Live + patchs
La méthode “live + patchs” (concert + séances de corrections) consiste à enregistrer un ou plusieurs concerts donnés par le chef et l’orchestre, puis à corriger les éventuelles faiblesses lors d’une séance d’enregistrement supplémentaire (la séance de patchs). Un dialogue entre le chef et le directeur artistique est mis en place entre le concert et la séance de patchs dans le but de réfléchir à quelle stratégie adopter. Les directeurs artistiques interrogés insistent sur le fait que cette méthode les pousse à être directifs et à se concentrer sur l’essentiel.
- “Une fois le concert enregistré, j’arrive avec la partition et une liste de choses qu’il faudrait améliorer. Je fais parler le chef d’orchestre pour lui demander quelles sont ses impressions et ce que lui souhaite refaire. Puis il me demande mon avis et on décide quoi réenregistrer. Il faut être concret. Ensuite, on fait une séance de patchs et c’est vraiment le directeur artistique qui va prendre les rênes, tout simplement parce qu’il faut être très efficace à cause du temps imparti. Le directeur artistique va donc être très directif.” (DA4)
- “Pour une séance de patchs après un concert, on doit aller à l’essentiel. En général on a entre une heure et un service, ce qui est peu. Entre le concert et ma séance de patchs, je ré-écoute tout le concert, je regarde ce qui n’a pas marché et j’élabore un plan d’attaque de façon à ce qu’on aille vraiment à l’essentiel.” (DA5)
Bien que l’influence du directeur artistique soit ici limitée, la méthode “live + patchs” reste aujourd’hui la plus utilisée car elle est aussi la plus rentable.
- “En “live + patchs” j’ai beaucoup moins la main sur l’aspect artistique parce qu’au concert je ne fais pas grand chose à part prendre des notes. Je n’aurai la main que pendant la séance de patchs, ce qui peut être un peu frustrant parce qu’on ne peut pas toujours approfondir les choses. Le “live + patchs” n’est pas la meilleure solution mais c’est celle qui est la plus utilisée car ça coûte moins cher. Mais des fois ça apporte vraiment une plus-value car on a l’énergie du concert, chose difficilement reproductible en studio.” (DA5)
Studio
Certains participants affirment que l’enregistrement studio est quant à lui plus propice à des échanges artistiques poussés. Il consiste à effectuer l’intégralité de l’enregistrement sur plusieurs jours, dans un seul et même lieu (studio d’enregistrement, salle de concert…). L’organisation du travail est donc sensiblement différente de celle de la méthode “live + patchs”.
- “Le fonctionnement de l’enregistrement en studio pur est différent : on prend le temps de faire une première prise, puis une deuxième prise, le chef peut venir écouter, on en parle, on se dit « ça c’est génial il faut garder » , « ça musicalement est-ce qu’on pourrait pas un peu changer », etc. Il y a vraiment un échange artistique beaucoup plus intéressant. On peut façonner davantage la musique puisqu’on part de rien, il n’y a pas déjà une base de concert sur laquelle on va rajouter des corrections.” (DA5)
L’influence du directeur artistique en situation de studio est variable selon les chefs d’orchestre. Il peut être actif et directif ou au contraire s’effacer derrière la personnalité du chef.
- “A l’issue des prises, certains chefs d’orchestre voudront parler immédiatement à l’orchestre et seront plutôt directif et autonome. Dans ce cas-là le directeur artistique n’est en quelque sorte qu’un scripte qui note sur la partition les prises, ce qui est bien, pas bien, et éventuellement il pourra intervenir à la fin s’il y a des choses qui manquent. Dans d’autres cas, ce sera vraiment au directeur artistique de diriger la séance et de guider le chef à chaque prise. C’est variable.” (DA4)
Rehearse and record
Enfin, trois participants ont mentionné la méthode du “rehearse and record” qui permet de construire progressivement l’œuvre enregistrée en alternant des phases de répétitions et d’enregistrement.
- “On laisse l’orchestre répéter quelques mesures, puis on les enregistre, etc. C’est la technique du “répété-enregistré”, c’est très pratique surtout pour le répertoire contemporain.” (DA1)
- “J’aime bien prendre une section, assez longue, puis on la travaille et on l’enregistre au fur et à mesure jusqu’à ce qu’on ait tout.” (CO3)
V. Discussions
1. Évaluation de la démarche méthodologique
a) Deux approches analytiques complémentaires
La démarche méthodologique consistant à combiner deux types d’analyse s’avère pertinente dans le sens où l’analyse par théorisation ancrée vient confimer et préciser de manière significative les résultats obtenus par l’analyse de contenu. L’analyse de contenu est un bon point d’entrée dans le traitement des données car c’est une méthode qui a l’avantage de donner rapidement des éléments de compréhension. Ainsi, nous avons pu aisément identifier trois grandes problématiques liées à la relation professionnelle du directeur artistique et du chef d’orchestre, à savoir l’aspect collaboratif, la communication et la gestion du temps. L’analyse par théorisation ancrée est quant à elle une approche plus dynamique dans la mesure où elle incite le chercheur à développer et à proposer une interprétation du phénomène étudié. C’est en ce sens que nous considérons ces deux approches comme complémentaires, tant sur la forme de la méthode que sur le fond des résultats obtenus.
Le tableau ci-dessous met en parallèle les catégories référencées grâce à l’une et l’autre des deux méthodes d’analyse.
| Analyse de contenu | Actions liées au processus d’enregistrement |
| Collaboration | |
| Communication | |
| Gestion du temps | |
| Analyse par théorisation ancrée | Aspects relationnels |
| Expertise du directeur artistique | |
| Nature des échanges | |
| Organisation du travail |
La catégorie Actions liées au processus d’enregistrement identifiée par l’analyse de contenu reste très générale et donc peu précise. Elle ne permet pas de bien cerner tous les enjeux organisationnels induits par la collaboration entre le directeur artistique et le chef d’orchestre. L’analyse par théorisation ancrée nous a permis de développer plus largement cet aspect en déterminant la manière dont se déroule un enregistrement et la façon dont le directeur artistique et le chef d’orchestre interagissent ensemble.
La notion de Collaboration de l’analyse de contenu a pu être précisée dans la sous-catégorie Dimension collaborative, elle-même issue d’une catégorie plus vaste que nous avons nommée Aspects relationnels. L’importance de la Communication se traduit par la mise en place de nombreux échanges entre le directeur artistique et le chef d’orchestre. Grâce à la méthode d’analyse par théorisation ancrée, nous avons pu identifier la nature de ces discussions.
Notons que c’est également cette seconde méthode qui nous a permis de mettre en lumière l’importance du rôle et les compétences du directeur artistique, deux éléments que nous n’avions pas explicitement identifiés par l’analyse de contenu.
Les deux approches analytiques choisies ne sont pas redondantes mais bel et bien complémentaires. Si l’analyse de contenu aide à identifier certaines problématiques de manière globale voire distanciée, l’analyse par théorisation ancrée permet quand à elle d’étudier plus en profondeur le phénomène observé.
b) Limitations et perspectives
Comme dans tout processus scientifique, il est nécessaire que le chercheur prenne un certain recul sur son travail. Il doit faire preuve de réflexivité et identifier les limitations de sa démarche. Nous souhaitons avant tout rappeler que cette étude s’inscrit dans le cadre d’un projet de recherche étudiant. Celle-ci aurait davantage pu être approfondie si nous avions disposé de temps et de moyens supplémentaires.
Panel de participants
Malgré nos efforts, le nombre peu élevé de participants et les profils de chacun ne permettent pas d’embrasser l’ensemble du milieu étudié, à savoir celui de l’enregistrement de musique d’orchestre. Il aurait donc été préférable d’interroger un nombre plus conséquent de professionnels pour pouvoir aller plus loin dans l’analyse des données et dans la validation des catégories identifiées.
Cette étude se limite à des experts du monde francophone et il serait pertinent de la mener dans des pays germaniques et anglo-saxons afin de confirmer ou d’infirmer l’universalité de nos résultats.
Nous aurions également pu envisager d’étendre et de préciser notre travail en interrogeant des acteurs extérieurs à la relation qu’entretiennent le directeur artistique et le chef d’orchestre comme par exemple les musiciens d’orchestre, les ingénieurs du son ou les producteurs. Nous invitons les chercheurs à approfondir ce sujet sous cet angle et à étudier les rapports triangulaires existant entre le directeur artistique, le chef d’orchestre et le compositeur ou bien entre le directeur artistique, le chef d’orchestre et le soliste.
Rigueur analytique
Bien que l’analyse par théorisation ancrée fasse appel à une méthodologie rigoureuse, elle reste malgré tout en partie subjective. Même s’il est fortement recommandé au chercheur de mettre son savoir et ses références de côté, celui-ci va interpréter les données collectées à travers le filtre de sa sensibilité théorique et produira sa propre catégorisation des concepts. Selon Guillemette (2006), il est donc impératif d’expliciter “la relation entre les intuitions du chercheur (faites de savoirs antérieurs et de références à des théories existantes) et les suggestions qui proviennent des données de terrain”.
Dans le cas de cette étude, notre double compétence en matière de direction artistique et de direction d’orchestre aurait donc pu compromettre toute tentative d’objectivité totale. Cependant, par souci d’honnêteté intellectuelle et de rigueur scientifique, nous nous sommes efforcés de mettre de côté nos présupposés et de construire le plus objectivement possible notre analyse.
Difficultés d’analyse
Il nous paraît important de mentionner les quelques difficultés auxquelles nous avons dû faire face pendant la phase d’analyse par théorisation ancrée. Tout d’abord, l’élaboration des catégories et des sous-catégories n’a pas été une tâche très aisée. Notre grille d’analyse a régulièrement subi un certain nombre de modifications, ce qui à plusieurs reprises nous a paru déroutant.
D’autre part, nous avons parfois eu du mal à classer certains propos pouvant appartenir à plusieurs catégories et nous avons été contraint de faire des choix. A titre d’exemple, la citation “En post-production, quand on a beaucoup de matériel à écouter, il m’arrive parfois d’être un peu perdu et de ne plus savoir quoi choisir. Le directeur artistique peut être la personne qui dit que telle prise est meilleure qu’une autre. Il va donner un argument ou souligner une qualité d’une prise par rapport à une autre .” peut se rapporter à deux de nos quatre catégories. Le chef d’orchestre évoque ici clairement la mise en place d’un échange autour de la sélection des prises, ce qui relève de la Nature des échanges et de sa sous-catégorie Échanges d’ordre artistique. Cependant si l’on considère que le participant met ici en lumière l’une des compétences du directeur artistique, à savoir sa disposition à conseiller l’interprète, alors cette citation relève de la catégorie Expertise du directeur artistique. De la même manière, la citation “A plusieurs reprises j’ai eu l’impression d’avoir le rôle d’assistant du chef, parce que finalement c’est un boulot assez similaire.” pourrait aussi bien être classée dans la sous-catégorie Rapports hiérarchiques que dans Dimension collaborative.
Outre les difficultés de catégorisation auxquelles nous avons dû faire face, le processus de fragmentation du discours s’est parfois révélé délicat et abstrait.
Enfin, la principale limite de cette étude réside peut-être en son ambition d’aboutir à une explication d’un phénomène en grande partie régi par des concepts appartenant aux domaines de la sociologie et la psychologie. Ainsi, il serait pertinent de
mener un travail similaire à celui-ci en prenant davantage en compte la dimension sociologique du phénomène et en menant une étude approfondie des profils psychologiques des divers participants.
Observations sur le terrain
La recherche scientifique se contruit aussi de manière empirique : effectuer une série d’observations sur le terrain aurait pu alimenter notre réflexion. Confronter les données issues de nos entretiens à la réalité du système nous aurait probablement permis de valider, d’infirmer ou de nuancer certains points d’analyse. Cependant, les résultats issus d’observations sur le terrain auraient exigé la mise en place d’une méthodologie plus complexe et d’un travail d’analyse trop conséquent pour un mémoire de cette envergure.
2. L’enregistrement comme une “création artistique commune et partagée”
Dans son étude, Ravet (2015) identifie les deux versants de la relation entre un chef d’orchestre et un ensemble de musiciens. Le premier repose selon elle sur des rapports de pouvoir sous-jacents : de par la nature de sa fonction, le chef d’orchestre est formellement en position de décider. La relation est dans ce cas dissymétrique. Le second aspect semble plus modéré car selon Ravet, l’interprétation de l’œuvre découle de la participation de l’ensemble des protagonistes et de l’organisation d’un travail commun : l’action créatrice est de nature profondément collective.
La collaboration professionnelle entre le directeur artistique et le chef d’orchestre est complexe. Elle se construit autour d’enjeux relationnels et repose sur un ensemble d’interactions et de négociations. Les résultats obtenus à la suite de notre analyse semblent converger vers le modèle proposé par Ravet. En effet, les notions de hiérarchie et d’autorité sont bel et bien présentes dans les rapports qu’entretiennent le directeur artistique et le chef d’orchestre. Le chef est un interprète à part entière. Par conséquent, son autorité est aussi légitime devant un orchestre que devant un directeur artistique. C’est à lui, l’auteur de l’interprétation musicale, que reviennent les décisions artistiques. Il aura pour ainsi dire toujours le dernier mot. Le second aspect identifié par Ravet trouve son pendant dans le concept “Dimension collaborative” de notre étude. Comme nous l’avons vu, l’enregistrement résulte de la participation active du chef d’orchestre et des musiciens mais aussi du directeur artistique. C’est ce partage de l’autorité créatrice qui fait de l’enregistrement un espace de création artistique commun au sein duquel sont investis le chef d’orchestre et le directeur artistique.
3. Mise en perspective avec le contexte économique actuel
Au cours de cette étude, nous avons pu identifier une préoccupation récurrente dans les propos des participants : le temps. La majorité d’entre eux affirme que la gestion du temps est, dans le contexte spécifique de l’enregistrement de musique d’orchestre, une contrainte importante. Le temps de préparation, le temps de dialogue, le temps de balance, le temps d’enregistrement et le temps de post-production sont comptés et dépendent de facteurs extérieurs d’ordre pratique et économique. Nous mentionnerons principalement les emplois du temps chargés liés aux carrières des chefs, le coût financier d’un orchestre et la restriction des budgets liée au contexte économique actuel.
Burgess (2008) affirme qu’aujourd’hui, les directeurs artistiques doivent non seulement s’adapter aux nouvelles formes de consommation et de diffusion de la musique (streaming, musique filmée, etc.), mais également faire face à des contraintes inhérentes à une industrie du disque en déclin, de moins en moins rentable et attractive. La contrainte budgétaire imposée par les labels discographiques possède donc un impact non négligeable sur les conditions de réalisation des enregistrements. Ces contraintes sont évoquées par les participants à notre étude et se traduisent particulièrement dans la catégorie Organisation du travail → Contraintes temporelles. La restriction du temps aloué à l’enregistrement amène donc à une modification des pratiques. L’enregistrement de type live + patchs est aujourd’hui devenu la norme car c’est une solution moins coûteuse et moins chronophage que le studio. Aujourd’hui, les enregistrements d’orchestre intégralement réalisés en studio sont devenus beaucoup plus rares.
La contrainte temporelle semble cependant moins impacter les enregistrements de musique de chambre ou de récitals puisque les musiciens ne sont pas soumis aux mêmes règles syndicales que les musiciens d’orchestre. Comme l’a précisé dans un entretien l’un des directeurs artistiques, un pianiste ou un quatuor à cordes jouera jusqu’à avoir donné le meilleur de lui-même. Mais qu’en est-il de l’action du directeur artistique ? Est-elle réellement impactée par ces contraintes de temps ? Les résultats tendent à montrer que la fonction première du directeur artistique, à savoir la gestion du projet dans sa globalité, ne change pas. Cependant, il peut être amené à adapter ses méthodes en fonction des conditions de travail et du temps alloué pour l’enregistrement.
Bien qu’aucun participant à l’étude n’ait explicitement formulé cette idée, l’influence musicale du directeur artistique pourrait quant à elle être impactée par ces nouvelles contraintes de travail. Dans le cadre d’un enregistrement live+patchs (environ 80% de la production de disques d’orchestre aujourd’hui), l’influence du directeur artistique sur le résultat final est moins important. Pendant le concert, son action va se limiter à répertorier les points positifs et négatifs de la performance, en vue d’une prochaine séance de patchs. Ces séances possèdent un intérêt artistique moins développé que l’enregistrement studio intégral, dans le sens où l’action du directeur artistique est limitée par la contrainte de devoir corriger toutes les erreurs survenues au concert. Il est frappant de comparer nos méthodes d’enregistrement actuelles, contraintes par le temps et les financements, avec celles pratiquées dans années 1960, lorsqu’il était encore possible de consacrer quinze services d’orchestre à l’enregistrement d’un opéra de Wagner (Burton, 1992). La direction artistique est donc un métier qui évolue continuellement avec son temps.
4. Apports personnels
Pour conclure, nous tenons à souligner que cette étude nous a été bénéfique sur plusieurs aspects. Tout d’abord, ce fut pour nous une magnifique occasion de rencontrer des chefs d’orchestre reconnus de stature internationale, et d’aborder avec eux les problématiques relatives à l’enregistrement. La parole des interprètes est très précieuse et permet de prendre un certain recul que nous n’avons pas toujours en cabine. Échanger avec plusieurs directeurs artistiques sur leur activité nous aura permis d’élargir et de réévaluer notre vision de ce métier. Ces rencontres ont été enrichissantes car elles nous auront probablement aidé à améliorer notre pratique de la direction artistique dans le contexte spécifique des enregistrements d’orchestre.
Aborder un travail tel que celui-ci en faisant appel à toute la rigueur de l’approche scientifique a été bénéfique. Ce fut pour nous une excellente opportunité de nous confronter aux différents processus de la recherche scientifique : formulation d’une problématique, recherche bibliographique, mise en place d’une méthodologie rigoureuse, rédaction d’un travail de grande ampleur, etc.
Enfin, les échanges que nous avons pu avoir avec les participants nous ont permis de mettre des mots sur les enjeux de l’enregistrement et de prendre conscience de l’importance des dimensions sociale et psychologique. L’enregistrement ne se limite pas à la simple captation sonore d’une œuvre musicale. C’est une véritable aventure humaine au sein de laquelle sont impliquées un grand nombre d’individualités qui agissent dans un but commun : celui de partager et de faire vivre la musique.
Conclusion
A notre connaissance, cette recherche est la première à aborder spécifiquement la collaboration professionnelle entre directeurs artistiques et chefs d’orchestre puisqu’il n’existe presque aucune littérature à ce sujet mis à part des témoignages autobiographiques. Notre travail a ainsi pu permettre d’élargir et de préciser le champ de recherche autour du domaine de la direction artistique en étudiant un cas précis dont nous avons souligné les spécificités.
Par l’intermédiaire d’une série d’entretiens avec des experts du monde de l’enregistrement, nous avons collecté un ensemble de données discursives. Celles-ci ont par la suite été confrontées à un double processus d’analyse qui au final s’est avéré pertinent. En effet, cette démarche nous a permis de mettre en lumière les divers aspects de la collaboration professionnelle entre le directeur artistique et le chef d’orchestre, ainsi que les différentes problématiques mises en jeu sur les plans humain, musical et pratique.
Comme dans toute collaboration professionnelle, l’aspect relationnel est un point essentiel. Son étude est révélatrice de la manière dont le directeur artistique et le chef d’orchestre collaborent. On sait qu’une grande partie du projet d’enregistrement est portée par le directeur artistique. L’analyse a permis de mieux cerner son action et ses compétences dans le contexte particulier imposé par l’étude. Nous avons également pu identifier la nature des discussions mises en place : elles peuvent être d’ordre musical, technique ou bien organisationnel. Enfin, l’analyse a montré que les conditions d’enregistrement ne sont jamais les mêmes et varient d’un projet à l’autre. Le directeur artistique et le chef d’orchestre sont donc amenés à adapter leur conception de l’organisation du travail.
L’enregistrement s’inscrit dans une démarche collaborative de création artistique commune et partagée entre le chef d’orchestre et le directeur artistique. Cependant, il est aujourd’hui légitime de s’interroger sur l’influence de ce dernier, à l’heure où le nombre de séances consacrées aux enregistrements est de plus en plus réduit.
Nous invitons les directeurs artistiques et les chefs d’orchestre à mener une réflexion personnelle sur leur fonction au sein de l’enregistrement, ainsi que sur les rapports professionnels qu’ils entretiennent. Nous invitons également les chercheurs intéressés à poursuivre cette étude sous un autre angle d’approche (contexte culturel anglo-saxon ou germanique, approche basée sur la psychologie des individus, point de vue des musiciens d’orchestre, des producteurs et des ingénieurs du son).
Références Bibliographiques
ADORNO, T., The Curves of the Needle, The Form of the Phonograph Record, and Opera and the Long-playing Record. Dans October, vol.55, 1990.
BADAL, J., Recording the Classics : Maestros, Music and Technology. Kent, Ohio : The Kent State University Press, 1996.
BARDIN, L., L’analyse de contenu (5e éd.). Paris: Presses Universitaires de France, 1989.
BÉNET, M., La collaboration entre une équipe son et une équipe image au sein d’une production de musique classique filmée, quelle question des contraintes ? Mémoire de Master 2, Formation Supérieure aux Métiers du Son, Conservatoire National Supérieur de Musique et de Danse de Paris, 2018.
BENJAMIN, W., The Work of Art in the Age of its Technological Reproductibility and Other Writings on Media (édité par JENNINGS, M.W. ; DOHERTY, B. ; LEVIN, T.Y.) Cambridge : Harvard University Press, 2008.
BLANCHET, A., L’entretien dans les sciences sociales : l’écoute, la parole et le sens. Paris : Dunod, 1985.
BLANCHET, A. & GOTMAN, A., L’enquête et ses méthodes : l’entretien (2e éd.) Paris: Armand Colin, 2007.
BORWICK, J., The Tonmeister Concept. Présenté à la 46e Audio Engineer Society Convention à New York, États-Unis, septembre 1973.
BURGESS, R.J., Producer Compensation: Challenges and Options in the New Music Business. Dans Journal on the Art of Record Production, vol.3, 2008.
BURTON, H., The Golden Ring. Antony : Polygram video (éd.) ; Paris : Polygram music video (distrib.), 1992.
CHANAN, M., Repeated takes: A short history of recording and its effects on music . London: Verso, 1995.
COTELLE, A., La direction artistique : quand les relations humaines croisent la musique, Mémoire de Master 2, Formation Supérieure aux Métiers du Son, Conservatoire National Supérieur de Musique et de Danse de Paris, 2001.
CULSHAW, J., The Record Producer Strikes Back. Dans High Fidelity, vol. 18(10), pp.68-71, 1968.
FENNETEAU, H., : Enquête : entretien et questionnaire (2e éd.), Collection Les Topos. Paris : Dunod, 2007.
FRITH, S. & ZAGORSKI-THOMAS, S., The art of record production : an introductory reader for a new academic field. Burlington: Ashgate, 2012.
GARITY, W.E. & HAWKINS, J.,N.A., Fantasound dans Journal of the Society of Motion Picture Engineers, vol.37(8), pp.127-146, 1941.
GHIGLIONE, R., & MATALON, B., Les enquêtes sociologiques : théories et pratique (6e éd.). Paris : Armand Colin, 1998.
GLASER, B. & STRAUSS, A., La découverte de la théorie ancrée : stratégies pour la recherche qualitative (2e éd.). Malakoff : Armand Colin, 2017.
GUILLEMETTE, F., L’approche de la Grounded Theory : pour innover ? Dans Recherches qualitatives, vol.26(1), pp.32-50, 2006.
HAAS, M., Studio Conducting dans The Cambridge Companion to Conducting, pp.28-39. Cambridge : Cambridge University Press, 2003.
HENNION, A., An intermediary between production and consumption – The producer of popular music dans Science Technology and Human Values, vol.14(4), pp.400-424, 1989.
KING, R., Recording Orchestra and Other Classical Music Ensembles. New York : Routledge, 2016.
LEHMANN, B., L’orchestre dans tous ses états : ethnographie des formations symphoniques. Paris: La Découverte, 2002.
LEVIN, T., For the Record : Adorno on Music in the Age of Its Technological Reproductibility. Dans October, vol.55, pp.23-47, 1990.
MOORE, J.N., Sound Revolutions : A Biography of Fred Gaisberg, Founding Father of Commercial Sound Recording. London : Sancturary Publ.,1999
NEW YORK TIMES, Connecting Music and Gesture with Alan Gilbert [vidéo en ligne]. The New York Times Company, 6 avril 2012 [vue le 15 septembre 2019] http://archive.nytimes.com/www.nytimes.com/interactive/2012/04/06/arts/music/the-connection-between-gesture-and-music.html
PAILLÉ, P., L’analyse par théorisation ancrée. Da n s Cahiers de recherche sociologique, vol.23, pp.147-181, 1994.
PAILLÉ, P. & MUCCHIELLI, A., L’analyse qualitative en sciences humaines et sociales (3e éd.). Paris : Armand Colin, 2012.
PATMORE, D. & CLARKE, E., Making and hearing virtual worlds: John Culshaw and the art of record production. Dans Musicae Scientiae, vol.11(2), pp.269–293, 2007.
PRAS, A., How to draw out the best musical performance : best practices for studio recording in the digital era. Thèse de doctorat, Université McGill, 2012.
PRAS, A. & GUASTAVINO, C., The role of music producers and sound engineers in the current recording context, as perceived by young professionals, in Musicae Scientiae, vol.15(1), pp.73-95, 2011.
PRAS, A. ; CANCE, C. ; GUASTAVINO, C., Record Producers’ Best Practices For Artistic Direction—From Light Coaching To Deeper Collaboration With Musicians, Journal of New Music Research, vol.42(4), pp.381-395, 2013.
RAVET, H., L’orchestre au travail : interactions, négociations, coopérations, Collection MusicologieS. Clermont-Ferrand : Vrin, 2015.
ROBERT, P., Performing Music in the Age of Recording. New Haven & London : Yale University Press, 2004.
SHIRAKAWA, S., The Devil’s Music Master : The Controversial Life and Career of Wilhelm Fürtwangler. Oxford: Oxford University Press, 1992.
SCHWARZKOPF, E., La voix de mon maître : Walter Legge. Paris : Pierre Belfond, 1983.
SMITH, W., The mystery of Leopold Stokowski. Cranbury : Associated University Presses, 1990.
ANNEXE 1 : Profil des participants à l’étude

ANNEXE 2: Guide d’entretien
- Quelles sont les fonctions et le rôle du directeur artistique dans le contexte d’un enregistrement de musique d’ensemble ?
- Selon vous, quelles sont les principales qualités que doit avoir un directeur artistique dans le contexte d’un enregistrement de musique d’ensemble ?
- J’aimerais que vous me parliez maintenant de votre collaboration avec le directeur artistique/chef d’orchestre en amont de l’enregistrement.
- Décrivez-moi maintenant l’interaction que vous avez avec le directeur artistique/chef d’orchestre pendant la séance d’enregistrement.
- De quelle nature sont les échanges mis en place avec le directeur artistique/chef d’orchestre pendant la phase de post-production ?
- J’aimerais que vous me fassiez part des éventuels problèmes et divergences que vous avez pu rencontrer en travaillant avec un directeur artistique/chef d’orchestre. Quelles solutions ont été adoptées ?
- Au regard de votre parcours, parlez-moi de vos expériences les plus marquantes avec un directeur artistique/chef d’orchestre, qu’elles soient positives ou négatives.
- Souhaitez-vous ajouter quelque chose que nous n’aurions pas évoqué ?
ANNEXE 3 : Formulaire de consentement préalable à l’entretien
Présentation du projet. Cet entretien s’inscrit dans le cadre d’un mémoire de recherche réalisé au Conservatoire National Supérieur de Musique et de Danse de Paris (CNSMDP) dans la Formation Supérieure aux Métiers du Son (FSMS). Ce projet vise à étudier la relation entre le directeur artistique et le chef d’orchestre au cours des enregistrements de musique d’ensemble dirigée et ce, dans le but de documenter cette pratique et d’identifier les problématiques artistiques et esthétiques mises en jeu.
Procédure. Votre participation à cette étude prendra la forme d’un entretien au cours duquel vous serez invité(e) à parler de votre expérience d’enregistrement de musique d’ensemble (orchestre symphonique, orchestre de chambre, ensemble baroque ou contemporain…) en tant que directeur artistique ou chef d’orchestre. Cet entretien, d’une durée variable entre une demi-heure et une heure et demie, sera enregistré en format audio uniquement, et ne sera utilisé que dans le cadre du présent projet de recherche.
Droits du participant. Votre participation à cette étude est volontaire. Ainsi, il vous sera permis de refuser de répondre à n’importe quelle question ou de stopper à tout moment l’entretien. Vous aurez le droit de réécouter l’intégralité ou une partie de l’enregistrement audio et d’en exiger sa destruction.
Confidentialité. Cet entretien sera traité de manière confidentielle et anonyme. Votre nom n’apparaîtra pas dans les publications résultantes.
Déclaration du participant :
« J’ai lu la description du projet de recherche et par la présente, accepte d’y participer. J’ai pris connaissance des conditions d’utilisations des résultats de cet entretien, et du fait que mon identité restera confidentielle. »
Nom : Date : / /
Signature :
Cette étude est menée par Théo Terracol et encadrée par François-Xavier Féron (STMS-IRCAM).
Contact : theo.terracol@gmail.com / 06 77 65 48 13.
ANNEXE 4 : Listes de lemmes classés par fréquence
Corpus « directeurs artistiques
| on | 2,84% | entendre | 0,15% |
| faire | 1,63% | parler | 0,15% |
| je | 1,57% | changer | 0,14% |
| chef | 1,50% | avis | 0,13% |
| pouvoir | 0,97% | disque | 0,13% |
| orchestre | 0,80% | trouver | 0,13% |
| dire | 0,71% | donner | 0,12% |
| artistique | 0,57% | musical | 0,12% |
| échange | 0,56% | partition | 0,12% |
| enregistrement | 0,56% | montage | 0,11% |
| confiance | 0,51% | relation | 0,11% |
| directeur | 0,46% | tempo | 0,10% |
| temps | 0,41% | gérer | 0,10% |
| vouloir | 0,39% | décider | 0,10% |
| séance | 0,27% | interprétation | 0,10% |
| ensemble | 0,25% | correction | 0,9% |
| écouter | 0,25% | essayer | 0,9% |
| travailler | 0,25% | technique | 0,9% |
| devoir | 0,25% | refaire | 0,9% |
| musique | 0,25% | balance | 0,8% |
| discuter | 0,24% | règle | 0,8% |
| prise | 0,24% | gestion | 0,8% |
| musicien | 0,23% | accord | 0,8% |
| demander | 0,22% | aimer | 0,7% |
| concert | 0,21% | ||
| savoir | 0,21% | ||
| différent | 0,19% | ||
| rôle | 0,18% | ||
| soliste | 0,17% | ||
| jouer | 0,16% | ||
| studio | 0,16% |
Corpus « chefs d’orchestre »
| je | 3,09% | qualité | 0,16% |
| on | 2,10% | attendre | 0,15% |
| faire | 1,20% | échange | 0,15% |
| artistique | 1,18% | aimer | 0,15% |
| directeur | 1,12% | donner | 0,15% |
| pouvoir | 1,08% | répétition | 0,15% |
| dire | 0,87% | refaire | 0,14% |
| avec | 0,72% | travail | 0,14% |
| moi | 0,60% | trouver | 0,14% |
| orchestre | 0,52% | rôle | 0,14% |
| savoir | 0,51% | oreille | 0,13% |
| temps | 0,44% | problème | 0,12% |
| musicien | 0,41% | interprétation | 0,12% |
| enregistrement | 0,40% | ensemble | 0,12% |
| chef | 0,35% | gérer | 0,12% |
| devoir | 0,33% | cabine | 0,12% |
| entendre | 0,33% | technique | 0,11% |
| prise | 0,31% | œuvre | 0,11% |
| séance | 0,30% | remarque | 0,11% |
| confiance | 0,30% | avancer | 0,11% |
| autre | 0.29% | connaître | 0,11% |
| besoin | 0,28% | montage | 0,10% |
| penser | 0,24% | perception | 0,09% |
| parler | 0,21% | manière | 0,08% |
| vouloir | 0,20% | choix | 0,08% |
| vite | 0,20% | micro | 0,08% |
| travailler | 0,19% | écoute | 0,08% |
| enregistrer | 0,17% | métier | 0,07% |
| suivre | 0,17% | ||
| disque | 0,17% | ||
| deux | 0,16% | ||
| musical | 0,16% |
Remerciements
La réalisation de ce mémoire a été possible grâce au concours de plusieurs personnes à qui je souhaiterais témoigner toute ma reconnaissance.
Tout d’abord, je tiens à remercier chaleureusement François-Xavier Féron (STMS-IRCAM) pour son aide précieuse et ses conseils avisés, sa relecture attentive et l’intérêt porté à mon sujet de recherche.
Merci également à Corsin Vogel, Pierre-Antoine Signoret, Jean-Pascal Jullien et Denis Vautrin pour m’avoir aidé à préciser ma recherche.
Merci à tous les directeurs artistiques et chefs d’orchestre interrogés qui, par leur aide et leur collaboration, ont permis la réalisation de ce mémoire.
Merci au Conservatoire National Supérieur de Musique et de Danse de Paris, et plus particulièrement à la FSMS et ses professeurs, auprès de qui j’ai beaucoup appris pendant ces quatre riches années d’études.
Merci à mes camarades FSMS pour ces innombrables heures passées en Régie des Amphithéâtres…
Enfin un grand merci à mes parents, mon frère Hugo et Valentine qui m’ont toujours fait preuve d’un soutien des plus sincères.
Notes
- « One of the ways to make your sound better is to make it really obvious that you’re really listening and that it really matters to you what it sounds like. That’s not actually conducting. It’s kind of embodying or representing a kind of aspiration, if you will, and it’s uncanny how that actually can make a difference. As soon as it’s apparent that your ears are open and that you’re interested and you’re following the contour of the sound, then that very contour is affected by that.” ↩︎
- « Soundmen will be trained in music, acoustics, physics, mechanics and related fields to a degree enabling them to control and improve the sonority of recordings. […] The student should will be trained to notice all the differences between the image in his mind of the manner in which music should sound when perfectly played and the real playing; he will be able to name these differences and to tell how to correct them. » ↩︎
- STRAUSS, R., Elektra. Wiener Philharmoniker (Georg Solti), Londres, Decca, 1966. ↩︎
- WAGNER, R., Der Ring des Nibelungen. Wiener Philharmoniker (Georg Solti), Londres, Decca, 1958-1964. ↩︎
- Blanchet & Gotman, 2007, p.25. ↩︎
- Blanchet & Gotman, 2007, p.27. ↩︎
- Paillé & Mucchielli, 2012, p.59. ↩︎
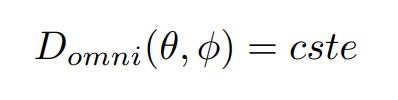
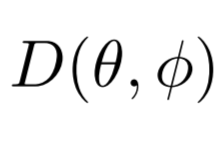
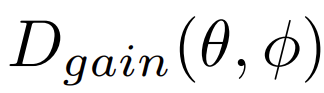
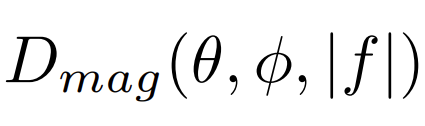
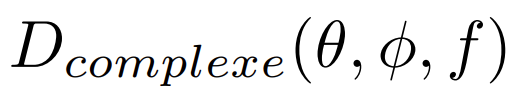
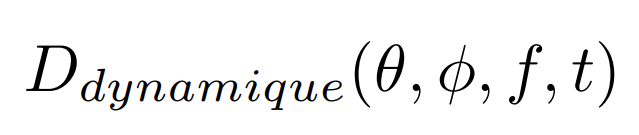
![(a) Enregistrement en conditions acous- (b) Enregistrement en conditions anéchoïques, tiré de [28] tiques, tiré de [36]
Figure 2 – Captation de sources directives en conditions acoustiques et anéchoïques](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-220.png)
![Figure 3 – Dimension caractéristique de source (d0) en conditions anéchoïques (gauche) et semi-anéchoïque (droite), extrait de [16].](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-221.png)

![Figure 5 – Analyses spectrales des différentes notes d’une trompette, enregistrement tiré de la base de données de Pollow et al [34]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-225.png)
![Figure 6 – Diagramme de rayonnement d’un monopole à 1000Hz décalé de 30cm, avant et après recentrage acoustique, tiré de [10]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-226.png)
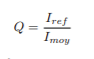
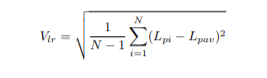

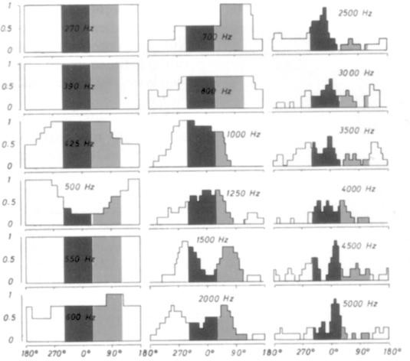
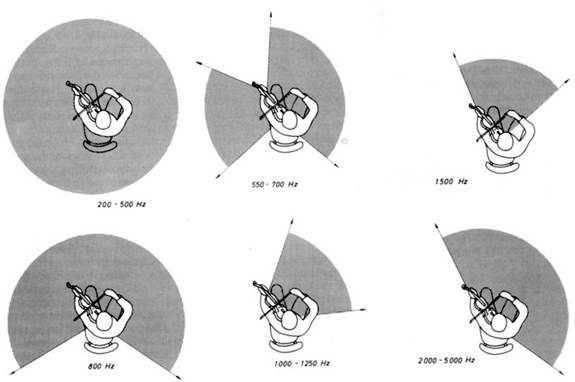
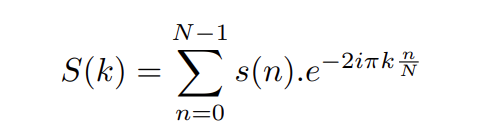
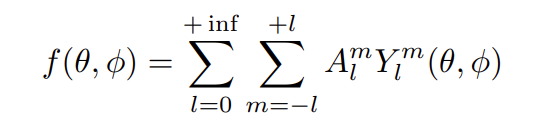
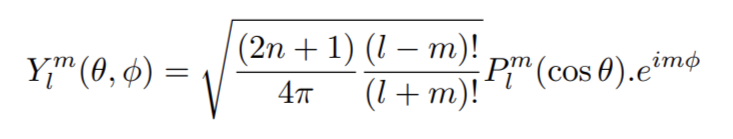


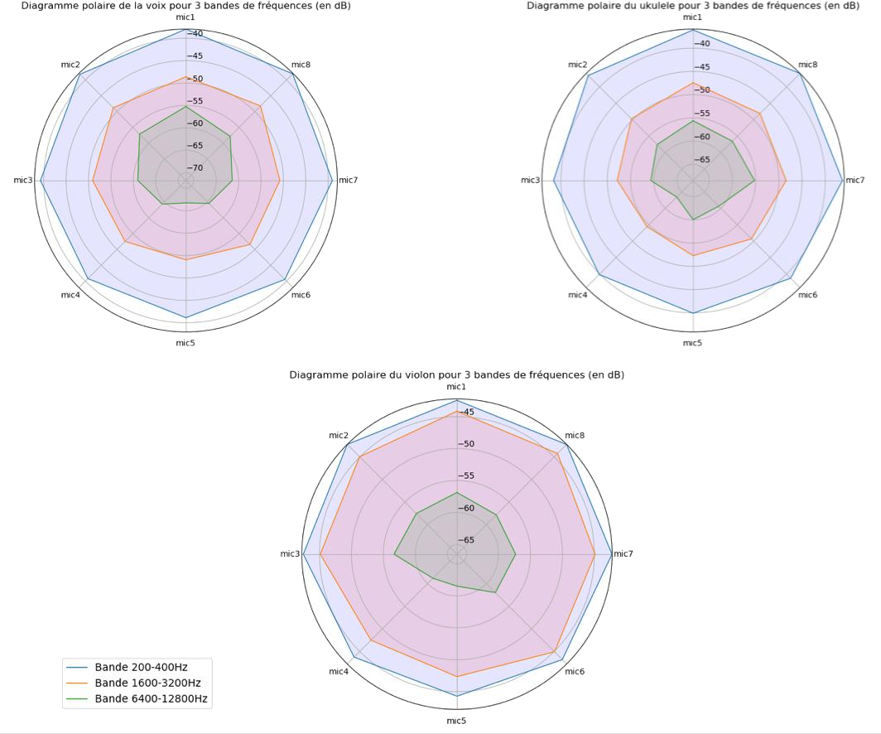
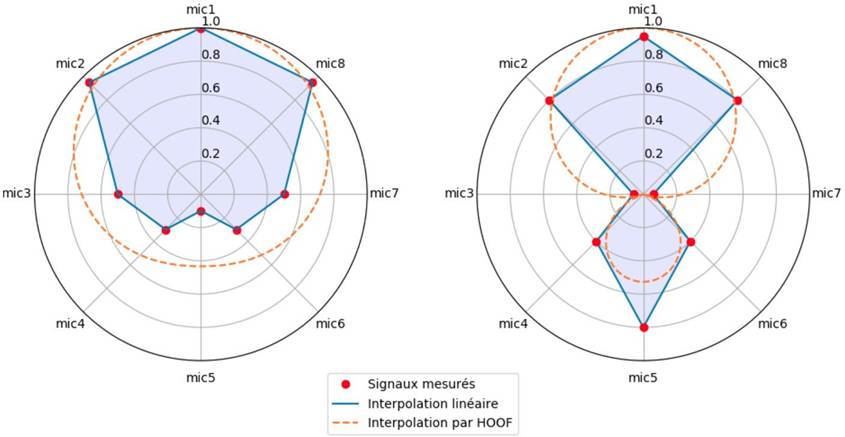
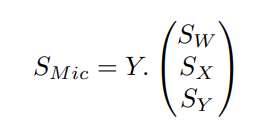
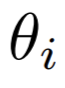
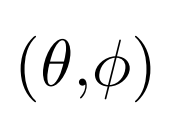
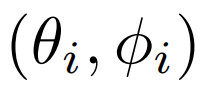
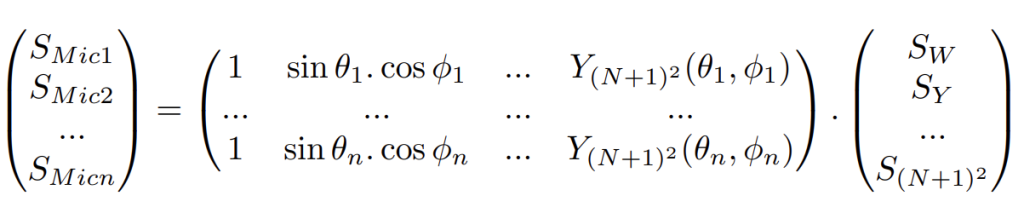
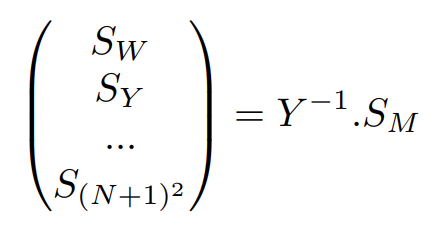
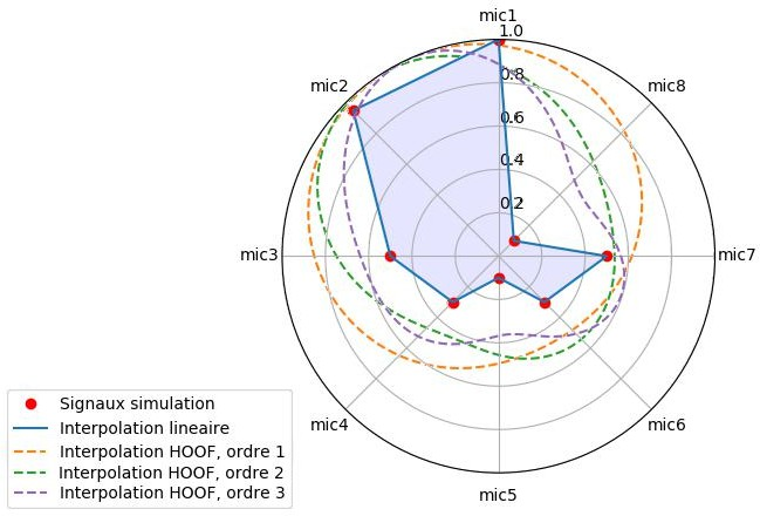
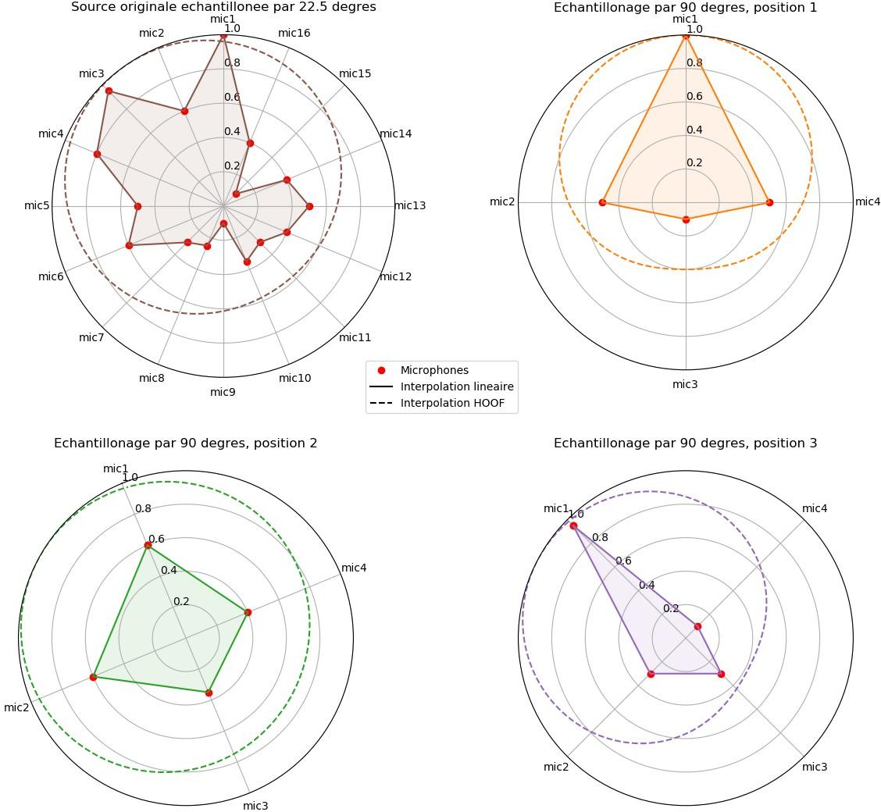
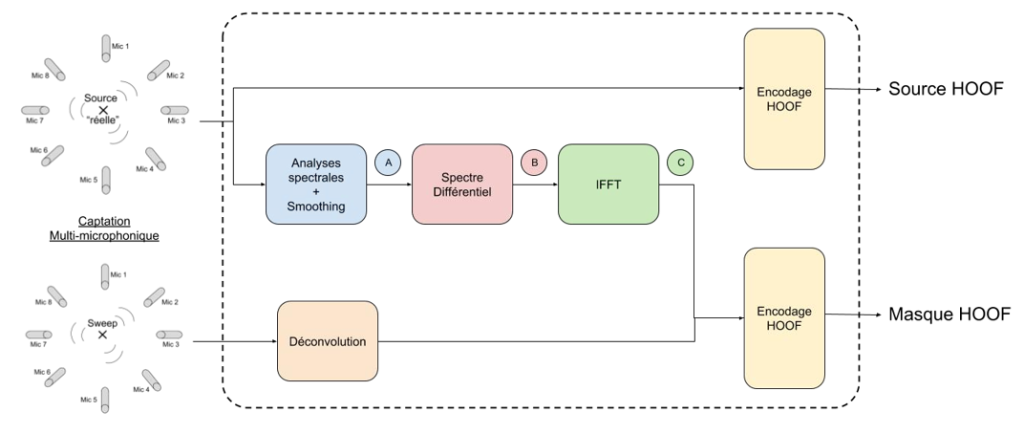

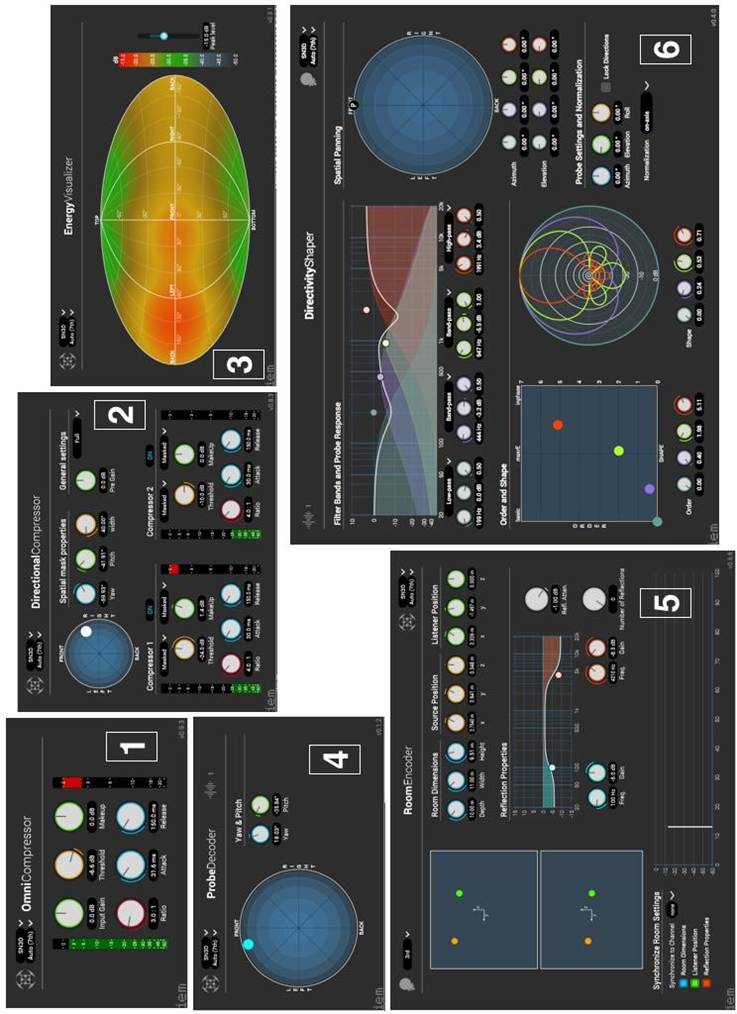
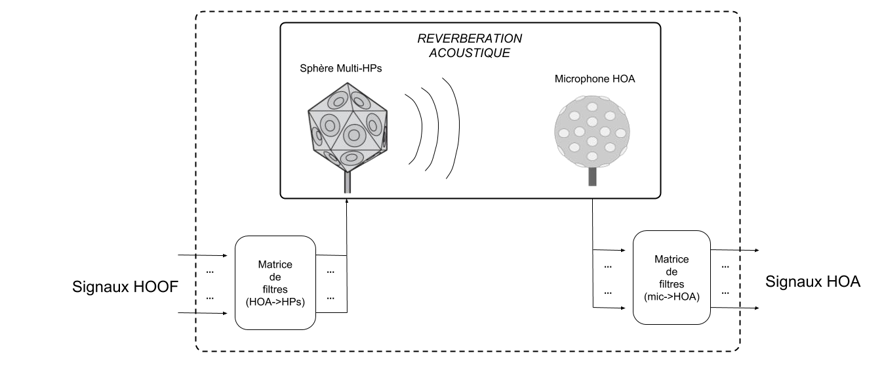
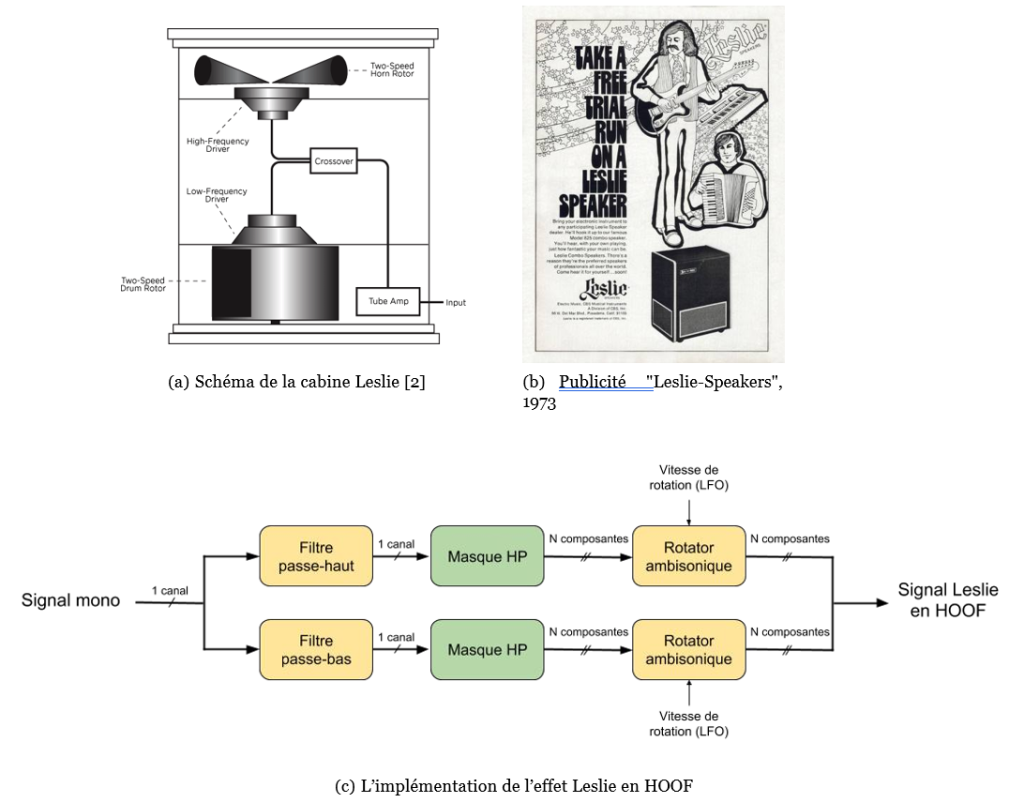

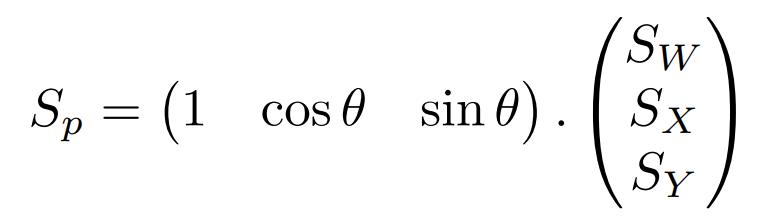
![Figure 25 – Lobes de directivité associés aux différents décodages ambisoniques, ordres 1 à 4. Figures tirées de [8].](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-252.png)
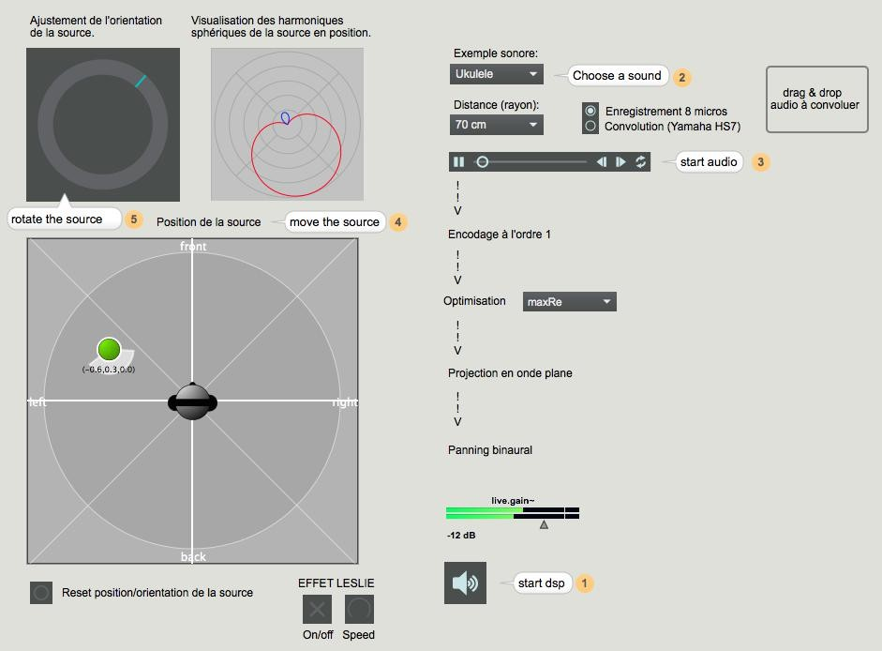















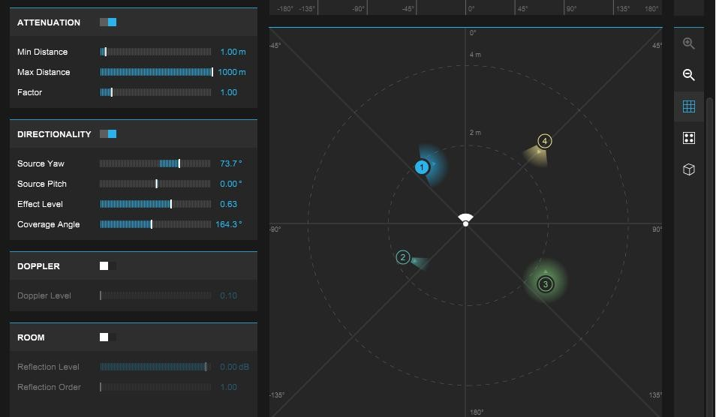
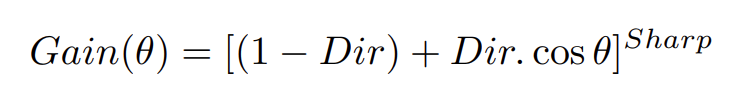
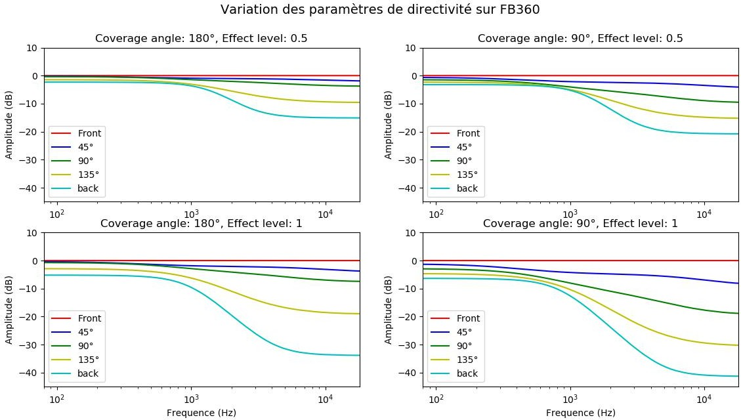
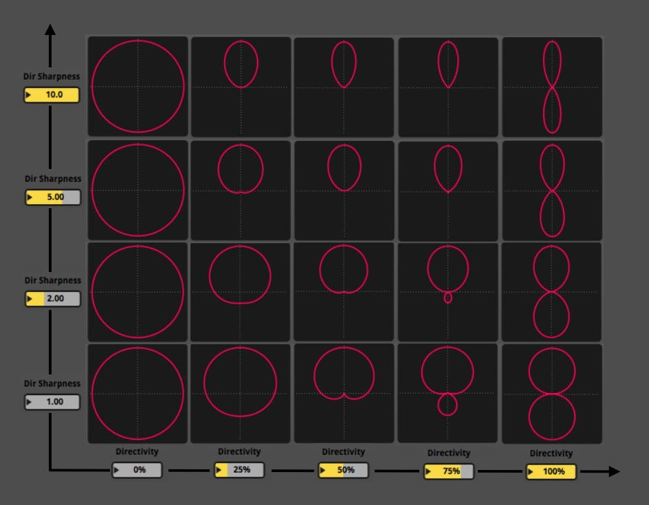















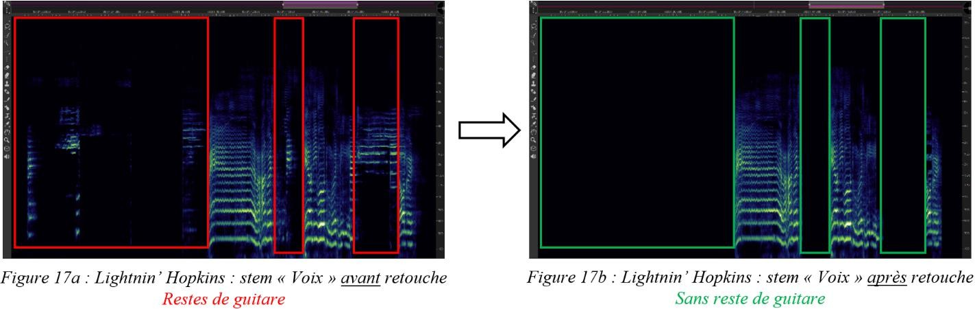
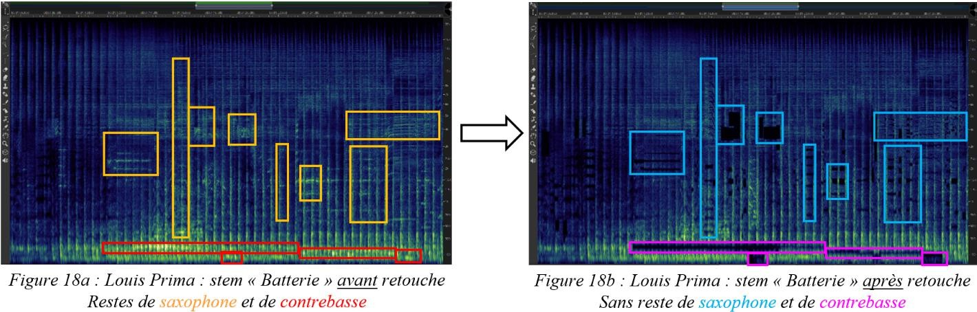

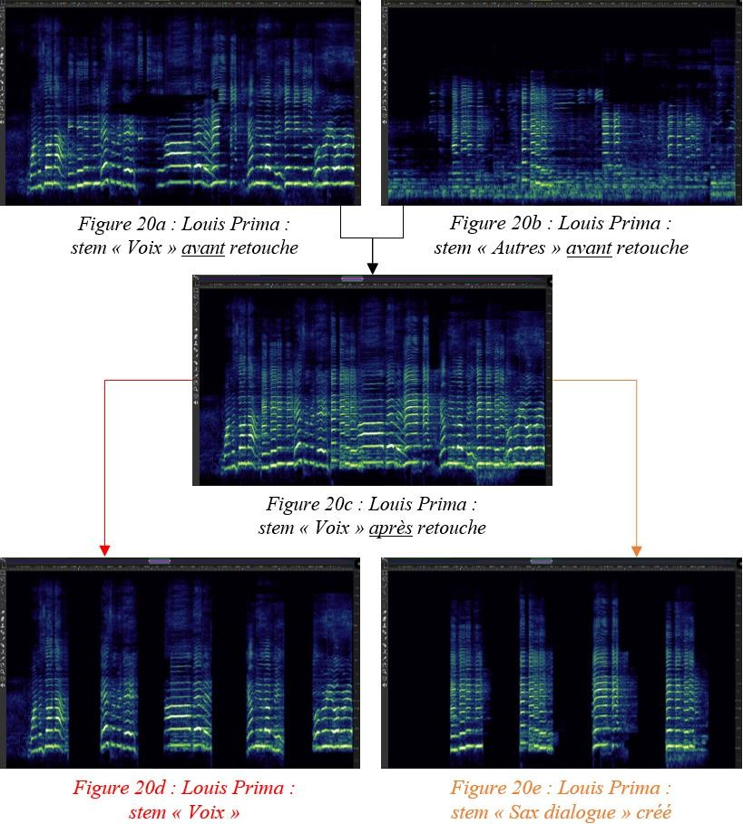

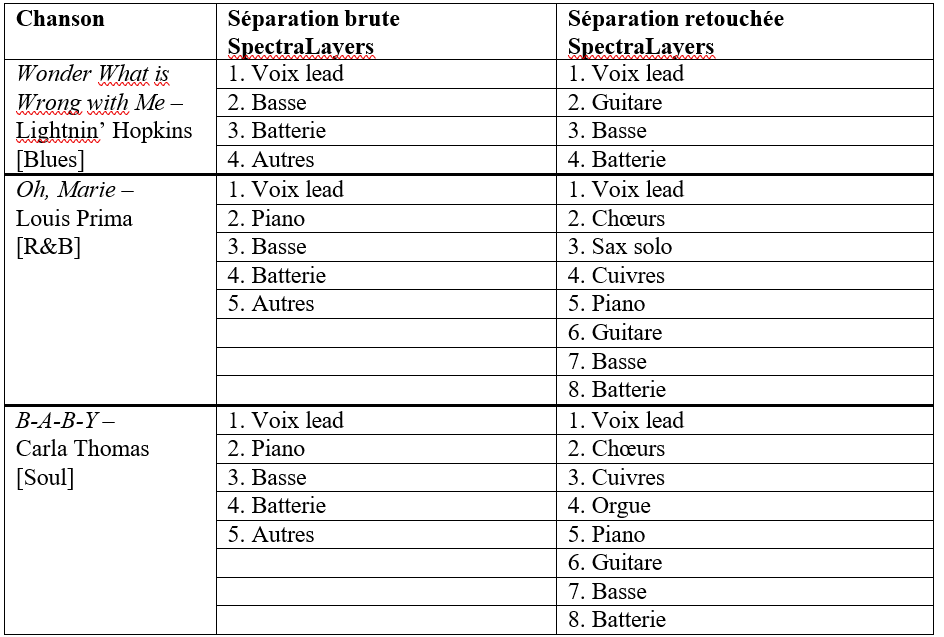
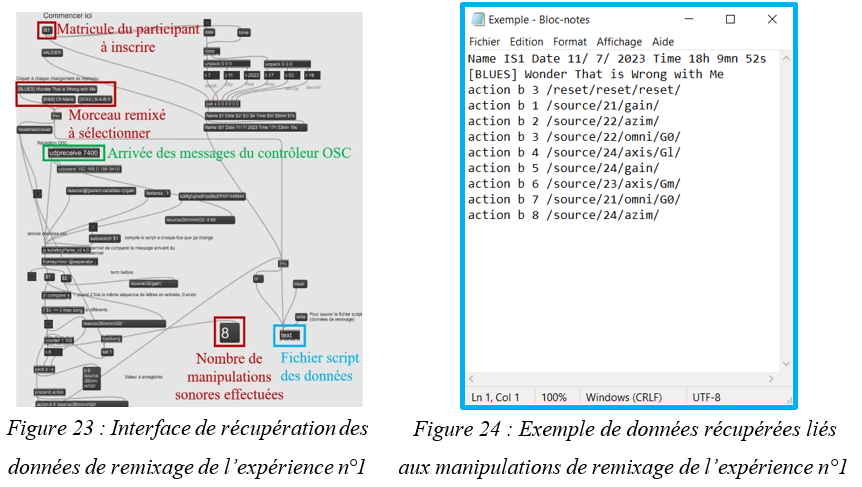
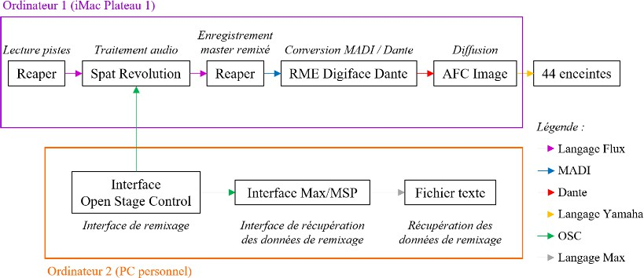
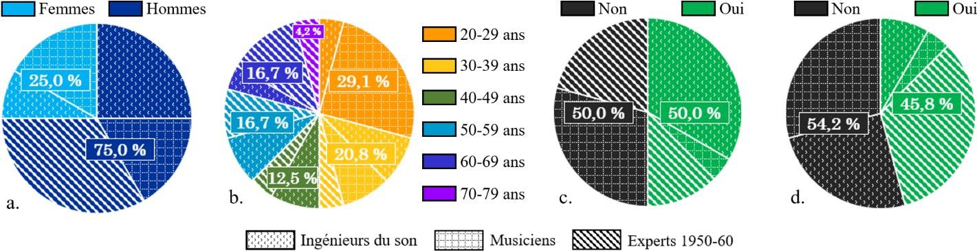


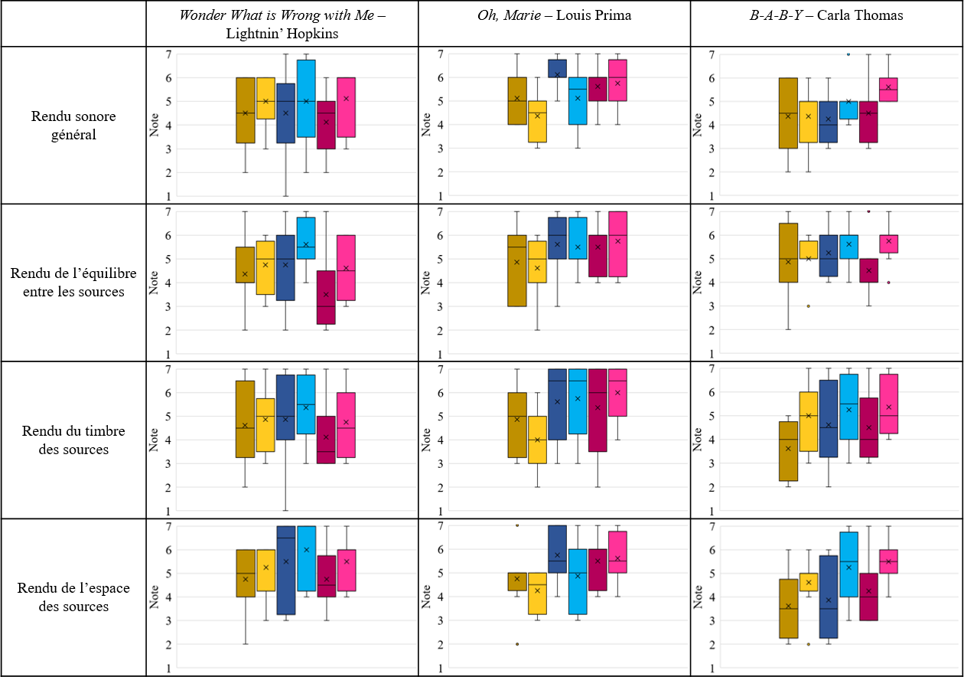

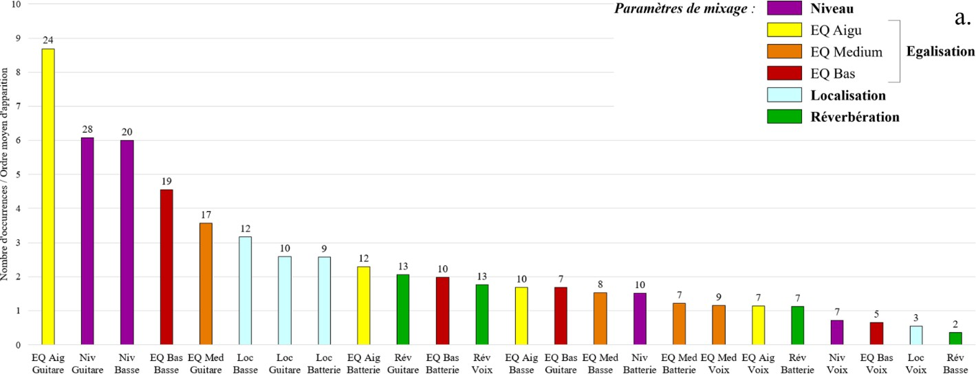
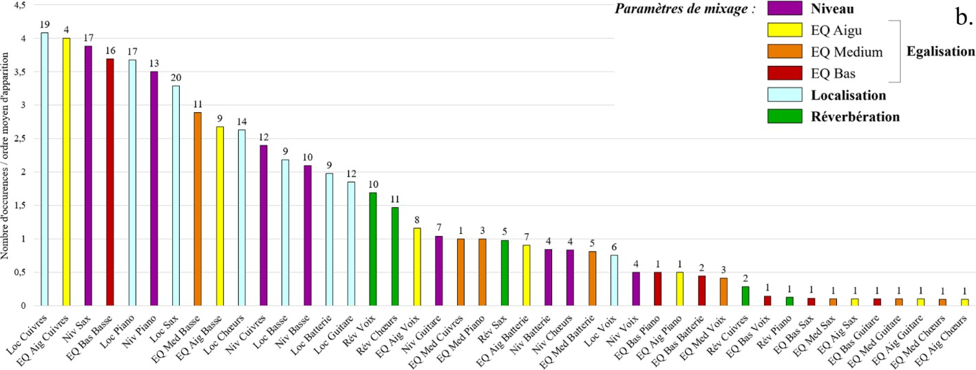
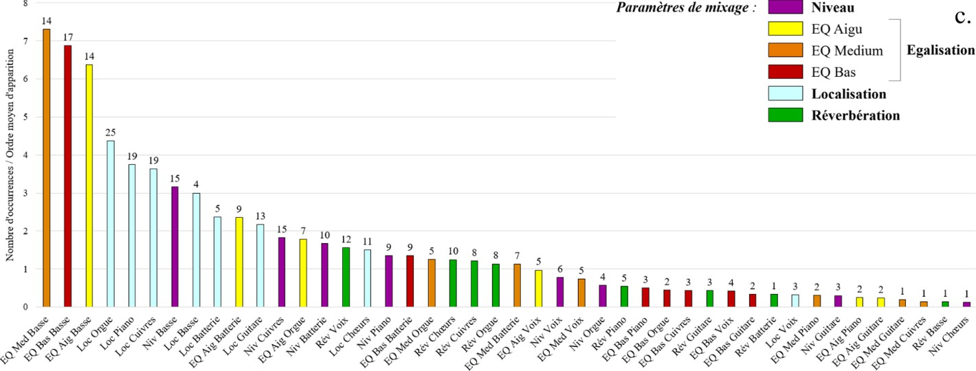
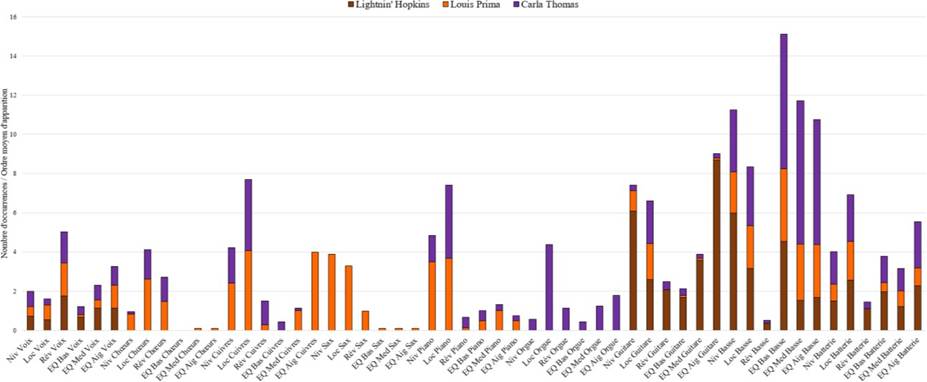

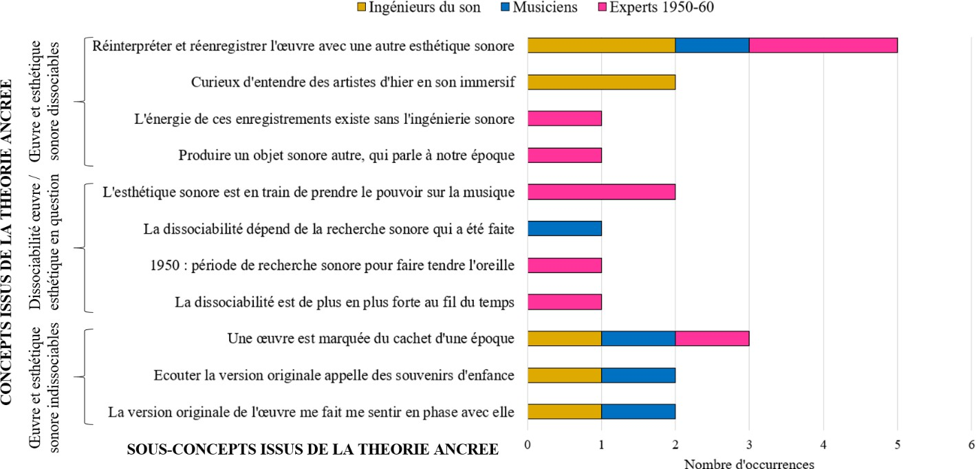
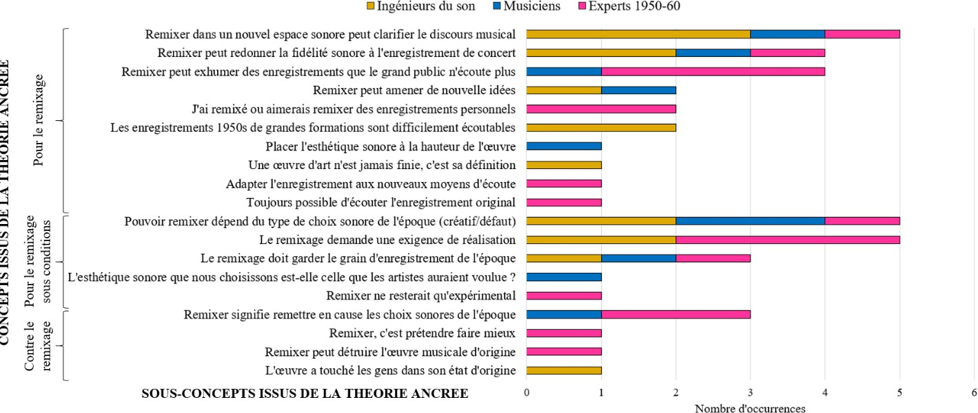
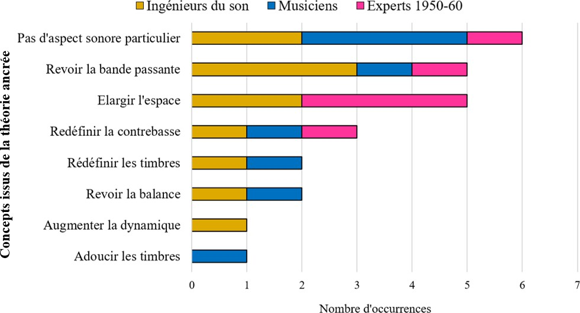
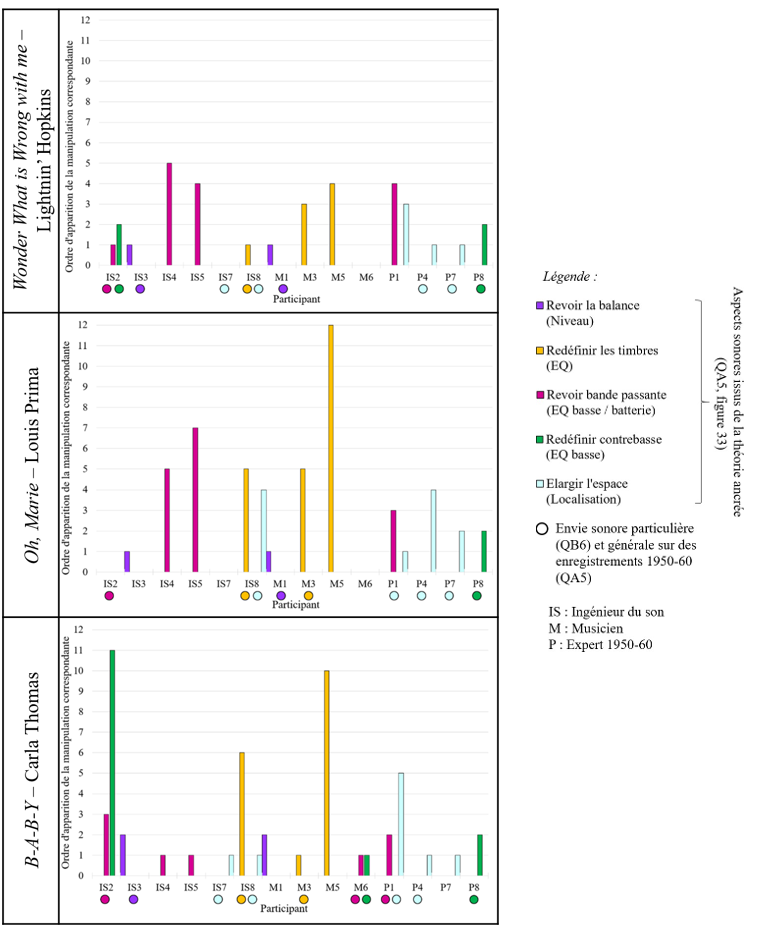
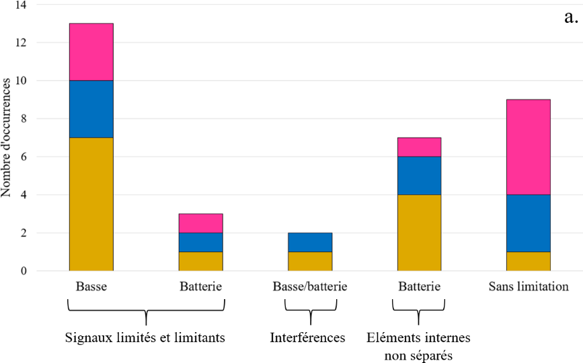
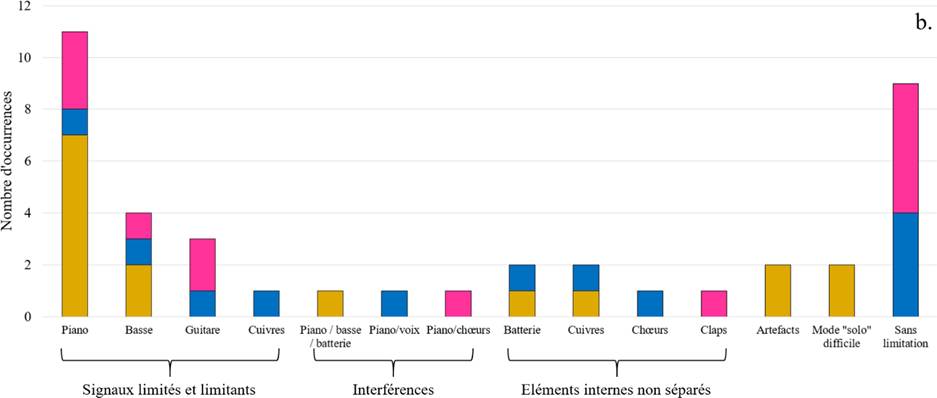
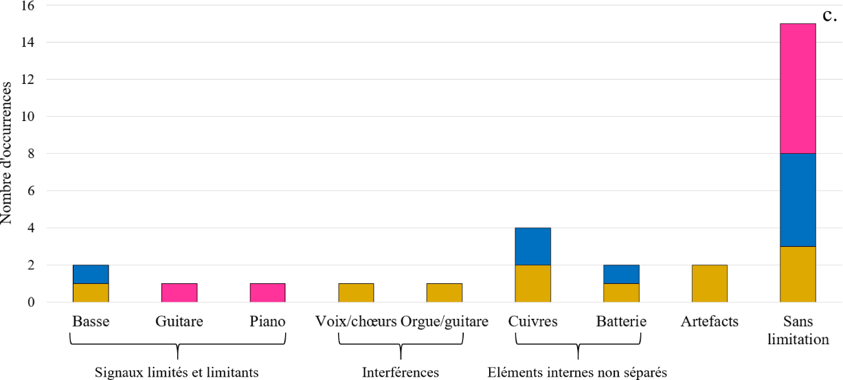
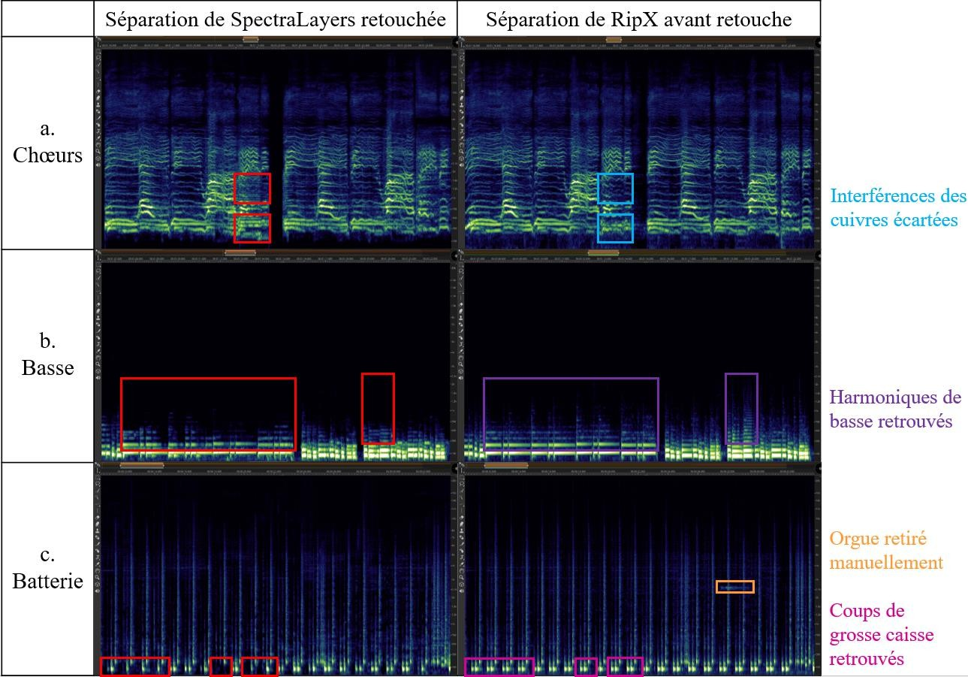
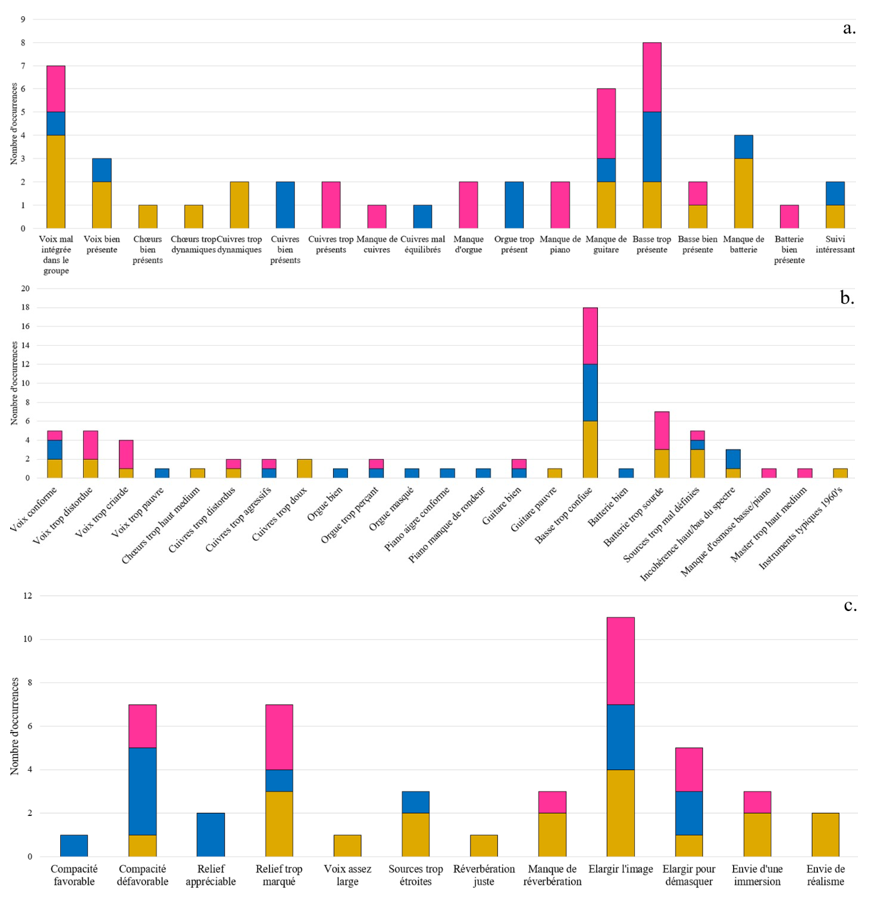
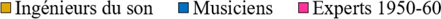
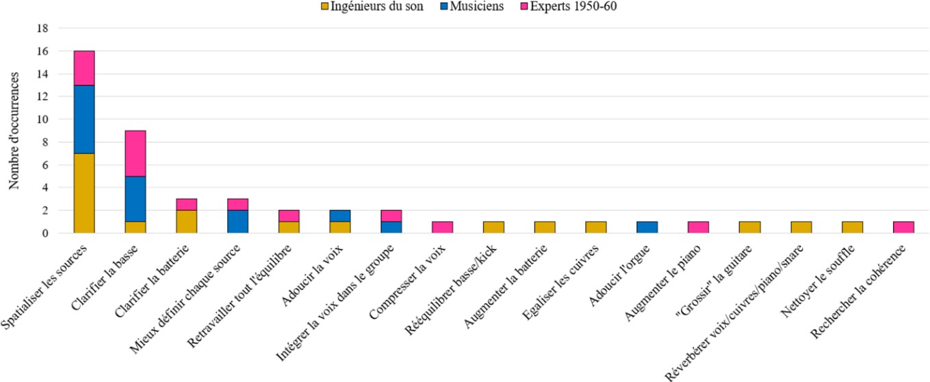



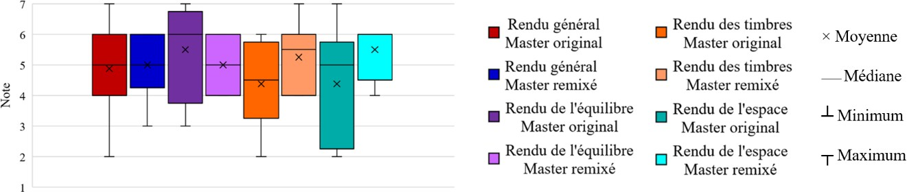
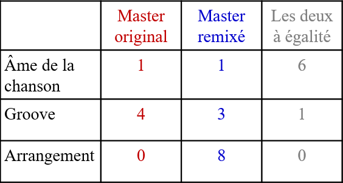
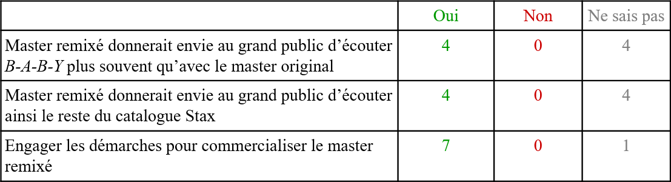
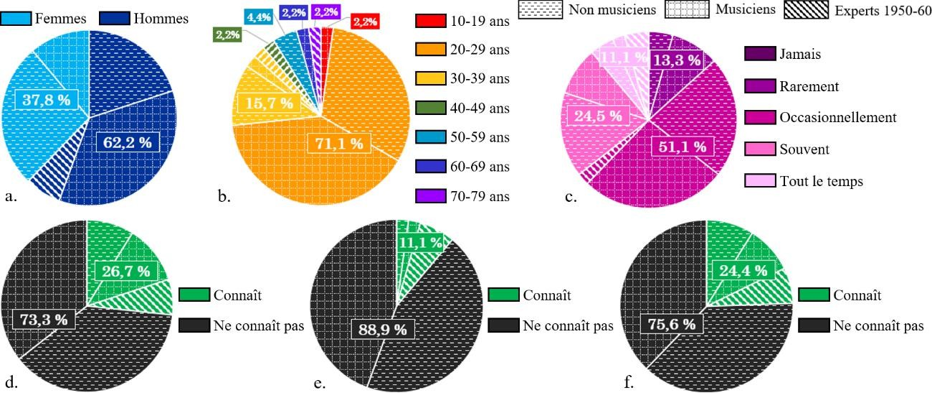
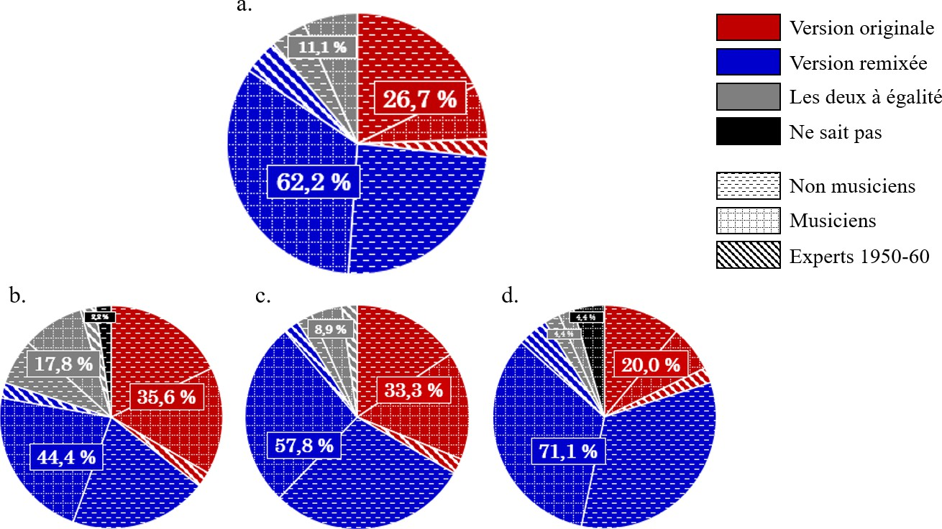
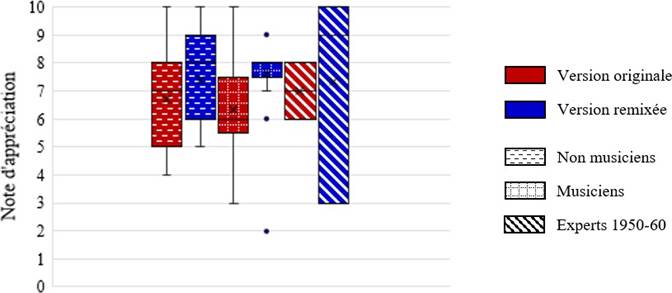
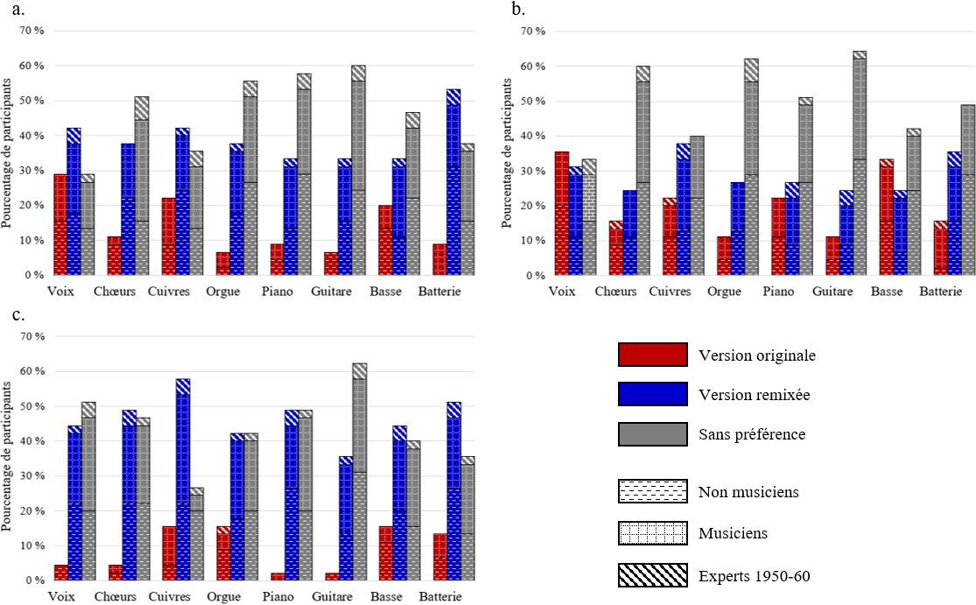

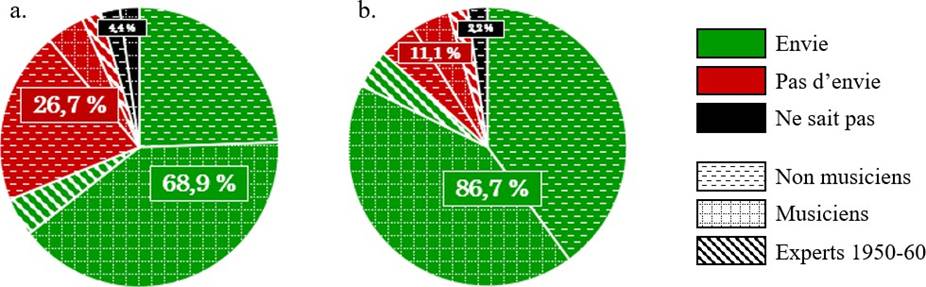




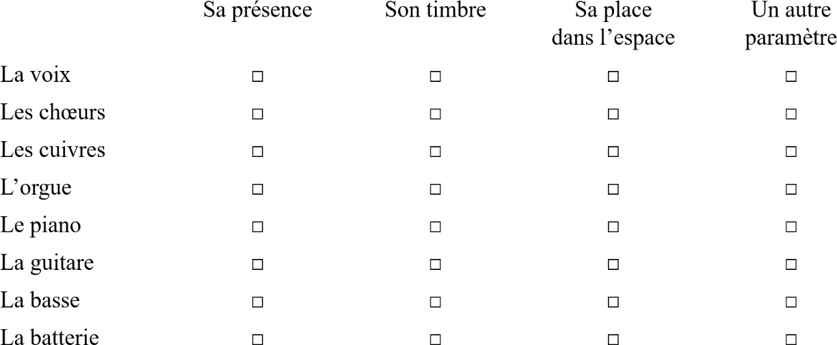
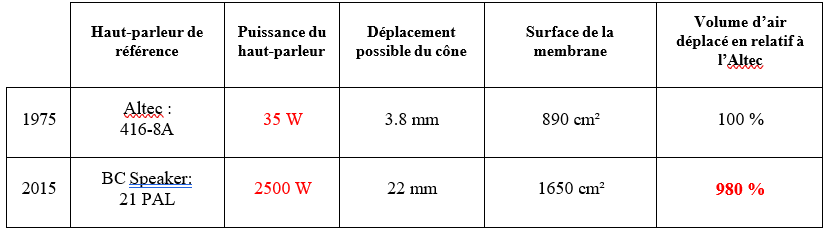
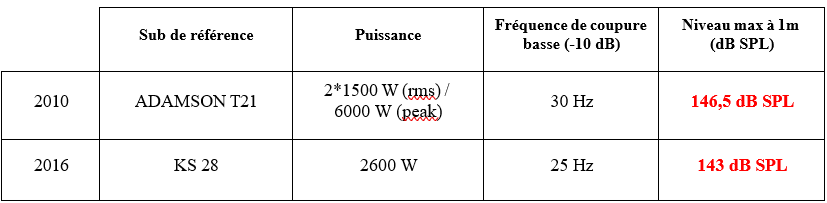
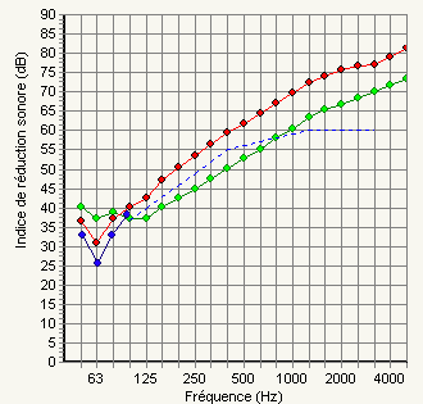
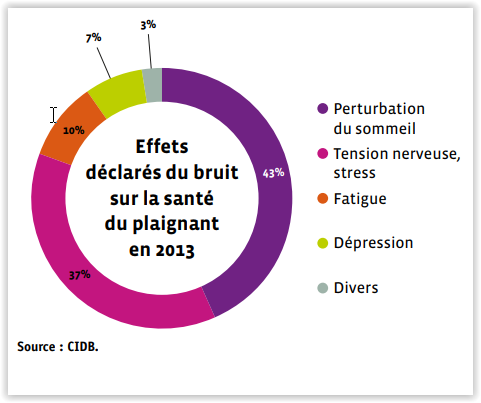
![Figure 2 : (A) un obstacle très petit devant la longueur d'onde (B) un obstacle plus grand que la longueur d'onde (Everest F. Alton, [5])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-56.png)
![Figure 3 : Cas en 2D d'ondes stationnaires entre deux parois rigides et réfléchissantes (Jouhaneau J., 1992, [13])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-113707.png)
![Figure 4 : Vue dans l'espace. Modes axiaux 1D (a), Modes tangentiels 2D (b) et modes obliques 3D (c) (Jouhaneau J., 1992, [13])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-58.png)
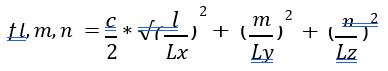
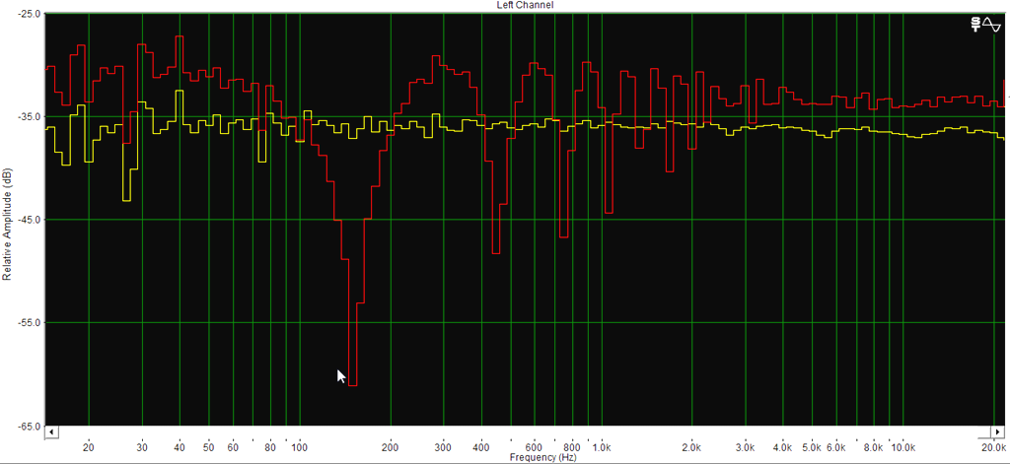
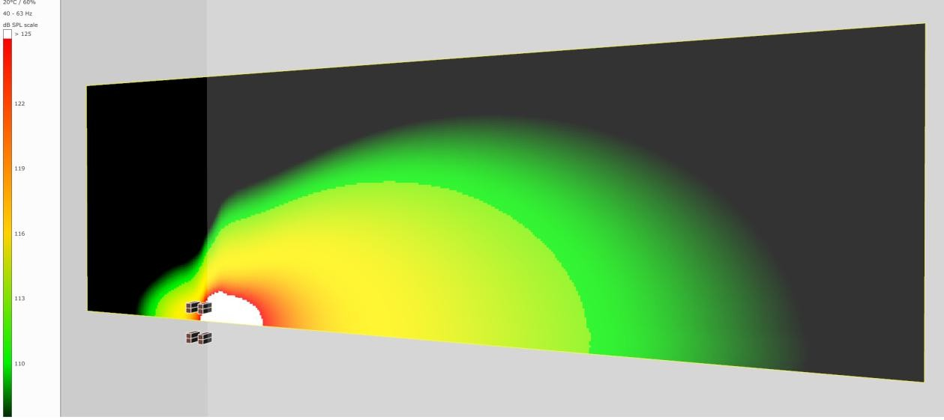
![Figure 8 : Phase et longueur d'onde (Pietquin D. 2008, [18])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-61.png)
![Figure 9 : Cercle des phases et valeurs d'annulation pour deux signaux de même niveau (Van Veen M., 2008, [24])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-114904.png)
![Figure 10 : niveaux de sommation en fonction du niveau relatif et de la phase entre les deux signaux (Mc Carthy B., 2016, [24]) (NB : « ripple » signifie maximum de variation entre l’addition et la soustraction)](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-64.png)
![Figure 11 : zones de sommation en fonction des fréquences et du décalage temporel (McCarthy B., 2016,[6]])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-65-373x1024.png)
![Figure 12 : Courbe de réponse d'un HP dans 3 situations différentes : Chambre anéchoïque (1), Angle d’une cabine en bois (2), Centre de la cabine en bois (3) (Rossi M., 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/Capture-decran-2026-06-02-115541.png)
![Figure 13 : Gain en SNR3 en fonction de temps de mesure du sweep en relatif à une mesure en bruit rose (Rousseau D.,[22])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-67.png)
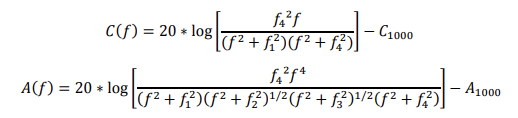
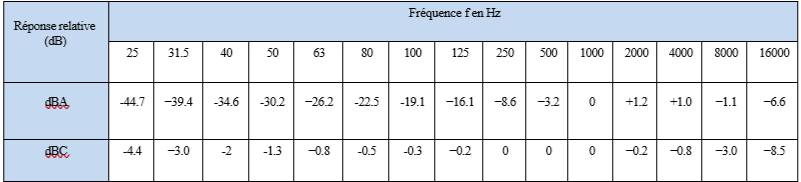
![Figure 16 : courbe du champ auditif et de pondération acoustique (HCSP, [26])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-70.png)
![Figure 18 : Influence de la taille de la FFT sur la résolution fréquentielle (Van Veen M., 2017, [24])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-72.png)
![Figure 19 : Analyse des discontinuités introduites dans le signal temporel lors de l'utilisation d'une fenêtre rectangulaire (01dB, [27])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-75.png)
![Figure 20 : Effet de la fenêtre de Hanning sur une fonction (01DB, 1996, [27])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-76.png)
![Figure 21 : fréquences (Hz) en tiers d'octave et octave (Mario Rossi, 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-77.png)
![Figure 22 : spectre en bande d'octave, tiers d'octave et 24e d'octave de la trompette jouet de Toutankhamon (Mario Rossi, 2007, [20])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-79.png)
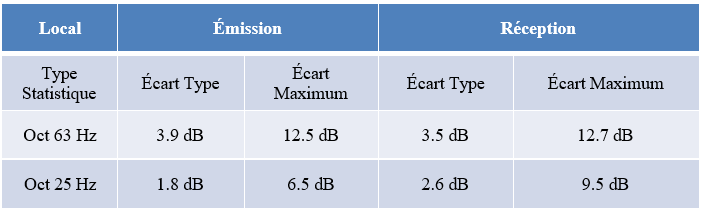
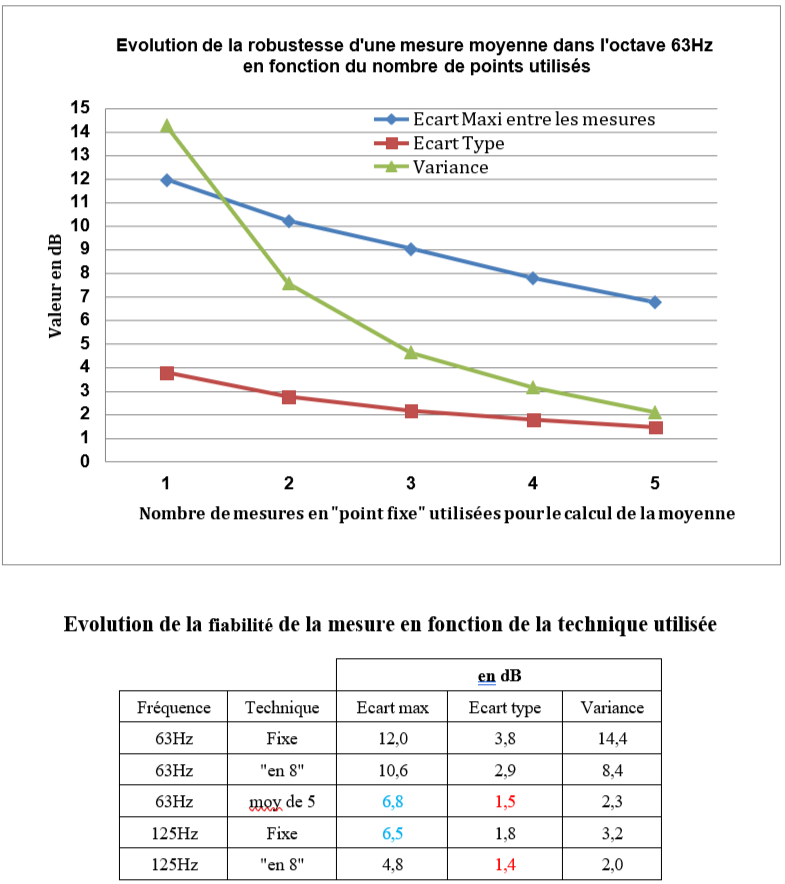
![Figure 23 : Configuration cardioïde à gradient (Bob Mc Carthy, 2016, [6])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-82.png)
![Figure 24 : Configuration End Fire (Bob Mc Carthy, 2016, [6])](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/06/image-83.png)
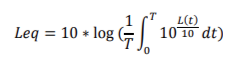

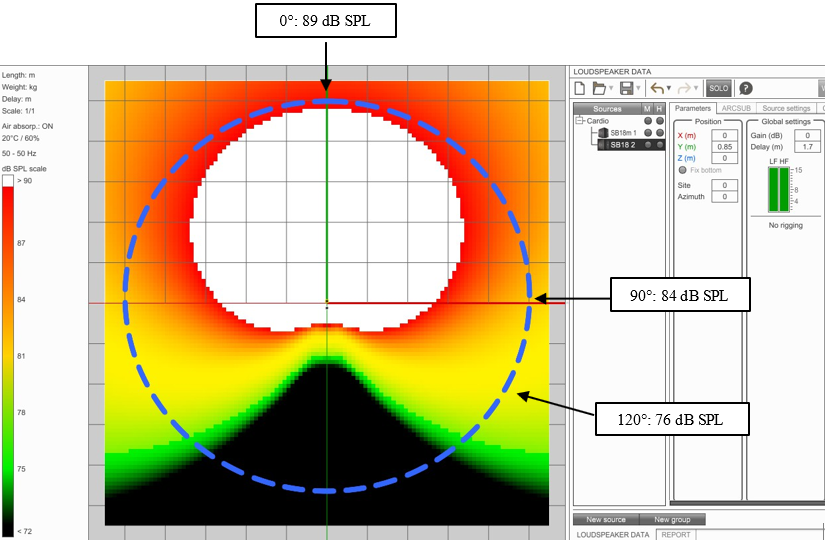
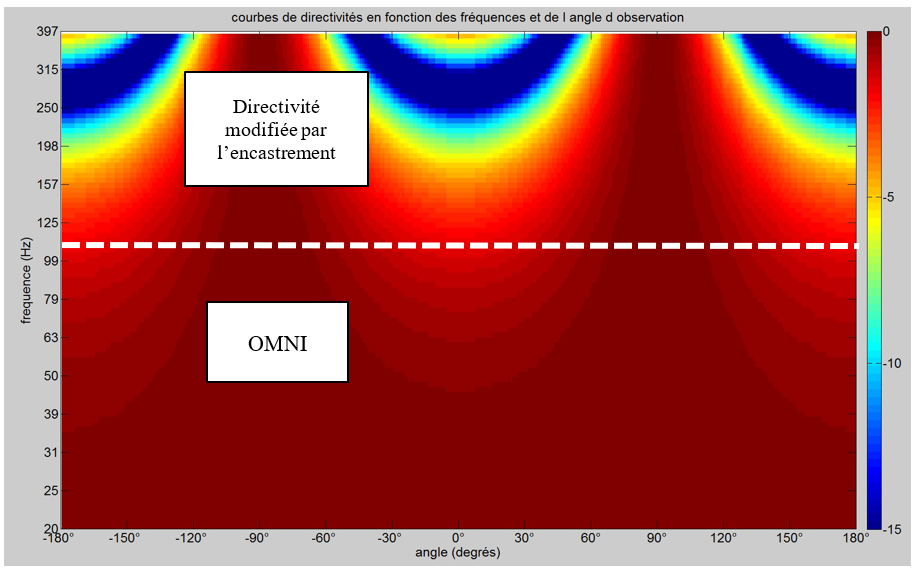
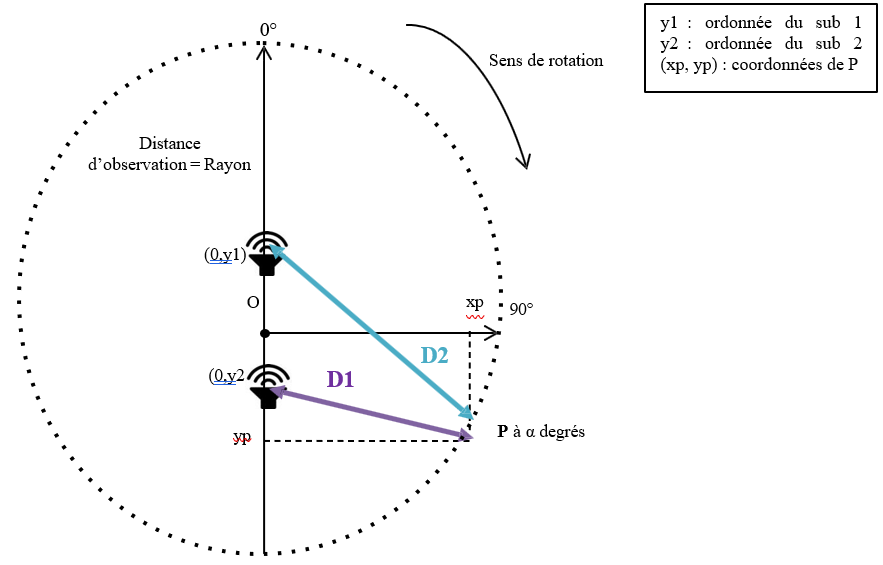
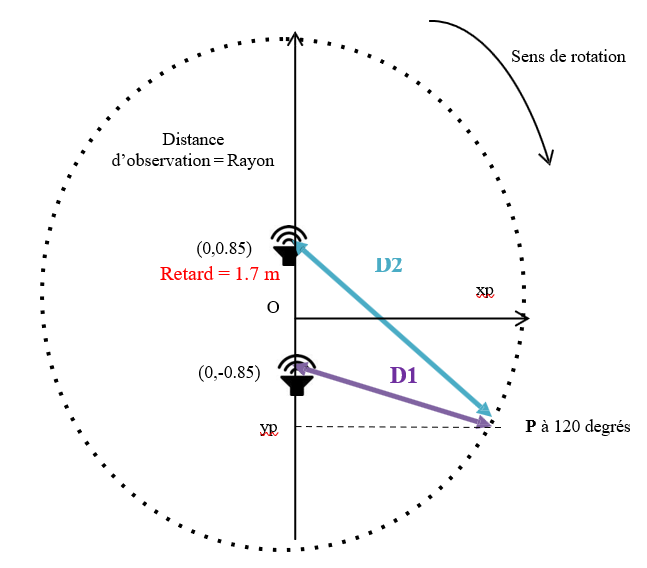
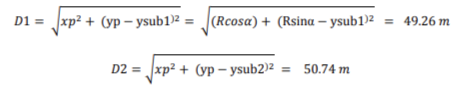
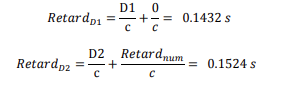
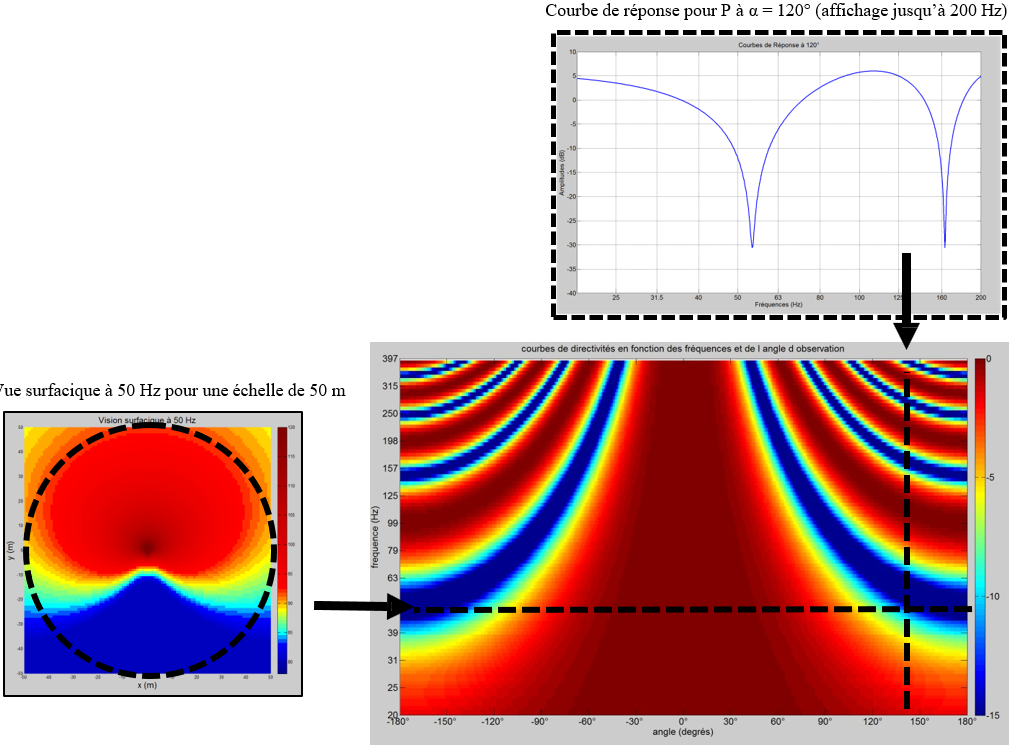
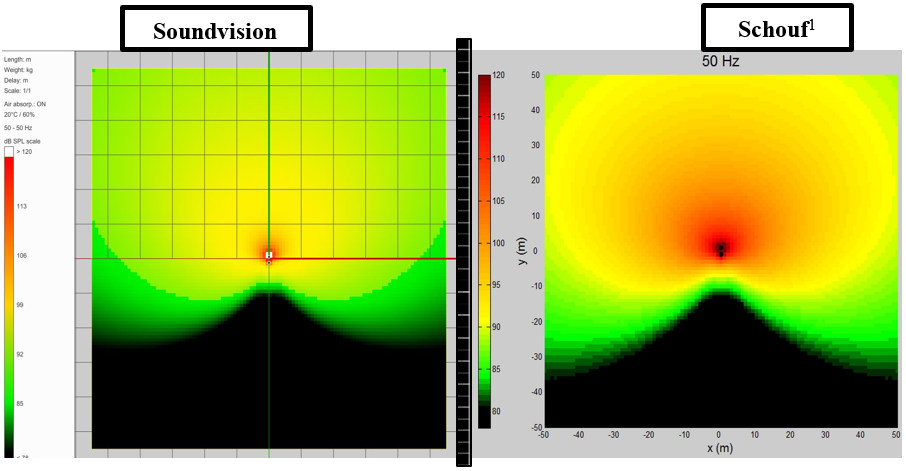
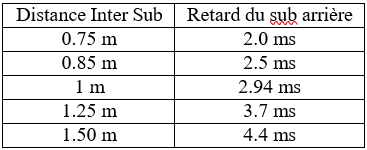
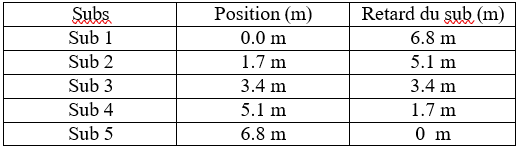
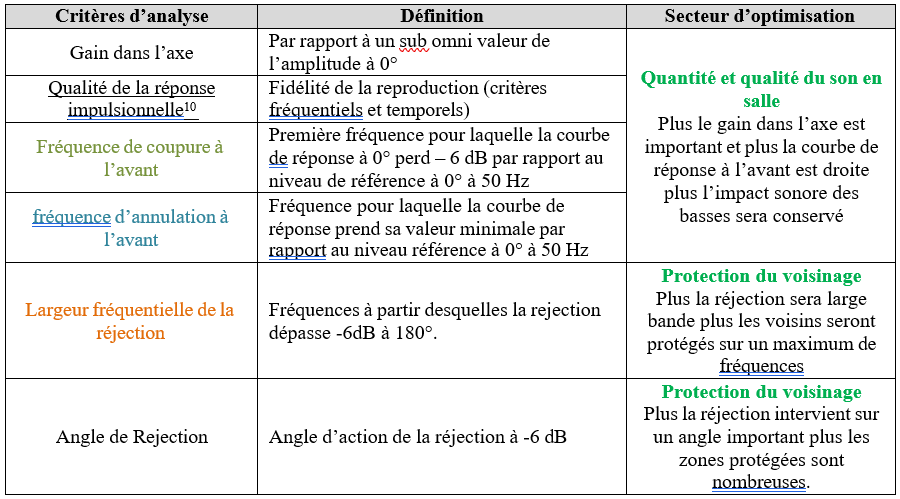
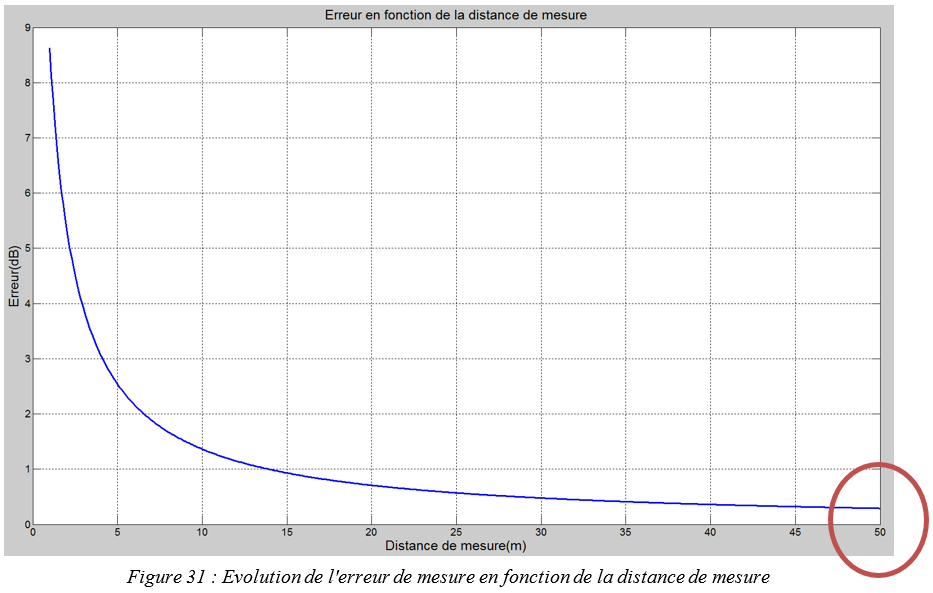
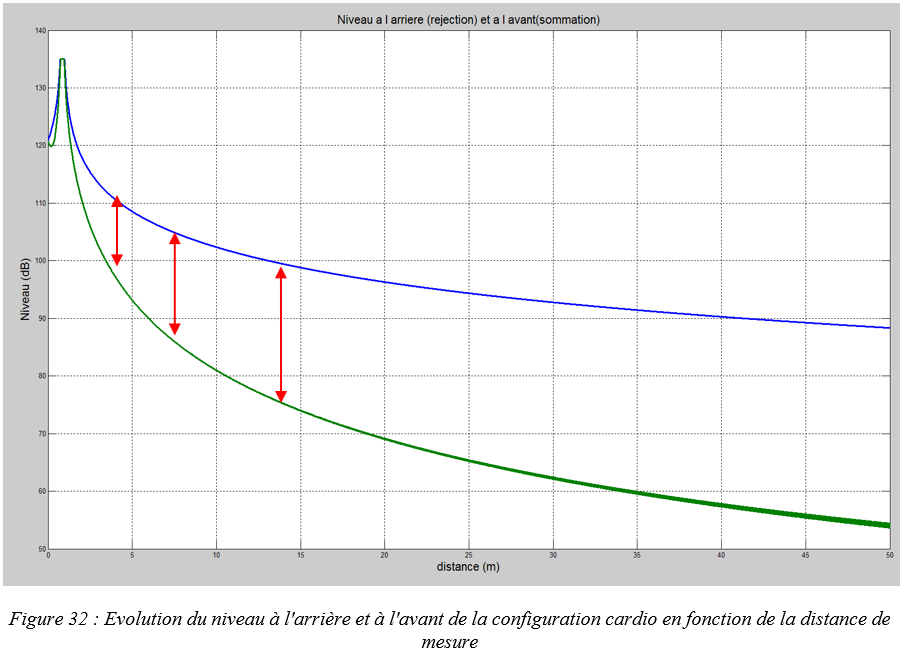
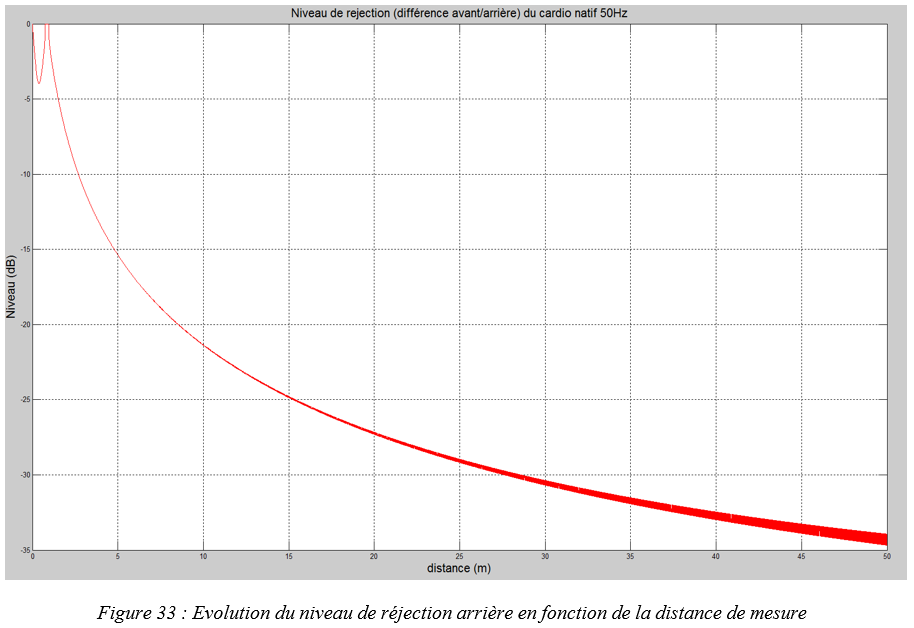
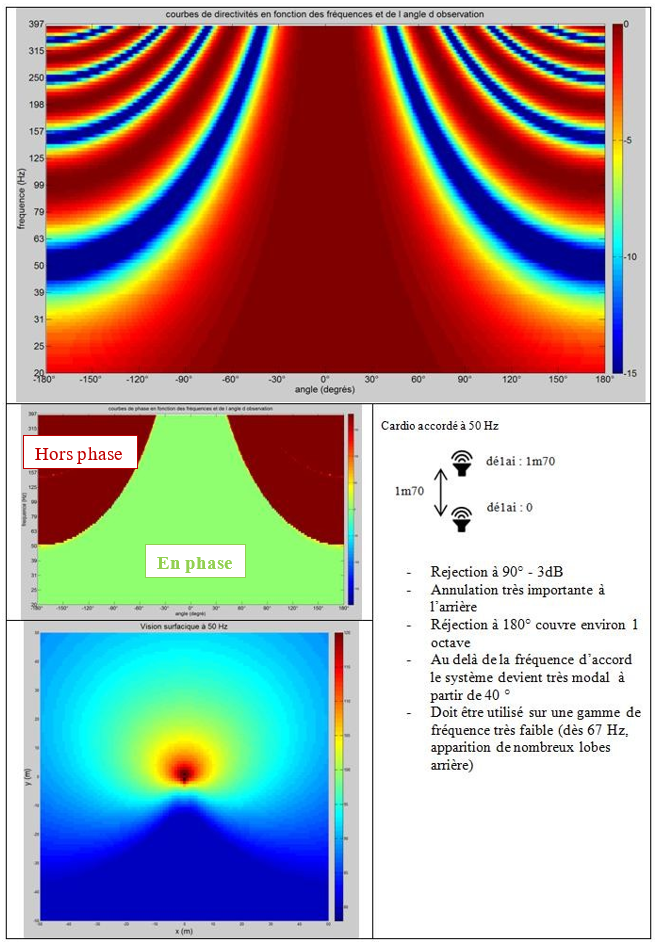
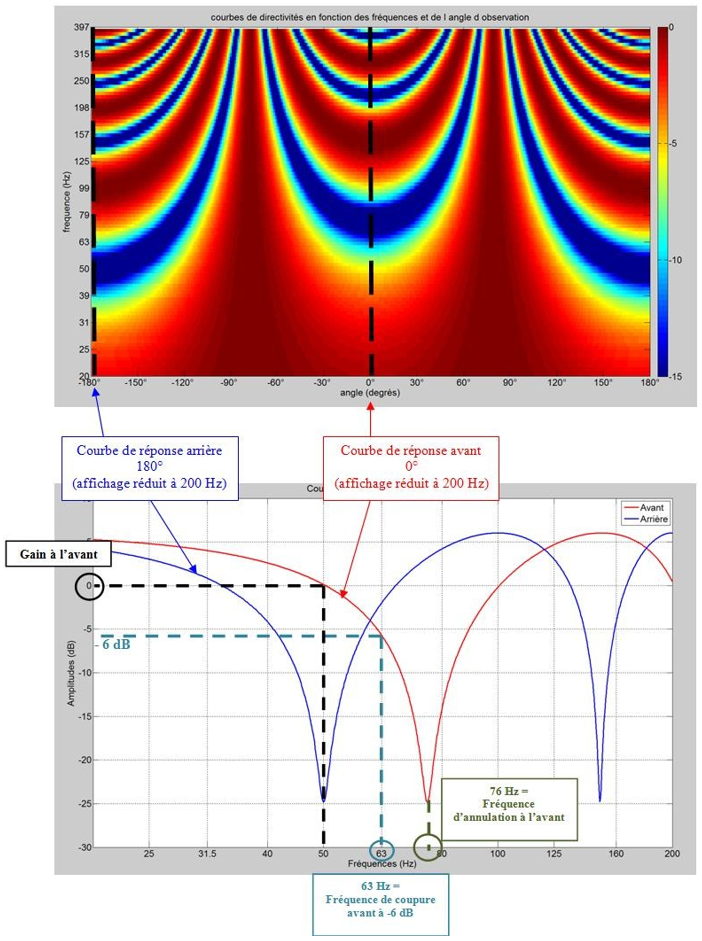
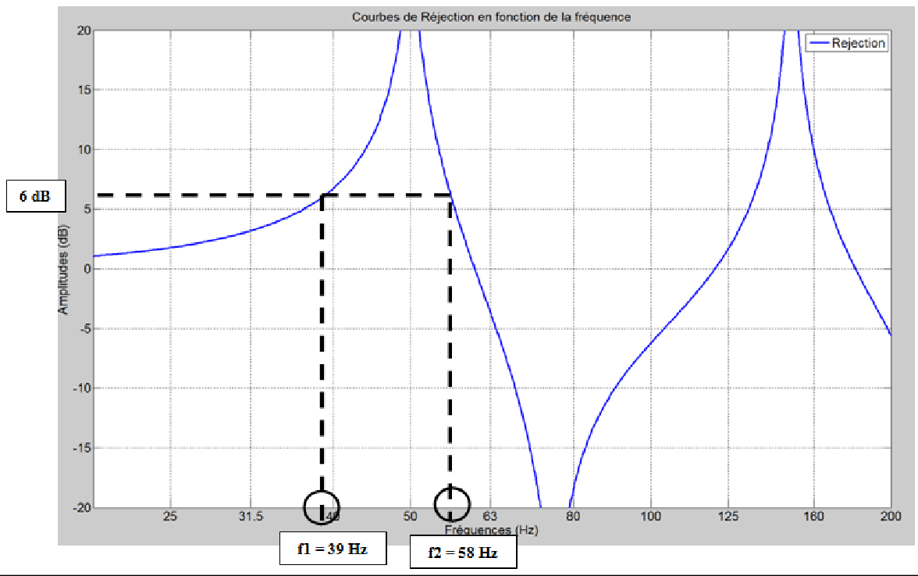
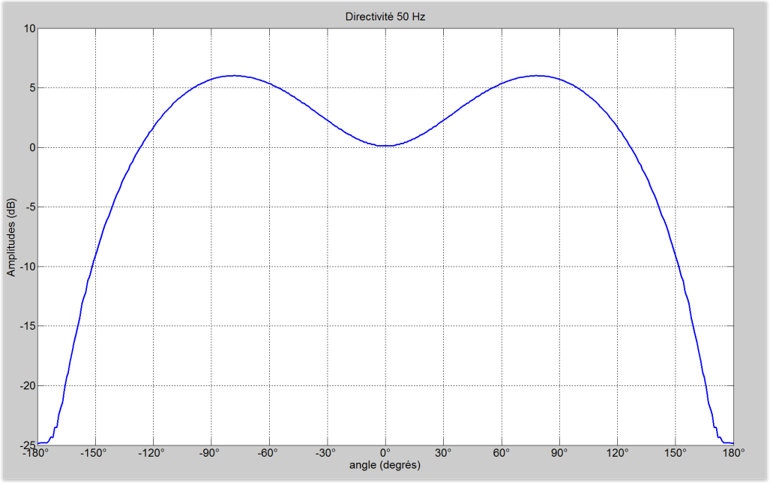
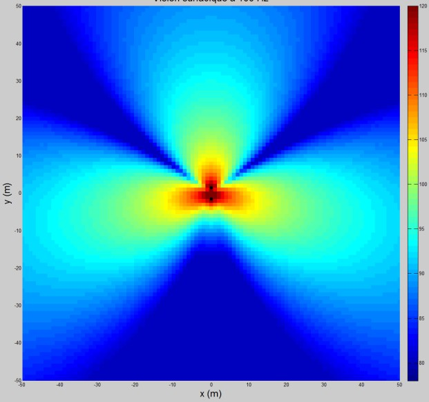
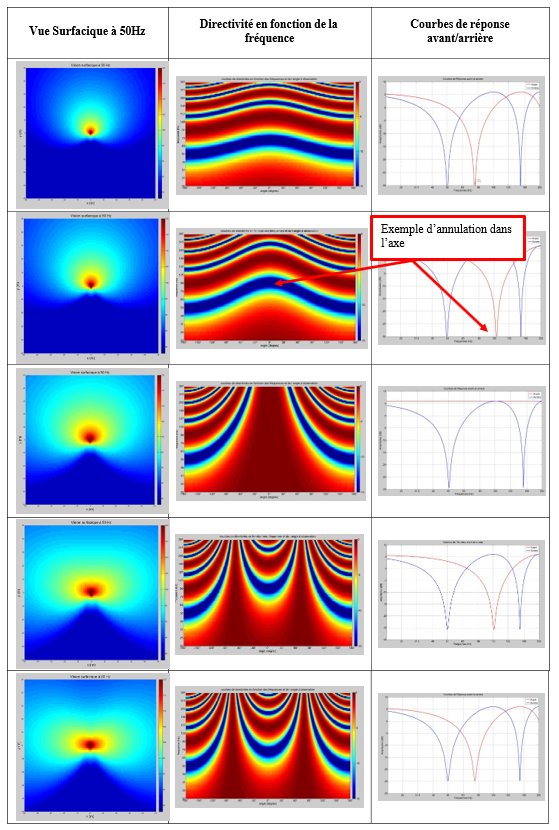
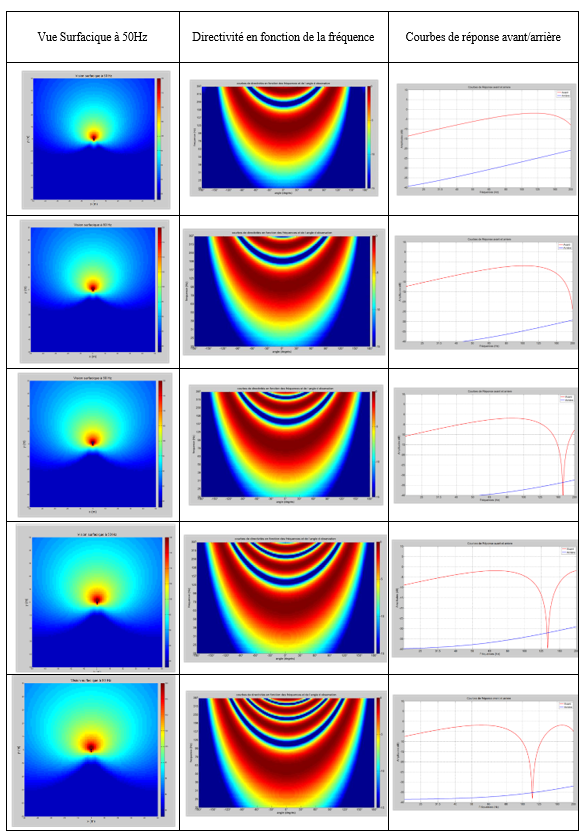
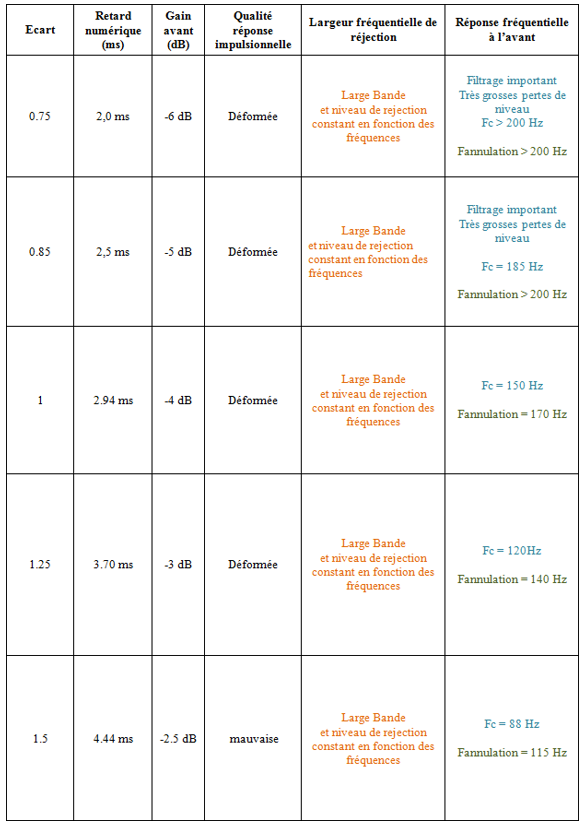
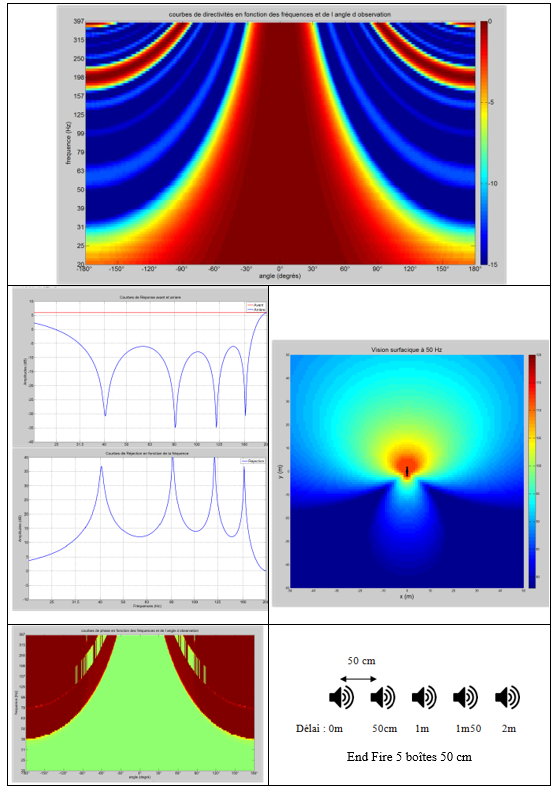
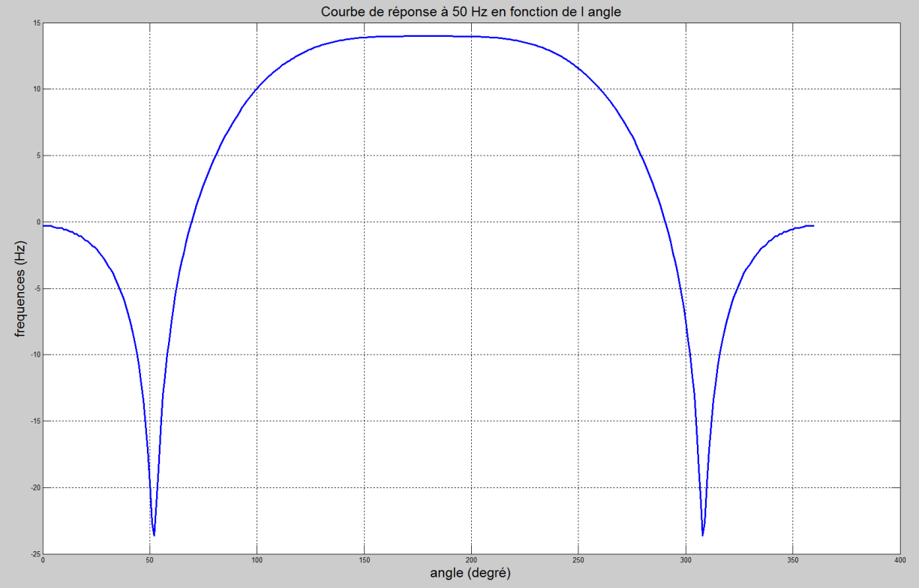
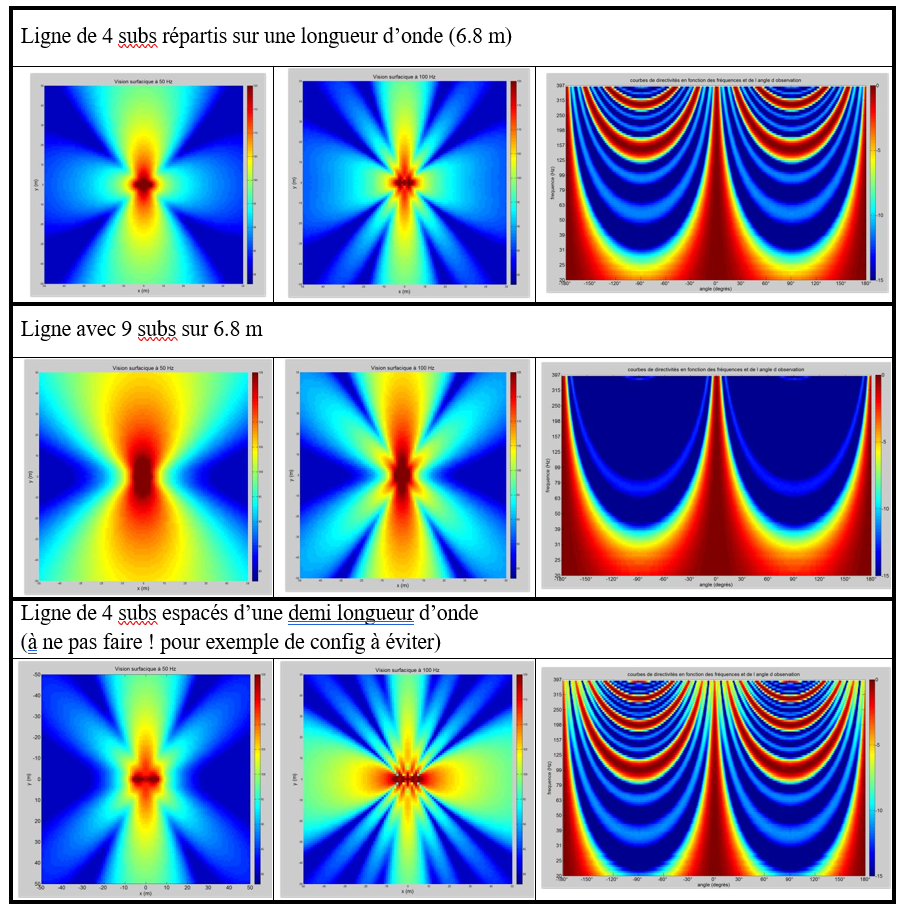
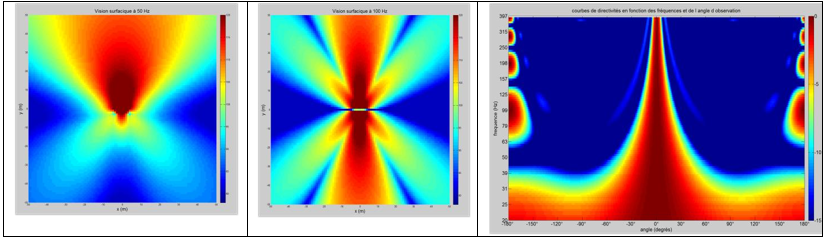
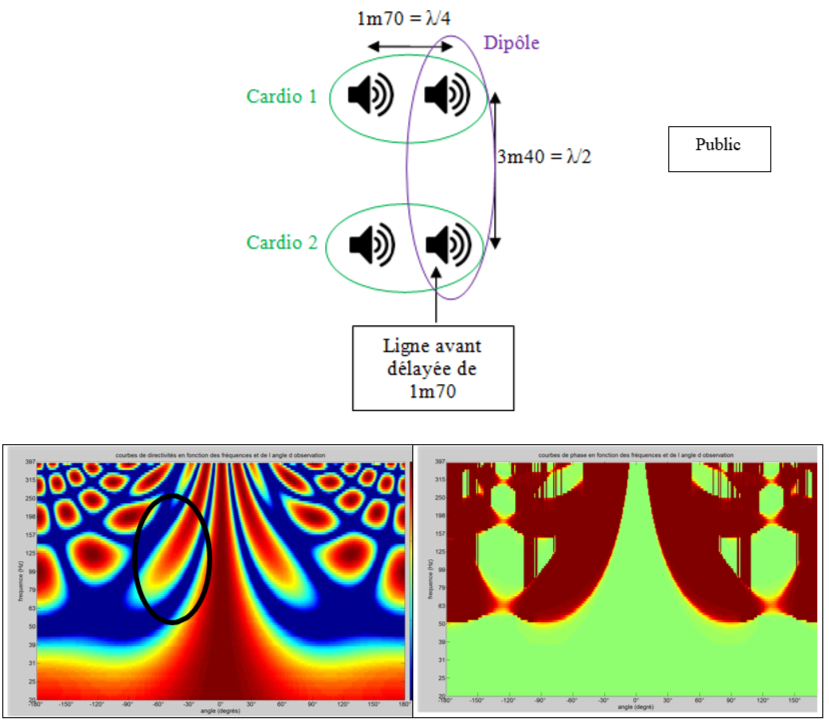




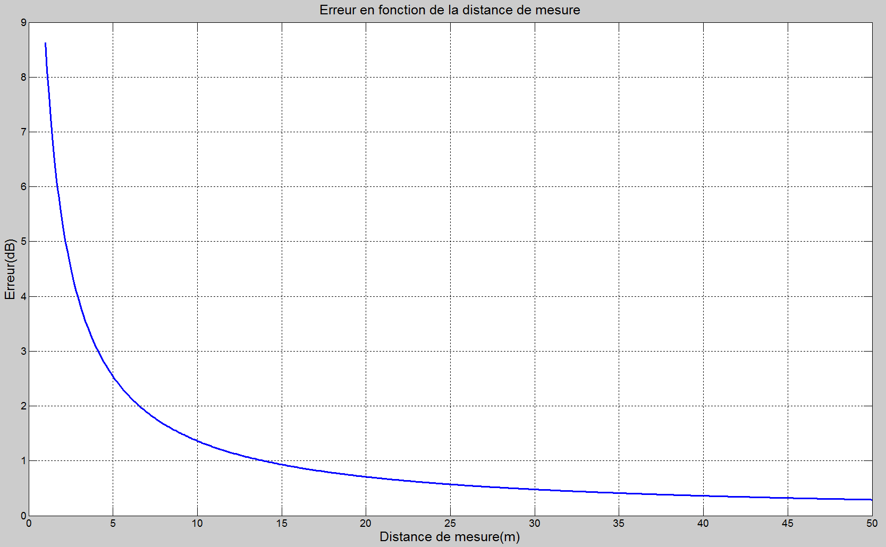

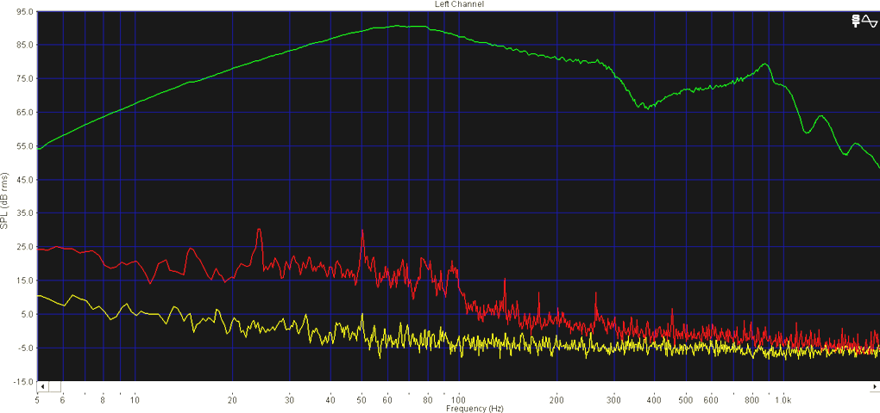
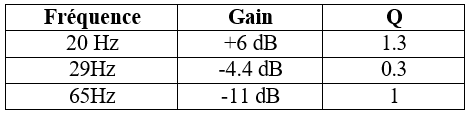
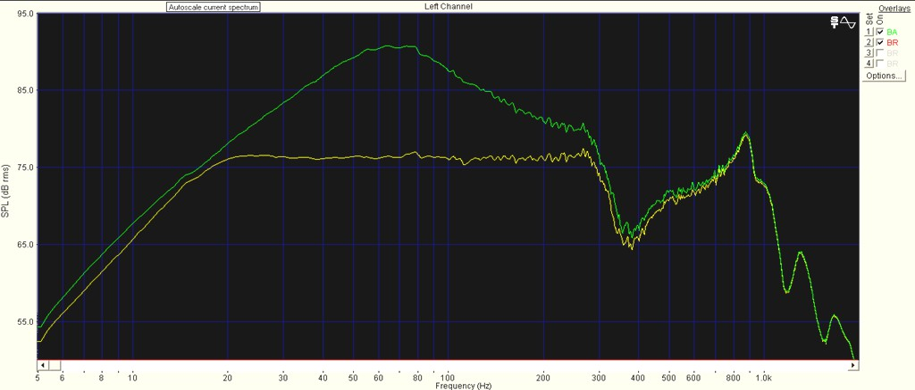
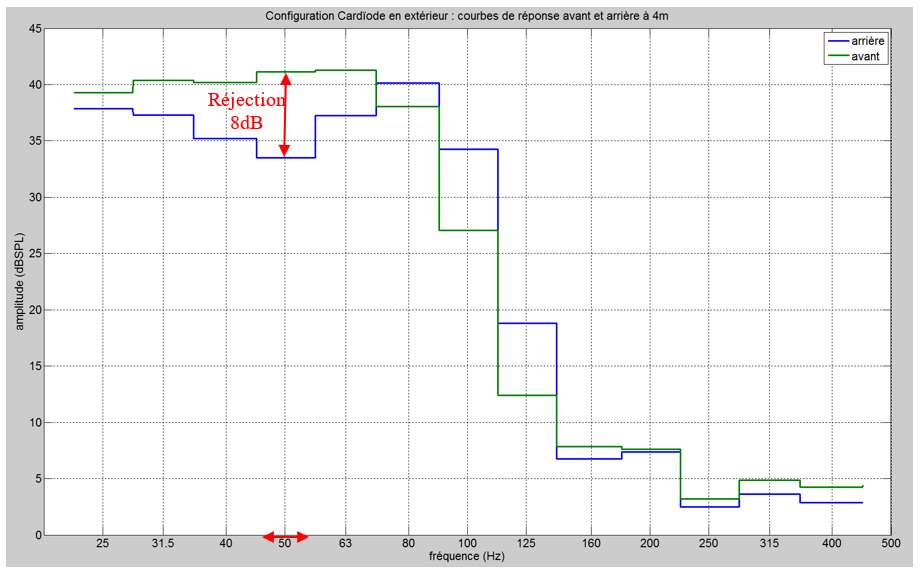
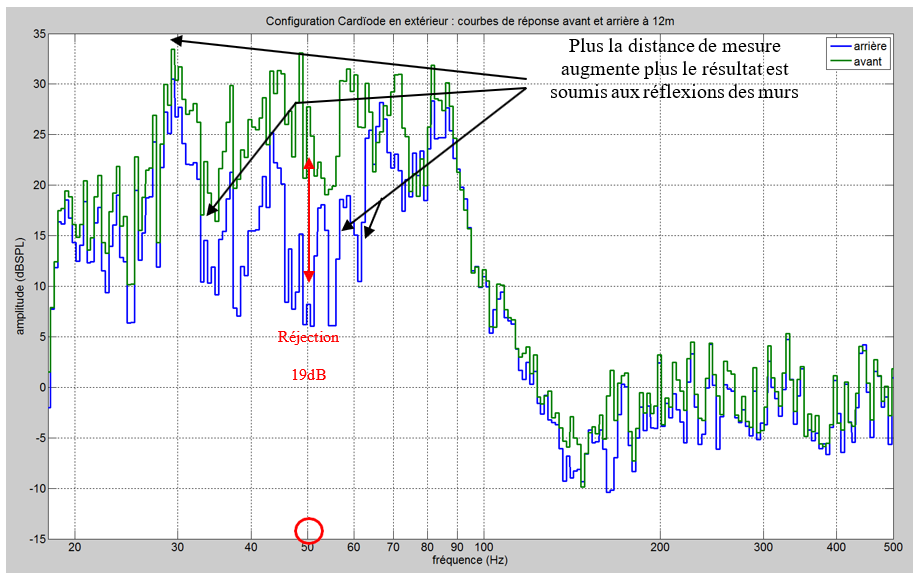
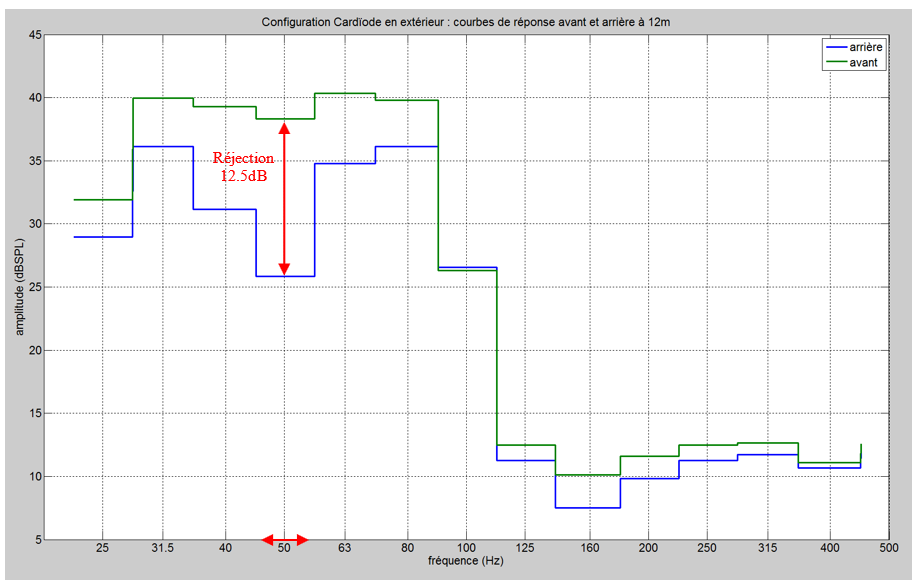

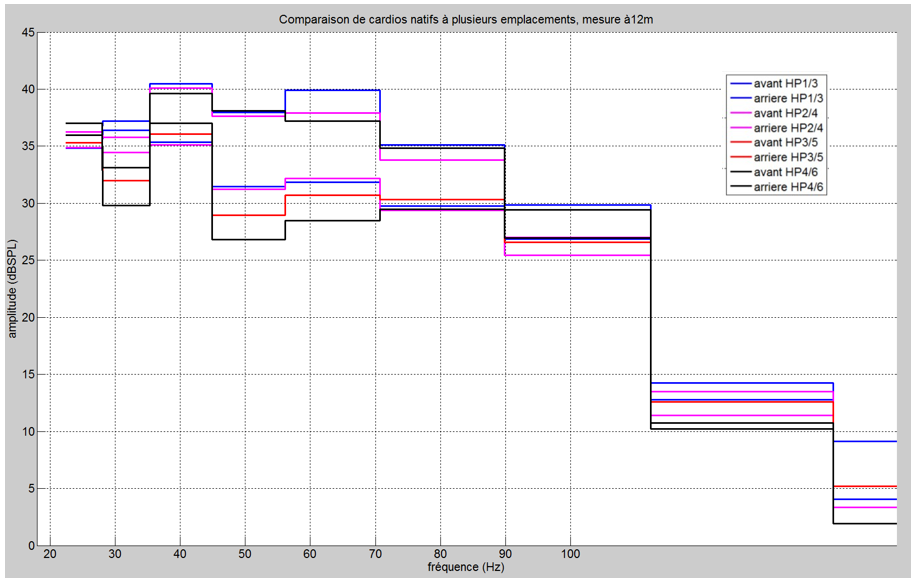
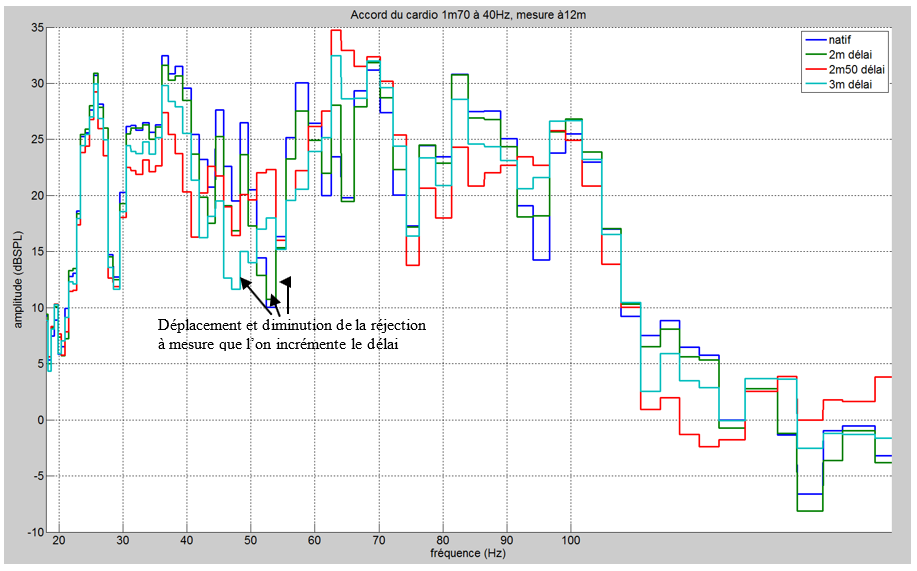
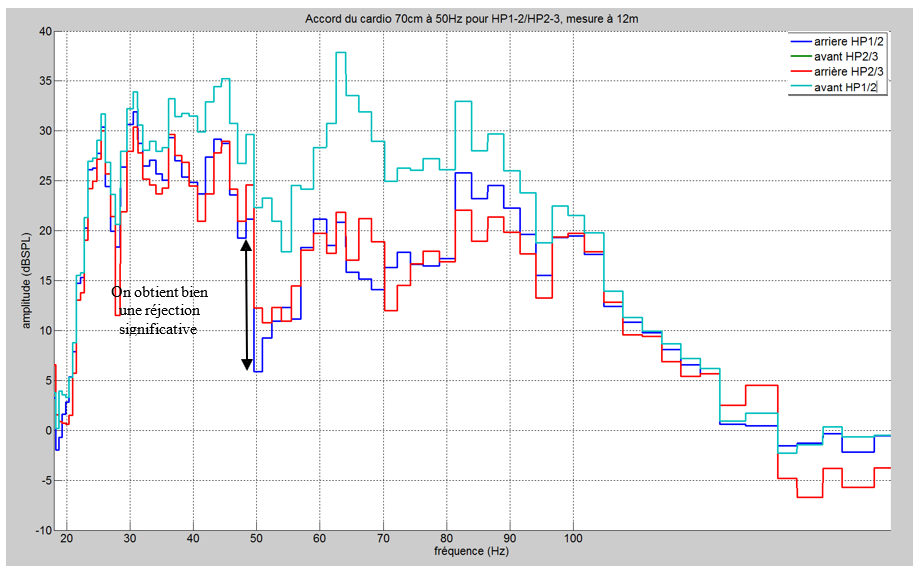

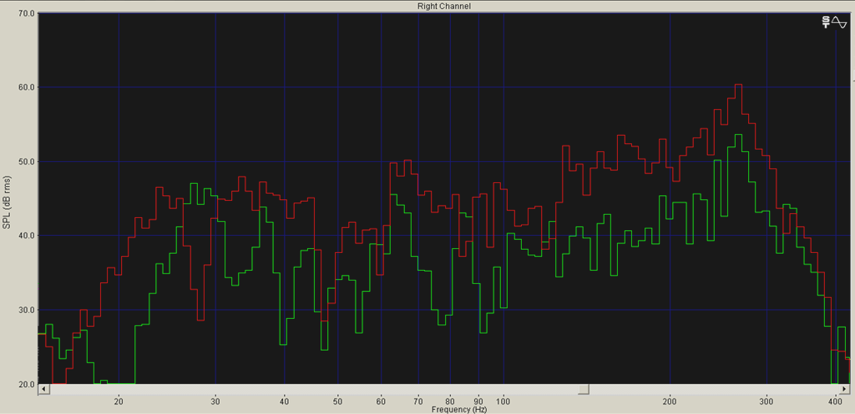


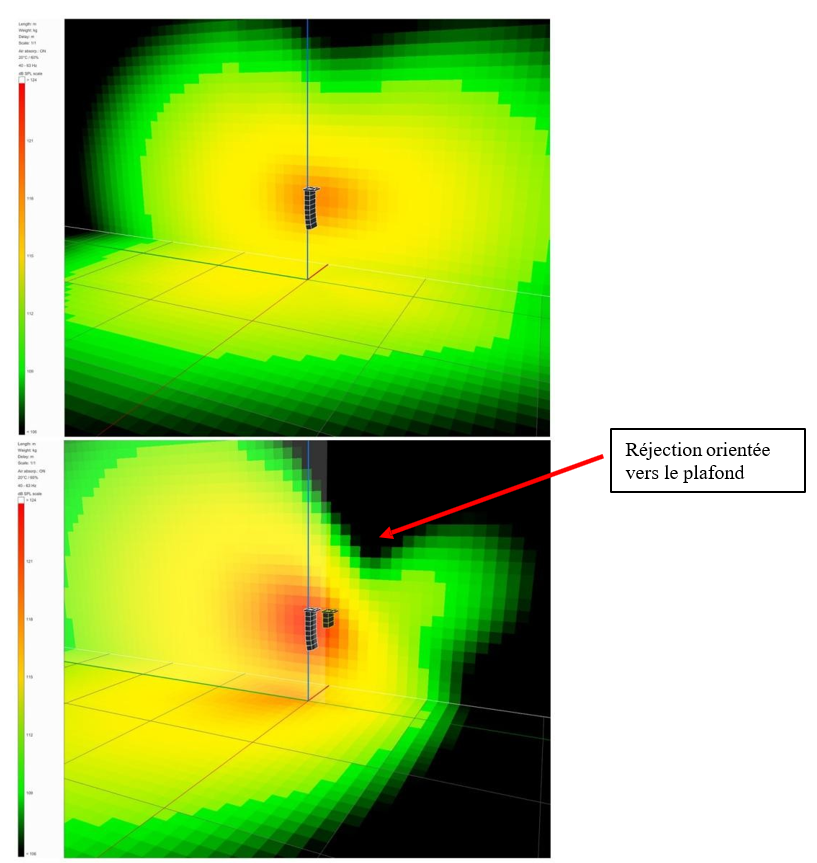

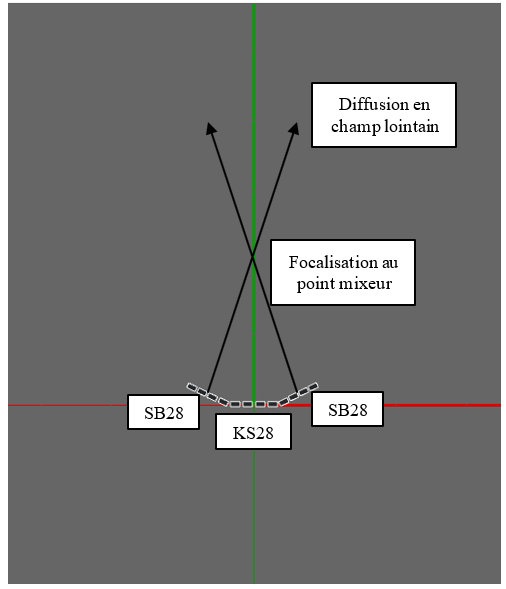

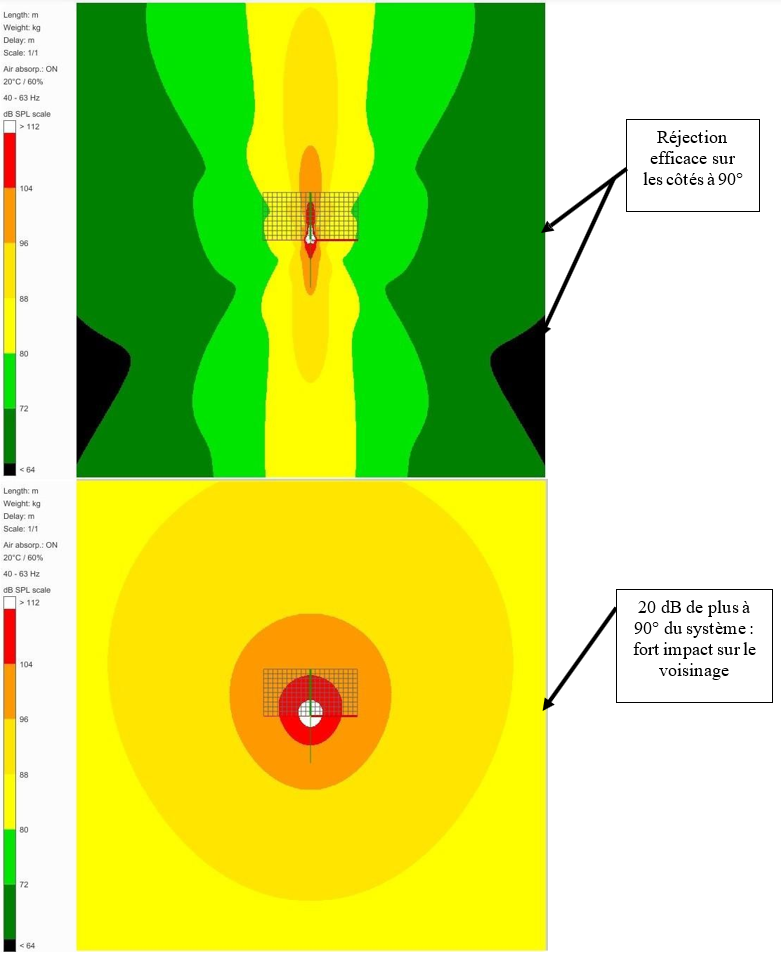
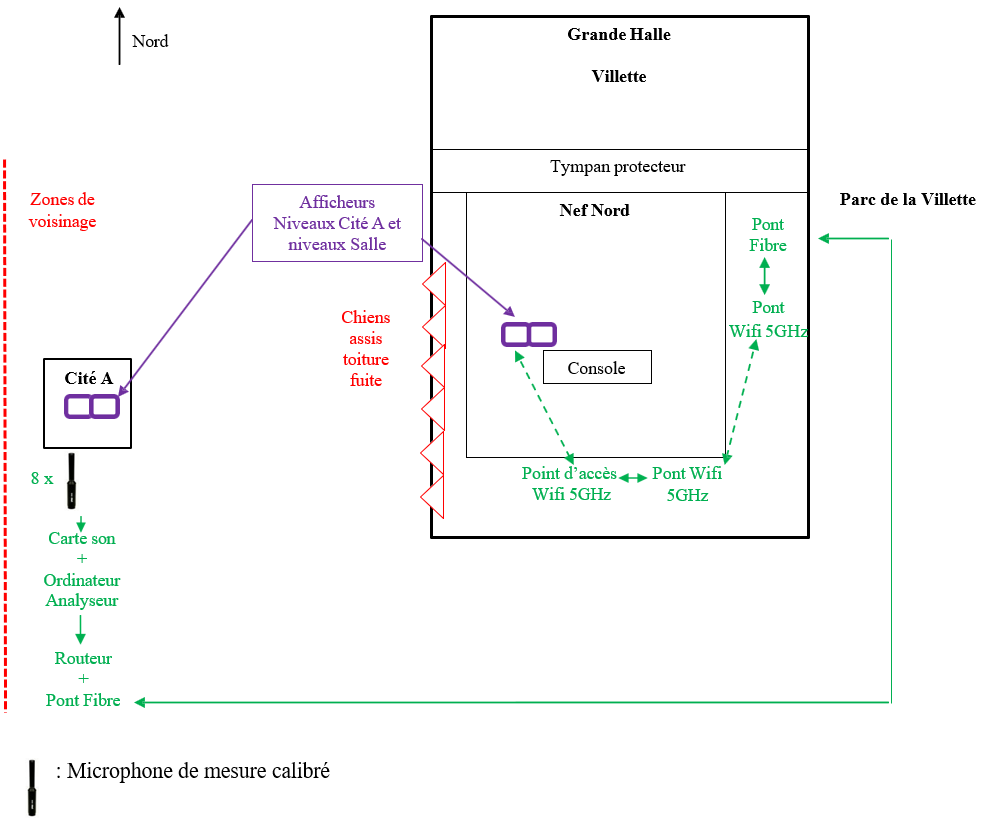

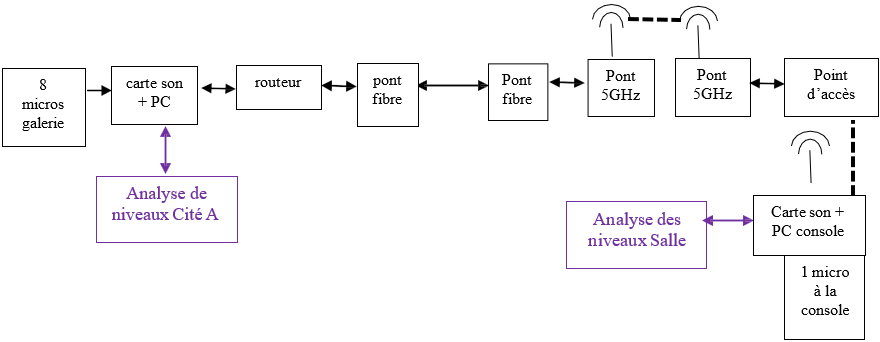
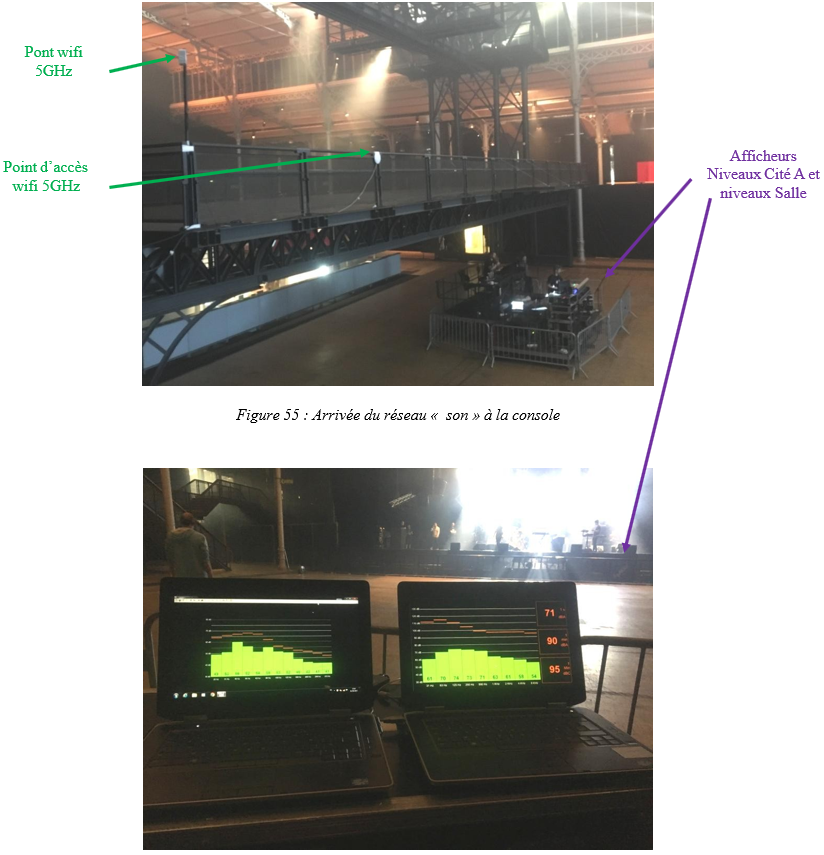
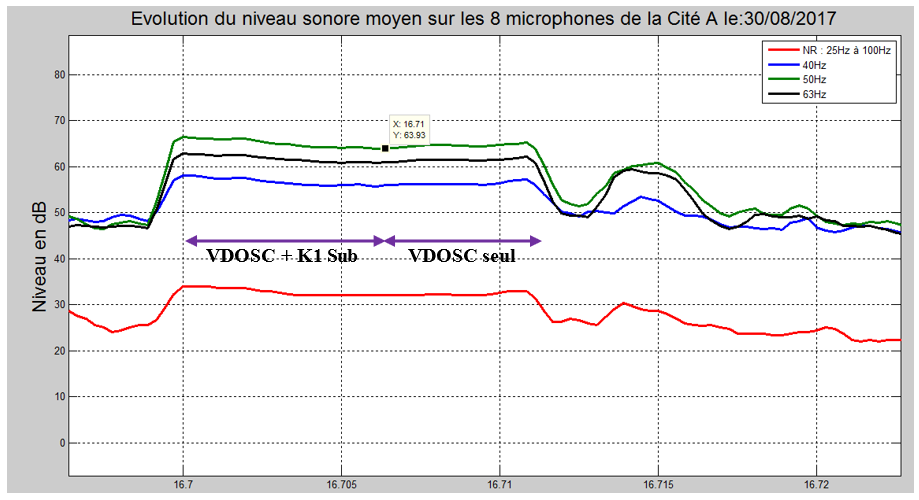
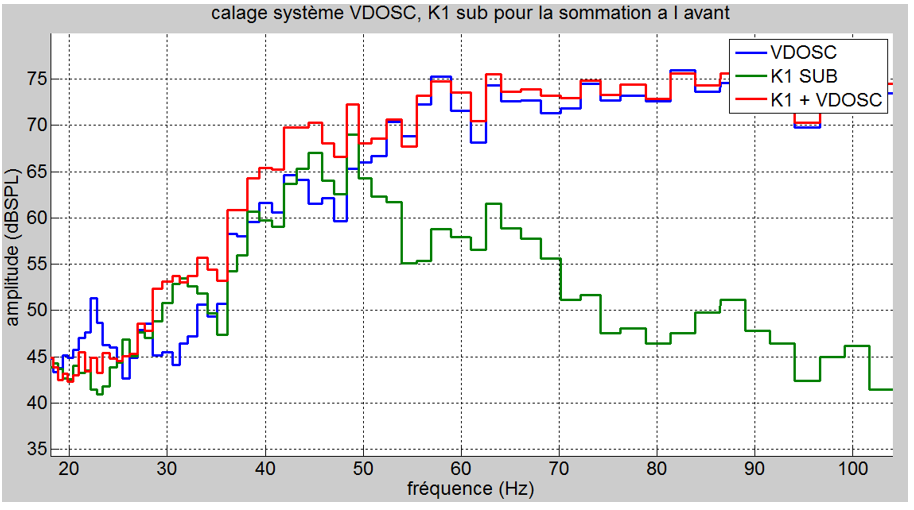
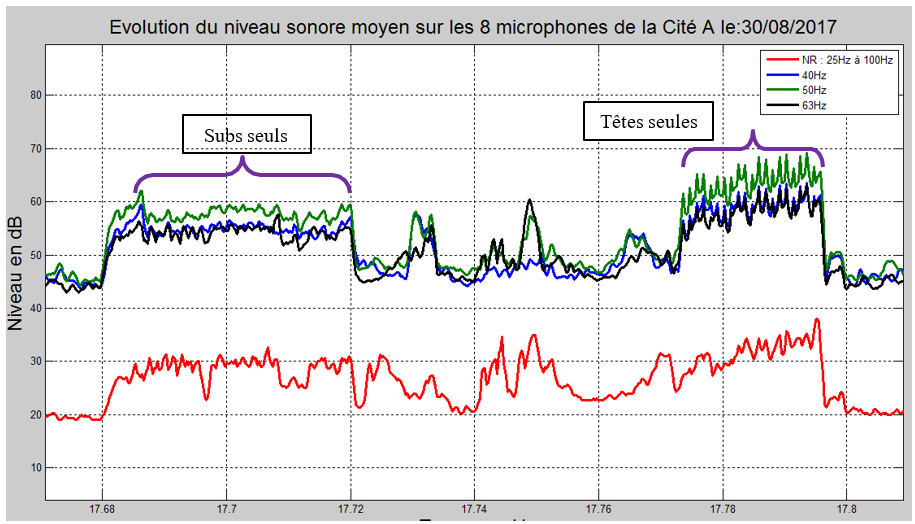
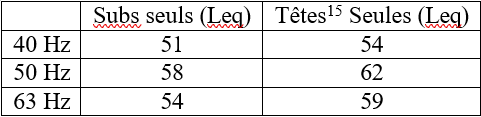
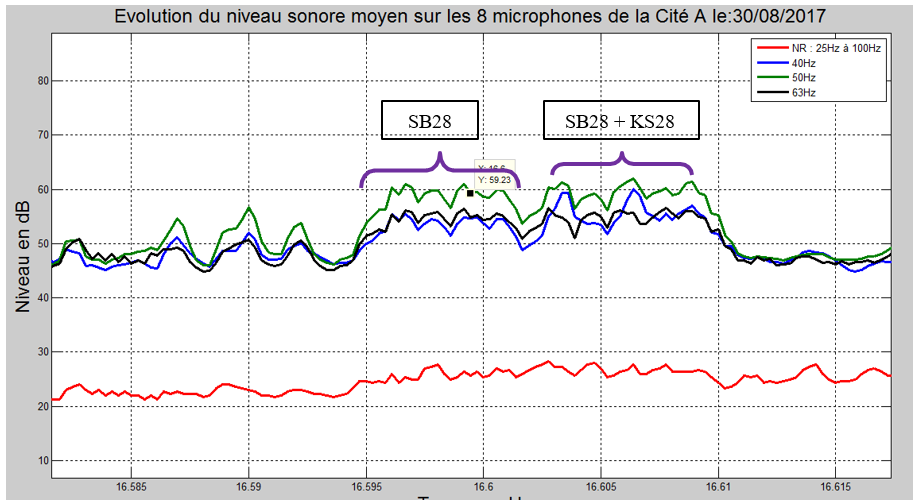
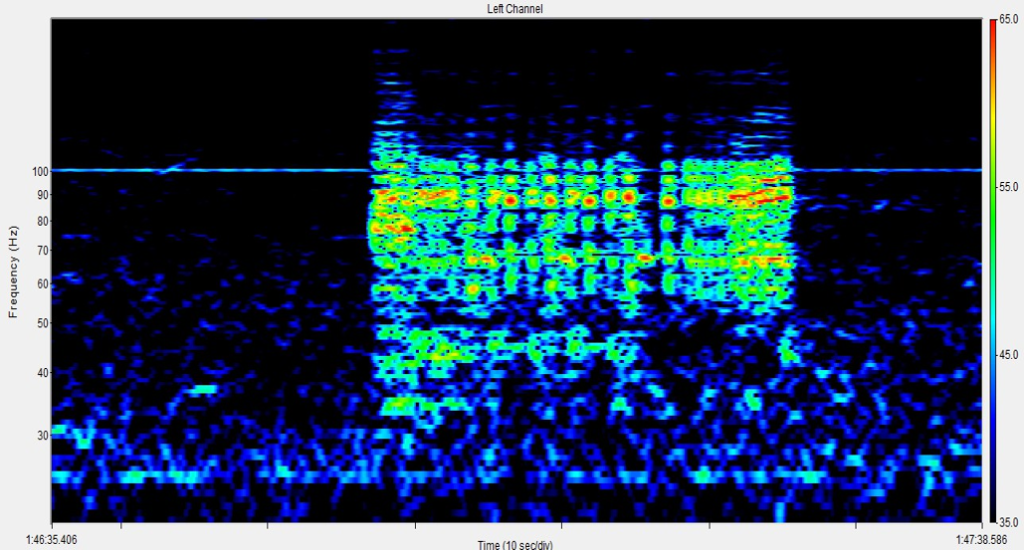
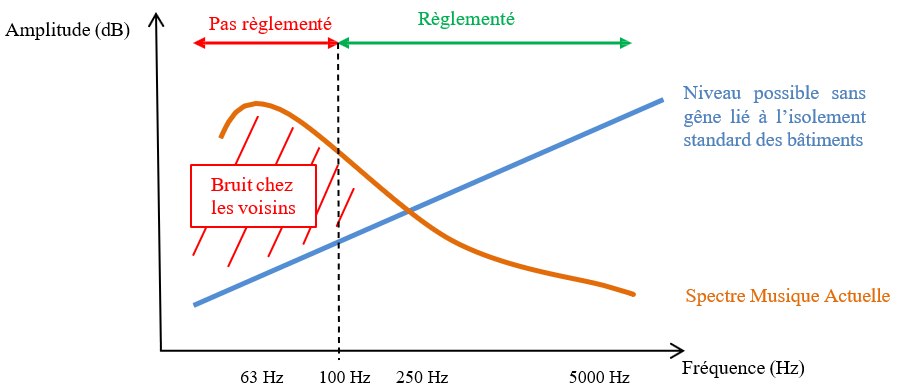
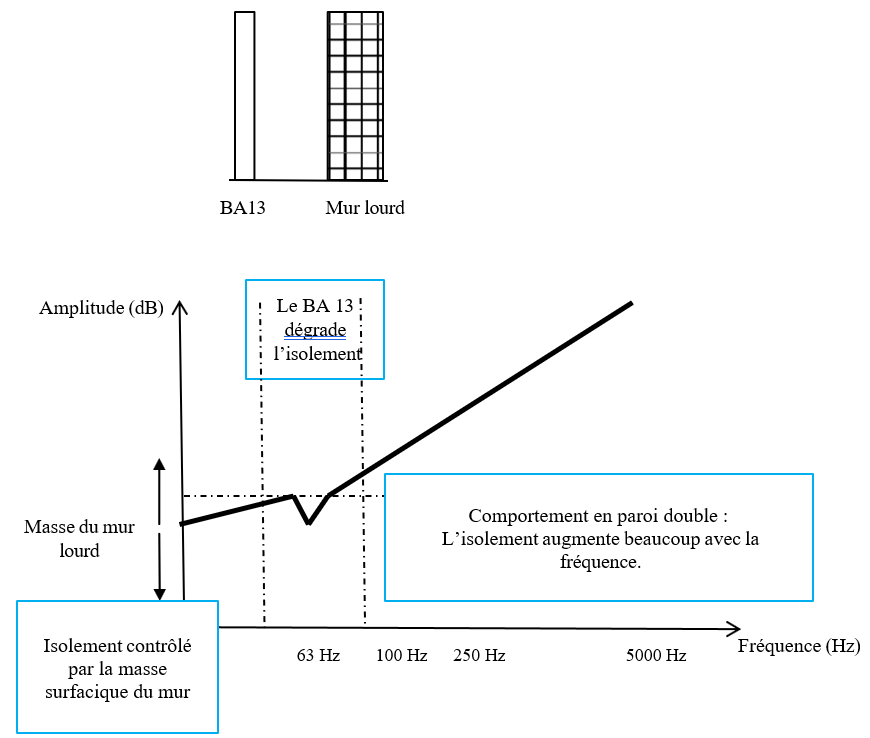

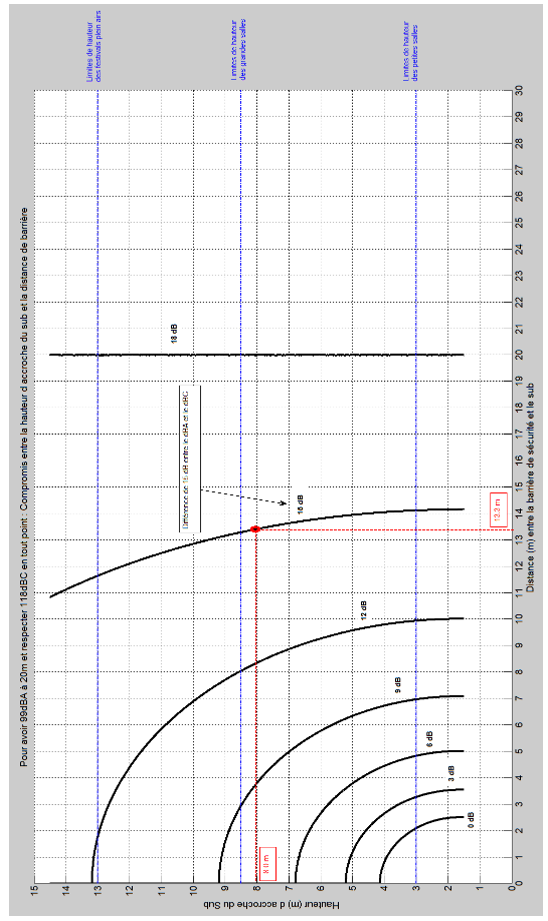

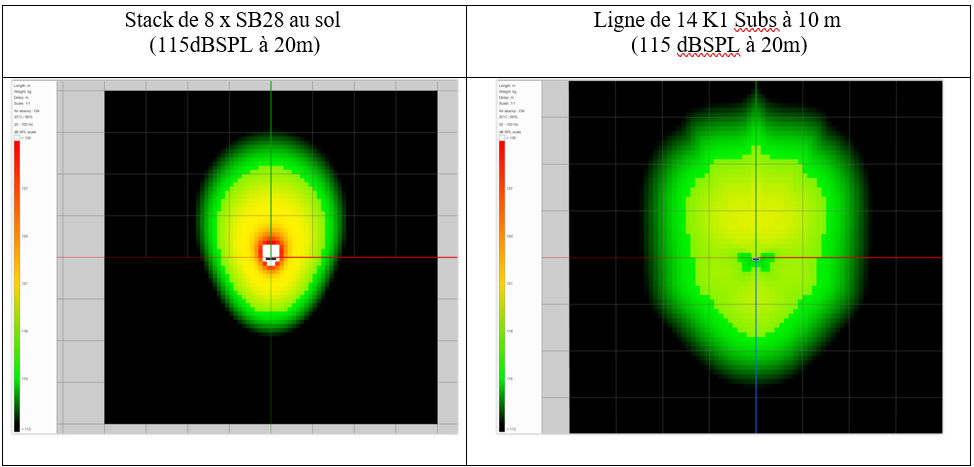
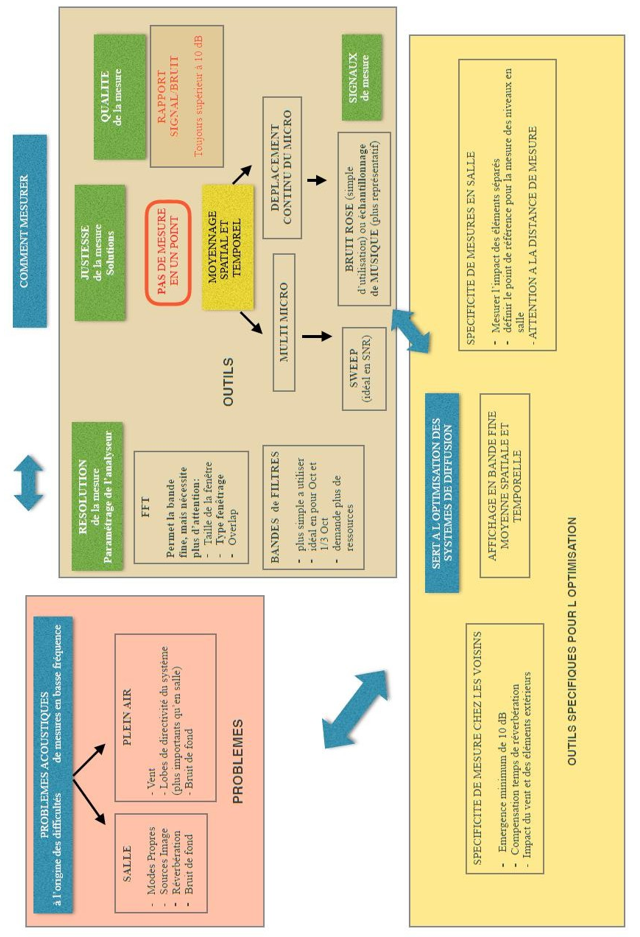
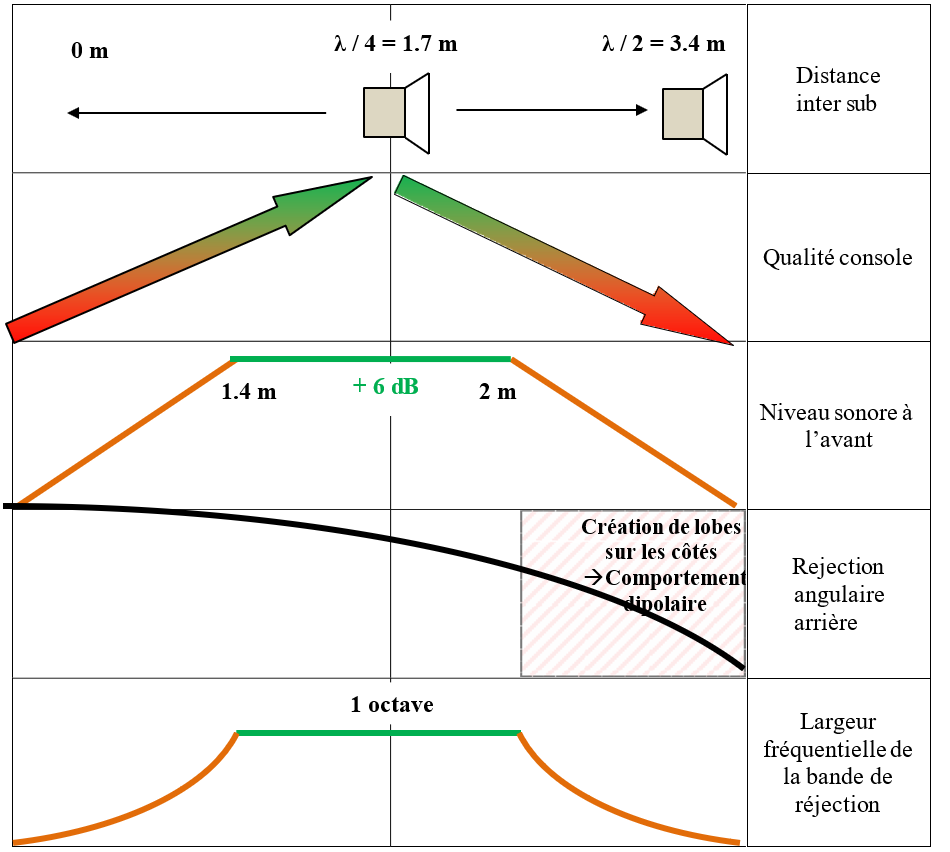
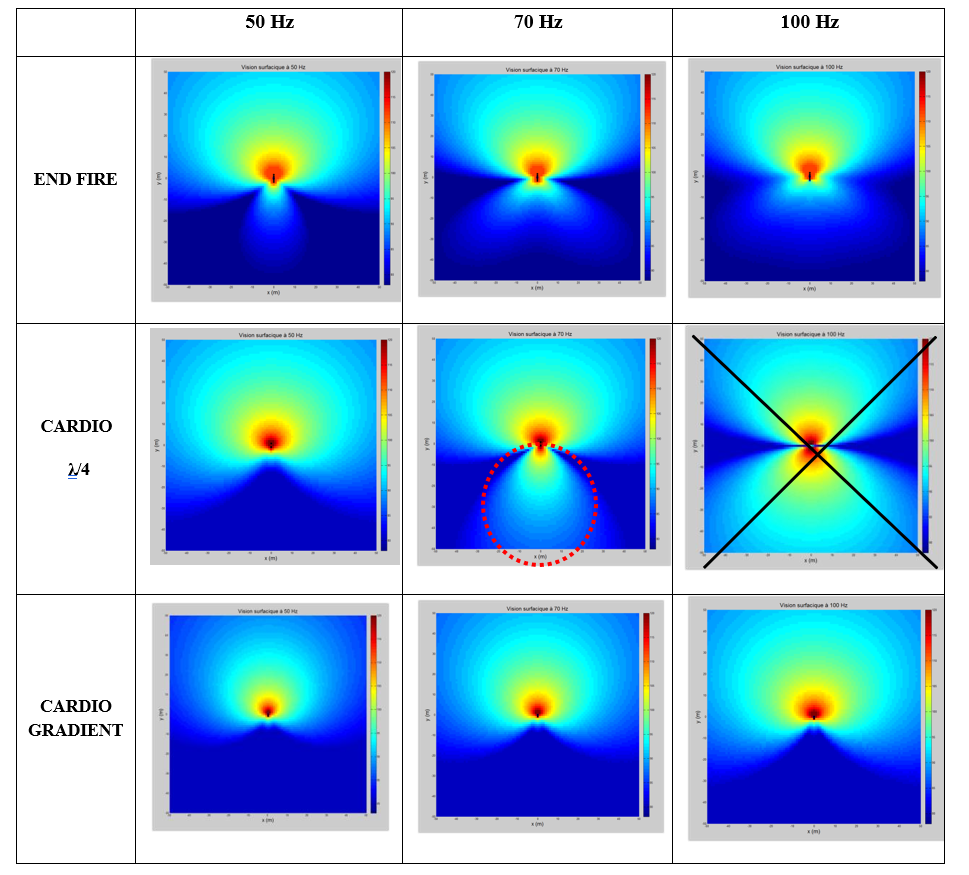
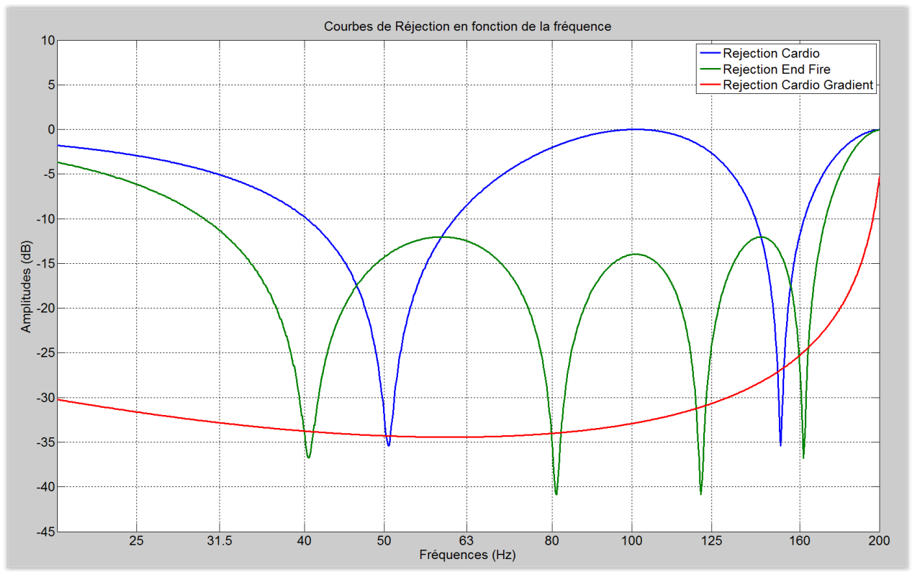
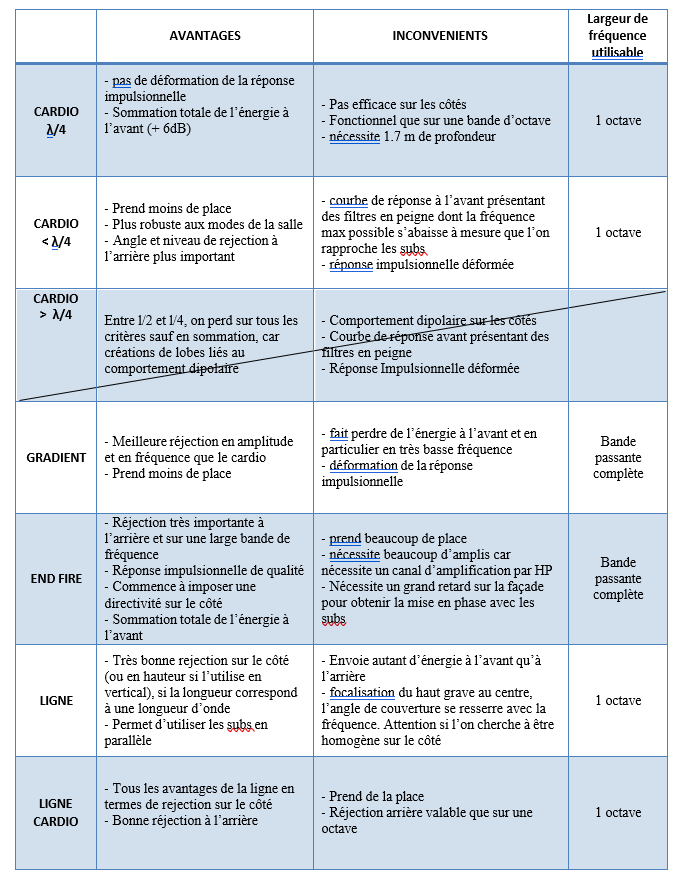
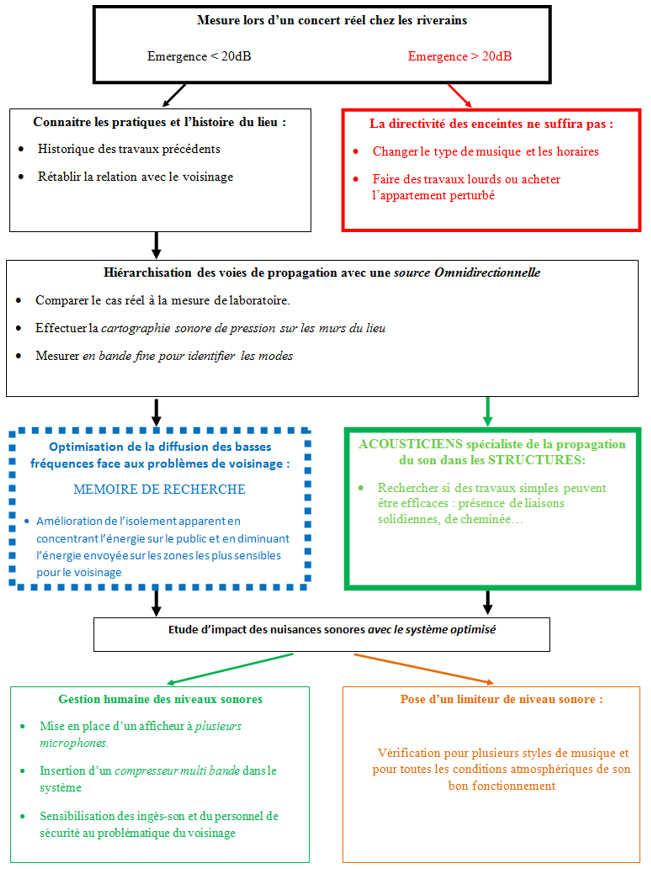
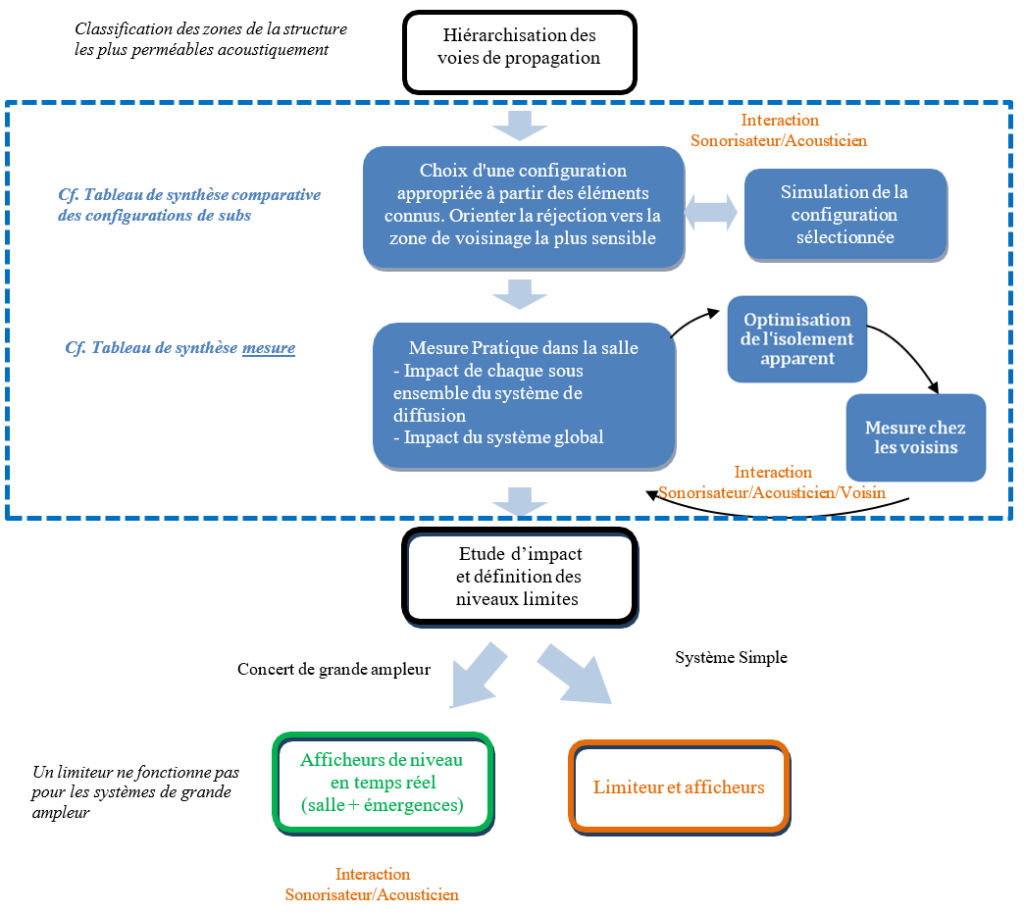

















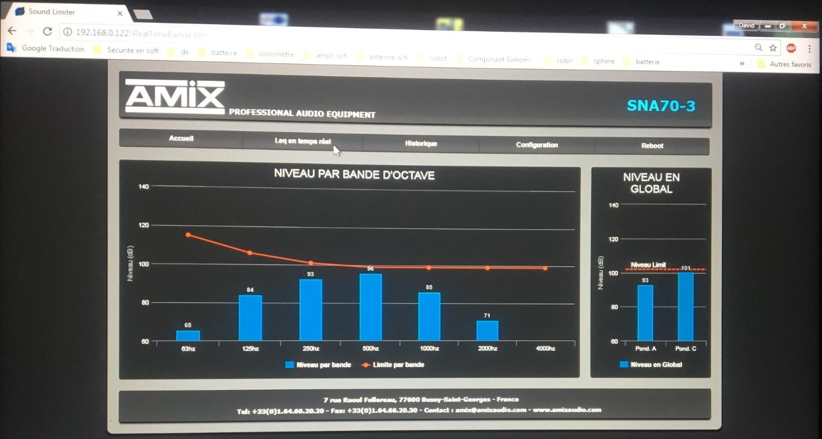

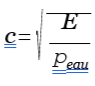
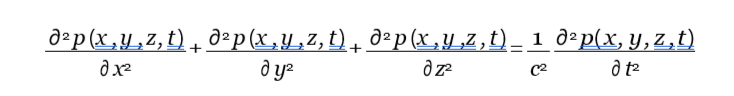
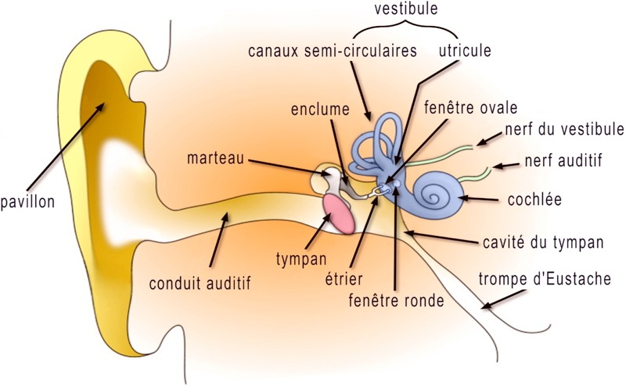
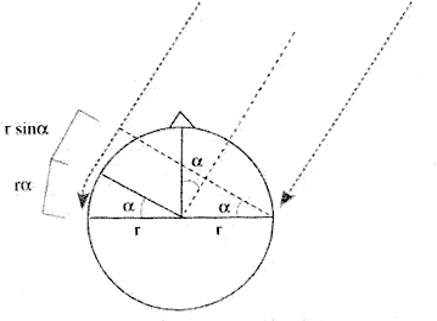
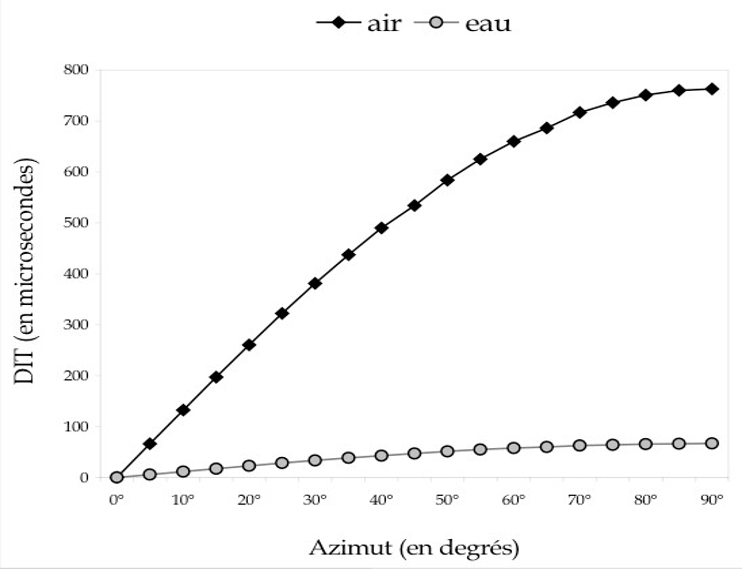

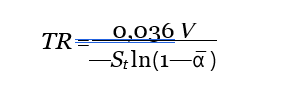








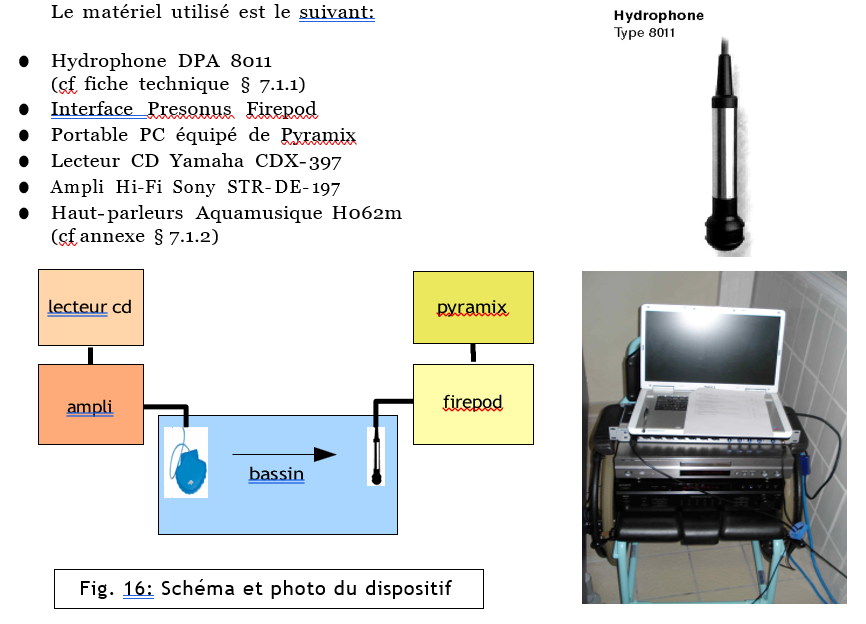
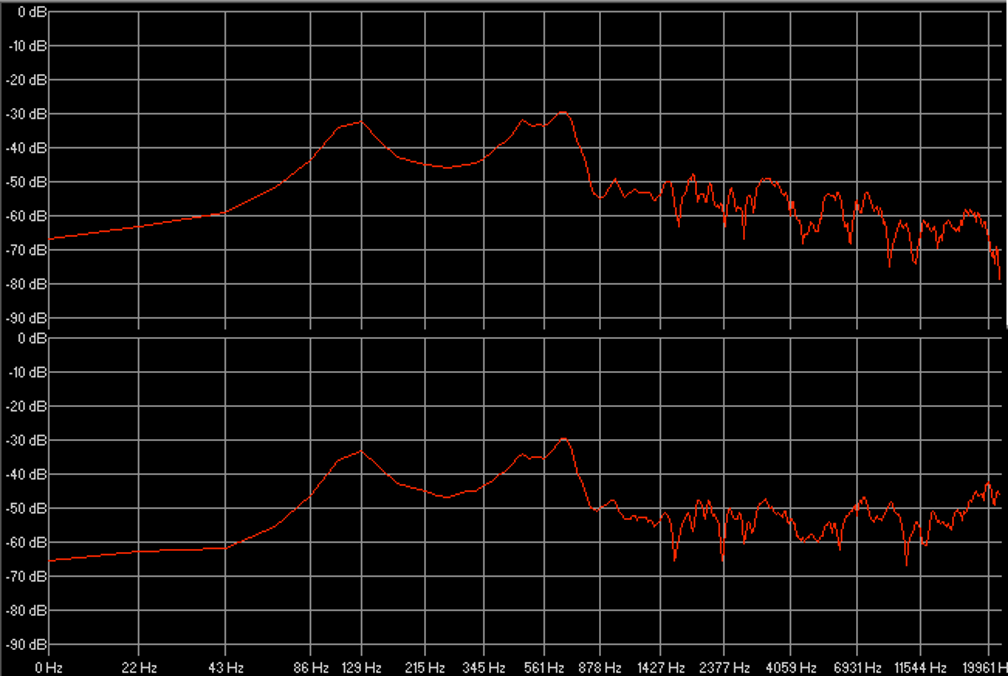
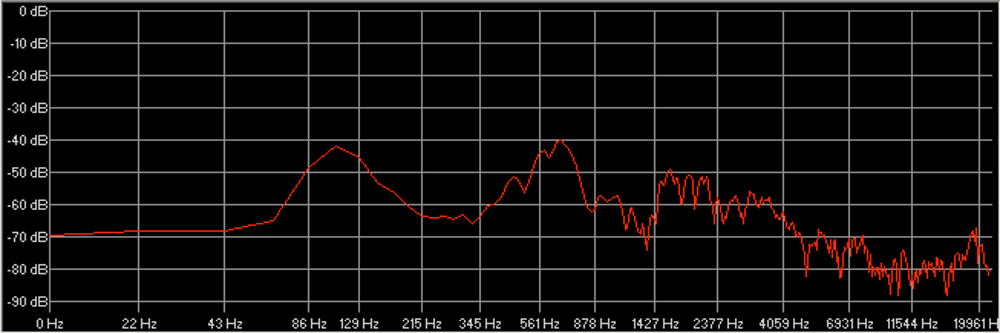
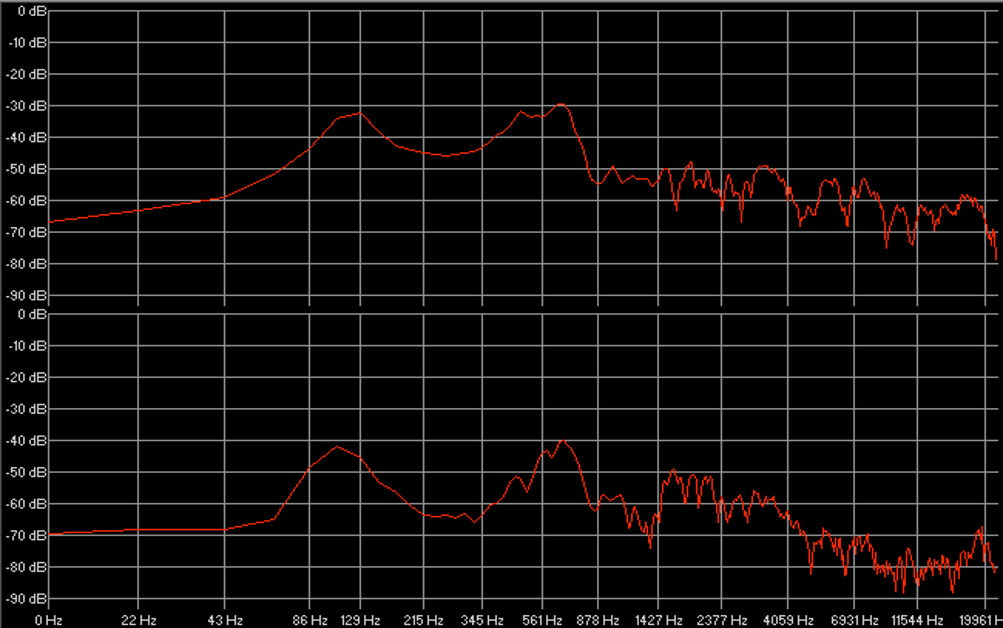

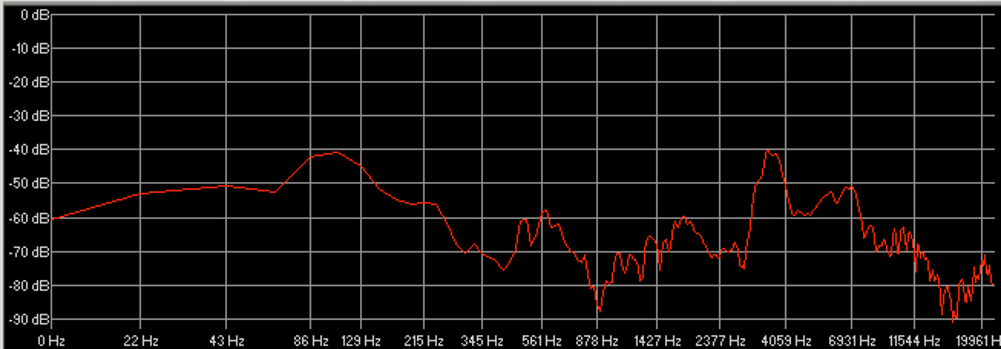
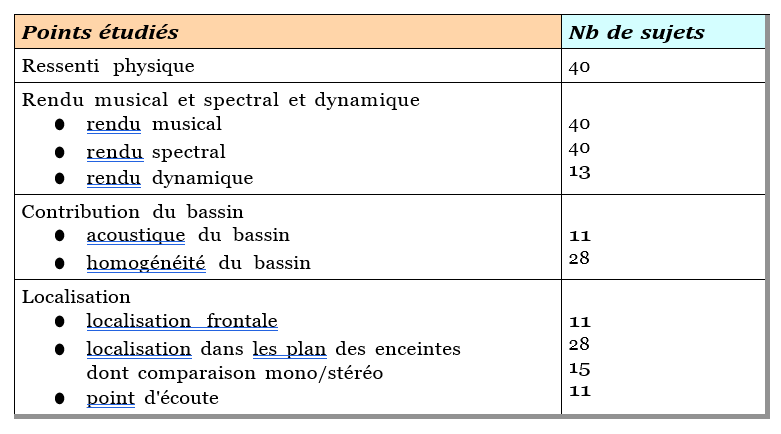
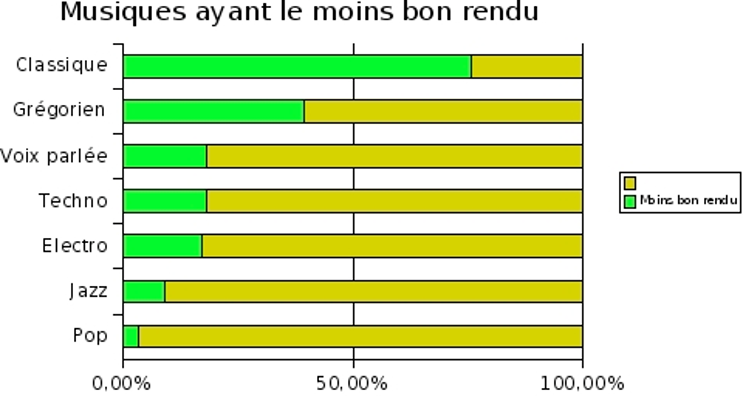
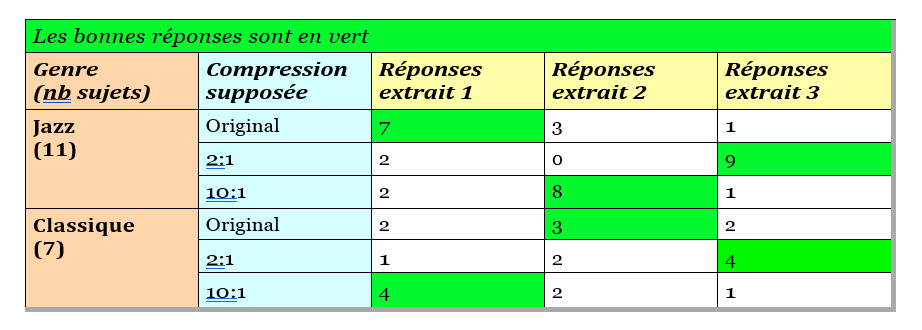



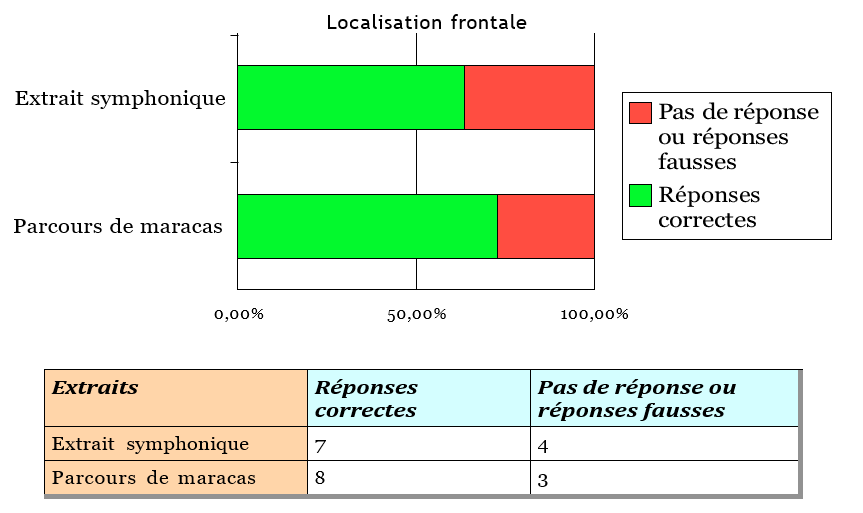

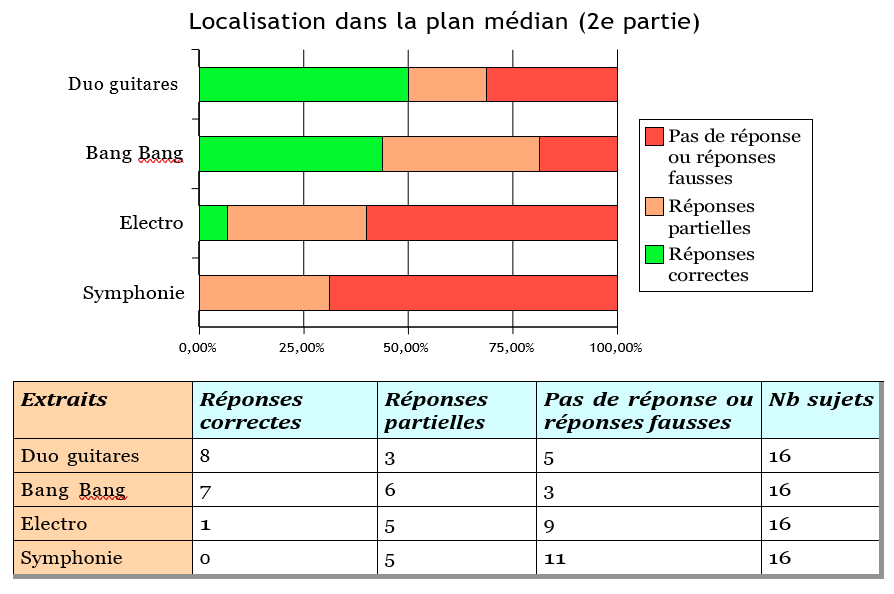

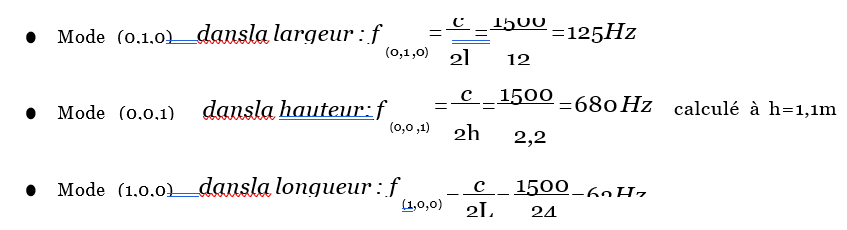

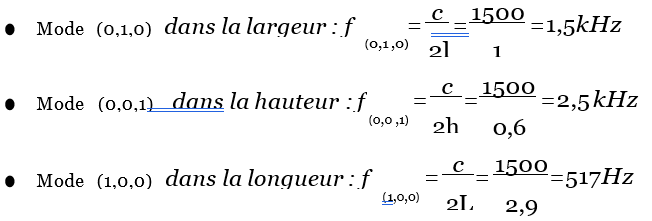
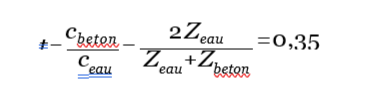




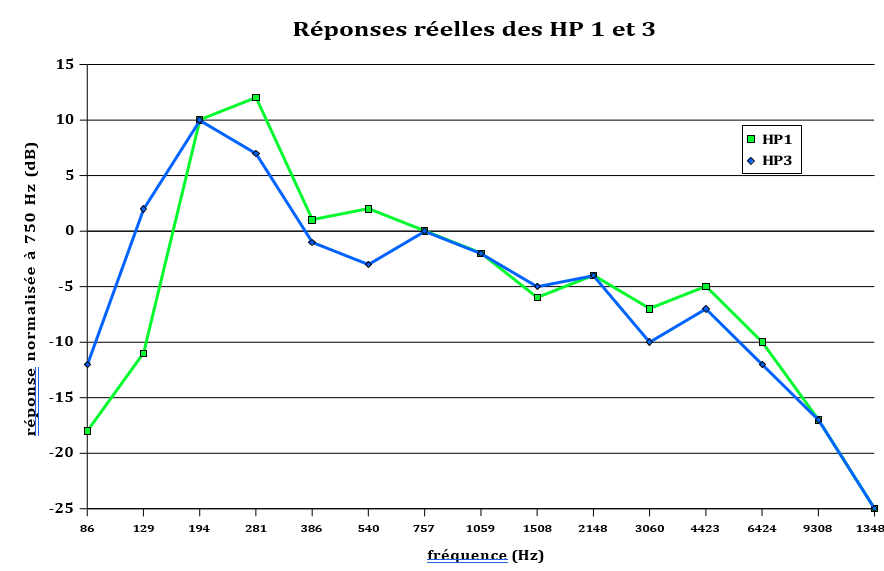






















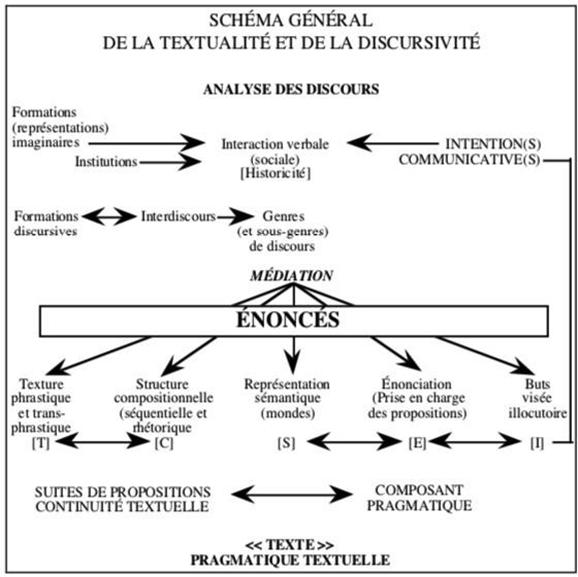




































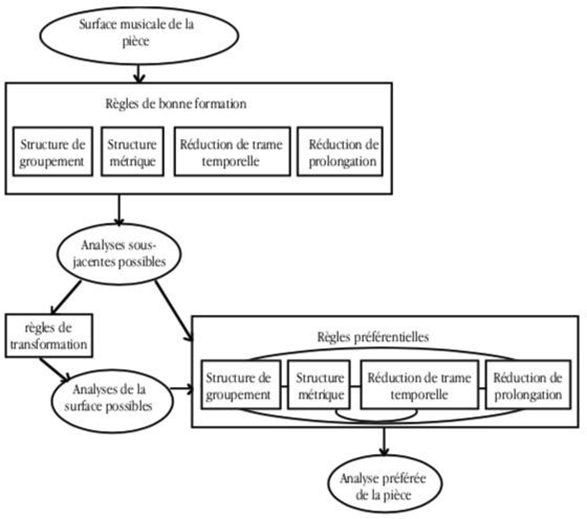



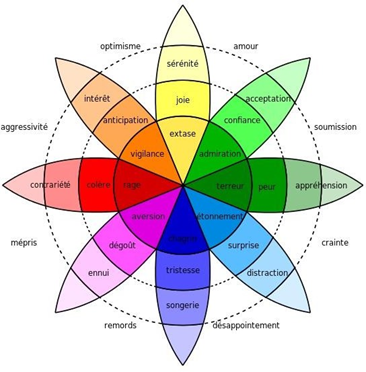
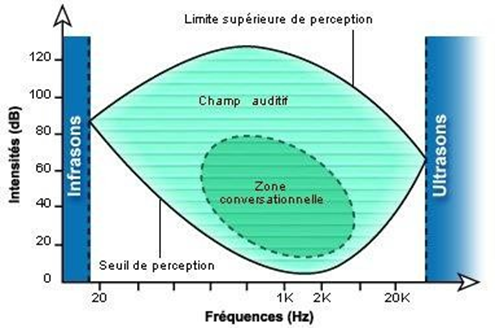
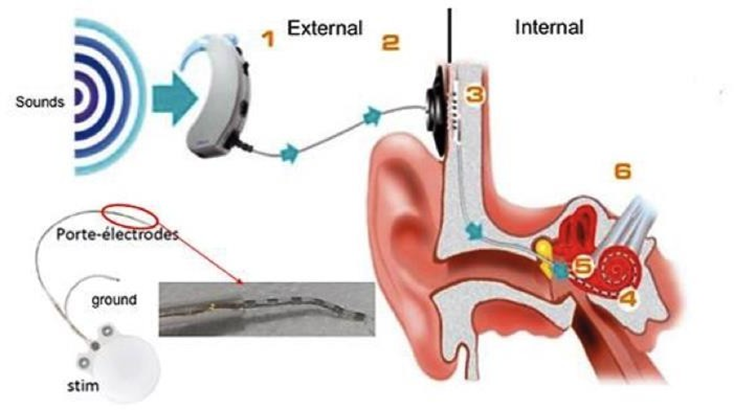
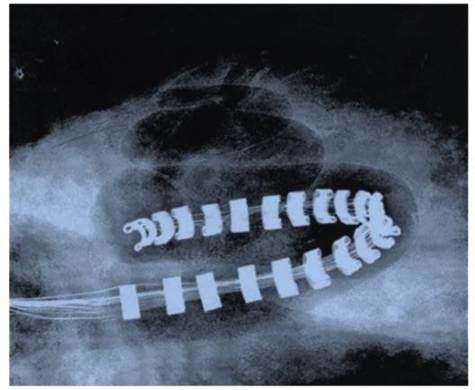
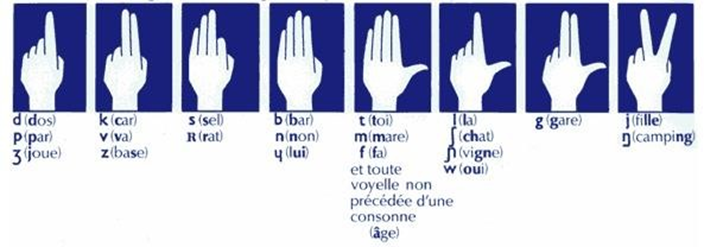














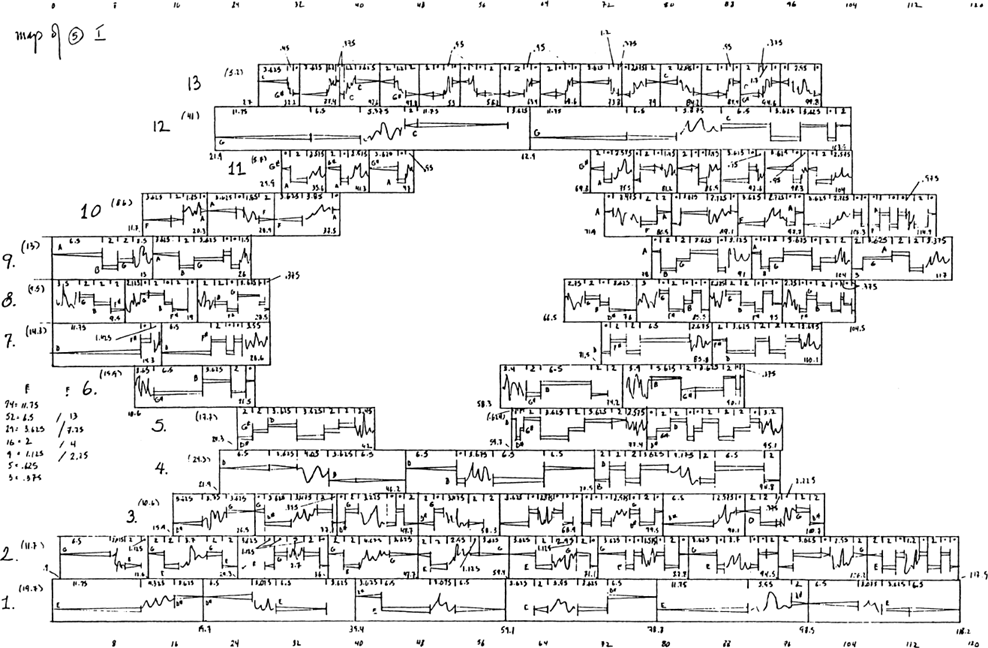
![Figure 102 : extrait de la partition Symphony [Myths] de Roger Reynolds, éditions Peters.](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-506-607x1024.png)
![Figure 103 : Symphony [Myths], de la mesure 1 à 51.](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-40.jpeg)






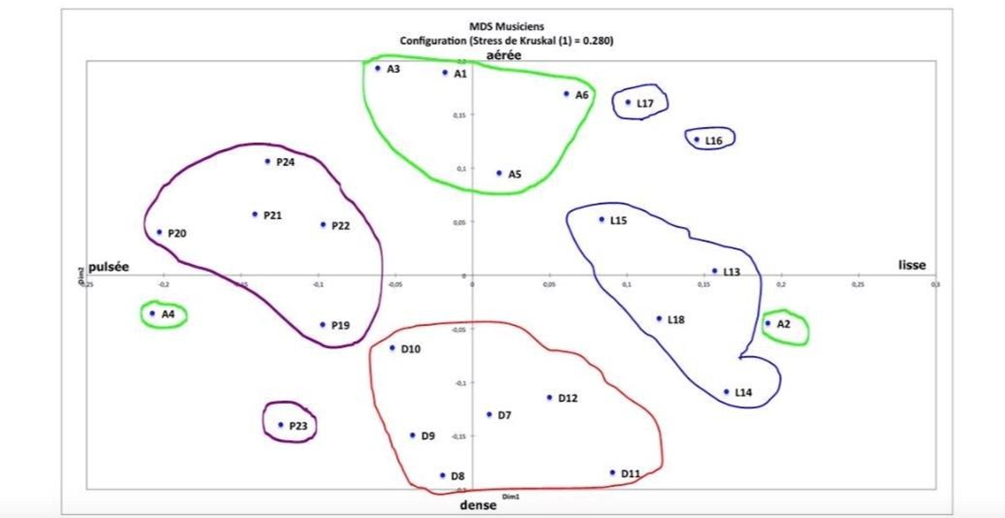
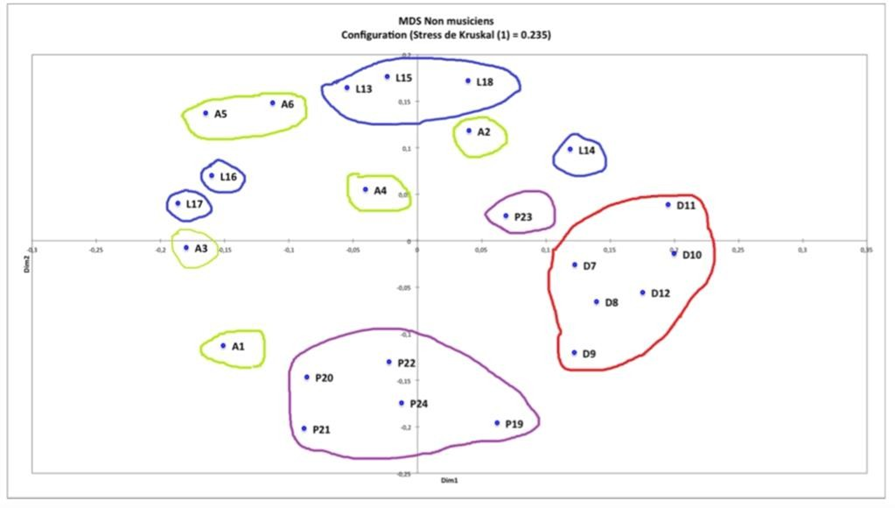

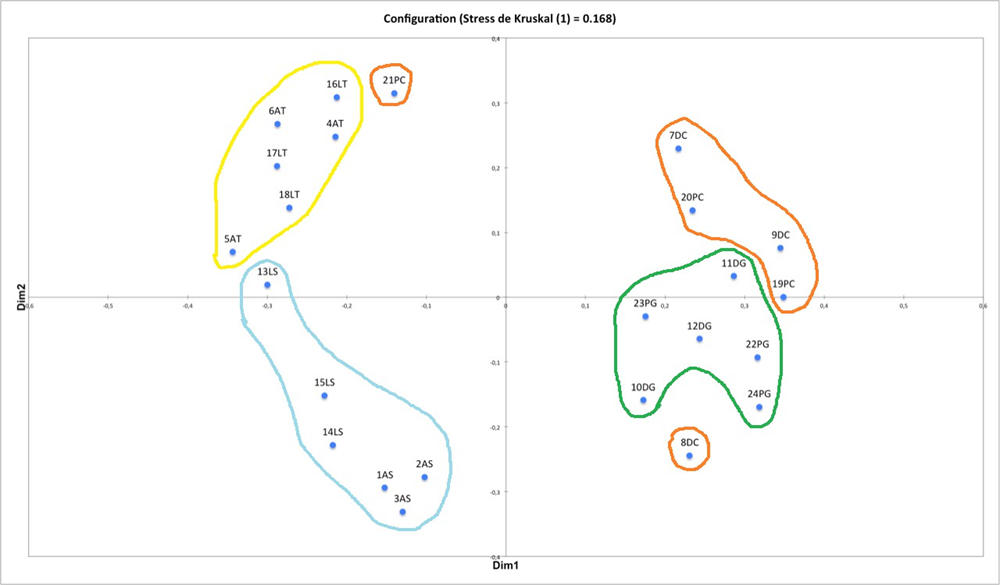
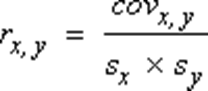
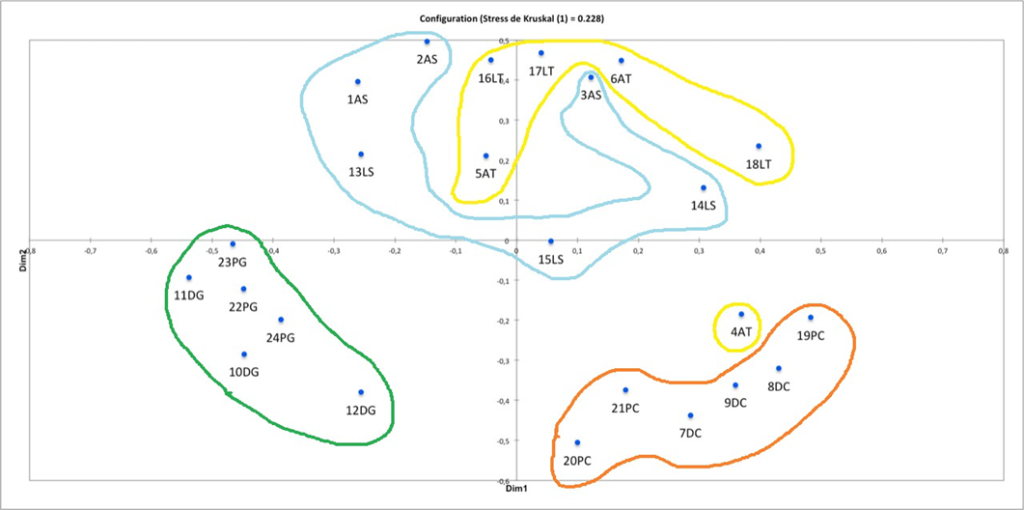
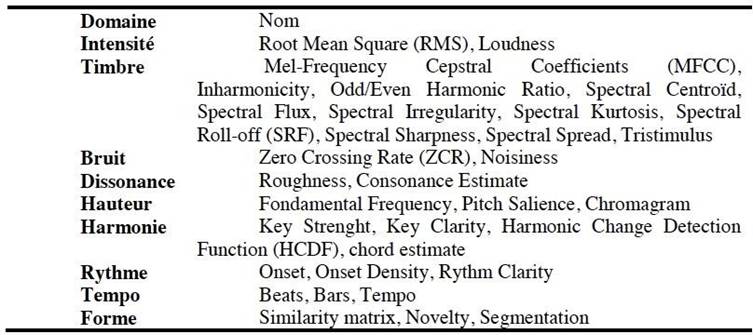
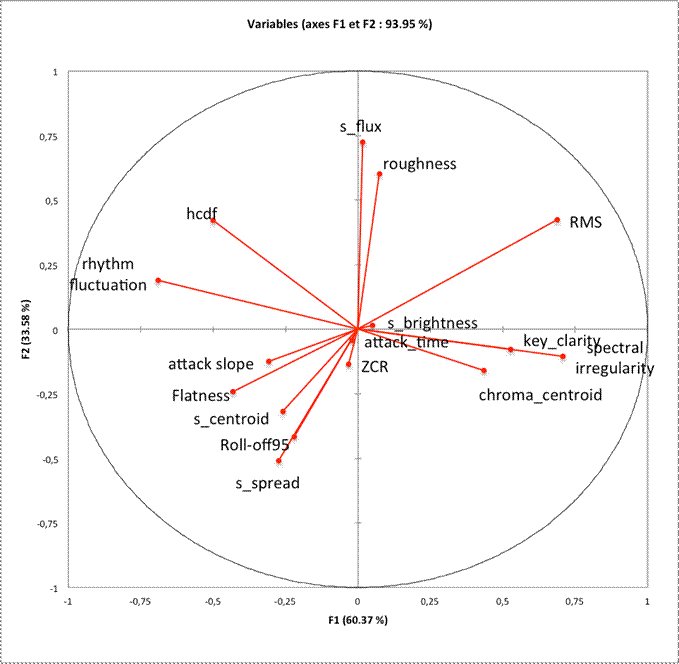
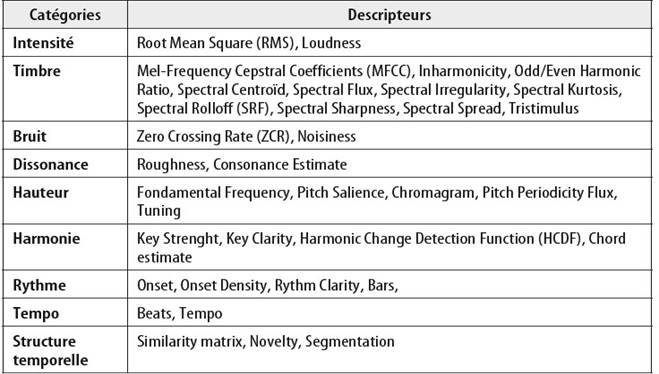
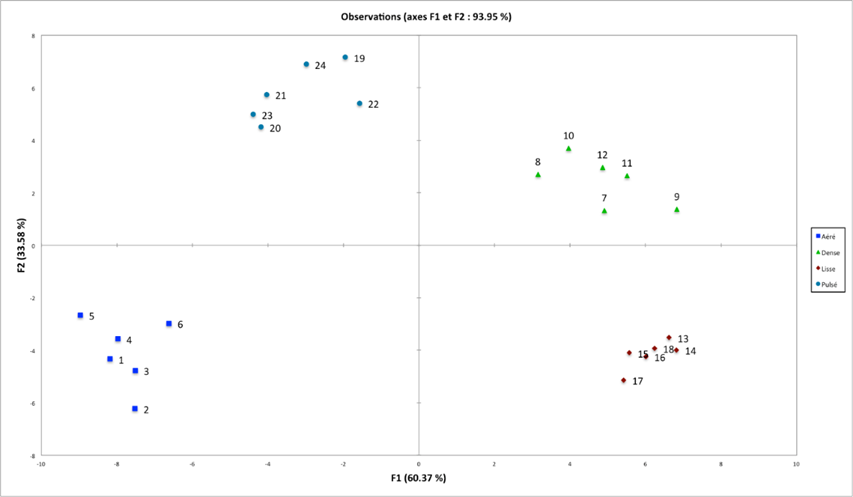
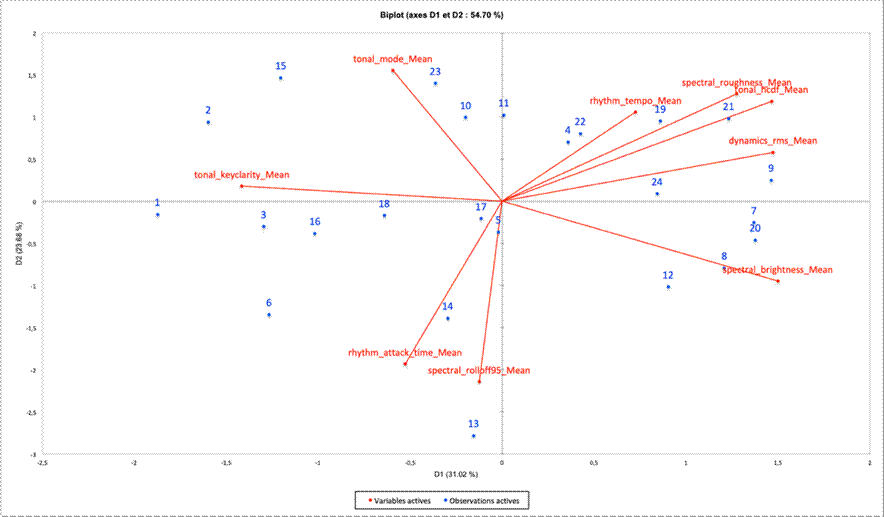
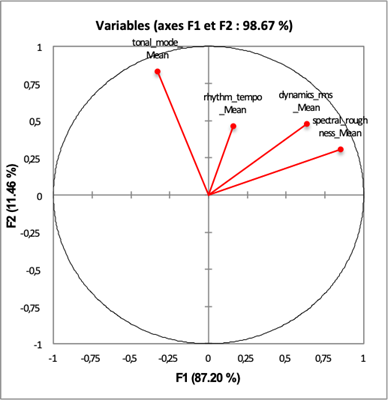
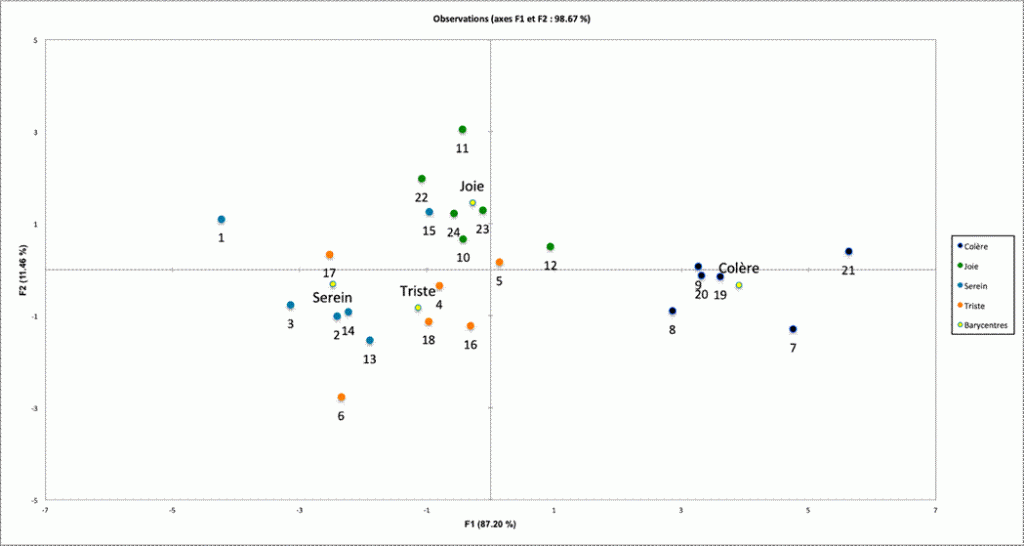


























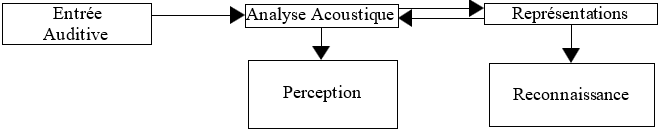
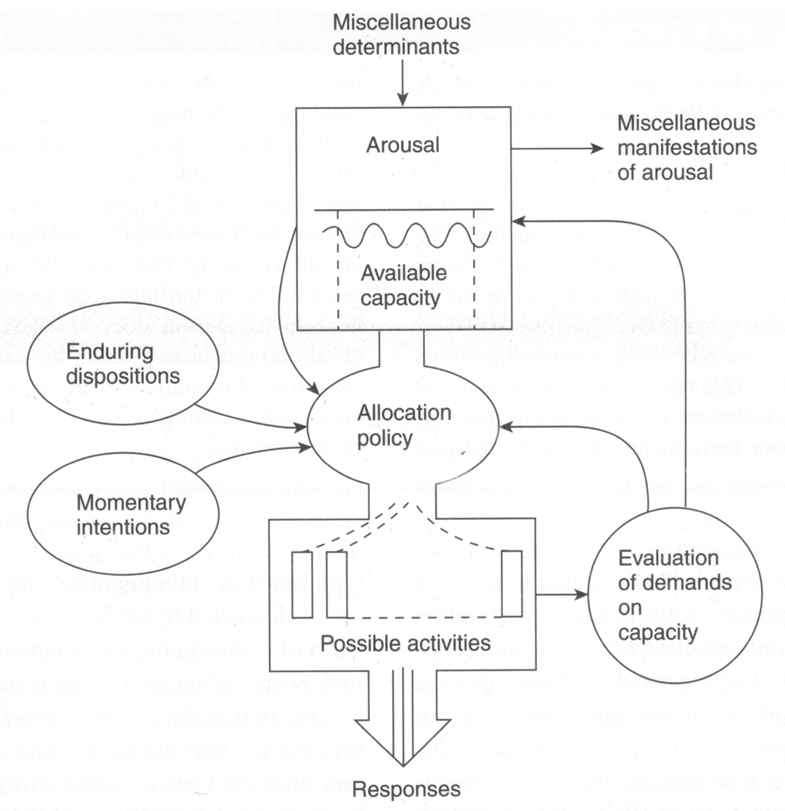
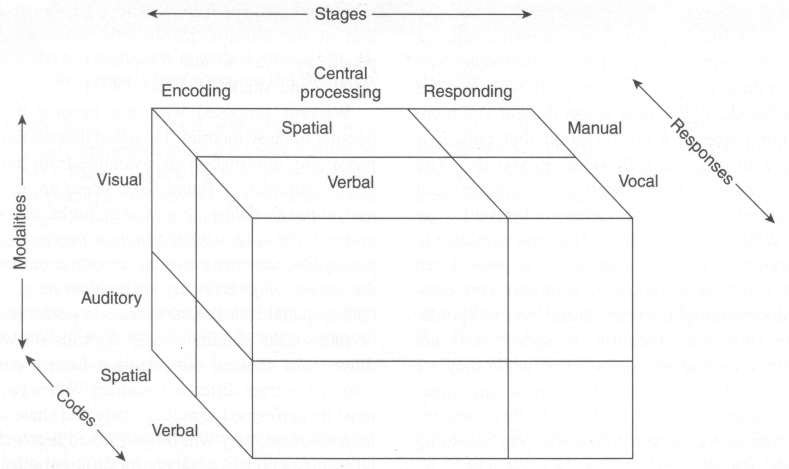
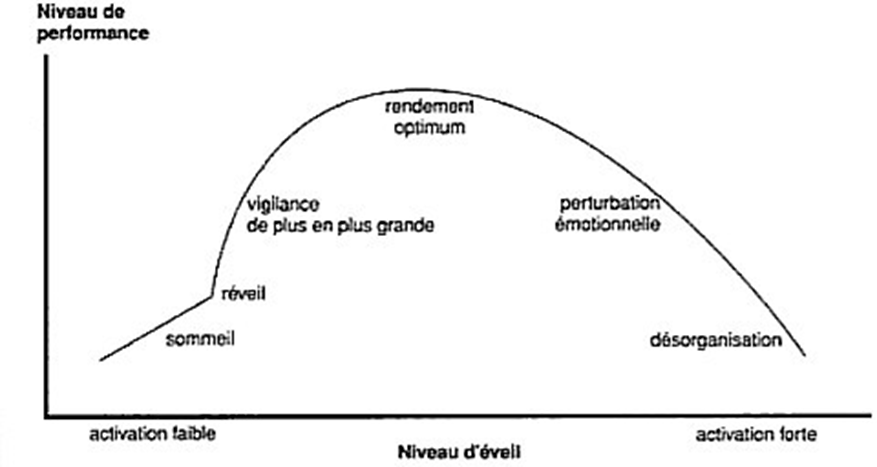

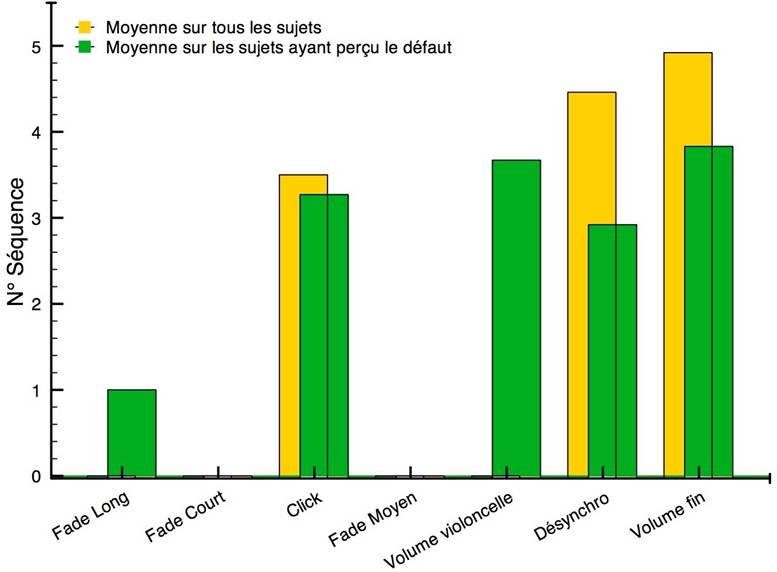
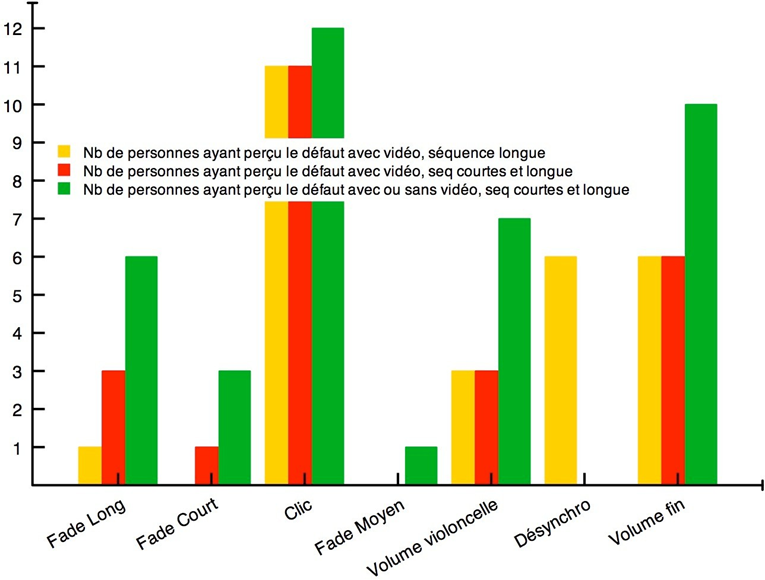
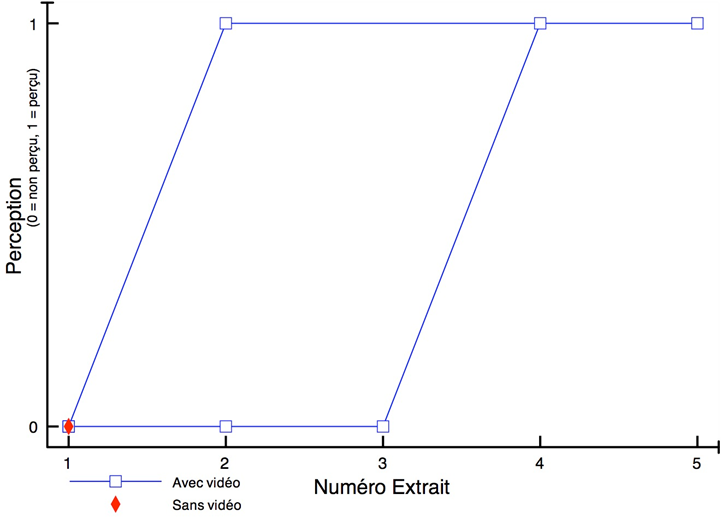
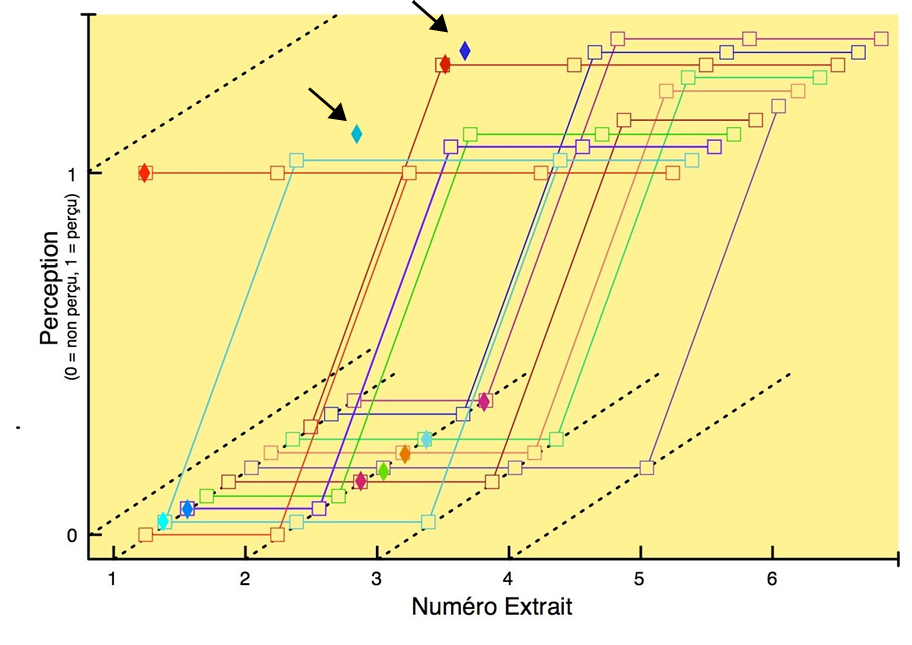
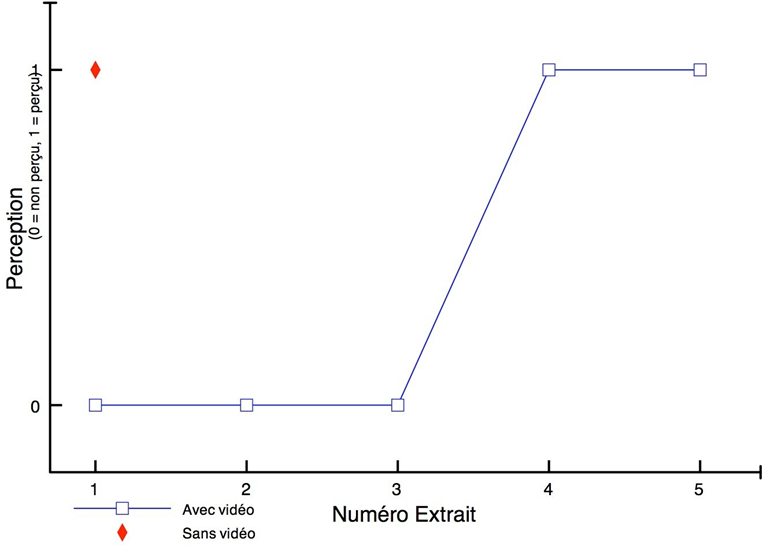
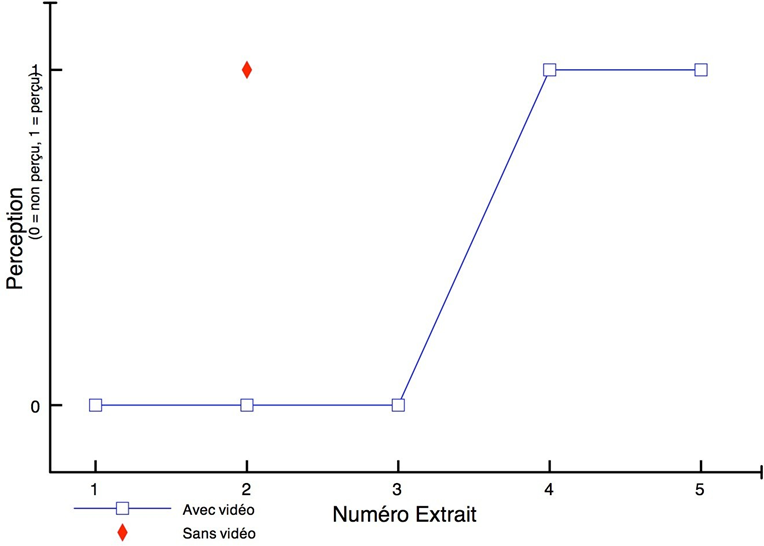
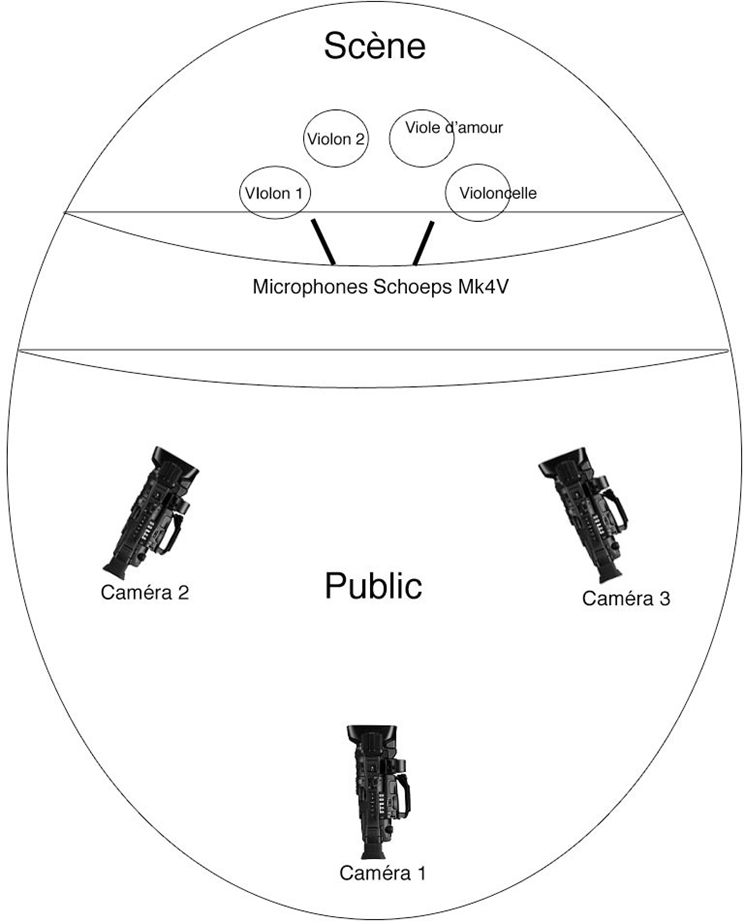
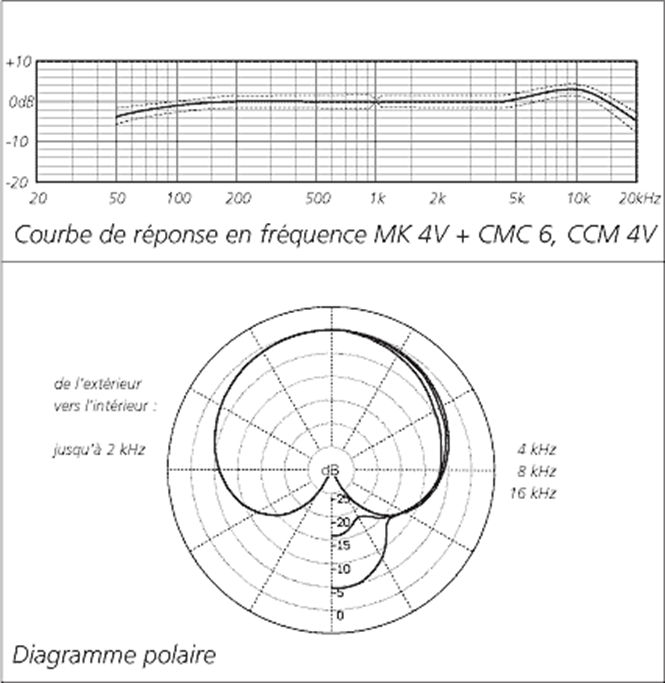








![Figure 1.4 – La grande salle de l'Arsenal de Metz. - Crédits photos : [11]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-323.png)
![Figure 1.4 – L'Auditorium de Dijon - Crédits photos :[12]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-324.png)


![Figure 1.7 – Deux configurations de Decca Tree - A gauche : configuration avec obstacle acoustique. A droite : 5 microphones M50 (dont deux ailes) - Crédits photos : [19]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-327.png)

![Figure 1.9 – Session d'enregistrement Philips - Crédits photo : [21]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-330.png)
![Fig. 1.10 – Utilisation d’un syst`eme XY lors d’un enregistrement Deutsche Grammophon Cr´edits photo : [17]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-332.png)
![Figure 1.11 – Enregistrement Deutsche Grammophon à la Jesus-Christus-Kirche, Dahlem, Berlin - Crédits photo : [17]](https://learninghub-prod-media.s3.fr-par.scw.cloud/uploads/2026/05/image-333.png)